
- 1怎么给字符串字段加索引?_非整形字段 怎么做索引
- 2关于 QSound播放wav音频文件,播放失败“using null output device, none available” 的解决方法_qsound::play using null output device, none availa
- 3【acwing算法基础课】 数据结构 单链表_acwing中的单链表
- 4GitHub Pages + Hexo搭建个人博客网站,史上最全教程_github pages hexo
- 5r3live运行步骤及时间同步,以及遇到的问题_r3live有明显延迟
- 62024年转行软件测试,报培训班3个月出来就是高薪工作,真的靠谱吗?_软件测试公司三个月培训靠谱吗
- 7升级win11后无线鼠标失灵,win11鼠标用不了
- 8【学习】黑盒测试用例设计方法都有哪些
- 9美丽的松花江作文800字
- 10docker、ctr、crictl命令对比
图解NebulaGraph-开源国产分布式图数据库!
赞
踩
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~
转载文章请保留以下声明:
正文
注意!以下为官网的一些介绍,和个人对这个图数据库的理解,仅供参考
此为图解Nebula Graph系列第一篇~
Nebula Graph:国产,开源,原生图支持,国内图库专家开发,这几个名词就值得我们去了解这个图库!
官网上介绍,Nebula Graph 是一个开源 (Apache 2.0),高性能的分布式图数据库,是一个支持百亿节点,万亿条边,并提供毫秒延迟的图数据库解决方案。
那就让我们一探究竟!
Nebula Graph 特点
Nebula Graph 有如下重要特点:
-
高性能
提供低延时高并发读写 -
类 SQL 查询语言
SQL 式的查询语言,易学易用,满足复杂业务需求 -
高度安全
完善的分组和用户鉴权 -
可扩展
支持水平扩展,可自动实现负载均衡与弹性扩容 -
多存储后端
支持 RocksDB、HBase 等多种存储后端 -
智能驱动
通过索引推荐、指标监控、慢查询分析发现性能风险 -
高可用
多重冗余架构设计,为数据持久存储提供可靠保障
图存储方式
1、存储方式
有向属性图:包含节点、边和属性。节点和边都可以拥有自己的属性,edge存在方向;
现今,几乎所有的图数据库都是使用属性图模型来表示一个图模型,neo4j、janusgraph、nebula graph、hugegraph、tigergraph…等等
2、切图方式
如果想要存储图,需要将图按照不同的方式进行切分;
现有的两种切分方式主要包含:edge cut 和 vertex cut,不了解相关切分方式可以Google查询一下,博主后期也会出一篇相关的介绍
Nebula Graph底层的图切分方式:edge cut , 节点逻辑存储一份,edge存储两份;
一个edge的key分为两种out edge key 和 in edge key
- out vertex + out edge存储在同一个partition
- in vertex + in edge存储在同一个partition
本文主要是做一个整体的介绍,具体细节就不展开了,后续会出一篇博文详细分析一下设计的想法
图查询语言
nGQL : 这是Nebula Graph专门新开发的一门图数据声明型的文本查询语言, 类似于sql语言,主要目的就是为了便于开发者学习,减少学习成本!
特点 (来自官网)
- 类 SQL,易学易用
- 可扩展
- 大小写不敏感
- 支持图遍历
- 支持模式匹配
- 支持聚合运算
- 支持图计算
- 支持分布式事务(开发中)
- 无嵌入支持组合语句,易于阅读
架构设计
架构设计图(来自官网):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cSmfOiZz-1608195445199)(http://images.coderstudy.vip/架构图)]](https://img-blog.csdnimg.cn/ca16609c1eee4b92b300f51e5aec3093.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0NTRE5fX19MWVk=,size_16,color_FFFFFF,t_70)
由上图可以看出,架构设计存在的优点:
1、存储计算分离
整体设计采用 计算层 和 存储层分离的架构,可以更友好的支持水平扩展 、可以根据各自的情况弹性扩缩容;
此外,存储计算分离使得 Storage Service 可以为多种类型的个计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的计算层,而各种迭代计算框架会是另外一个计算层。(来自官网)
2、无状态计算层
每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 meta 信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上(来自官网)
3、Shared-nothing 分布式存储层
各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,类似于MPP(大规模并行处理)模式,各处理单元之间通过协议通信,并行处理和扩展能力更好,Nebula Graph的Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有多个本地 KV 存储实例作为物理存储。Nebula Graph 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性;
一个完整的 Nebula Graph 部署集群包含三个服务
- Query Service
- Storage Service
- Meta Service
Query Service
查询引擎部分,提供查询服务;
主要功能就是解析nGQL,生成优化后的执行计划,组成action算子链提交执行!
