
- 1系统的安全以及强行破解密码的手法_auth sufficient
- 2CVPR2021 视频目标检测论文推荐_视频目标检测顶刊论文
- 3Linux的三种配置 IP方法_linux配置ip地址
- 4ChatGPT接口使用及计费策略简述_chatgpt token如何计费
- 5textRank4zh抽取关键词,中文摘要生成_textrank4keyword
- 6thinkphp5——控制器与请求_thinkphp5请求和控制器名字不对应
- 7如何使用Python进行自然语言处理_用python做nlp
- 8python拼写_用 Python 27 行实现拼写纠正
- 9全闪存储技术市场新洞察_nof高速互联 全闪/混闪 存储系统 应用行业
- 10python中类的继承与扩展、私有方法和属性,以及forward()函数_pythonz中的对象后面括号,为什么直接调用forward
BERT句向量(一):Sentence-BERT
赞
踩
前言
句向量:能够表征整个句子语义的向量,目前效果比较好的方法还是通过bert模型结构来实现,也是本文的主题。
有了句向量,我们可以用来进行聚类,处理大规模的文本相似度比较,或者基于语义搜索的信息检索。
例如搜索系统中的输入query和匹配文档document、Q&A任务的问题和答案等等,都可以转化为计算两个句子的语义相似/相关度,相关度最高的n个作为模型的返回结果。
题外话
这种类似的模型一般称为passage retrieval models,即段落检索,有两个代表:
- sparse models:BM25、TF-IDF等;
- dense models(DPR,Dense Passage Retrieval):将query和doc(question和passage/answer)都转化为稠密向量,然后通过faiss等工具进行相关召回。
原生Bert
原生的BERT模型在诸多句子分类和句子对的回归任务上都取得了state-of-the-art的表现,它使用一种 cross-encoder的结构:将两个句子拼接输入到模型,经过带有self attention的transformer网络得到最终的预测值。
但这种做法不适用于大量句子对的回归任务,例如给定10000个句子,找出每个句子最相似的句子,那么每个句子就得需要与其他所有句子进行两两组合,才能得到与所有句子的相似度,即需要进行n*(n-1)/2= 49995000次的推理计算,这显然是不合理的。
这其实与推荐场景类似,采用这种结构的话,query需要与所有的doc进行分别计算,才能分数相关度最高的doc,这是不现实。所以这种做法一般是放在后面的排序阶段。
而在此之前,一般会先经过召回阶段,则是需要事先将所有doc输入到bert模型,提取出句向量进行存储,实际使用时,实时计算query的句向量,然后通过faiss等ann工具,来从所有doc中召回相关度最高的n个。
因此,sentence-bert此时就派上用场,它使得bert模型能够提取表征句子语义的句向量。
Sentence-BERT
相关论文:《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》
pooling strategies
其实原生bert模型本身是具备句向量提取的能力,一般是以下3种方法,sentence-bert也是采用相同的方法:
- CLS:使用[CLS]字符最后一层的输出向量,作为句向量;
- MEAN:使用句子的所有字符的最后一层输出向量,计算它们的均值,作为句向量;
- MAX:使用句子的所有字符的最后一层输出向量,所有字符向量对应位置提取最大值,作为句向量。
但是,如果**直接使用原生bert模型来提取句向量,效果十分不理想,甚至不如GloVe提取的句向量。**
fine-tune
所以,作者提出一种针对句向量,对bert模型进行微调的方法,包括无监督和监督训练。

fine-tune的三种结构:
1. Classification Objective Function
如图1的分类结构,句子A和句子B输入到同个bert模型(参数绑定),然后使用[CLS]向量或者所有字符的向量均值得到A的句向量u、B的句向量v,然后拼接u、v和 element-wise的 |u-v|,最后通过softmax做一个k分类,loss为cross-entropy;
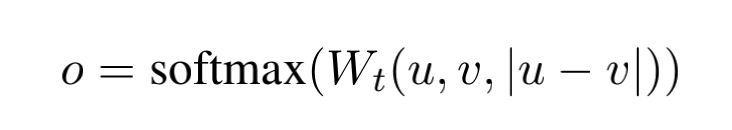
2. Regression Objective Function
如图2的回归结构,同样的方法得到u和v, 再经过cosine函数得到u和v的相似度,使用MSE( mean-squared-error)作为loss;
3. Triplet Objective Function
最后一种为三元组结构,如下式,句子a和p为负例,a和n为正例, s a s_a sa为句子a的句向量,方法同上。这个结构是让负例句子的距离要尽量比正例的大
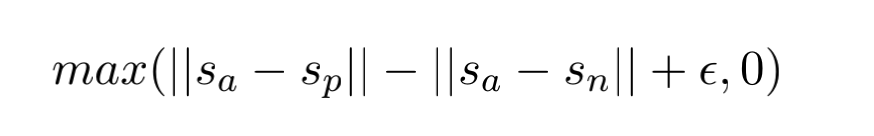
其中|| · ||是距离度量,例如欧式距离,
ξ \xi ξ为 margin ,控制负例和正例句子的距离差最小为 ξ \xi ξ
inference
推理阶段,按照上图2的做法,两个句子u和v输入到Sentence-BERT结构微调后的模型,选择一种pooling策略,得到句子的向量,然后使用cosine函数来计算两个句子的相似/相关度。
无监督训练
作者使用 SNLI(Bowman et al., 2015) 和Multi-Genre NLI(Williams et al., 2018)两个公开的数据集,带有三种标签contradiction、eintailment、neutral的句子对。
使用Classifification Objective Function来对bert模型进行微调,详细参数为:batch_size为16、Adam optimizer、2e-5的学习率、10%的线性学习率warmup,采用MEAN的pooling策略。
然后在STS数据集上进行验证,由于未使用到目标数据集,因此可以认为是无监督训练,具体效果如下:
( STS12-STS16:SemEval 2012-2016, STSb: STSbenchmark, SICK-R: SICK relatedness dataset,这些数据集带有0-5级的相关程度)
明显看出微调后的sentence-bert比原生bert的句向量效果提升了许多,并且使用RoBERTa可以进一步提升效果。
(作者也是做了实验,才得出原生bert句向量甚至不如GloVe的结论)

监督训练
上面提到,STS数据的标签是0-5级的相关程度,作者使用了regression objective function的结构进行微调SBERT。
实验了两种监督训练方案:
- 仅使用STSb数据进行监督训练;
- 先在NLI数据进行训练,然后再使用STSb数据
结果如下:
监督训练比无监督训练效果进一步提升,并且BERT的模型大小影响较大,BERT-large比base提升3-4点;
但使用RoBERTa未没有明显的效果提升。

代码实现
tensorflow1.x:github
pytorch推荐使用:Sentence-Transformers

