
- 1springboot项目中引入本地依赖jar包,如何打包到lib文件夹中_springboot引入lib包
- 2神经网络入门(二):多层感知机和BP迭代算法_多层感知机如何更新是不是用bp更新的思想
- 3数据结构:详解【链表】的实现(单向链表+双向链表)
- 4uni-app跨平台开发_uniapp开发安卓app可以用vue开发吗
- 5vue同一浏览器登录不同账号,覆盖token的解决办法_前端单点登录进入一个页面时如果这个页面之前有别的号的token怎么办
- 6Android res文件夹下新建layout文件夹出错:invalid resource directory name
- 7电商项目中的经典问题_电商项目的bug
- 8使用ELK收集解析nginx日志和kibana可视化仪表盘_elk nginx
- 9【精通内核】计算机程序的本质、内存组成与ELF格式深度解析_elf结构和进程内存结构
- 1020.2 二维数组_定义一个二维数组$data,20个元素,每个元素是一个小数组,3个元素,小数组分别用于保
PyTorch深度学习实战 | 基于RNN的文本分类_基于rnn的文本意图分类系统
赞
踩

PyTorch是当前主流深度学习框架之一,其设计追求最少的封装、最直观的设计,其简洁优美的特性使得PyTorch代码更易理解,对新手非常友好。
本文为实战篇,介绍基于RNN的文本分类!
本文将构建和训练基本的字符级RNN(递归神经网络)来对单词进行分类。展示如何“从头开始”进行NLP(自然语言处理)建模的预处理数据,尤其是不使用众多NLP工具库提供的许多便利功能,因此读者可以从系统层面角度了解NLP建模的预处理工作。
字符级RNN将单词作为一系列字符读取,之后在每个步骤输出一个预测结果和“Hidden State”,将其先前的Hidden State输入每个下一步。这里将最终的预测作为输出,即单词属于哪个类别。
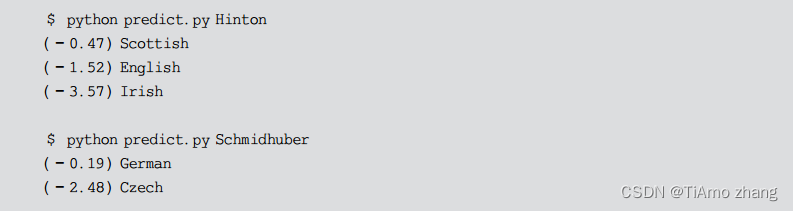
具体来说,这里将训练来自18种起源于不同语言的数千种姓氏,并根据拼写方式预测名称的来源,样例如下。
1、数据准备
数据下载超链接:https://download.pytorch.org/tutorial/data.zip。
解压缩上述数据得到18个txt文件,将它们放置在data/names目录下。下面提供一段代码做预处理。

上述代码输出如下。

2、将名字转换为张量
现在已经整理好了所有数据集中的名字,这里需要将它们转换为张量以使用它们。为了表示单个字母,这里使用大小为<1×n_letters>的“one-hot”向量。一个one-hot向量用0填充,但当前字母的索引处的数字为1,例如 “ b”=<0 1 0 0 0 …>。为了用这些向量组成一个单词,这里将其中的一些连接成2维矩阵<line_length × 1 × n_letters>。
可以观察到数据的维度是<line_length×1×n_letters>,而不是<line_length×n_letters>,是因为额外的1维是因为PyTorch假设所有内容都是批量的——在这里只使用1的batchsize。
代码如下。

输出如下。

3、构建神经网络
在PyTorch中构建递归神经网络(RNN)涉及在多个时间步长上克隆多个RNN层的参数。RNN层保留了Hidden State和梯度,这些状态完全由PyTorch的计算图来自动完成维护。这意味着读者可以以非常“纯粹”的方式实现RNN,即只关心前馈网络(Feed-forward Network)而不需要关注反向传播(Back Propagation)。
下面样例中的RNN模块只有两个线性层,它接受一个输入和一个Hidden State,之后网络输出结果需要经过一个LogSoftmax层。RNN模型如图1所示。
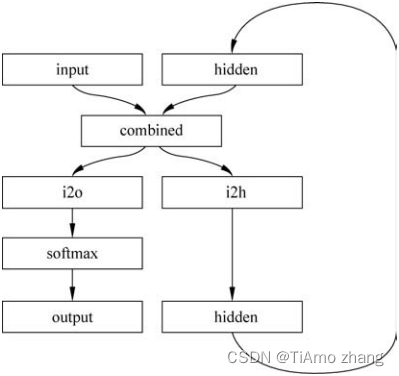
■ 图1 RNN模型
RNN代码定义如下。


要运行此网络,需要传递输入(在本例中为当前字母的Tensor)和先前的Hidden State(首先将其初始化为零)。这里将返回输出(每种语言的概率)和下一个Hidden State(将其保留用于下一步)。

为了提高效率,这里不想为每个步骤都创建一个新的Tensor,因此将使用lineToTensor代替letterToTensor并使用切片。这可以通过预先计算一批(Batch)张量来进一步优化。

可以看到,输出为<1×n_categories>张量,其中每个项目都是该类别的可能性(更高的可能性更大)。


