
- 1算法的时间复杂度和空间复杂度_算法的时间和空间复杂度
- 2【自监督论文阅读笔记】Learning Transferable Visual Models From Natural Language Supervision_论文精读 learning transferable visual models from natu
- 3那两年炼就的Android内功修养
- 4C++入门:命名空间,缺省参数,函数重载详解_byte头文件
- 5C语言----最长公共前缀_c语言编写一个函数来查找字符串数组中的最长公共前缀
- 6STM32 HAL库 CubeMX配置 定时器学习 F103C8T6_stm3f103 定时器 hal库
- 7linux系统能看抖音吗,在Linux系统下用XDroid来安装和运行抖音Android APP应用
- 8uni-app学习总结_uniapp使用总结
- 9代码编写行为准则,编码是一个认真思考的过程,如何有效提高代码的可读性?_编码重要的是梳理清楚代码逻辑
- 10杭电acm-1874畅通工程续_java实现acm畅通工程续
【Python深度学习】利用Pytorch的Dataset和DataLoader实现自定义宝可梦数据集_python创造dataloader
赞
踩
最近一直再学Pytorch进行深度学习,其中有一个比较困难的地方在于如何实现自定义的数据集。Pytorch官方提供了两个抽象类Dataset和DataLoader来帮助我们实现自定义数据集。经过查阅网络资料和观看相关视频,最终基本上掌握了如何利用pytorch自定义图像数据集的方法,这里写一个博客以便后续回忆。
Dataset类
首先官方中文文档对Dataset类的一个介绍:
表示Dataset的抽象类。
所有其他数据集都应该进行子类化。所有子类应该override
__len__和__getitem__,前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)。
那么,肯定是我们要定义一个类,然后重写相关的魔法方法了。
从网上下载来Pokemon数据集,然后初步开始搭建该数据集的骨架结构
- class PokeDatasets(Dataset):
- def __init__(self,root,resize,do):
- super().__init__()
- self.resize=resize
- self.root=root
- self.alllabels={}
-
一个一个介绍。首先__init__是Python独有的构造函数。用来初始化一个对象用的。
构造函数的第一个参数self不用多说,这是Python面向对象的基础知识,凡是构造函数或者成员方法,第一个参数永远是self。
第二个参数root,root代表根目录,这个主要再后面获取这个数据集中所有的类别(label)要用的。
第三个参数是resize,这个resize是代表了图片的尺寸,后续用于处理的。
第四个参数是do,这个参数的作用是告诉Python现在定义的数据集是测试集、验证集、还是训练集?
参数介绍完了,下面介绍一下构造函数体里面的代码。首先super().__init__()是调用父类的构造方法,这个不用多说,注意Python3可以采用该简写方法。不必写出super(本类,self).__init__()
然后就是给成员变量赋值,do在后面直接用不需要赋值。
然后就是一个alllabels,alllabels这个成员变量是一个字典,用来记录该数据集的所有类别以及其数字代表。
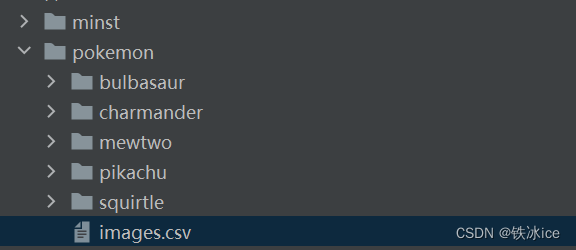
看一下我们的数据集
我们希望alllabels的属性值为:
{'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}怎么做?这就要牵扯到Python的一个标准库os的一个函数listdir。
简单来说listdir就是获取该目录下的子文件(夹)
