
- 1ICRA 2021 Paper List_icra2021
- 22023年网络安全HW攻防技术总结(珍藏版)_hw攻击队
- 36-闭包和装饰器_带参数的装饰器。定义一个没有参数的函数foo,用于输出语句;定义一个装饰器函
- 4Oracle的rollup、cube、grouping sets函数
- 5使用 Python 指纹识别远程操作系统_python 通过ip地址获取指纹打卡机的数据的方法
- 6PyTorch源码解读之torchvision.transforms_pytorch_android_torchvision源码
- 7SylixOS动态加载器系列文章(6) C++支持_exidx段
- 8在主引导程序中打印字符串,读取软盘数据_可引导asm程序读取软盘
- 9python正则表达式
- 10Arduino ESP32 flash数据存储结构_esp32使用flash存储
自然语言处理之Textcnn
赞
踩
一、 模型原理
- Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence
Classification提出TextCNN。 - 将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
网络结构图如下:

详细原理图:(出自论文:A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification)

TextCNN详细过程:
-
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点(word embedding的维度是5,对于句子 i like this movie very muc,转换成7×5的矩阵;
-
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出channel(有6个卷积核,尺寸为(2×5), (3×5), (4×5),每种尺寸各2个,embedding的结果分别与以上卷积核进行卷积操作(这里的Stride Size相当于等于高度h))
-
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
-
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
1. 嵌入层(embedding layer)
- textcnn使用预先训练好的词向量作embedding layer。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩MM,MM里的每一行都是词向量。这个MM可以是静态(static)的,也就是固定不变。可以是非静态(non-static)的,也就是可以根据反向传播更新。
- 多种模型:Convolutional Neural Networks for Sentence Classification文章中给出了几种模型,其实这里基本都是针对Embedding layer做的变化。
CNN-rand
- 作为一个基础模型,Embedding layer所有words被随机初始化,然后模型整体进行训练。
CNN-static
- 模型使用预训练的word2vec初始化Embedding
layer,对于那些在预训练的word2vec没有的单词,随机初始化。然后固定Embedding layer,fine-tune整个网络。
CNN-non-static
-
同(2),只是训练的时候,Embedding layer跟随整个网络一起训练。 CNN-multichannel
-
Embedding layer有两个channel,一个channel为static,一个为non-static。然后整个网络fine-tune时只有一个channel更新参数。两个channel都是使用预训练的word2vec初始化的。
2. 卷积池化层(convolution and pooling)
卷积(convolution)
- 输入一个句子,首先对这个句子进行切词,假设有s个单词。对每个词,跟句嵌入矩阵M, 可以得到词向量。假设词向量一共有d维。那么对于这个句子,便可以得到s行d列的矩阵AϵRs×d.
- 我们可以把矩阵A看成是一幅图像,使用卷积神经网络去提取特征。由于句子中相邻的单词关联性总是很高的,因此可以使用一维卷积,即文本卷积与图像卷积的不同之处在于只在文本序列的一个方向(垂直)做卷积,卷积核的宽度固定为词向量的维度d。高度是超参数,可以设置。对句子单词每个可能的窗口做卷积操作得到特征图(feature map) c = [c_1, c_2, …, c_s-h+1]。
- 现在假设有一个卷积核,是一个宽度为d,高度为h的矩阵w,那么w有h∗d个参数需要被更新。对于一个句子,经过嵌入层之后可以得到矩阵AϵRs×d。
A[i:j]表示A的第i行到第j行, 那么卷积操作可以用如下公式表示: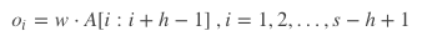
叠加上偏置b,在使用激活函数f激活, 得到所需的特征。公式如下:
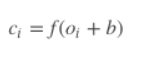
对一个卷积核,可以得到特征cϵRs−h+1, 总共s−h+1个特征。我们可以使用更多高度h不同的卷积核,得到更丰富的特征表达。
Note: TextCNN网络包括很多不同窗口大小的卷积核,常用的filter size ∈ {3,4,5},每个filter的feature maps=100。
池化(pooling)
- 不同尺寸的卷积核得到的特征(feature map)大小也是不一样的,因此我们对每个feature map使用池化函数,使它们的维度相同。最常用的就是1-max pooling,提取出feature map照片那个的最大值,通过选择每个feature map的最大值,可捕获其最重要的特征。这样每一个卷积核得到特征就是一个值,对所有卷积核使用1-max pooling,再级联起来,可以得到最终的特征向量,这个特征向量再输入softmax layer做分类。这个地方可以使用dropout防止过拟合。

