
- 1Armbian-安装cpus_armbian安装cups
- 22022数学建模国赛C题-古代玻璃制品的成分分析与鉴别-分析结果和代码_2022国赛c题优秀论文
- 3一文了解语音合成技术(TTS)_tts技术
- 4antd upLoad 受控fileList_antd upload filelist
- 5【无标题】XCode 版本12以上 模拟器调试失败_showing recent messages undefined symbol: _objc_cl
- 6算法50:动态规划专练(力扣514题:自由之路-----4种写法)
- 7LeetCode-热题100:74. 搜索二维矩阵
- 8AI大语音(四)——MFCC特征提取(深度解析)_语音特征提取 mfcc
- 9加载bert-base-uncased预训练模型
- 10深度学习作业——使用长短期记忆网络进行中文分词(基于jieba和Pytorch)_outputs = self.output(hn[-1])
命名实体识别实战(BERT)_bert模型输出的eval_results是什么意思
赞
踩
一、背景
本实例是当时参加第八届泰迪杯数据挖掘挑战赛C题的一部分,该赛题是智慧政务方面的,主要是根据群众的留言来了解民意

第二问是挖掘热点问题,为了先识别出问题发生的地点,涉及的任务以及问题本身,我们先对留言做了命名实体识别以支撑后续对热点问题的挖掘

所给的数据如下

下面我们要做的就是对留言主题和留言详情中的数据进行命名实体识别。
整个项目的代码如下:
链接:https://pan.baidu.com/s/1sFnYvIYuEx6CtNXrL9rYYQ
提取码:2sdk
二、数据预处理
首先需要构建训练需要的训练集,训练集是tmp目录下的source.txt和target.txt,另外验证集为dev.txt,dev-lable.txt,测试集为test1.txt,test_tgt.txt

其中source.txt为训练集中文如下:

target.txt为训练集的label如下:

这两个文件是对应的,label的标签如下,其中共设置了10个类别,PAD是当句子长度未达到max_seq_length时,补充0的类别,CLS是每个句首前加一个标志[CLS]的类别,SEP是句尾同理

在这里我们的目的是使用训练好的模型对上面所提到的excel数据进行预测,所以需要将数据处理成类似训练集的格式才能使用模型进行预测。
在data_process文件夹下的create_train_data.py将excel数据处理成相应格式

这里将留言主题和留言详情进行连接,然后将留言按照每两个字间隔一个空格的格式写入test1.txt中,test_tgt.txt是留言对应的标签,因为这就是我们想要得到的,而缺少这个文件模型不能正常运行,所以将标签都设置为O,数目与留言的字数对应即可
import pandas as pd from sklearn.model_selection import train_test_split data = pd.read_excel("附件3.xlsx",usecols=[5, 4],) data1 = pd.read_excel("附件3.xlsx",usecols=[2],) #将留言主题和留言详情合并 for i in range(len(data.留言详情)): data.留言详情[i]=''.join(data1.留言主题[i].split())+'。'+''.join(data.留言详情[i].split()) with open('test_tgt.txt',"w",encoding = "utf8") as f1: with open("test1.txt","w",encoding = "utf8") as f: for i in data.留言详情: for j in range(0,len(i)-1): f1.write("O ") f.write(i[j]+" ") f1.write("O\n") f.write(i[len(i)-1]+"\n")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
处理后的数据


三、训练模型
首先需要下载BERT的中文预训练模型,这里我的项目代码里已经包括,无需再进行下载。
代码的整体框架是这样的,我将训练和预测的入口都写成了个两个脚本文件,分别为run.sh和predict.sh,只需要在这两个文件中进行配置后运行即可

下面看一下这两个配置文件:
run.sh
首先指定BERT预训练模型所在的目录,然后是训练数据所在的目录即tmp,因为是训练所以设置do_train为true,后面是将模型输出到BERT预训练模型的目录中
export BERT_BASE_DIR=chinese_L-12_H-768_A-12
export NER_DIR=tmp
python run_NER.py \--task_name=NER \--do_train=true \--do_eval=true \--data_dir=$NER_DIR/ \--vocab_file=$BERT_BASE_DIR/vocab.txt \--bert_config_file=$BERT_BASE_DIR/bert_config.json \--learning_rate=2e-5 \--train_batch_size=32 \--num_train_epochs=3 \--output_dir=$BERT_BASE_DIR/output \--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \--max_seq_length=256 \
- 1
- 2
- 3
predict.sh
与训练不同的是不设置do_train并设置do_predict为true即可使用训练的模型对测试集进行预测并输出到BERT预训练模型目录下的output中
export BERT_BASE_DIR=chinese_L-12_H-768_A-12
export NER_DIR=tmp
python run_NER.py \--task_name=NER \--do_eval=true \--do_predict=true \--data_dir=$NER_DIR/ \--vocab_file=$BERT_BASE_DIR/vocab.txt \--bert_config_file=$BERT_BASE_DIR/bert_config.json \--learning_rate=2e-5 \--train_batch_size=32 \--num_train_epochs=3 \--output_dir=$BERT_BASE_DIR/output \--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \--max_seq_length=512 \
- 1
- 2
- 3
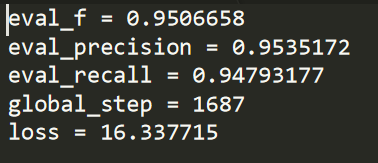
其中test_prediction.txt即对我们的测试集进行预测得到的标签,eval_results.txt为对模型的评估结果

首先看一下test_prediction.txt:

eval_results.txt:可以看出模型的结果是很不错的
四、对预测结果进行转换
上面得到的test_prediction.txt只是测试集的标签,但是并没有将其转换为中文,所以我们需要使用一段代码对其进行转换。
在data_process目录下的process_predict.py中实现了转换功能。

# 将测试集与预测出的标签分别读到a和b中 with open("../tmp/test1.txt",encoding="utf8") as f1: a = [] b = [] with open("../chinese_L-12_H-768_A-12/output/test_prediction.txt") as f: for line in f1: a.append(line.split(" ")) for line in f: b.append(line.split(" ")) # 根据[SEP]对每一行的实体进行识别,并存入all中 all = [] for i in range(0,len(a)): tmp = [] string = "" for j in range(0,len(a[i])): print(j) if b[i][j+1] != "O" and b[i][j+2] == "[SEP]\n": string = string+a[i][j] tmp.append(string) #all.append(tmp) string = "" break elif b[i][j+1] != "O" and b[i][j+2] != "O": string = string+a[i][j] elif b[i][j+1] == "O" and b[i][j+2] == "[SEP]\n": break elif b[i][j+1] != "O" and b[i][j+2] == "O": string = string+a[i][j] tmp.append(string) string = "" aa = set(tmp) tmp = list(aa) all.append(tmp) # 将识别的实体写入final.txt中 with open("final.txt","w",encoding = "utf8") as f: for i in all: if len(i)==0: f.write("\n") continue for j in range(0,len(i)-1): #f.write(i[j].strip+' ') string = "" for k in i[j].strip(): string = string+k f.write(string+' ') f.write(i[len(i)-1].strip()+"\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
下面是转换后的结果,可以看出整体的结果还是不错的