观看我们的数据集,我们的数据集的结构是一个根目录pokemon,然后下面5个文件夹,每个文件夹以该图片的类别命名。
因此我们可以利用listdir函数获取该名字,然后进一步处理即可。
- In[4]:os.listdir("D:\MachineLearningProject\深度学习torch\pokemon")
- Out[4]: ['bulbasaur', 'charmander', 'images.csv', 'mewtwo', 'pikachu', 'squirtle']
可以发现多了一个images.csv的文件,我们可以用isdir来判断是不是文件夹
- import os
-
- root="pokemon"
-
- alllabels={}
- count=0
- for name in os.listdir(root):
- if os.path.isdir(os.path.join(root,name)):
- alllabels[name]=count
- count+=1
-
- print(alllabels)
运行结果就是我们想要的:
{'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}把这个代码加入到我们的类中
- class PokeDatasets(Dataset):
- def __init__(self,root,resize,do):
- super().__init__()
- self.resize=size
- self.root=root
- self.alllabels={}
- for name in os.listdir(root):
- if os.path.isdir(os.path.join(root, name)):
- self.alllabels[name]=len(self.alllabels)
-
- poke=PokeDatasets("pokemon",42,"train")
-
- print(poke.alllabels)
当然还有一种写法。count可以不写可以使用len(self.alllabels)代替
alllabels定义完了,接下来要定义的是img属性和label属性。两个属性都是列表
img属性代表了所有图片的路径,label属性代表了,img[i]对应的label。
为了获取这两个属性我们需要定义一个成员函数read(),这个函数会返回一个元组,元组里面是两个列表,一个是img,一个是label。
这个函数需要传入一个file_path,代表了该csv的路径
- def read(self,file_path):
- if not os.path.exists(os.path.join(self.root,file_path)):
- pass #准备自己编程造一个images.csv
首先要考虑到可能这个csv文件是不存在,那么我们需要自己去创造一个csv文件。
写入的时候要获取相关图片的路径这里要用到glob模块,这也是Python的标准库
glob.glob(pathname,recursive=False):返回符合匹配条件的所有文件的路径;
- root="pokemon"
- file_path="images2.csv"
-
- alllabels={'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
-
- if not os.path.exists(os.path.join(root,file_path)):
- img_path=[]
- for name in alllabels.keys():
- img_path.extend(glob.glob(os.path.join(root,name,"*.jpg")))
- img_path.extend(glob.glob(os.path.join(root,name,"*.png")))
- img_path.extend(glob.glob(os.path.join(root,name,"*.jpeg")))
