
- 1手把手教你如何使用AI绘画:Stable-Diffusion本地化部署及使用教程_ai模型如何本地部署
- 2signature=6d8fc7e05b99dc0c89f1553a795ec1e3,Elgg/CHANGELOG.md at 2.3.8 · Elgg/Elgg · GitHub
- 3GitHub新上线并发编程深度解析实战PDF,阿里大牛评:入门到大成!_并发编程 pdf
- 4开源流量分析系统 Apache Spot 概述(转)
- 5C4.5算法分类器
- 6【华为OD机试真题 JS语言】424、虚拟游戏理财 | 机试真题+思路参考+代码解析(最新C卷抽中)(本题100%)_在一款虚拟游戏中生活,你必须
- 7Python框架Django:render()函数_python的render函数
- 8数据分析 -- numpy
- 9vasp计算之输入输出文件_vasp自旋极化磁矩为负
- 10Your branch is up to date with 'origin/develop'._your branch is up to date with 'origin/dev'.
深入理解深度学习——注意力机制(Attention Mechanism):位置编码(Positional Encoding)_深度学习相对位置编码器
赞
踩
分类目录:《深入理解深度学习》总目录
相关文章:
·注意力机制(AttentionMechanism):基础知识
·注意力机制(AttentionMechanism):注意力汇聚与Nadaraya-Watson核回归
·注意力机制(AttentionMechanism):注意力评分函数(AttentionScoringFunction)
·注意力机制(AttentionMechanism):Bahdanau注意力
·注意力机制(AttentionMechanism):多头注意力(MultiheadAttention)
·注意力机制(AttentionMechanism):自注意力(Self-attention)
·注意力机制(AttentionMechanism):位置编码(PositionalEncoding)
在处理词元序列时,循环神经网络是逐个的重复地处理词元的,而自注意力则因为并行计算而放弃了顺序操作。 为了使用序列的顺序信息,通过在输入表示中添加位置编码(Positional Encoding)来注入绝对的或相对的位置信息。 位置编码可以通过学习得到也可以直接固定得到。 接下来描述的是基于正弦函数和余弦函数的固定位置编码。
