
- 1Vue 0基础学习路线(22)—— 图解深度详述vue的路由组件传参和传参默认处理模式、对象模式、回调函数模式三种方式及详细案例(附详细案例代码解析过程及版本迭代过程)_vue-router 对象模式
- 2.NET中的IO操作基础介绍
- 3HTML的基础使用以及方法
- 4使用uniapp开发微信小程序的流式对话展示_微信小程序文字流式输出示例
- 5@Transactional 事务不要滥用, 要考虑各方面的回滚方案哦_spring事务回滚如何实现消息补偿
- 6Datawhale 动手学大模型应用开发 第六章第七章笔记 迭代优化prompt / 大模型评估 / 项目结构 / Gradio&FastAPI_gradio和fastapi
- 7量子计算 | 解密著名量子算法Shor算法和Grover算法_洛伊德·格罗夫提出grover算法
- 8FLStudio21.2.2.3中文版完整下载及新功能介绍_fl21.2.2
- 9tensorflow-gpu安装(详解)_gpu tensorflow
- 10AI基础知识(3)--神经网络,支持向量机
RAFT:让大型语言模型更擅长特定领域的 RAG 任务_raft rag
赞
踩
RAFT(检索增强的微调)代表了一种全新的训练大语言模型(LLMs)以提升其在检索增强生成(RAG)任务上表现的方法。“检索增强的微调”技术融合了检索增强生成和微调的优点,目标是更好地适应各个特定领域。该技术由微软的主要AI倡导者 Cedric Vidal 和 Meta 的 AI 倡导者 Suraj Subramanian 共同提出。
一、前言
生成式 AI 对企业最具影响力的应用之一是创建能够访问已有知识库的自然语言接口,换句话说,它能够针对银行、法律和医学等特定领域提供问题解答。目前主要有两种方法可以实现这一点:
-
特定领域微调 (DSF):在代表特定领域知识的文档集上训练现有的基础模型。
-
检索增强生成 (RAG):将文档存储在矢量数据库中,并在查询时根据与问题的语义相似性检索相关文档,并将其纳入大型语言模型的上下文进行情境学习。
本文将探讨这两种方法的局限性,并介绍加州大学伯克利分校研究人员 Tianjun Zhang 和 Shishir G. Patil 提出的 RAFT 方法如何克服这些局限性。该团队以 Gorilla 大型语言模型而闻名,他们在 RAFT 论文中介绍了这种新方法,并展示了如何使用 Meta Llama 2 和 Azure AI Studio 进行研究和实施。
伯克利团队还发表了一篇博客文章,解释了 RAFT 方法的优缺点以及如何产生更有效的结果。RAFT 论文的代码实现可在他们的 Github 代码库中找到。
接下来,我们将介绍 RAFT 方法的工作原理。
二、理解 RAFT 方法
RAFT 是一种将预训练的大型语言模型微调到特定领域 RAG 设置的通用方法。在特定领域 RAG 中,模型需要根据特定领域的一组文档回答问题,例如企业中的私有文件。这与通用 RAG 不同,因为通用 RAG 中的模型并不知道它将在哪个领域进行测试。
为了更好地理解特定领域 RAG,我们可以将其与考试类比。
-
闭卷考试:类比于大型语言模型无法访问任何外部信息来回答问题的情况,例如聊天机器人。在这种情况下,模型只能依靠预训练和微调期间学习到的知识来响应用户的提示。
-
开卷考试:类比于大型语言模型可以参考外部信息来源(例如网站或书籍)的情况。在这种情况下,模型通常会与检索器配对,检索器会检索相关文档并将其附加到用户的提示中。模型只能通过这些检索到的文档获取新知识。因此,模型在开卷考试设置中的性能很大程度上取决于检索器的质量以及检索器识别相关信息的能力。
传统的 RAG 在收到查询时,会从索引中检索一些可能包含答案的文档,并将其作为上下文来生成答案。这就像学生参加开卷考试,可以翻阅教科书寻找答案。相比之下,微调就像闭卷考试,学生只能依靠记忆来回答问题。显然,开卷考试更容易,这也解释了 RAG 的有效性和流行性。
然而,这两种方法都存在局限。微调的模型只能依赖于它所训练的知识,有时可能会出现近似或幻想的问题。RAG 虽然基于文档,但检索到的文档可能只是与查询语义接近,并不一定包含正确答案。这些干扰性文档可能会误导模型,导致生成错误的答案。
为了克服 RAG 的这些缺陷,Tianjun 和 Shishir 提出了一种新的方法:RAFT。他们认为,如果学生在开卷考试前预先学习教科书,就能取得更好的成绩。同样,如果大型语言模型能够事先“学习”文档,就能提高 RAG 的性能。他们提出的检索增强型微调(Retrieval-Augmented Fine Tuning)方法,就是试图让模型在使用 RAG 之前先对特定领域进行学习和适应。