- print(img_path[:12])
这里要提出该Pokemon数据集中共有三种图片类型,分别为jpg,png,jpeg,我们的目的就是找到这些图片的路径。
该代码的意思是比如name="pikachu"
那么它会把该路径下("D:\MachineLearningProject\深度学习torch\pokemon\pikachu")下所有的文件以*jpg,*png,*jpeg结尾的文件的路径全部读取出来

一般这个过程结束后要对图片进行打乱操作,使用random.shuffle来实现
- import os
- import glob
- import random
- import csv
-
-
-
- root="pokemon"
- file_path="images2.csv"
-
- alllabels={'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
-
- if not os.path.exists(os.path.join(root,file_path)):
- img_path=[]
- for name in alllabels.keys():
- img_path.extend(glob.glob(os.path.join(root,name,"*.jpg")))
- img_path.extend(glob.glob(os.path.join(root,name,"*.png")))
- img_path.extend(glob.glob(os.path.join(root,name,"*.jpeg")))
- random.shuffle(img_path)
-
- with open(os.path.join(root,file_path),mode="w",encoding='utf-8',newline='') as f:
- writer=csv.writer(f)
- for img in img_path:
- name=img.split(os.sep)[-2]
- label=alllabels[name]
- writer.writerow([img,name])
-
-
-
-

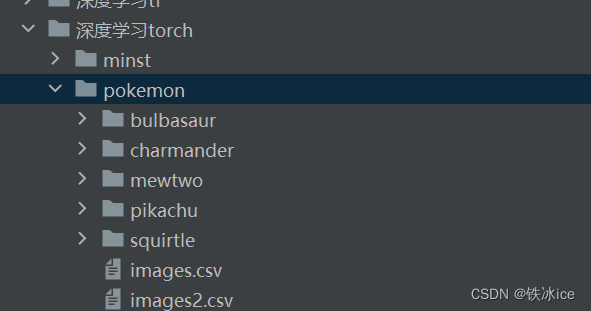
程序运行后,多了一个images2文件夹说明成功了。

将该函数加入到我们的类中
- def read(self,file_path):
- if not os.path.exists(os.path.join(self.root, file_path)):
- img_path = []
- for name in self.alllabels.keys():
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpg")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.png")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpeg")))
- random.shuffle(img_path)
-
- with open(os.path.join(self.root, file_path), mode="w", encoding='utf-8', newline='') as f:
- writer = csv.writer(f)
- for img in img_path:
- name = img.split(os.sep)[-2]
- label = self.alllabels[name]
- writer.writerow([img, label])
- return 1,2
接下来就是读取该csv文件了。
读取csv文件那是太简单了,调用pandas的read_csv即可。
- import pandas as pd
- import os
-
- root="pokemon"
