
热门标签
当前位置: article > 正文
Python处理 PDF神器PyMuPDF 将PDF转文字_python pymupdf 处理中文
作者:凡人多烦事01 | 2024-04-28 05:44:02
赞
踩
python pymupdf 处理中文
目录
最近学习RAG的时候,偶然解锁了PDF转文字的小功能,用的python,在win10-64位操作系统上,使用的IDE是Pycharm_Professional_2020.3.2_Portable,这里记录一下。
第一步,需要安装pycharm
1、安装文件在这里:
链接:https://pan.baidu.com/s/1uHe5BWS6BnXJt5_ujgNcLw?pwd=o80w
提取码:o80w
2、安装方案看这里(仅供学习交流,请勿用作商业用途)
原链接可以看这里:https://www.3363.cn/soft/19122.html#。

第二步、关键代码
当时参考了这篇文章:Python 处理 PDF神器 —— PyMuPDF 的安装与使用!-CSDN博客。关键点是以下:
1、下载依赖
pip install PyMuPDF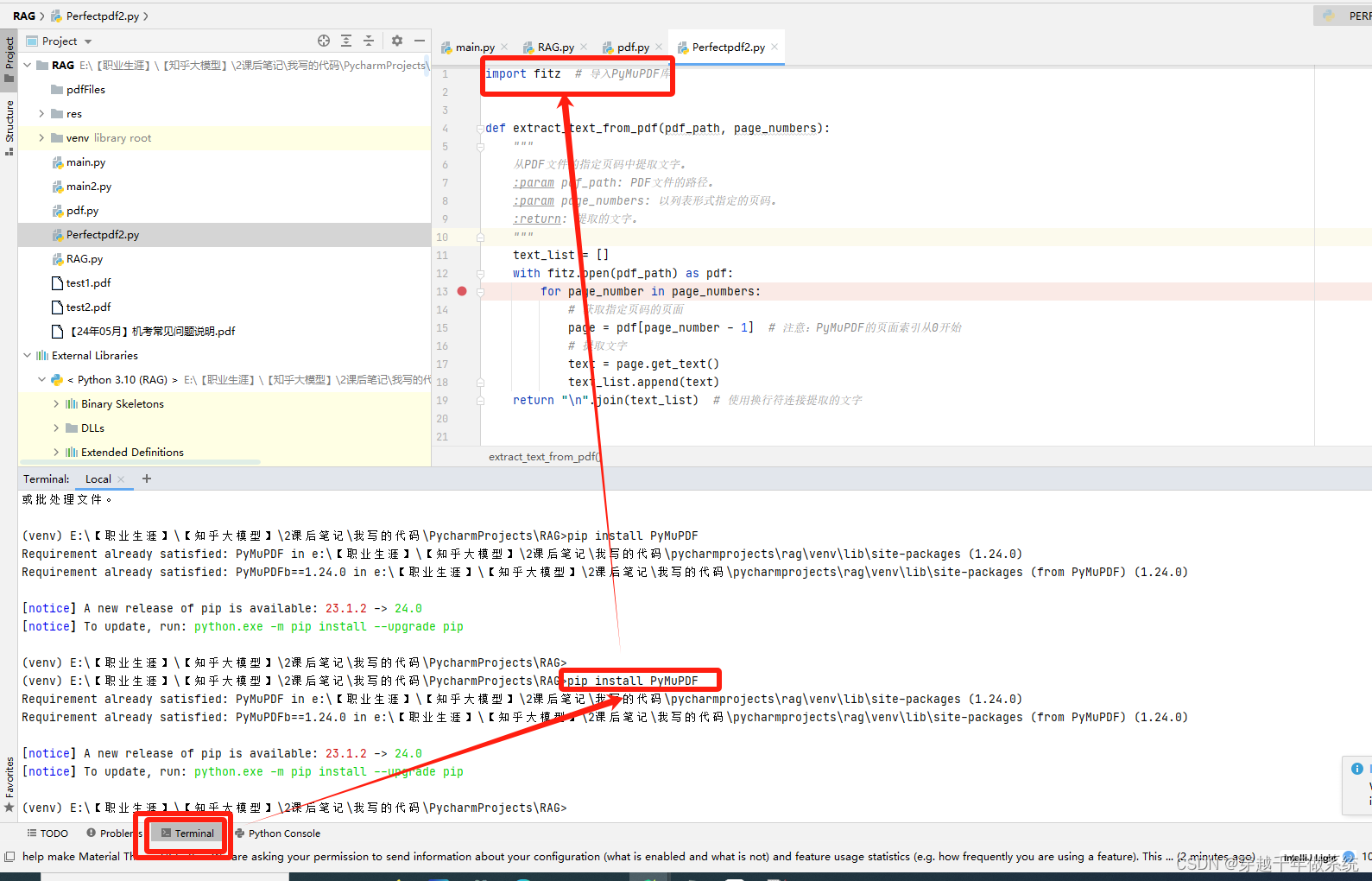
2、关键代码
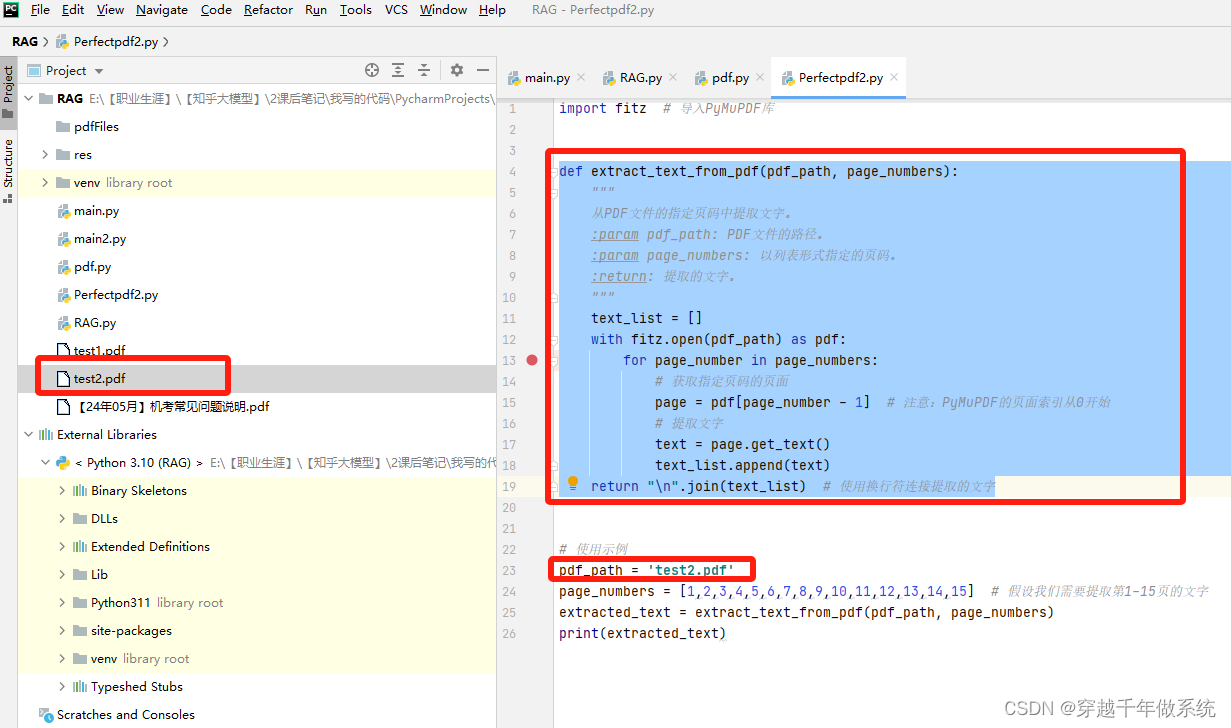
- def extract_text_from_pdf(pdf_path, page_numbers):
- """
- 从PDF文件的指定页码中提取文字。
- :param pdf_path: PDF文件的路径。
- :param page_numbers: 以列表形式指定的页码。
- :return: 提取的文字。
- """
- text_list = []
- with fitz.open(pdf_path) as pdf:
- for page_number in page_numbers:
- # 获取指定页码的页面
- page = pdf[page_number - 1] # 注意:PyMuPDF的页面索引从0开始
- # 提取文字
- text = page.get_text()
- text_list.append(text)
- return "\n".join(text_list) # 使用换行符连接提取的文字

 附:完整代码
附:完整代码
链接:https://pan.baidu.com/s/1psP0vX4tsW52_DSlRlA0OQ?pwd=8j7i
提取码:8j7i
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/500661
推荐阅读

相关标签