假设输入表示
X
∈
R
n
×
d
X\in R^{n\times d}
X∈Rn×d包含一个序列中
n
n
n个词元的
d
d
d维嵌入表示。 位置编码使用相同形状的位置嵌入矩阵
P
∈
R
n
×
d
P\in R^{n\times d}
P∈Rn×d输出
X
+
P
X + P
X+P, 矩阵第
i
i
i行、第
2
j
2j
2j列和
2
j
+
1
2j+1
2j+1列上的元素为:
p
pos
,
2
i
=
sin
(
pos
1000
0
2
i
d
)
p
pos
,
2
i
+
1
=
cos
(
pos
1000
0
2
i
d
)
在位置嵌入矩阵
P
P
P中,行代表词元在序列中的位置,列代表位置编码的不同维度。从下面的例子中可以看到位置嵌入矩阵的第6列和第7列的频率高于第8列和第9列。 第6列和第7列之间的偏移量及第8列和第9列之间的偏移量正是由于正弦函数和余弦函数的交替。
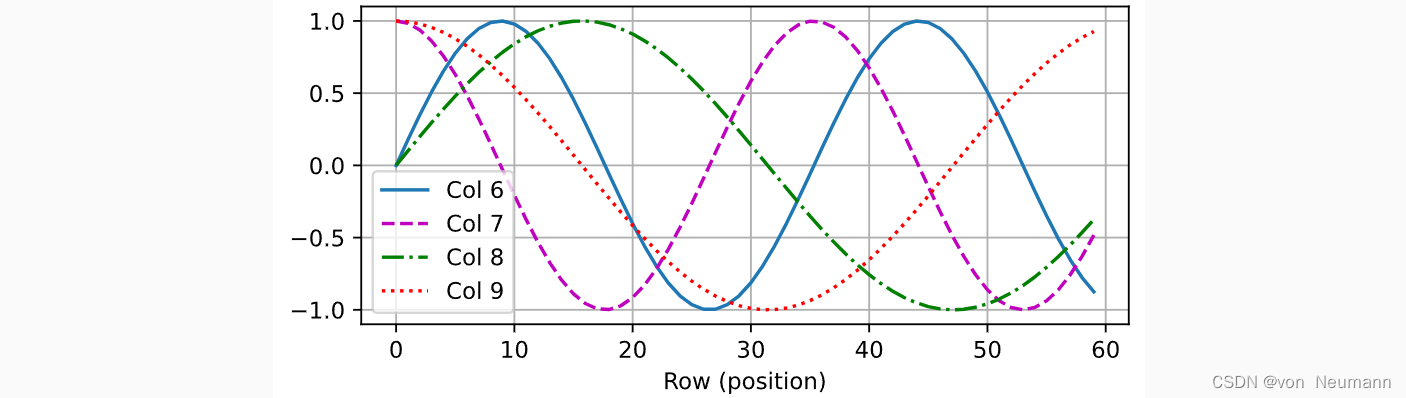
可以看到,在位置编码中,当列数是偶数时,使用正弦函数;当列数是奇数时,则使用余弦函数。
绝对位置信息
为了明白沿着编码维度单调降低的频率与绝对位置信息的关系, 下面是 0 , 1 , ⋯ , 7 0, 1, \cdots, 7 0,1,⋯,7的二进制表示形式。正如所看到的,每个数字、每两个数字和每四个数字上的比特值在第一个最低位、第二个最低位和第三个最低位上分别交替。
0的二进制是:000
1的二进制是:001
2的二进制是:010
3的二进制是:011
4的二进制是:100
5的二进制是:101
6的二进制是:110
7的二进制是:111
在二进制表示中,较高比特位的交替频率低于较低比特位, 与下面的热图所示相似,只是位置编码通过使用三角函数在编码维度上降低频率。 由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
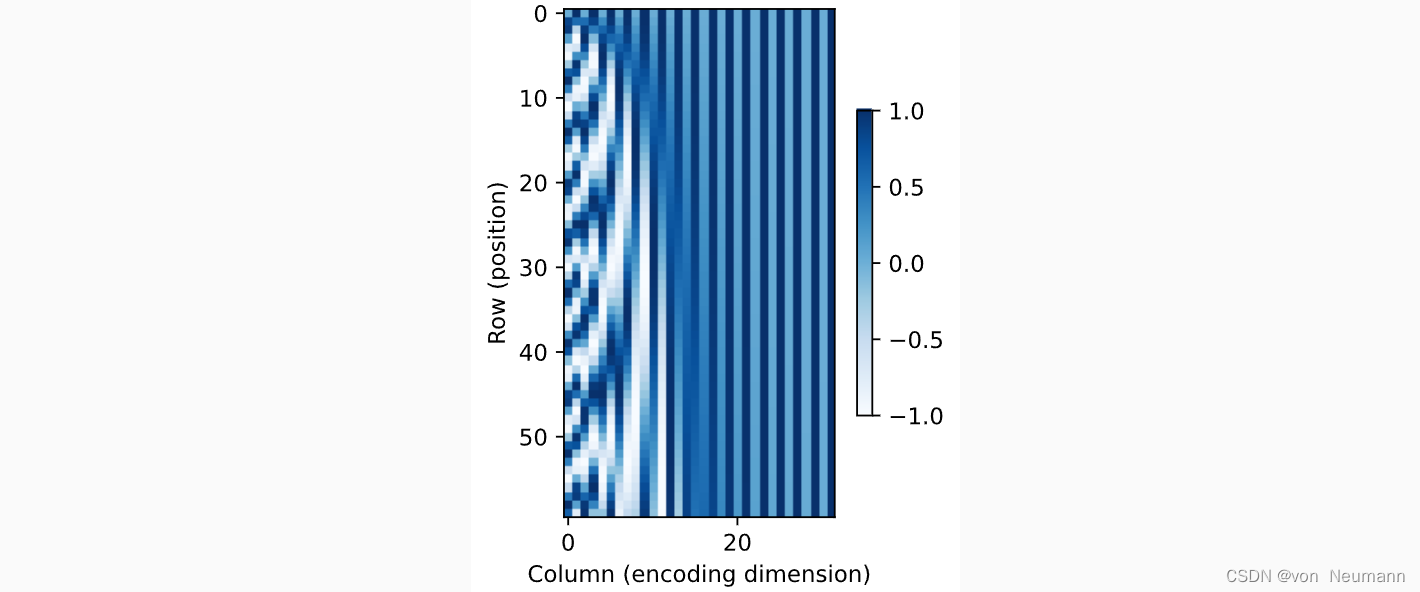
相对位置信息
除了捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。 这是因为对于任何确定的位置偏移 δ \delta δ,位置 i + δ i + \delta i+δ处的位置编码可以线性投影位置 i i i处的位置编码来表示。