- file_path="images2.csv"
-
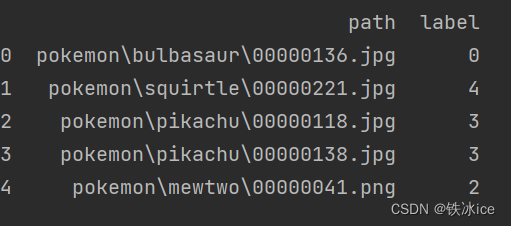
- df=pd.read_csv(os.path.join(root,file_path))
- df.columns=["path","label"]
- print(df.head())
看一下效果
到目前为止完整的代码如下:
-
- from torch.utils.data import DataLoader,Dataset
- import csv
- import os
- import glob
- import random
- import pandas as pd
-
-
-
- class PokeDatasets(Dataset):
- def __init__(self,root,resize,do):
- super().__init__()
- self.resize=resize
- self.root=root
- self.alllabels={}
- for name in os.listdir(root):
- if os.path.isdir(os.path.join(root, name)):
- self.alllabels[name]=len(self.alllabels)
-
- self.img,self.label= self.read("images.csv")
-
-
- def read(self,file_path):
- if not os.path.exists(os.path.join(self.root, file_path)):
- img_path = []
- for name in self.alllabels.keys():
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpg")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.png")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpeg")))
- random.shuffle(img_path)
-
- with open(os.path.join(self.root, file_path), mode="w", encoding='utf-8', newline='') as f:
- writer = csv.writer(f)
- for img in img_path:
- name = img.split(os.sep)[-2]
- label = self.alllabels[name]
- writer.writerow([img, label])
-
- df=pd.read_csv(os.path.join(self.root,file_path),header=None)
- df.columns=["path","label"]
- label=[]
- img=[]
- lens=len(df)
- for i in range(lens):
- img.append(df.loc[i,"path"])
- label.append(df.loc[i,"label"])
- if len(label)==len(img):
- return label,img
- else:
- print("label和img长度不匹配")
-
-
- poke=PokeDatasets("pokemon",64,"train")
-
-
-
-
然后就是实现__len__
- def __len__(self):
- return len(self.img)
__init__函数没有写完,还需要加上数据集划分
我们以60%的训练集,20%的测试集,20%的验证集为划分
目前的完整代码:
-
- from torch.utils.data import DataLoader,Dataset