RAFT 专注于一种比通用开卷考试更窄但越来越受欢迎的领域,称为特定领域开卷考试。在这种情况下,我们事先知道模型将要测试的领域,例如企业文档、最新新闻或代码库等。模型可以使用它所微调的特定领域中的所有信息来回答问题。

RAFT 使用 Meta Llama 2 7B 语言模型,首先准备一个合成数据集,其中每个样本包含:
-
一个问题
-
一组参考文档(包括相关文档和干扰性文档)
-
从文档中生成的答案
-
使用思维链解释,包含来自相关文档的摘录(由如 GPT-4 或 Llama 2 70B 这样的通用大语言模型生成)
该数据集用于微调 Llama 2 7B 模型,使其更好地适应特定领域,并学会从检索到的上下文中提取有用的信息。思维链解释可以防止过拟合,提高训练的鲁棒性。
RAFT 介于 RAG 和特定领域微调之间,它既能使大型语言模型学习领域知识和风格,又能提高答案生成的质量。对于像 Llama 2 这样在多个领域训练的预训练模型,RAFT 可以使其更适合医疗保健或法律等专业领域。
三、RAFT 模型评估
为了评估 RAFT 模型的性能,伯克利团队使用了来自不同领域的数据集,包括维基百科、编码/API 文档和医学问答:
-
自然问题 (NQ)、Trivia QA 和 Hotpot QA:基于维基百科的开放域问题,主要集中在常识。
-
HuggingFace、Torch Hub 和 TensorFlow Hub:来自 Gorilla 论文中提出的 APIBench,主要关注如何根据文档生成正确的 API 调用。
-
PubMed QA:专门针对生物医学研究问答的数据集,主要侧重于根据给定文档回答医学和生物学问题。
研究人员还比较了以下基线模型:
-
使用零样本提示的 LlaMA2-7B-chat 模型:这是问答任务中常用的指令微调模型,提供清晰的指令,但不提供参考文档。
-
使用 RAG 的 LlaMA2-7B-chat 模型 (Llama2 + RAG):与前者类似,但添加了参考上下文,是处理特定领域问答任务时最常用的组合。
-
使用零样本提示的特定领域微调 (DSF):在没有参考文档的情况下进行标准指令微调。
-
使用 RAG 的特定领域微调 (DSF + RAG):为特定领域微调模型配备外部知识,使其能够参考上下文来回答未知问题。
下表展示了 RAFT 在医学 (PubMed)、常识 (HotPotQA) 和 API (Gorilla) 基准测试上的结果。

四、Azure AI Studio 微调
伯克利团队使用 Azure AI Studio 中的模型即服务 (MaaS) 对 Meta Llama 2 进行了微调,用于他们的 RAFT 论文。微软学习平台也提供了相关教程,解释如何在 Azure AI Studio 中微调 Llama 2 模型。
过去,微调通常需要机器学习工程师具备丰富的专业知识,包括生成式 AI、Python、机器学习框架、GPU 和云基础设施等。Azure AI Studio 的出现改变了这一现状,它自动化了所有技术细节和基础设施设置,让用户可以专注于数据准备。
以下是训练 RAFT 模型的简短教程,包括数据集准备、模型微调和模型部署。
4.1、数据集准备
我们提供一个示例来准备 RAFT 的数据集。数据集包含问题、上下文和答案。上下文是一组文档,答案是使用思维链风格从其中一个文档生成的,并借助 GPT-4 进行辅助。
- Question: The Oberoi family is part of a hotel company that has a head office in what city?
-
- context: [The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group]...[It is located in city center of Jakarta, near Mega Kuningan, adjacent to the sister JW Marriott Hotel. It is operated by The Ritz-Carlton Hotel Company. The complex has two towers that comprises a hotel and the Airlangga Apartment respectively]...[The Oberoi Group is a hotel company with its head office in Delhi.]