Storage Service
存储引擎部分,基于RocksDb开发的分布式底层存储,用来持久化存储图数据;
Meta Service
元数据管理服务,主要用于图库集群元数据的管理;
注意,如果该服务不可用,会导致整体图库的不可用,所以建议集群部署,提高可用性
底层存储
图数据库以存储底层来划分,可以分为:
- 原生图
- 非原生图
原生图:数据存储使用专门为当前图数据库开发的底层存储,最大程度的适应图数据格式的存储;大多数都是原生图,neo4j,nebula graph,tiger graph等
非原生图:数据底层存储使用现有的第三方存储软件,例如使用Hbase等;代表图数据Janusgraph和fork自Janus的HugeGraph
原生图:
Nebula Graph默认采用原生图实现,底层开发人员基于分布式kv存储引擎RocksDB开发了一套图数据存储引擎,用来存储Nebula Graph的图数据;
非原生图:
Nebula Graph也支持使用Hbase作为第三方存储,非原生图实现;
数据可用性和一致性
可用性
集群:
集群可以说是保证可用性的一把手,一台机器挂掉,还有其他的机器在提供服务;
Nebula Graph支持集群部署,Meta Service也支持集群部署
数据分区多副本:
一般来说,分布式存储为了保证可用性,采用多副本的方式,不同副本存储到不同的机器,避免数据丢失和一个机器down机后还可以继续提供服务;
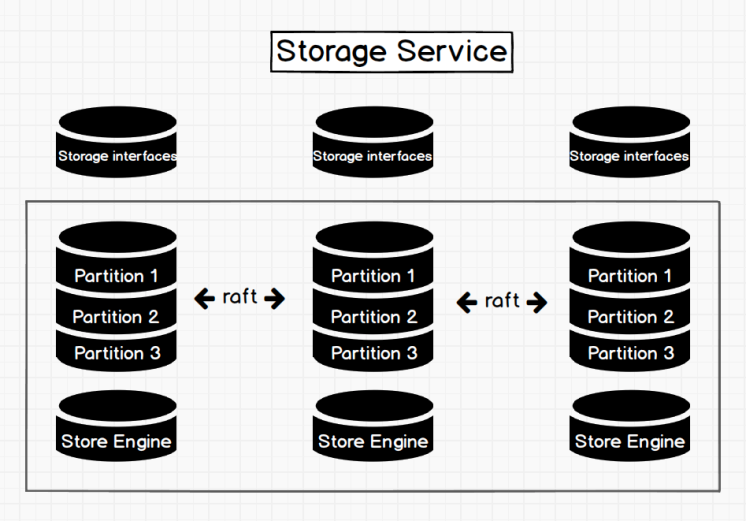
Nebula Graph底层将数据分区存储,如下图
一致性
Raft
Nebula Graph的数据一致性采用Raft协议保证强一致性;
锁机制
存储层架构图(来自官网):
查询引擎
查询引擎架构图(来自官网):
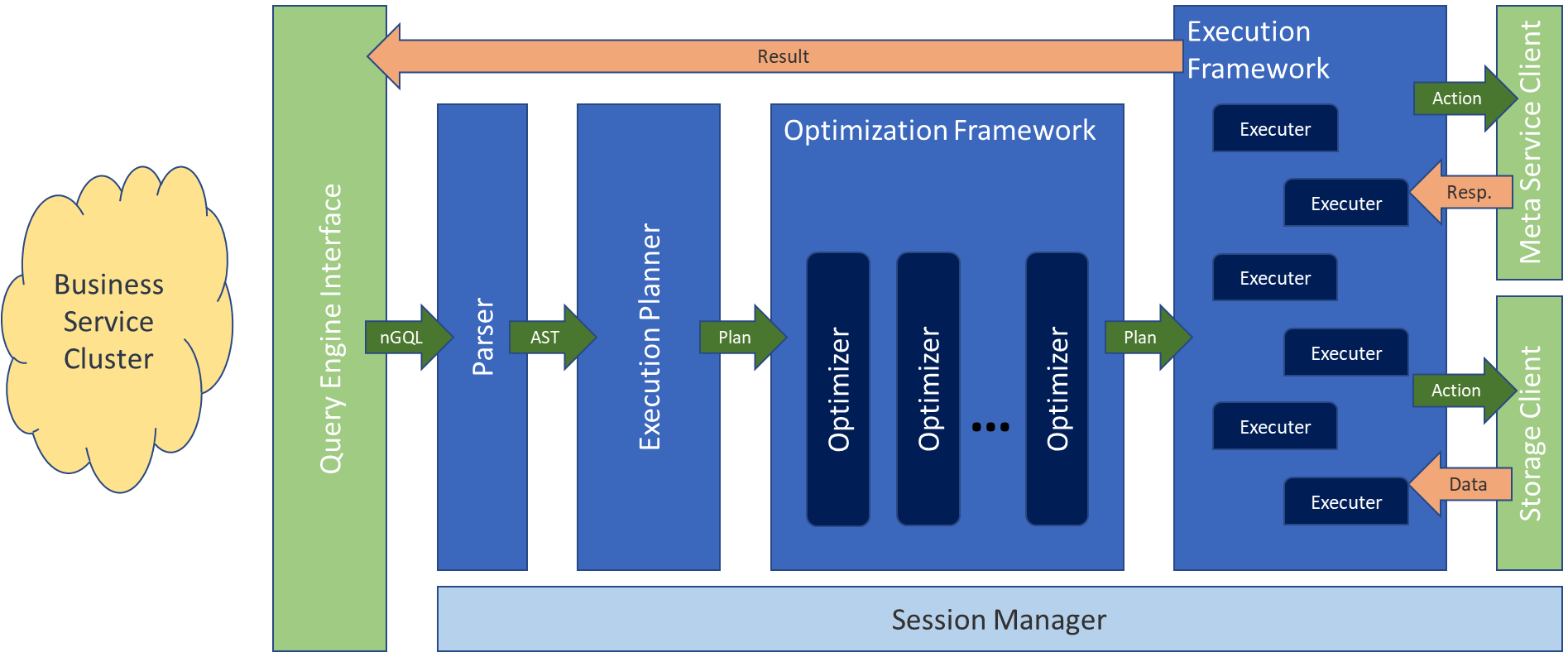
查询引擎是常用的设计的那一套,当然Nebula肯定对图数据查询做了大量的优化
- 分析器(Parser)构建AST
- 计划器(Execution Planner)将AST转为执行计划
- 优化器(Optimization)优化执行计划
- 执行器(Execution)执行优化后的执行计划
olap支持度
Nebula提供了nebula-algorithm;
nebula-algorithm基于 GraphX 的 Spark 应用程序,提供了 PageRank 和 Louvain 社区发现的图计算算法