- import csv
- import os
- import glob
- import random
- import pandas as pd
-
-
-
- class PokeDatasets(Dataset):
- def __init__(self,root,resize,do):
- super().__init__()
- self.resize=resize
- self.root=root
- self.alllabels={}
- for name in os.listdir(root):
- if os.path.isdir(os.path.join(root, name)):
- self.alllabels[name]=len(self.alllabels)
-
- self.img,self.label= self.read("images.csv")
-
- if do == 'train':
- self.img = self.img[:int(0.6 * len(self.img))]
- self.label = self.label[:int(0.6 * len(self.label))]
- elif do == 'val':
- self.img = self.img[int(0.6 * len(self.img)):int(0.8 * len(self.img))]
- self.label = self.label[int(0.6 * len(self.label)):int(0.8 * len(self.label))]
- elif do == 'test':
- self.img = self.img[int(0.8 * len(self.img)):]
- self.label = self.label[int(0.8 * len(self.label)):]
-
-
-
- def __len__(self):
- return len(self.img)
-
-
- def read(self,file_path):
- if not os.path.exists(os.path.join(self.root, file_path)):
- img_path = []
- for name in self.alllabels.keys():
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpg")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.png")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpeg")))
- random.shuffle(img_path)
-
- with open(os.path.join(self.root, file_path), mode="w", encoding='utf-8', newline='') as f:
- writer = csv.writer(f)
- for img in img_path:
- name = img.split(os.sep)[-2]
- label = self.alllabels[name]
- writer.writerow([img, label])
-
- df=pd.read_csv(os.path.join(self.root,file_path),header=None)
- df.columns=["path","label"]
- label=[]
- img=[]
- lens=len(df)
- for i in range(lens):
- img.append(df.loc[i,"path"])
- label.append(df.loc[i,"label"])
- if len(label)==len(img):
- return label,img
- else:
- print("label和img长度不匹配")
-
-
- poke=PokeDatasets("pokemon",64,"train")
-
- print(len(poke))
-
还有最后一步,实现__getitem__方法
这里要用到torchvision中的transforms。
Transforms
transforms提供了大量的图像预处理方法。
Transforms提供了大量的图像处理或者图像增强的方法,这里就介绍下面要用的几个:
1.Compose(transforms)
这个类的作用是将多个transform组合起来使用,骑在transforms是一个列表由多个transforms组合成。
2.ToTensor()
这个类把PIL.Image或者numpy.ndarray转换成pytorch能够识别的Tensor格式。
3.Resize(size)
能够根据size对图像进行分辨率调整裁剪。注意size为一个元组或者列表。
4.CenterCrop(size)
从图像中心裁剪图片 size:所需裁剪图片尺寸
5.Normalize(mean,std)
对图像进行归一化操作。归一化公式
mean:各个通道的均值,std:各个通道的标准差。
我们知道图像是由RGB三个通道组成的因此mean,std都是由三个浮点数组成的三元列表。
一般是在自定义数据集中的类的构造方法中声明transforms成员变量
- self.transforms=transforms.Compose([
- transforms.ToTensor(),
- transforms.Resize((int(self.resize * 1.5), int(self.resize * 1.5))),
- transforms.CenterCrop(self.resize),
- transforms.Normalize(mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225])
- ])
然后在getitem中写入
images = self.transforms(image)这里采用opencv进行读取图像,但是值得注意的是opencv读取的图像会报警告,如果不喜欢警告的话可以考虑使用PIL。同时注意opencv的颜色通道是BGR,而我们传统图像是RGB因此需要进行转换。
具体转换方式可以见该博客:
python代码使用matplot opencv读取图像色彩失真_plot红和蓝反了_Katzelala的博客-CSDN博客
Dataloader
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False)
数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。
参数:
- dataset (Dataset) – 加载数据的数据集。
- batch_size (int, optional) – 每个batch加载多少个样本(默认: 1)。
- shuffle (bool, optional) – 设置为
True时会在每个epoch重新打乱数据(默认: False).- sampler (Sampler, optional) – 定义从数据集中提取样本的策略。如果指定,则忽略
shuffle参数。- num_workers (int, optional) – 用多少个子进程加载数据。0表示数据将在主进程中加载(默认: 0)
- collate_fn (callable, optional) –
- pin_memory (bool, optional) –
- drop_last (bool, optional) – 如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
DataLoader用于加载数据集。
data = DataLoader(poke, batch_size=64, shuffle=True)Visdom展示
