
- 1智能加速:AI光模块助力数据中心迈向400G/800G超高速率的新境界
- 2Android Studio学习笔记(二)_android studio笔记(二)
- 3如何安装llvm的比较新的版本_lib库llvmjit.so 升级
- 4中文词向量:使用pytorch实现CBOW_怎样查看torch里有没有cbow
- 5通过 docker-compose 快速部署 DolphinScheduler 保姆级教程_dolphinscheduler docker
- 6java final 修饰变量_Java笔记:final修饰符
- 7Facebook广告投放技巧及思路、如何最大化发挥广告效益!_fb广告先投awareness获得数据再跟帖投转化
- 8安全计算环境(设备和技术注解)_当远程管理云计算平台中设备时,管理终端和云计算平台之间应建立双向身份验证机制
- 951单片机课程设计——基于单片机的AD模数转换设计_51单片机ad是什么
- 10飞桨自然语言处理框架 paddlenlp的 trainer_paddlenlp.trainer中train
【自然语言处理】【细粒度情感分析】细粒度情感分析:了解文本情感的What、How、Why
赞
踩
论文地址:https://arxiv.org/pdf/1911.01616.pdf
一、细粒度情感分析
细粒度情感分析任务ABSA(Aspect Based Sentiment Analysis)的目标是解决各类情感分析任务,其包括任务ATE(Aspect Term Extraction)、OTE(Opinion Term Extraction)和ATC(Aspect Term Sentiment Classification)。举例说明一下这些任务。给定一个例句
Waiters are very friendly and the pasta is simply average.
\text{Waiters are very friendly and the pasta is simply average.}
Waiters are very friendly and the pasta is simply average.
ATE的目标是抽取
Waiters
\text{Waiters}
Waiters和
pasta
\text{pasta}
pasta,ATC的目标是为ATE抽取出的aspect进行情感分类,OTE是抽取导致情感极性的词
friendly
\text{friendly}
friendly和
average
\text{average}
average。
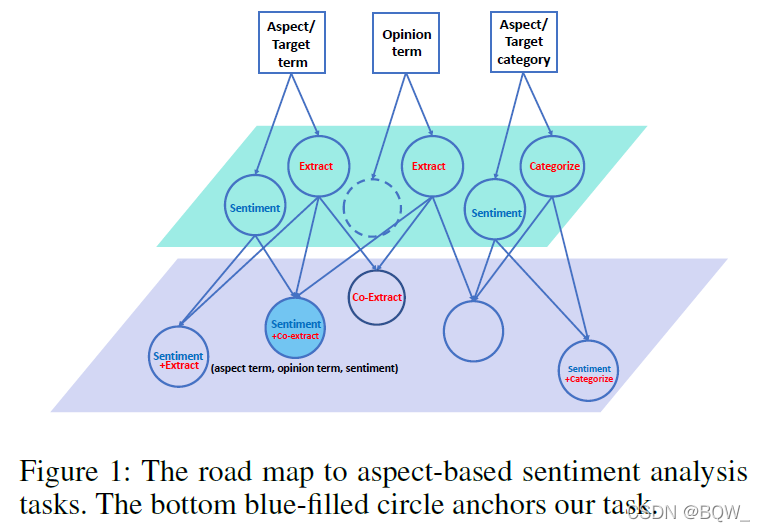
虽然这几个任务看起来容易混淆,但是任务边界其实十分清晰。如下图所示,顶上的三个正方形表示ABSA的三个目标,其中aspect term表示需要句子中要目前讨论的目标(waiter),opinion term表示评论观点的术语或者短语(friendly),aspect category表示将aspect分类到预先定义的类别,例如“服务”或者“食物”。
中间层的圆圈表示具体的子任务。研究人员认为独立去解决这些子任务是不够的,提出了两两成对解决这些子任务。但是,这样仍然不足以完成的描绘出整个情感的状态。例如,先前的例子中,能够确定 waiters \text{waiters} waiters是正向情感,但是无法给出为什么是正向的线索,只有确定了 friendly \text{friendly} friendly,才能真正理解导致情感正向的原因。Fan等人提出给定aspect,抽取对应opinion term的任务,该任务并不会预测情感。联合抽取aspect和opinion的任务也并不能解决二者间配对的问题。aspect抽取和情感分类联合任务中不能为aspect抽取opinion term。综合分析这些子任务的缺陷,论文提出了新的子任务ASTE(Aspect Sentiment Triplet Extraction),其在所有子任务中的位置如下图中的实心圆。
二、方法简介