-
- CoT Answer: ##Reason: The document ##begin_quote## The Oberoi family is an Indian family that is famous for its involvement in hotels, namely through The Oberoi Group. ##end_quote## establishes that the Oberoi family is involved in the Oberoi group, and the document ##begin_quote## The Oberoi Group is a hotel company with its head office in Delhi. ##end_quote## establishes the head office of The Oberoi Group. Therefore, the Oberoi family is part of a hotel company whose head office is in Delhi. ##Answer: Delhi
4.2、模型微调
我们将训练模型根据问题和提供的上下文输出思维链答案。基础模型 Llama2-7B 适用于 RAG 任务,因为它具备推理、理解语言、低延迟推理和易于适应不同环境的能力。用户只需打开 AI Studio 的微调向导
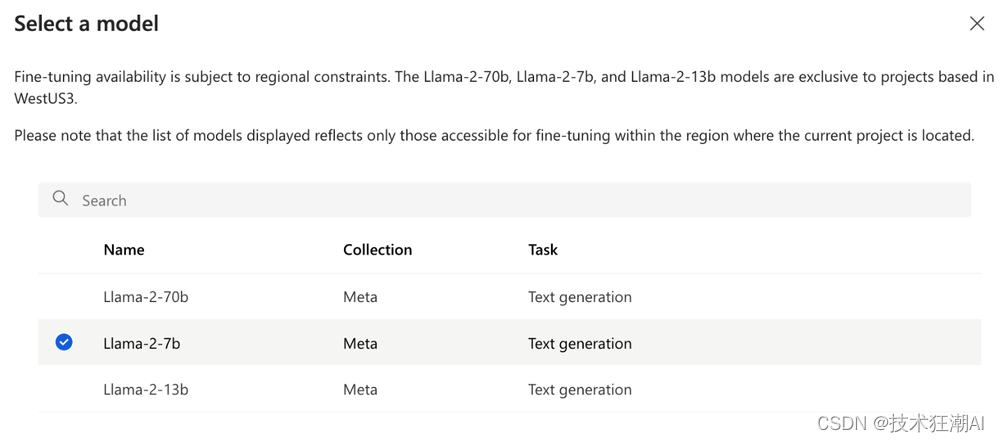
选择要微调的模型
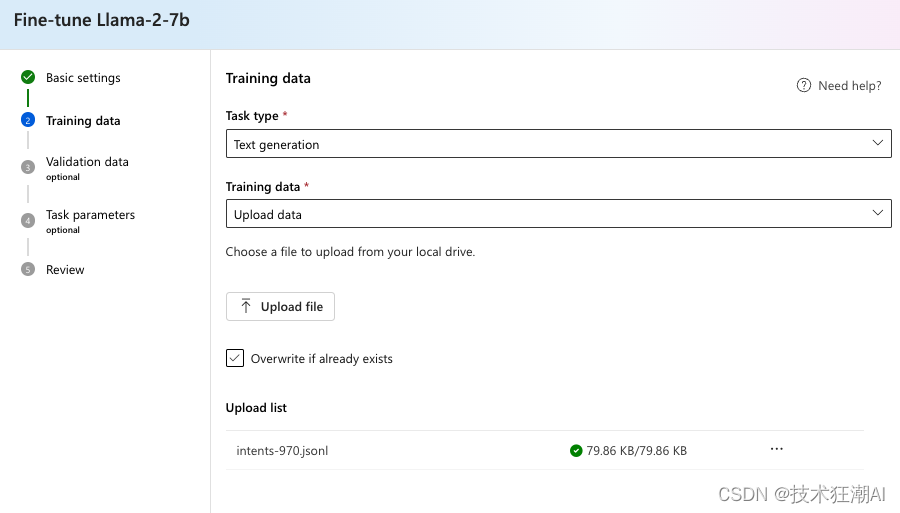
选择上传数据选项并上传您的训练数据集,它必须是 JSONL 格式
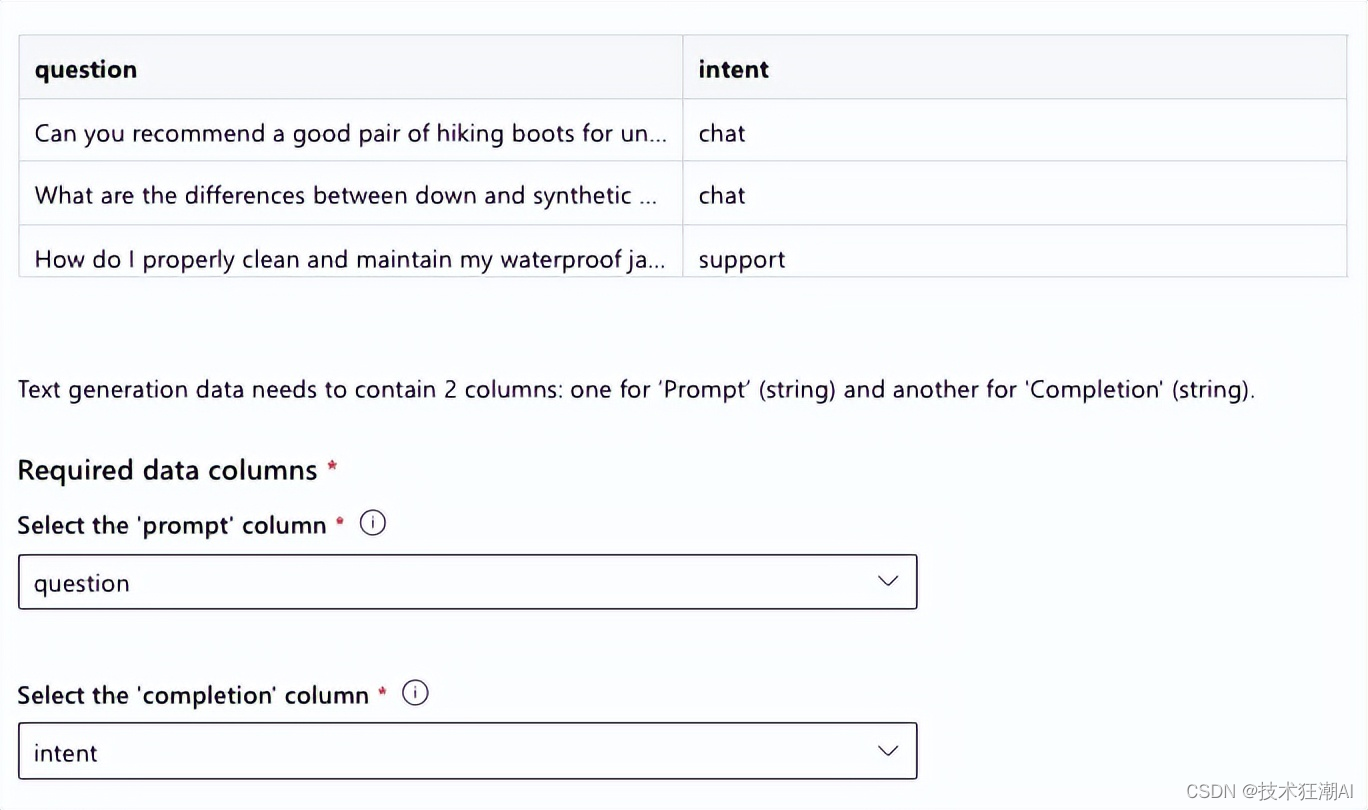
并指定提示和完成所在的列