这种投影的数学解释是,令
w
j
=
1
1000
0
2
j
d
w_j = \frac{1}{10000^{\frac{2j}{d}}}
wj=10000d2j1, 对于任何确定的位置偏移
δ
\delta
δ,任何一对
(
p
i
,
2
j
,
p
i
,
2
j
+
1
)
(p_{i, 2j}, p_{i, 2j + 1})
(pi,2j,pi,2j+1)都可以线性投影到
(
p
i
+
δ
,
2
j
,
p
i
+
δ
,
2
j
+
1
)
(p_{i + \delta, 2j}, p_{i + \delta, 2j + 1})
(pi+δ,2j,pi+δ,2j+1):
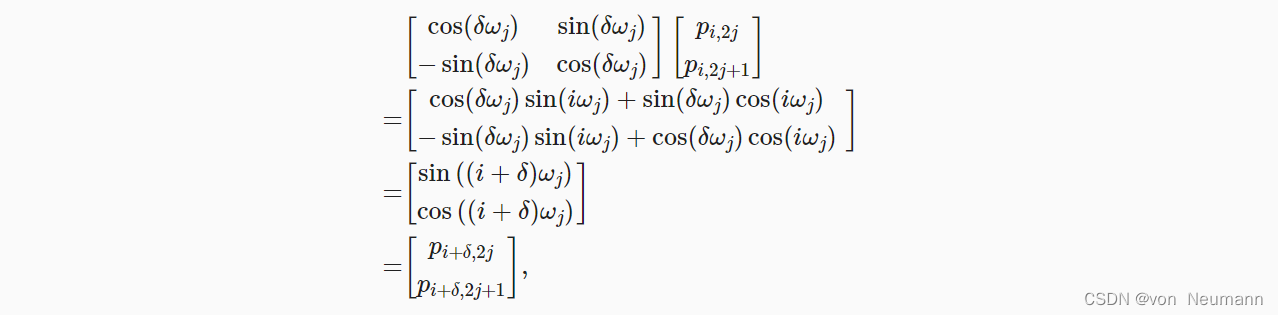
位置编码的实例
还是以“I am good.(我很好。)”这句话为例。在RNN模型中,句子是逐字送入学习网络的。换言之,首先把“I”作为输入,接下来是“am”,以此类推。通过逐字地接受输入,学习网络就能完全理解整个句子。然而,Attention网络并不遵循递归循环的模式。因此,我们不是逐字地输入句子,而是将句子中的所有词并行地输入到神经网络中。并行输入有助于缩短训练时间,同时有利于学习长期依赖。不过,并行地将词送入Attention,将不保留词序。要理解一个句子,词序(词在句子中的位置)是很重要吗的,Attention也需要一些关于词序的信息,以便更好地理解句子。
对于给定的句子“I am good.”,我们首先计算每个单词在句子中的嵌入值。嵌入维度可以表示为 d model d_{\text{model}} dmodel。比如将嵌入维度 d model d_{\text{model}} dmodel设为4,那么输入矩阵的维度将是 [ 句子长度 × 嵌入维度 ] [\text{句子长度}\times\text{嵌入维度}] [句子长度×嵌入维度],也就是 [ 3 × 4 ] [3 \times 4] [3×4]。
假设表示“I am good.”的输入矩阵
X
X
X如下图所示:
如果把输入矩阵
X
X
X直接传给Attention ,那么模型是无法理解词序的。因此,需要添加一些表明词序(词的位置)的信息,以便神经网络能够理解句子的含义。所以,我们不能将输入矩阵直接传给Attention 。这里引入了一种叫作位置编码(Positional Encoding)的技术,以达到上述目的。顾名思义,位置编码是指词在句子中的位置(词序)的编码。