现阶段支持算法:PageRank 和 Louvain 社区发现算法
此外,用户也可以通过 Spark Connector 编写 Spark 程序调用 GraphX 自带的其他图算法,如 LabelPropagation、ConnectedComponent 等。
数据导入
两种维度分析:速度 和 数据转换
1、批量导入在保证数据一致性下的速度
2、非图结构的结构化的数据 转换为 nebula可支持图结构数据的能力
3、非图结构的非结构化的数据 转换为 nebula可支持图结构数据的能力
提供了3种组件来服务数据导入部分:
1、Nebula Graph Exchange
2、Nebula Flink Connector
3、Nebula Spark Connector
现阶段,市面上也有一些速度对比文章,整体来说,导入速度是不错的,由于市面上绝大多数的图数据库,所以数据的批量导入应该不会是一个瓶颈;
数据转换,Nebula人性化的提供了Graph Exchange 组件,用于接入各种例如Flink等组件
不足
不支持分布式事务
截止到当前版本:2.0 是不支持的,有这方面需求可能无法使用这个图库;
迭代过程中升级版本问题
迭代过程中,可能下一个版本的底层存储结构变化或者框架内部变化导致不兼容的问题,可能会使使用者升级困难,当然这是几乎所有不断迭代的组件都可能存在的问题;
总结
整理来说,从数据导入,查询性能,组件维护,可用性,社区活跃度来说值得使用的
关键是开源哦
refer:Nebula Graph 官网
点击「文章最下方-Geek Tech」或搜索「Geek Tech」公众号可免费获取多种PDF技术文档:Java、图数据库、Git使用和原理、算法、如何单元测试等PDF! 还有每天的技术文章推送和每月免费送书抽奖!
- 《一文教会你写90%的Shell脚本》PDF:发送消息“shell”
- 《Git常用操作和Git底层原理全集》PDF:发送消息“git”
- 《图解-图数据库系列合集》PDF:发送消息“图数据库”
- 《近百页数据库和sql基础知识整理》PDF:发送消息“数据库”
- HRM人事管理系统+经典飞机大战+像素鸟源码+:关注后发送消息“源码”
- 更多免费pdf和资源可关注公众号查看!
「点击下方公众号Tab栏关注我们,专注于程序员的技术公众号!」