新子任务ASTE,该任务的目标是从句子中抽取三元组(What,How,Why),其中What表示aspect,How表示情感极性,Why表示为什么具有这样的情感极性。例如从句子“Waiters are very friendly and the pasta is simply average”中抽取三元组(Waiters, positive, friendly)。
论文针对任务ASTE,提出了一种两阶段框架的解决方案。第一阶段,提取aspect term、opinion term以及判断情感极性。这个阶段会将任务转换为两个序列标注任务,一个序列标注任务用来确定aspect term及其情感极性,另一个序列标注则是用来确定opinion term。第二阶段,将aspect和opinion进行配对。
三、问题的形式化
给定一个长度为 T T T的句子 X = { x 1 , … , x T } X=\{x_1,\dots,x_T\} X={x1,…,xT},ASTE的任务是抽取情感三元组。
首先,会将aspect抽取及情感极性判断转换为一个统一的序列标注任务,标注的标签为 Y T S = \mathcal{Y}^{\mathcal{TS}}= YTS={B-POS, I-POS, E-POS, S-POS, B-NEG, I-NEG, E-NEG, S-NEG, B-NEU, I-NEU, E-NEU, S-NEU, O}。句子 X X X在这个统一的序列标注任务中会得到预测标签 Y T S = { y 1 T S , … , y T T S } , y i T S ∈ Y T S Y^{\mathcal{TS}}=\{y_1^{\mathcal{TS}},\dots,y_T^{\mathcal{TS}}\},y_i^{\mathcal{TS}}\in\mathcal{Y}^{\mathcal{TS}} YTS={y1TS,…,yTTS},yiTS∈YTS。
其次,opinion抽取也会转换为序列标注任务,标注标签为 Y O P T = { B,I,E,S } ∪ { O } \mathcal{Y}^{\mathcal{OPT}}=\{\text{B,I,E,S}\}\cup\{O\} YOPT={B,I,E,S}∪{O},对应于句子 X X X的预测标签为 Y O P T = { y 1 O P T , … , y T O P T } , y i O P T ∈ Y O P T Y^{\mathcal{OPT}}=\{y_1^{\mathcal{OPT}},\dots,y_T^{\mathcal{OPT}}\},y_i^{\mathcal{OPT}}\in\mathcal{Y}^{\mathcal{OPT}} YOPT={y1OPT,…,yTOPT},yiOPT∈YOPT。
最后,前面2个序列标注任务会得到aspect集合 { T 1 , T 2 , … , T n } \{T_1,T_2,\dots,T_n\} {T1,T2,…,Tn}和opinion集合 { O 1 , O 2 , . . . , O m } \{O_1,O_2,...,O_m\} {O1,O2,...,Om}。然后,两两配对得到aspect-opinion对集合 { ( T 1 , O 1 ) , ( T 1 , O 2 ) , . . . , ( T n , T m ) } \{(T_1,O_1),(T_1,O_2),...,(T_n,T_m)\} {(T1,O1),(T1,O2),...,(Tn,Tm)},然后从中选出正确的aspect-opinion对。
1. 抽取apsect并判断情感;2. 抽opinion;3. 判断aspect-opinion对
四、模型概览
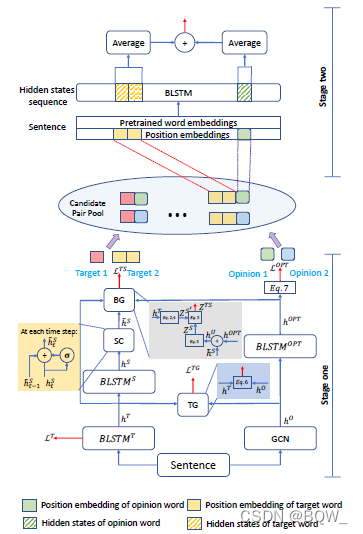
