
图解BERT、ELMo(NLP中的迁移学习)| The Illustrated BERT, ELMo, and co._图解bert, elmo, and co.
赞
踩
看我看我
这是我翻译这位大佬的第三篇文章了,我的翻译结束,翻译授权见最后。
之前的工作:
- 图解transformer | The Illustrated Transformer
- 图解GPT-2 | The Illustrated GPT-2 (Visualizing Transformer Language Models)
这部分内容为我主观注释,和原作无关。
正文
2018年是NLP模型发展的转折点。我们不断探索单词和句子的表示方法,以求能最好地捕捉其中潜在的语义和关系。此外,NLP领域已经提出了一些功能强大的组件式模型,你可以免费下载,并在自己的模型和pipeline中使用它们(这被称为NLP领域的ImageNet时刻,类似的发展在几年前,计算机视觉领域的机器学习也是这样加速发展起来的)。
我来解释一下:
在CV(Computer Vision)领域,预训练+微调已经应用很久了。他们有在ImageNet上训练好的模型可以直接拿去用。但是在NLP(Natural Language Processing)领域并没有像ImageNet那样大的带标签的数据集,因此NLP领域迟迟没有大型预训模型,还是停留在比较低层次的研究上。
GPT的出现让研究人员看到了曙光,我们使用无标签数据也能做出大模型用于微调。从原来的静态词向量到Transformer的动态词向量,再到使用无标签数据预训练模型并用于微调,简直是开创性的工作。同年又涌现出了BERT。所以那一年真的是开辟了NLP领域工作的新时代。
在后边本文的作者会说“BERT被认为是NLP新时代的开始”,我不是很同意这个说法,我认为GPT是新时代的开始。

Cookie Monster是芝麻街里边一个吃饼干的蓝色小怪兽。BERT是芝麻街里另一个黄色的角色。

在这一发展过程中,最新的里程碑工作之一是BERT。BERT被认为标志着NLP新时代的开始 。BERT模型在自然语言处理任务方面打破了多项记录。
BERT论文发布不久之后代码就开源了,还有已经在大型数据集上预训练好的模型可供直接下载。
这是一个重大的发展,BERT模型可以作为一个即插即用的组件,任何人都可以借助它建立一个NLP模型, 从而节省了从头开始训练模型所需的时间、精力、知识和资源。
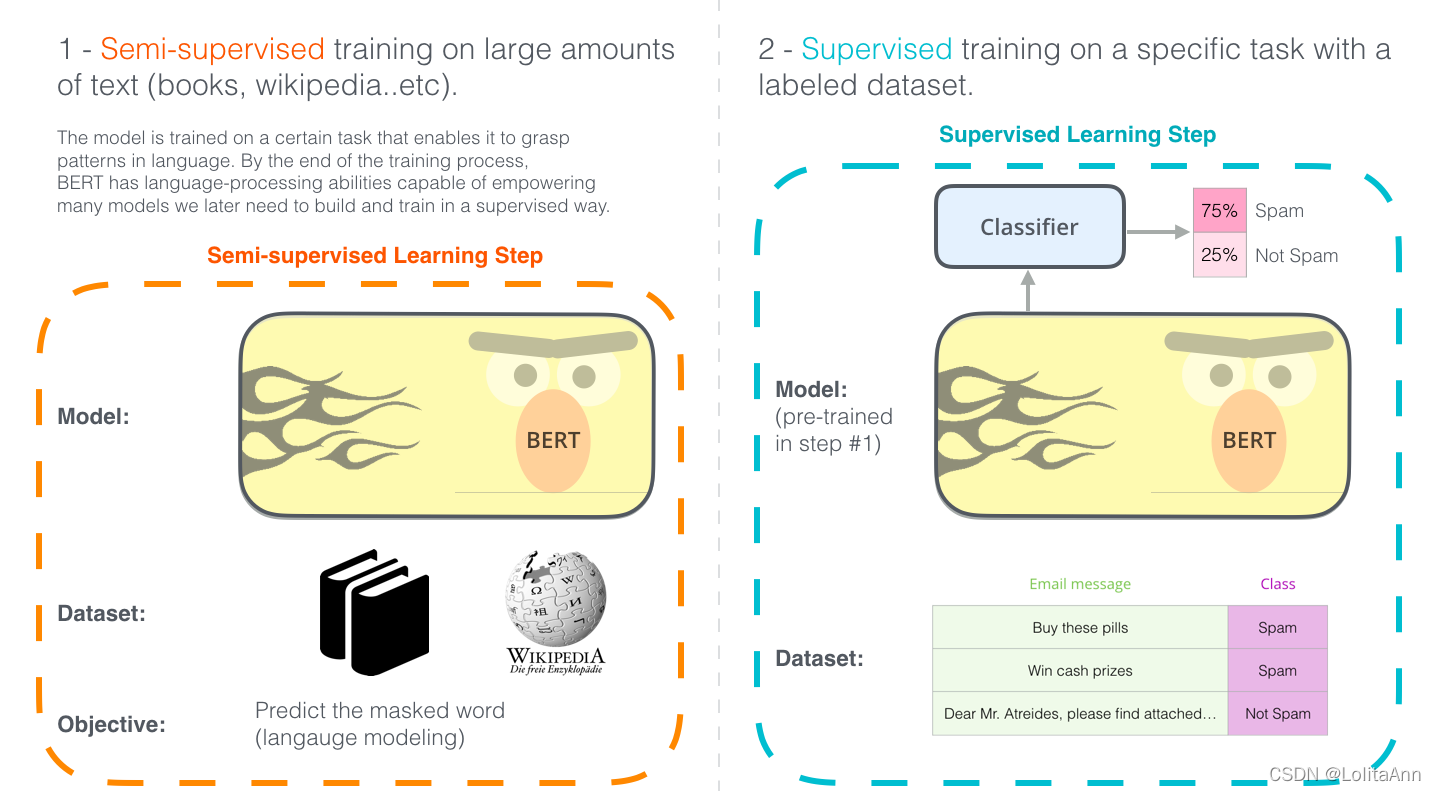
使用BERT的两个步骤:下载在步骤1中已经在无标签数据上预训练好的模型,只需要考虑步骤2的的微调。
BERT 是建立在近期NLP领域中涌现的许多聪明想法之上的,包括但不限于半监督学习、ELMo、ULMFiT、GPT 和Transformer。
为了正确理解BERT是什么,我们需要了解许多概念。先不去看这些概念,让我们先看看BERT的使用方法。
举个声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/354118
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