最后进行展示,我们使用visdom库进行
在Anaconda的命令行输入
python -m visdom.server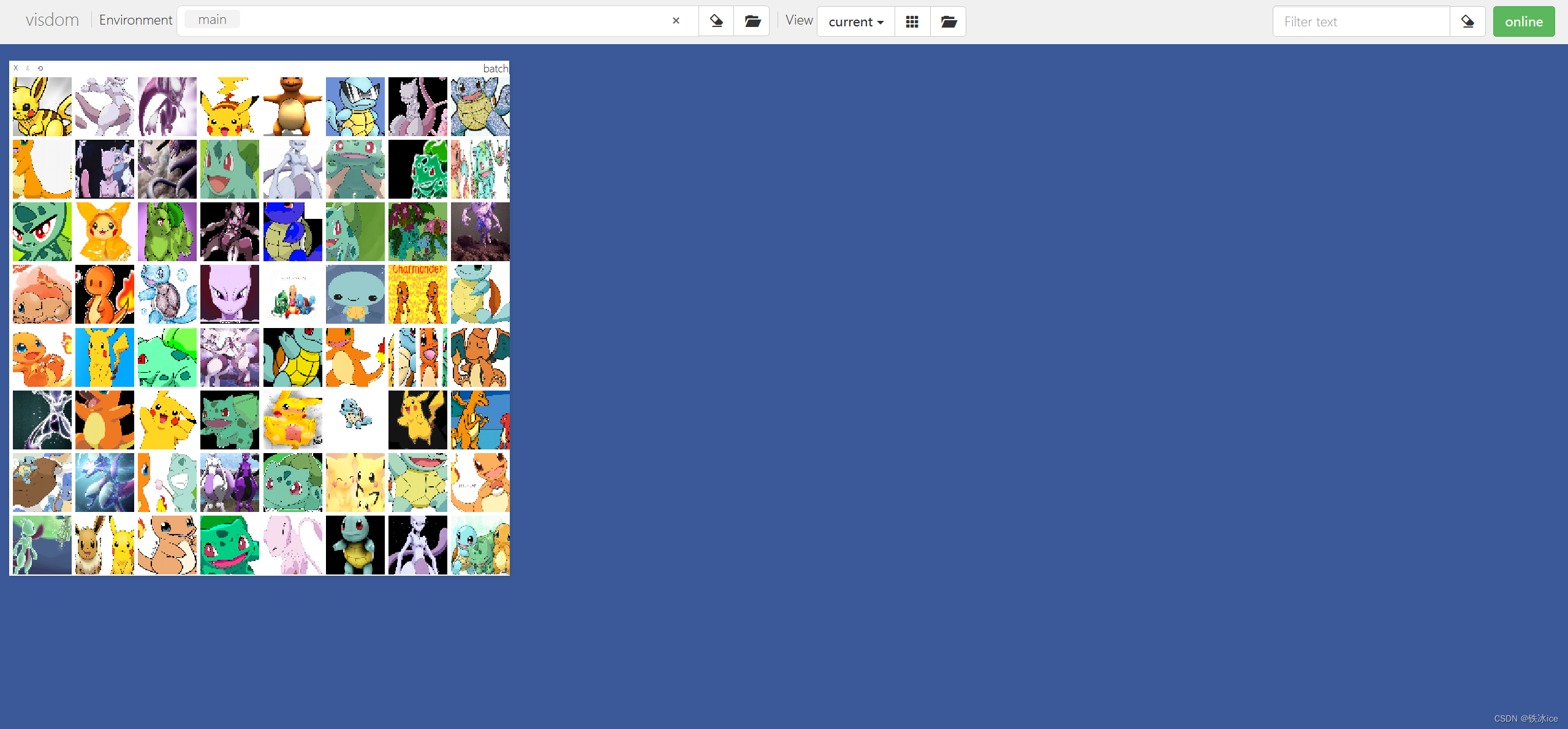
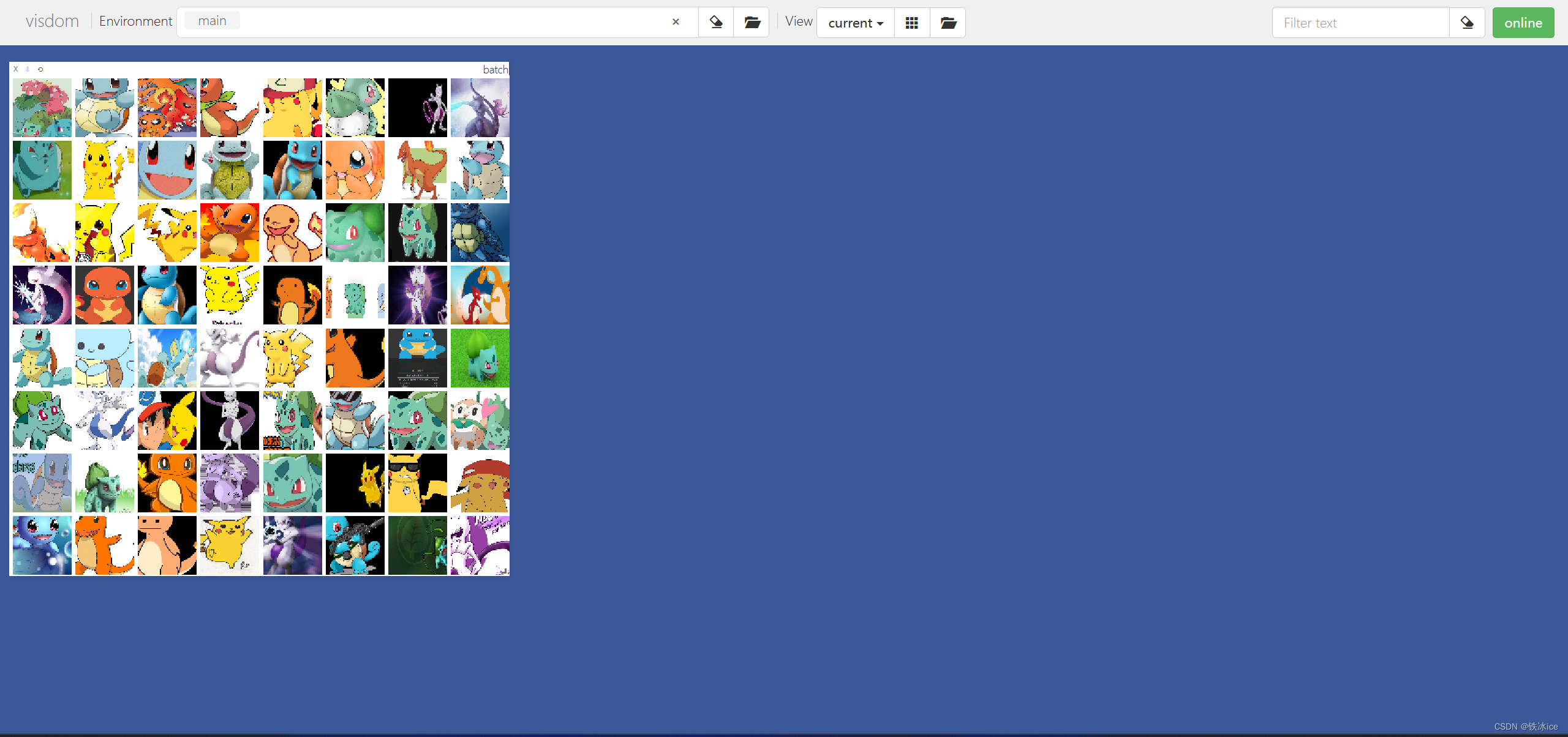
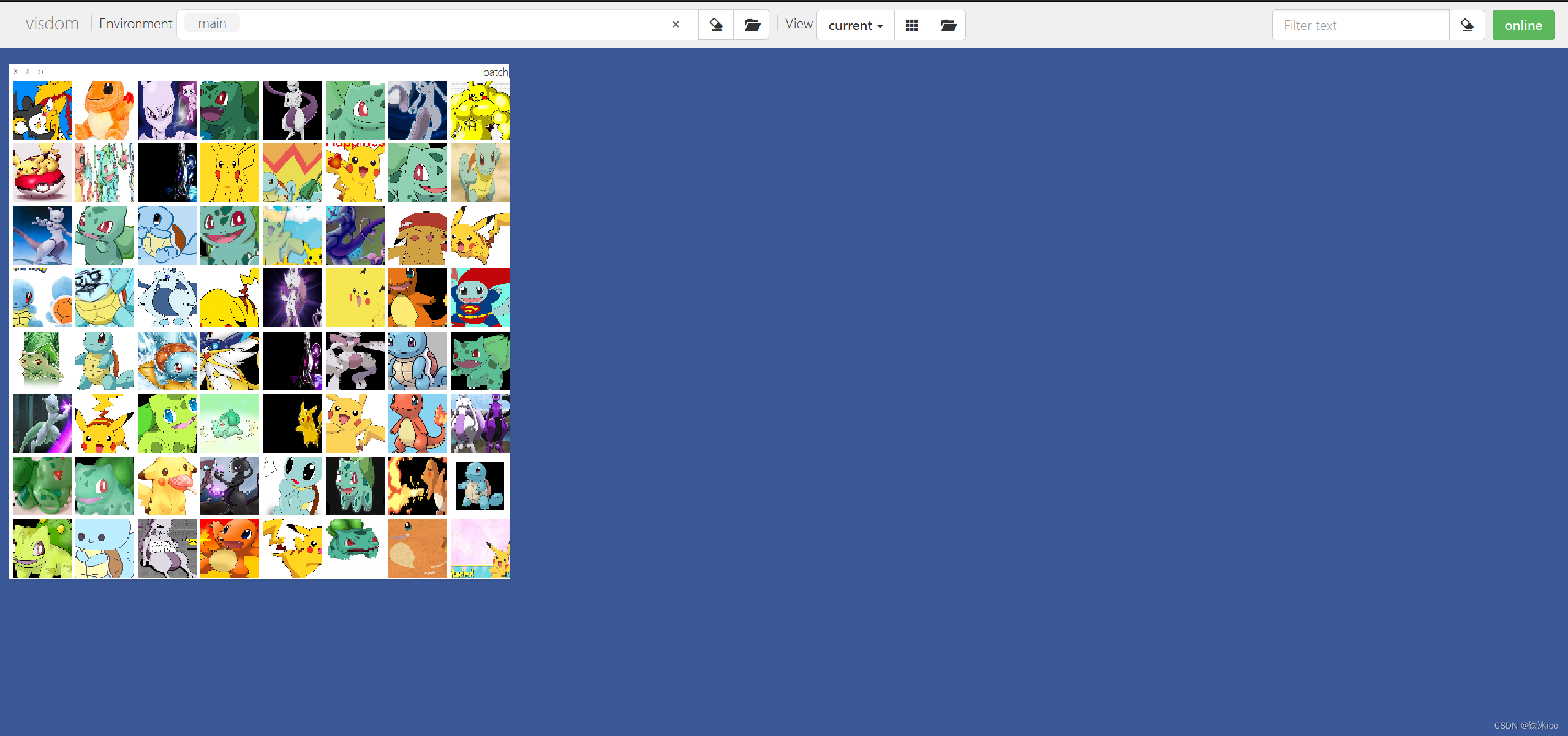
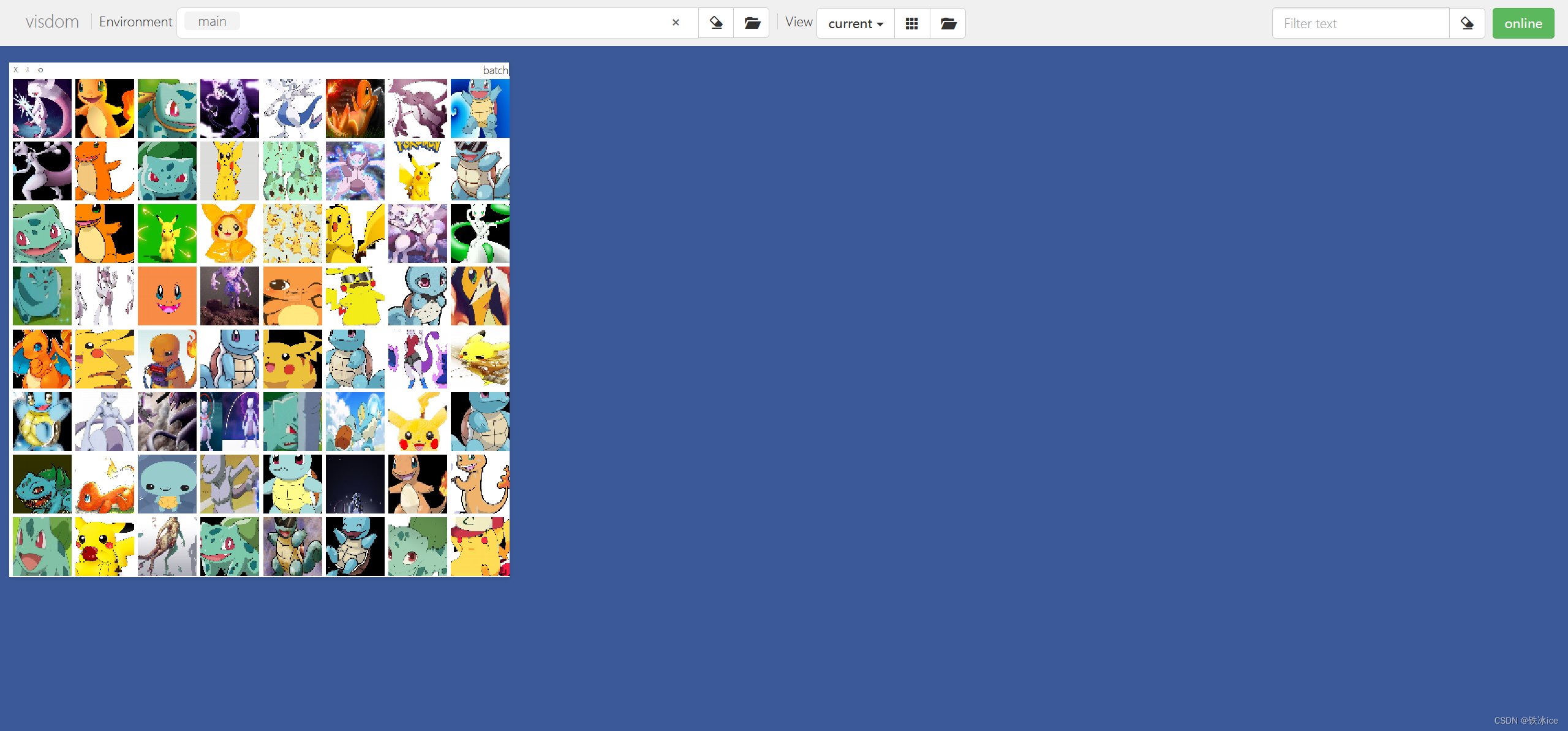
所有步骤到此结束
如果要停止Visdom服务可以在cmd窗口找到8097对应的PID,对应的指令
netstat -ano |findstr "8097"然后通过任务管理器或者直接输入指令关闭visdom服务。
具体可以参考
Windows 查看端口占用并关闭_windows查看端口占用并关闭_天航星的博客-CSDN博客
完整代码
- import torch
- from torch.utils.data import DataLoader,Dataset
- import csv
- import os
- import glob
- import random
- import pandas as pd
- from torchvision import transforms
- import cv2
- import warnings
- from visdom import Visdom
- import time
-
-
- warnings.filterwarnings("ignore")
- class PokeDatasets(Dataset):
- def __init__(self,root,resize,do):
- super().__init__()
- self.resize=resize
- self.root=root
- self.alllabels={}
- for name in os.listdir(root):
- if os.path.isdir(os.path.join(root, name)):
- self.alllabels[name]=len(self.alllabels)
-
- self.img,self.label= self.read("images.csv")
-
-
- if do == 'train':
- self.img = self.img[:int(0.6 * len(self.img))]
- self.label = self.label[:int(0.6 * len(self.label))]
- elif do == 'val':
- self.img = self.img[int(0.6 * len(self.img)):int(0.8 * len(self.img))]
- self.label = self.label[int(0.6 * len(self.label)):int(0.8 * len(self.label))]
- elif do == 'test':
- self.img = self.img[int(0.8 * len(self.img)):]
- self.label = self.label[int(0.8 * len(self.label)):]
-
-
- self.transforms=transforms.Compose([
- transforms.ToTensor(),
- transforms.Resize((int(self.resize * 1.5), int(self.resize * 1.5))),
- transforms.CenterCrop(self.resize),
- transforms.Normalize(mean=[0.485, 0.456, 0.406],
- std=[0.229, 0.224, 0.225])
- ])
-
- def __len__(self):
- return len(self.img)
-
- def __getitem__(self, item):