上图是整个模型的结构,其是一个两阶段的框架。第一阶段会预测两种类型的标签,分别是apsect边界和情感极性的统一标签 Y T S \mathcal{Y}^{\mathcal{TS}} YTS和opinion边界标签 Y O P T \mathcal{Y}^{\mathcal{OPT}} YOPT。具体来说,左边的模型包含两个堆叠的BiLSTM,用于预测 Y T S \mathcal{Y}^{\mathcal{TS}} YTS。下面的BiLSTM用于执行一个预测apsect的辅助任务,并将产生的辅助信号传递给上面的BiLSTM,上面的BiLSTM用于保证情感的连接性,并最终使用BG组件将所有的信息进行汇合后来预测统一标签。第一阶段右边的模型用于预测opinion的边界,即 Y O P T \mathcal{Y}^{\mathcal{OPT}} YOPT。整个句子会输入至GCN中,并通过aspect和opinion的依赖关系进行学习。然后,学习到的向量分别被输入至2个不同的模块 TG \text{TG} TG和 BiLSTM O P T \text{BiLSTM}^{OPT} BiLSTMOPT,TG模块会结合aspect的边界信息来预测opinion的边界, BiLSTM O P T \text{BiLSTM}^{OPT} BiLSTMOPT则直接预测opinion的边界。
第二阶段会基于第一阶段抽取的aspect和opinion来枚举所有可能的aspect-opinion对,然后基于apsect和opinion的相对距离来产生position embedding,利用BiLSTM编码后能够分别得到apsect和opinion的向量,将两者向量进行拼接后输入二分类器即可。
五、第一阶段
1. aspect抽取和情感极性判断
在上面“问题的形式化”中,将aspect抽取和情感判断转换成了统一标签 Y T S \mathcal{Y}^{\mathcal{TS}} YTS并使用序列标注进行解决。论文认为预测aspect的边界有助于预测整个统一标签 Y T S \mathcal{Y}^{\mathcal{TS}} YTS,因此会使用一个称为 B i L S T M T BiLSTM^{\mathcal{T}} BiLSTMT的双向LSTM来预测apsect的边界,预测的结果 Y T \mathcal{Y}^\mathcal{T} YT为 { B , I , E , S , O } \{B,I,E,S,O\} {B,I,E,S,O},且模型 B i L S T M T BiLSTM^{\mathcal{T}} BiLSTMT隐藏层的输出表示为 h T = [ LSTM → T ( x ) ; LSTM ← T ( x ) ] h^{\mathcal{T}}=[\text{LSTM}_{\rightarrow}^{\mathcal{T}}(x);\text{LSTM}_{\leftarrow}^{\mathcal{T}}(x)] hT=[LSTM→T(x);LSTM←T(x)]。随后, h T h^{\mathcal{T}} hT会被输入着一个称为 BiLSTM S \text{BiLSTM}^S BiLSTMS的双向LSTM来预测标签 Y S \mathcal{Y}^{\mathcal{S}} YS,其隐藏层输出为 h s = [ LSTM → S ( x ) ; LSTM ← S ( x ) ] h^s=[\text{LSTM}_{\rightarrow}^{S}(x);\text{LSTM}_{\leftarrow}^{S}(x)] hs=[LSTM→S(x);LSTM←S(x)]且 Y S \mathcal{Y}^{\mathcal{S}} YS={B-POS, I-POS, E-POS, S-POS, B-NEG, I-NEG, E-NEG, S-NEG, B-NEU, I-NEU, E-NEU, S-NEU}。(简单总结,第一层BiLSTM预测边界 Y T \mathcal{Y}^\mathcal{T} YT,隐藏层输出 h T h^{\mathcal{T}} hT,第二层BiLSTM输入 h T h^{\mathcal{T}} hT来预测 Y S \mathcal{Y}^{\mathcal{S}} YS,隐藏层输出为 h s h^s hs。预测 Y T \mathcal{Y}^\mathcal{T} YT是为了让预测 Y S \mathcal{Y}^{\mathcal{S}} YS的边界时更加准确。)
通常一个apsect是由多个token组成的,为了避免预测