- CNN中采用Max Pooling操作有几个好处:首先,这个操作可以保证特征的位置与旋转不变性,因为不论这个强特征在哪个位置出现,都会不考虑其出现位置而能把它提出来。但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等等。
- 其次,MaxPooling能减少模型参数数量,有利于减少模型过拟合问题。因为经过Pooling操作后,往往把2D或者1D的数组转换为单一数值,这样对于后续的Convolution层或者全联接隐层来说无疑单个Filter的参数或者隐层神经元个数就减少了。
- 再者,对于NLP任务来说,可以把变长的输入X整理成固定长度的输入。因为CNN最后往往会接全联接层,而其神经元个数是需要事先定好的,如果输入是不定长的那么很难设计网络结构。
- 但是,CNN模型采取MaxPooling Over Time也有缺点:首先特征的位置信息在这一步骤完全丢失。在卷积层其实是保留了特征的位置信息的,但是通过取唯一的最大值,现在在Pooling层只知道这个最大值是多少,但是其出现位置信息并没有保留;另外一个明显的缺点是:有时候有些强特征会出现多次,出现次数越多说明这个特征越强,但是因为Max Pooling只保留一个最大值,就是说同一特征的强度信息丢失了。
pooling的几个改进:
- K-MaxPooling:取所有特征值中得分在Top –K的值,并保留这些特征值原始的先后顺序,即多保留一些特征信息供后续阶段使用。

- Chunk-MaxPooling:把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。因为是先划分Chunk再分别取Max值的,所以保留了比较粗粒度的模糊的位置信息;当然,如果多次出现强特征,则也可以捕获特征强度。至于这个Chunk怎么划分,可以有不同的做法,比如可以事先设定好段落个数,这是一种静态划分Chunk的思路;也可以根据输入的不同动态地划分Chunk间的边界位置,可以称之为动态Chunk-Max方法。Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks这篇论文提出的是一种ChunkPooling的变体,就是动态Chunk-Max Pooling的思路,实验证明性能有提升。Local Translation Prediction with Global Sentence Representation 这篇论文也用实验证明了静态Chunk-Max性能相对MaxPooling Over Time方法在机器翻译应用中对应用效果有提升。
- K-Max Pooling是一种全局取Top K特征的操作方式,而Chunk-Max Pooling则是先分段,在分段内包含特征数据里面取最大值,所以其实是一种局部Top K的特征抽取方式。
最后上模型代码
# -*- coding: utf-8 -*- import torch import torch.nn as nn import torch.nn.functional as F class TextCNN(nn.Module): def __init__(self, args): super(TextCNN, self).__init__() self.args = args label_num = args.label_num # 标签的个数 filter_num = args.filter_num # 卷积核的个数 filter_sizes = [int(fsz) for fsz in args.filter_sizes.split(',')] vocab_size = args.vocab_size embedding_dim = args.embedding_dim self.embedding = nn.Embedding(vocab_size, embedding_dim) if args.static: # 如果使用预训练词向量,则提前加载,当不需要微调时设置freeze为True self.embedding = self.embedding.from_pretrained(args.vectors, freeze=not args.fine_tune) self.convs = nn.ModuleList( [nn.Conv2d(1, filter_num, (fsz, embedding_dim)) for fsz in filter_sizes]) self.dropout = nn.Dropout(args.dropout) self.linear = nn.Linear(len(filter_sizes)*filter_num, label_num) def forward(self, x): # 输入x的维度为(batch_size, max_len), max_len可以通过torchtext设置或自动获取为训练样本的最大=长度 x = self.embedding(x) # 经过embedding,x的维度为(batch_size, max_len, embedding_dim) # 经过view函数x的维度变为(batch_size, input_chanel=1, w=max_len, h=embedding_dim) x = x.view(x.size(0), 1, x.size(1), self.args.embedding_dim) # 经过卷积运算,x中每个运算结果维度为(batch_size, out_chanel, w, h=1) x = [F.relu(conv(x)) for conv in self.convs] # 经过最大池化层,维度变为(batch_size, out_chanel, w=1, h=1) x = [F.max_pool2d(input=x_item, kernel_size=(x_item.size(2), x_item.size(3))) for x_item in x] # 将不同卷积核运算结果维度(batch,out_chanel,w,h=1)展平为(batch, outchanel*w*h) x = [x_item.view(x_item.size(0), -1) for x_item in x] # 将不同卷积核提取的特征组合起来,维度变为(batch, sum:outchanel*w*h) x = torch.cat(x, 1) # dropout层 x = self.dropout(x) # 全连接层 logits = self.linear(x) return logits # forward的另外一种写法 # x = self.embedding(x) # x = x.unsqueeze(1) # x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] # x = [F.max_pool1d(item, item.size(2)).squeeze(2) for item in x] # x = torch.cat(x, 1) # x = self.dropout(x) # logits = self.fc(x) # return logits

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- texcnn全名 ...
赞
踩