- image=self.img[item]
- label=self.label[item]
-
- imgs=cv2.imread(image)
- b, g, r = cv2.split(imgs)
- imgs = cv2.merge([r, g, b])
- images = self.transforms(imgs)
- label = torch.tensor(label)
- return images, label
-
-
-
- def read(self,file_path):
- if not os.path.exists(os.path.join(self.root, file_path)):
- img_path = []
- for name in self.alllabels.keys():
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpg")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.png")))
- img_path.extend(glob.glob(os.path.join(self.root, name, "*.jpeg")))
- random.shuffle(img_path)
-
- with open(os.path.join(self.root, file_path), mode="w", encoding='utf-8', newline='') as f:
- writer = csv.writer(f)
- for img in img_path:
- name = img.split(os.sep)[-2]
- label = self.alllabels[name]
- writer.writerow([img, label])
-
- df=pd.read_csv(os.path.join(self.root,file_path),header=None)
- df.columns=["path","label"]
- label=[]
- img=[]
- lens=len(df)
- for i in range(lens):
- img.append(df.loc[i,"path"])
- label.append(df.loc[i,"label"])
- if len(label)==len(img):
- return img,label
- else:
- print("label和img长度不匹配")
-
- def denormalize(self, x_hat):
-
- mean = [0.485, 0.456, 0.406]
- std = [0.229, 0.224, 0.225]
- mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
- std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
- x = x_hat * std + mean
-
- return x
-
-
-
-
- poke=PokeDatasets("pokemon",64,"train")
- data = DataLoader(poke, batch_size=64, shuffle=True)
- viz = Visdom()
-
- for epochodx, (image, label) in enumerate(data):
- viz.images(image, nrow=8, win='batch', opts=dict(title='batch'))
- viz.images(poke.denormalize(image), nrow=8, win='batch', opts=dict(title='batch'))
- time.sleep(0.5)
参考博客:(代码来自该博客,经过部分小修改)


