
热门标签
热门文章
- 1普通二本,去过阿里外包,到现在年薪40W+的高级测试工程师,我的两年转行心酸经历..._二本去阿里巴巴外包项目
- 2sourceTree安装和使用(windows)
- 3Android Studio APK打包(签名),2024最新安卓大厂面试题来袭
- 4YOLOv5训练自己的数据集并测试(以及踩坑记录)_yolo测试集怎么用
- 5动态规划的常用状态转移方程总结_动态规划状态转移方程
- 6R语言 - 逻辑回归_r语言逻辑回归
- 7用指针实现队列_队列指针
- 8sql server 基础
- 9COIN++: Neural Compression Across Modalities 论文阅读笔记
- 10华为安全-防火墙-双向NAT_华为防火墙双向nat配置
当前位置: article > 正文
pytorch常见分布式训练报错(另备忘模型分布式后,named_modules,前会加module.)_valueerror: distributeddataparallel device_ids and
作者:凡人多烦事01 | 2024-04-14 06:01:30
赞
踩
valueerror: distributeddataparallel device_ids and output_device arguments o
1、–nproc_per_node=设置错误,比如就2块可见卡,设置3,那么代码中这行torch.cuda.set_device(args.local_rank)
就会报以下错误
Traceback (most recent call last):
File "trainDDP.py", line 32, in <module>
torch.cuda.set_device(args.local_rank)
File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/cuda/__init__.py", line 311, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: CUDA error: invalid device ordinal
- 1
- 2
- 3
- 4
- 5
- 6
2、在使用“DistributedDataParallel”时,model没有先放在GPU上,而是默认的CPU。所以会报如下错误
ValueError: DistributedDataParallel device_ids and output_device arguments only work with single-device/multiple-device GPU modules or CPU modules, but got device_ids [1], output_device 1, and module parameters {device(type='cpu')}.
- 1
代码,注意这个args.local_rank 是所有分布式训练中都需要加入的一个args,这个args会被自动传入参数
device = torch.device('cuda:{}'.format(args.local_rank))
#错误
model = VGG16_3D.VGG163D(num_classes=num_classes)
DDPmodel= torch.nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],
output_device=args.local_rank)
#正确
model = VGG16_3D.VGG163D(num_classes=num_classes)
model = model.to(device)
DDPmodel= torch.nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],
output_device=args.local_rank)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、在优化器中添加参数时,获取参数应该用未DDP封装的model,如果有DDP封装的model就会报如下错误:
optimizer = optim.SGD(train_params, lr=lr, momentum=0.9, weight_decay=5e-4) File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/optim/sgd.py", line 95, in __init__ super(SGD, self).__init__(params, defaults) File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/optim/optimizer.py", line 54, in __init__ super(SGD, self).__init__(params, defaults) File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/optim/optimizer.py", line 54, in __init__ self.add_param_group(param_group) self.add_param_group(param_group) File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/optim/optimizer.py", line 251, in add_param_group File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/optim/optimizer.py", line 251, in add_param_group param_group['params'] = list(params) File "/workspace/ws/C3D-main/network/VGG16_3D.py", line 106, in get_1x_lr_params param_group['params'] = list(params) File "/workspace/ws/C3D-main/network/VGG16_3D.py", line 106, in get_1x_lr_params b = [model.conv1a,model.conv1b, model.conv2a,model.conv2b, model.conv3a, model.conv3b,model.conv3c, model.conv4a, model.conv4b,model.conv4c, File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1177, in __getattr__ b = [model.conv1a,model.conv1b, model.conv2a,model.conv2b, model.conv3a, model.conv3b,model.conv3c, model.conv4a, model.conv4b,model.conv4c, File "/opt/conda/envs/torch1.10/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1177, in __getattr__ raise AttributeError("'{}' object has no attribute '{}'".format(raise AttributeError("'{}' object has no attribute '{}'".format( AttributeErrorAttributeError: 'DistributedDataParallel' object has no attribute 'conv1a': 'DistributedDataParallel' object has no attribute 'conv1a

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
代码
#错误 model = VGG16_3D.VGG163D(num_classes=num_classes) model = model.to(device) DDPmodel= torch.nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank], output_device=args.local_rank) train_params = [{'params': VGG16_3D.get_1x_lr_params(DDPmodel), 'lr': lr}, {'params': VGG16_3D.get_10x_lr_params(DDPmodel), 'lr': lr * 10}] criterion = nn.CrossEntropyLoss() # standard crossentropy loss for classification optimizer = optim.SGD(train_params, lr=lr, momentum=0.9, weight_decay=5e-4) #正确 model = VGG16_3D.VGG163D(num_classes=num_classes) model = model.to(device) DDPmodel= torch.nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank], output_device=args.local_rank) train_params = [{'params': VGG16_3D.get_1x_lr_params(model), 'lr': lr}, {'params': VGG16_3D.get_10x_lr_params(model), 'lr': lr * 10}] criterion = nn.CrossEntropyLoss() # standard crossentropy loss for classification optimizer = optim.SGD(train_params, lr=lr, momentum=0.9, weight_decay=5e-4)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4、因为分布式是多进程,而且我们一般都是用的all_reduce 即所有的GPU上张量相加,然后再把这些数值都放到这些GPU上,所以在用tensorboardX等工具时,需要注意,不用每个进程都写,因为每个进程都往文件里写入,需要设置锁机制,就会很复杂同时因为用的all_reduce也没必要,所以选定一个进程就行
reduce操作:
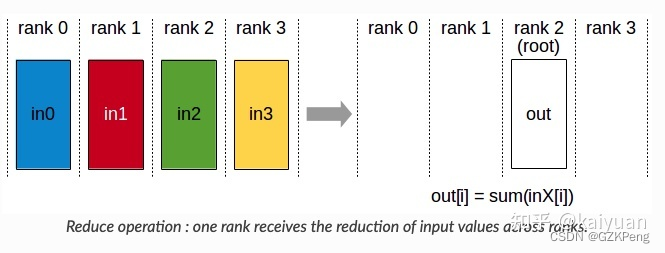
all_reduce操作:
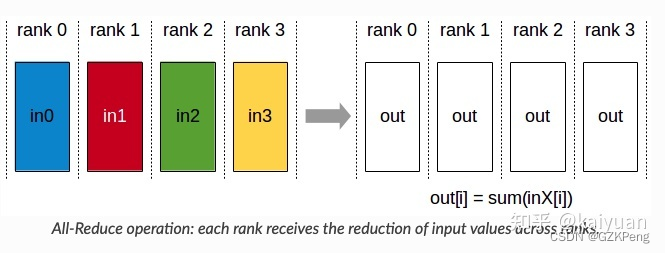
#错误方式 log_dir = os.path.join(save_dir, 'models', datetime.now().strftime('%b%d_%H-%M-%S') + '_' + socket.gethostname()) writer = SummaryWriter(log_dir=log_dir) writer.add_scalar('data/train_loss_epoch', epoch_loss, epoch) writer.close() #正确方式 log_dir = os.path.join(save_dir, 'models', datetime.now().strftime('%b%d_%H-%M-%S') + '_' + socket.gethostname()) os.makedirs(log_dir, exist_ok=True) #exist_ok=True表示如果存在就不创建了 global_rank=torch.distributed.get_rank() if global_rank==0: writer = SummaryWriter(log_dir=log_dir) else: writer = None if writer is not None: writer.add_scalar('data/train_loss_epoch', epoch_loss, epoch) if writer is not None: writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5、因为分布式是多进程,而且我们一般都是用的all_reduce 即所有的GPU上张量相加,然后再把这些数值都放到这些GPU上, 所以保存模型的时候,一个进程保存就行了
if torch.distributed.get_rank() == 0: #一般用0,当然,可以选任意的rank保存。
torch.save(net, "net.pth")
- 1
- 2
6、
model
print('823看看分布式前后模型名称的变化')
for name, layer in model.named_modules():
print(name) # 比如 model.0.conv
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model)
for name, layer in model.named_modules():
print(name) #比如 module.model.0.conv
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/420516
推荐阅读
相关标签