Y
S
\mathcal{Y}^{\mathcal{S}}
YS时,多个token的情感不一致。因此,这里会通过gate机制实现一个称为Sentiment Consistency(SC)模块(BiLSTM机制包含三个gate,这里的gate感觉上有点多余)
g
t
=
σ
(
W
g
h
t
S
+
b
)
h
~
t
S
=
g
t
⊙
h
t
S
+
(
1
−
g
t
)
⊙
h
~
t
−
1
S
其中,
W
g
\textbf{W}^g
Wg和
b
g
\textbf{b}^g
bg是SC模块的模型参数,
⊙
\odot
⊙是element-wise乘法,
σ
\sigma
σ是sigmoid函数。通过该gate可以降低情绪标签剧烈变化的风险。
前面的
B
i
L
S
T
M
T
BiLSTM^{\mathcal{T}}
BiLSTMT会预测aspect的边界
Y
T
\mathcal{Y}^\mathcal{T}
YT并得到
h
T
h^{\mathcal{T}}
hT,若希望基于
Y
T
\mathcal{Y}^\mathcal{T}
YT来预测
Y
S
\mathcal{Y}^{\mathcal{S}}
YS,那么
Y
T
\mathcal{Y}^\mathcal{T}
YT中的标签会有三种转换情况。举例来说,若
B
i
L
S
T
M
T
BiLSTM^{\mathcal{T}}
BiLSTMT在某个位置预测的标签是B,那边该标签转换后的结果一定是B-POS、B-NEG、B-NEU中的一个。因此,这里使用一个基于转移矩阵实现的Boundary Guidance(BG)模块。该模块中存在一个可训练的转移矩阵
W
t
r
∈
R
∣
Y
T
∣
×
∣
Y
S
∣
\textbf{W}^{tr}\in\mathbb{R}^{|\mathcal{Y}^{\mathcal{T}}|\times |\mathcal{Y}^{\mathcal{S}}|}
Wtr∈R∣YT∣×∣YS∣,其中某一个具体取值
W
i
,
j
t
r
\textbf{W}_{i,j}^{tr}
Wi,jtr表示从标签
Y
T
i
\mathcal{Y}^{\mathcal{T}_i}
YTi转移至标签
Y
S
j
\mathcal{Y}^{\mathcal{S}_j}
YSj的概率。具体的过程为
z
t
T
=
p
(
y
t
T
∣
x
t
)
=
Softmax
(
W
T
h
t
T
)
z
t
S
′
=
(
W
t
r
)
⊤
z
t
T
其中,
W
T
\textbf{W}^{\mathcal{T}}
WT是可训练参数,
z
t
S
′
z_t^{S'}
ztS′是获得的统一标签概率分布。(
z
t
S
′
z_t^{S'}
ztS′不是最终的统一标签概率,只是其中一部分,之后还会进行一个合并。)
z
t
S
′
z_t^{S'}
ztS′在预测统一标签时并没有合并opinion的信息,显然opinion信息对于预测apsect的位置会有很大的帮助。因此这里会将带有opinion信息的向量
h
O
P
T
h^{\mathcal{OPT}}
hOPT(后面会介绍怎么得到该向量)和
h
~
t
S
\tilde{h}_t^S
h~tS进行拼接合并,得到一个更强大的向量
h
U
h^\mathcal{U}
hU,然后基于
h
U
h^\mathcal{U}
hU在预测一次统一标签的概率分布,
z
t
S
=
p
(
y
t
S
∣
x
t
)
=
Softmax
(
W
S
h
t
U
)
z_t^S=\textbf{p}(y_t^S|x_t)=\text{Softmax}(\textbf{W}^Sh_t^{\mathcal{U}})
ztS=p(ytS∣xt)=Softmax(WShtU)
现在,有两个统计标签的预测概率,分布是
z
t
S
z_t^S
ztS和
z
t
S
′
z_t^{S'}
ztS′,现在讨论怎么将两者结合在一起。这里希望学习到一个权重,两者按这个权重进行加权求和。
这里的权重分
α
t
∈
R
\alpha_t\in\mathbb{R}
αt∈R的计算是基于称为apsect边界集中度分