最后设置批量大小乘数、学习率和训练轮数即可。
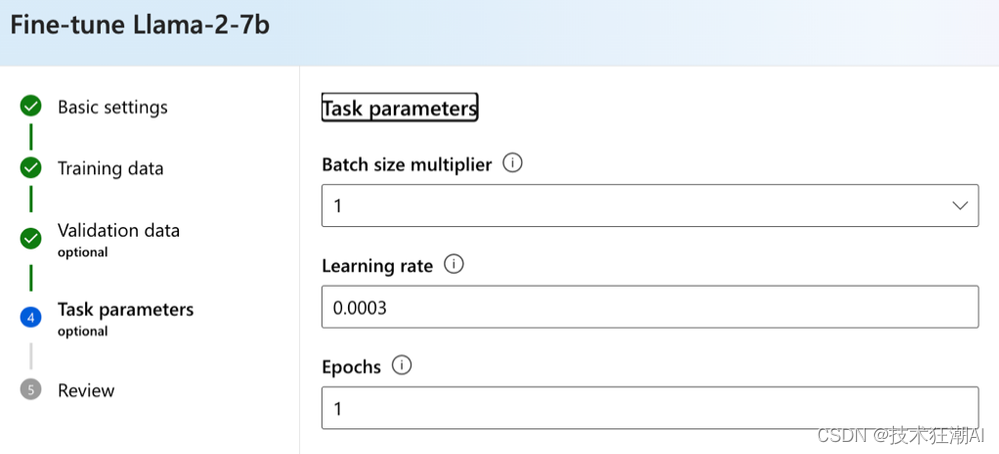
对于这些参数,Tianjun 和 Shishir 建议:
-
对于微调,使用乘数 1,学习率 0.00002 和训练轮数 1。
4.3、模型部署
训练模型后,您可以将其部署在您自己的 GPU 或 CPU 上,也可以将其部署在微软 AI Studio 上。
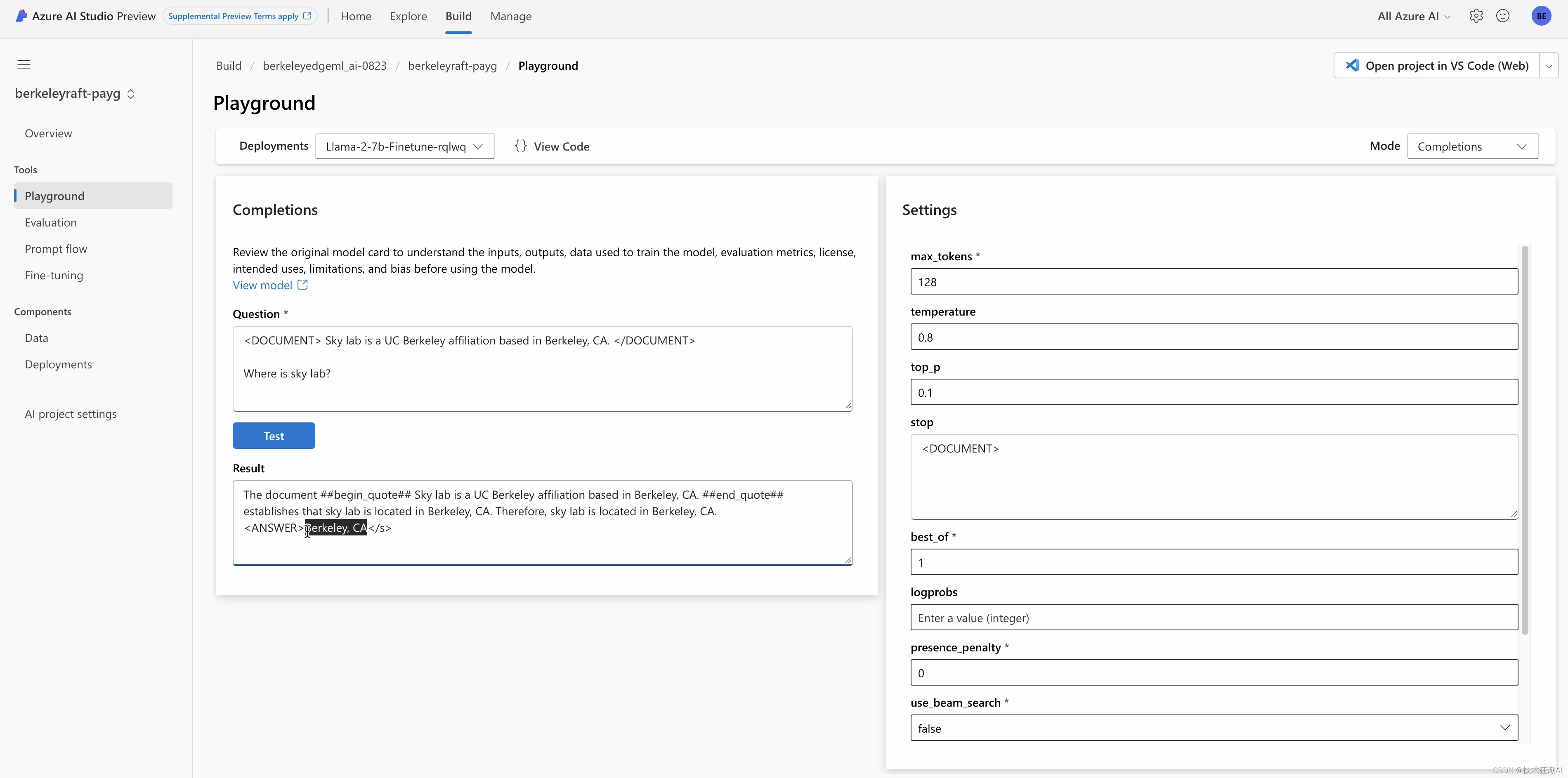
AI Studio 极大地降低了大型语言模型微调的门槛,让开发人员和企业可以更轻松地调整模型以适应特定领域的任务。这将推动定制模型在不同企业中的应用,促进生成式 AI 和大型语言模型的普及。
五、RAFT 团队答疑
Cedric 和 Suraj 就 RAFT 的相关问题采访了 Tianjun 和 Shishir。
问:为什么选择 Llama 2 7B?