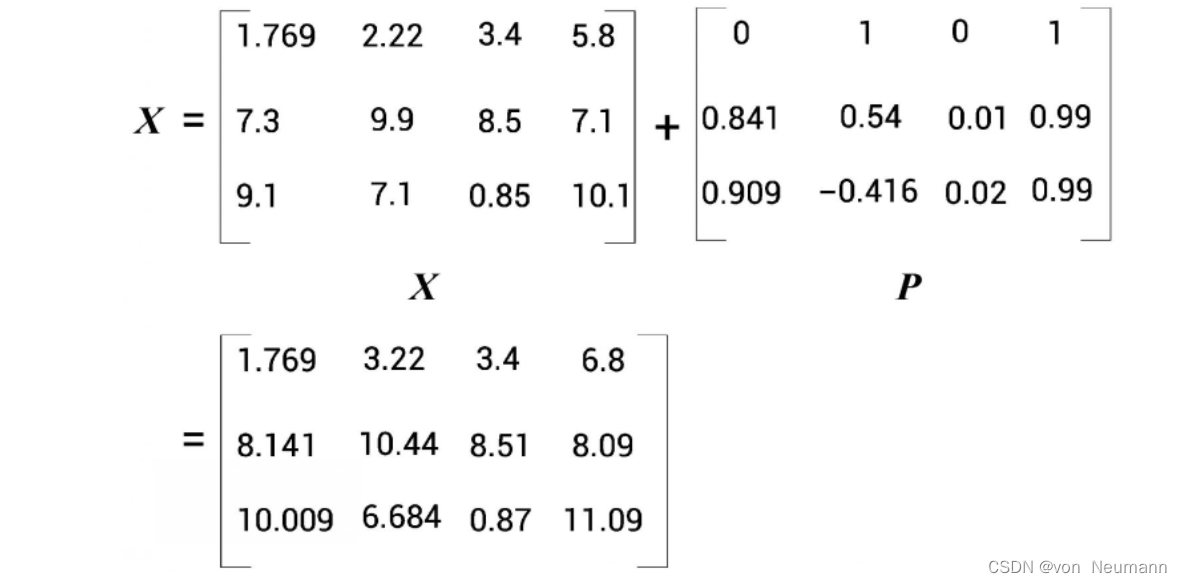
位置编码矩阵
P
P
P的维度与输入矩阵
X
X
X的维度相同。在将输入矩阵直接传给Attention 之前,我们将使其包含位置编码。我们只需将位置编码矩阵
P
P
P添加到输入矩阵
X
X
X中,再将其作为输入送入神经网络,如下图所示。这样一来,输入矩阵不仅有词的嵌入值,还有词在句子中的位置信息。
我们知道“I”位于句子的第0位,“am”在第1位,“good”在第2位。代入
i
i
i值,我们得到如下结果,其中第一行为“I”的位置编码,第二行为“am”的位置编码,第三行为“good”的位置编码:
[
sin
(
0
1000
0
0
4
)
=
sin
(
0
)
cos
(
0
1000
0
0
4
)
)
=
cos
(
0
)
sin
(
0
1000
0
2
4
)
=
sin
(
0
)
cos
(
0
1000
0
2
4
)
)
=
cos
(
0
)
sin
(
1
1000
0
0
4
)
=
sin
(
1
)
cos
(
1
1000
0
0
4
)
)
=
cos
(
1
)
sin
(
1
1000
0
2
4
)
=
sin
(
1
100
)
cos
(
1
1000
0
2
4
)
)
=
cos
(
1
100
)
sin
(
2
1000
0
0
4
)
=
sin
(
2
)
cos
(
2
1000
0
0
4
)
)
=
cos
(
2
)
sin
(
2
1000
0
2
4
)
=
sin
(
1
50
)
cos
(
2
1000
0
2
4
)
)
=
cos
(
1
50
)
]
最终的位置编码矩阵
P
P
P如下:
P
=
[
0
1
0
1
0.841
0.54
0.01
0.99
0.909
−
0.416
0.02
0.99
]
P =
只需将输入矩阵
X
X
X与计算得到的位置编码矩阵
P
P
P进行逐元素相加,并将得出的结果作为输入矩阵送入编码器中。让我们回顾一下编码器架构。下图是一个编码器模块,从中我们可以看到,在将输入矩阵送入编码器之前,首先要将位置编码加入输入矩阵中,再将其作为输入送入编码器。
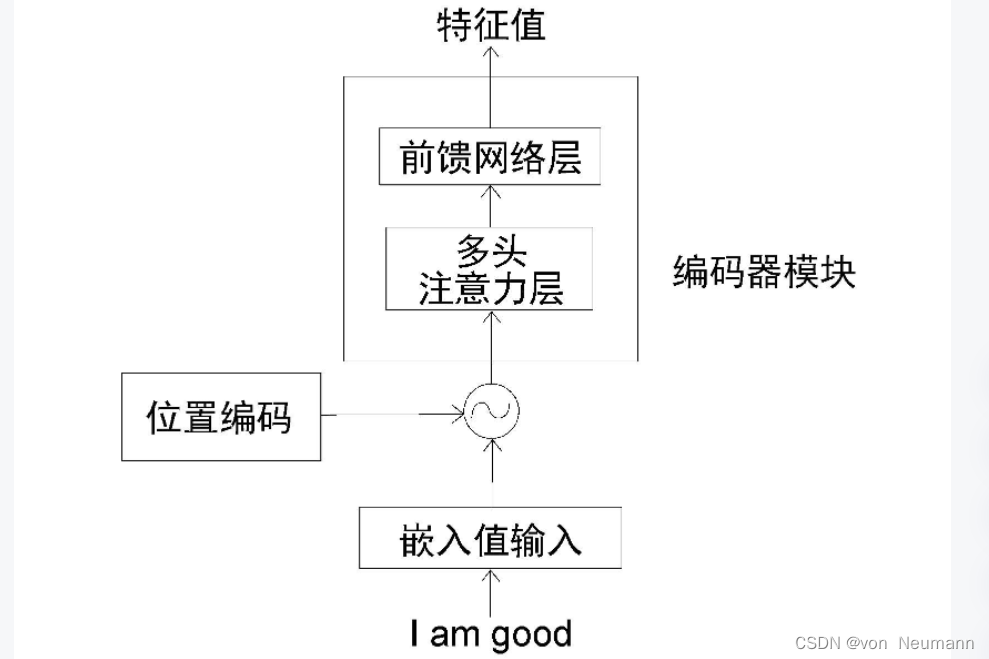
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.