答:因为我们专注于 RAG 任务,这类任务需要模型具备推理、理解语言、低延迟推理和易于适应不同环境的能力。Llama 2 7B 恰好满足这些要求,它是许多常识性问答任务的良好基础模型,具有优秀的数学能力,并且能够解析较长的文档。同时,它也适合在 4 个 A100-40G GPU 上训练并在单个 GPU 上部署。综合考虑性能、易部署性和许可证等因素,Llama 2 模型非常适合 RAFT 任务。我们也希望借助微软 AI Studio 探索 Llama 2 13b 或 70b 的潜力。
问:对于尝试微调 Llama 的人,您有什么建议?
答:微调 Llama 是一项复杂的任务,涉及数据收集、数据清理和实际微调。我们建议收集与目标领域相关的多样化问题,并构建思维链答案。存储中间检查点可以帮助提前停止训练。此外,微调的学习率应该比预训练的学习率低至少一个数量级。其他最佳实践包括使用 16 位精度、训练不超过 3 个 epoch,以及使用大批量大小。
问:微调应该应用于每个领域吗?
答:微调模型的知识学习依赖于特定领域,但其行为在一定程度上可以泛化到其他领域。这涉及到准确性和泛化性之间的权衡。通常,针对特定领域进行微调是比较好的做法,但如果企业文档集有限,针对这些文档进行微调可能会获得更好的性能,因为知识范围更集中。
问:您对 Azure AI Studio 微调系统有何看法?
答:Azure AI 微调系统非常用户友好,从训练数据上传到超参数选择,再到部署训练好的模型,一切都非常简单易用。
问:AI Studio 微调有什么优势?
答:最大的优势是用户无需担心 GPU、训练平台和模型部署等问题,只需一键操作即可完成,而且性能出色!
问:您认为 AI Studio 微调可以改进什么?
答:作为研究人员,我们希望开发者能够提供更多关于系统内部微调配方的细节,例如它是使用低秩近似微调还是全参数微调,使用了多少个 GPU,以及 LoRA 的超参数设置等等。
问:您认为 AI Studio 微调会给行业带来什么变化?
答:它可以使企业轻松进行大型语言模型的微调和部署,极大地促进定制模型在不同企业中的应用。
六、结论
Llama 和 Azure 通过提供易于使用的平台,使开发人员和企业能够创建针对特定需求和挑战的创新解决方案,推动了特定领域 AI 开发的新范式。这将使更多人受益于生成式 AI 和大型语言模型的最新进展,构建更加多样化和包容的 AI 生态系统。(注: AI Studio 微调目前在美国西部 3 可用)
七、References
[1]. Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez, R. (2024). RAFT: Adapting Language Model to Domain Specific RAG: https://arxiv.org/pdf/2401.08406.pdf
[2]. Gorilla LLM https://github.com/ShishirPatil/gorilla
[3]. Meta Llama 2 https://llama.meta.com/
[4]. Azure AI Studio https://ai.azure.com/
[5]. RAFT Github Repo: https://github.com/ShishirPatil/gorilla/tree/main/raft
[6]. Fine-tune a Llama 2 model in Azure AI Studio: https://learn.microsoft.com/en-us/azure/ai-studio/how-to/fine-tune-model-llama
[7]. MS Learn https://learn.microsoft.com/
[8]. RAFT: Adapting Language Model to Domain Specific RAG: https://gorilla.cs.berkeley.edu/blogs/9_raft.html