c
t
c_t
ct,具体来说
c
t
=
(
z
t
T
)
⊤
z
t
T
α
t
=
ϵ
c
t
其中,
c
t
c_t
ct是一个0到1的值,其越大表示模型在预测边界时的置信度越高,
ϵ
\epsilon
ϵ是一个超参数。
最终预测统一标签的概率分布为
z
t
T
S
=
α
t
z
t
S
′
+
(
1
−
α
t
)
z
t
S
z_t^{\mathcal{TS}}=\alpha_t z_t^{\mathcal{S'}}+(1-\alpha_t)z_t^{\mathcal{S}}
ztTS=αtztS′+(1−αt)ztS
2. opinion 抽取
前面介绍了aspect抽取和情感极性判断,这里会介绍opinion抽取的内容。此外,前面在预测 z t S z_t^S ztS时,使用了 h O P T h^{\mathcal{OPT}} hOPT,因此本部分也会介绍该向量的由来。
先前的一些研究表明aspect抽取和opinion抽取是互利的,而且直观上也能够判断aspect和opinion是经常共现的。因此,这里希望利用apsect的信息来指导opinion的抽取。具体来说,这里会将句子进行embedding,然后输入至GCN中来学习不同词之间的依赖。GCN的邻接矩阵是基于句子的依赖解析构造的,称为 W G C N ∈ R ∣ L ∣ × ∣ L ∣ \textbf{W}^{GCN}\in\mathbb{R}^{|\mathcal{L}|\times |\mathcal{L}|} WGCN∈R∣L∣×∣L∣,其中 L \mathcal{L} L是句子的长度。例如,第 i i i个单词和第 j j j个单词具有依赖关系,那么 W i , j G C N \textbf{W}^{GCN}_{i,j} Wi,jGCN和 W j , i G C N \textbf{W}_{j,i}^{GCN} Wj,iGCN均有值1,否则为0。(GCN输出的向量表示为 h O h^{\mathcal{O}} hO)
为了能够利用apsect信息来辅助opinion抽取,这里设计了一个辅助任务来集成aspect的边界信息和GCN的输出,称这部分为Target Guidance(TG)模块。具体来说,就是将apsect边界预测的隐向量
h
T
h^{\mathcal{T}}
hT和GCN输出的向量
h
O
h^{\mathcal{O}}
hO进行拼接,然后用于预测opinion的边界
Y
T
G
=
{
B
,
I
,
E
,
S
}
∪
{
O
}
\mathcal{Y}^{\mathcal{TG}}=\{B,I,E,S\}\cup\{O\}
YTG={B,I,E,S}∪{O},
z
t
T
G
=
p
(
y
t
O
P
T
∣
x
t
)
=
Softmax
(
W
T
G
[
h
t
T
;
h
t
O
]
)
z_t^{\mathcal{TG}}=\textbf{p}(y_t^{\mathcal{OPT}}|x_t)=\text{Softmax}(\textbf{W}^{\mathcal{TG}}[h_t^{\mathcal{T}};h_t^{\mathcal{O}}])
ztTG=p(ytOPT∣xt)=Softmax(WTG[htT;htO])
除了将
h
O
h^{\mathcal{O}}
hO与
h
T
h^{\mathcal{T}}
hT合并外,另一部分是将
h
O
h^{\mathcal{O}}
hO送入一个称为
B
i
L
S
T
M
OPT
BiLSTM^{\text{OPT}}
BiLSTMOPT的双向LSMT中,然后输出一个上下文编码向量
h
O
P
T
h^{OPT}
hOPT(前面计算
h
U
h^\mathcal{U}
hU会用到),然后利用其进行opinion边界预测
z
t
O
P
T
=
p
(
y
t
O
P
T
∣
x
t
)
=
Softmax
(
W
O
P
T
h
t
O
P
T
)
z_t^{\mathcal{OPT}}=\textbf{p}(y_t^{\mathcal{OPT}}|x_t)=\text{Softmax}(\textbf{W}^{\mathcal{OPT}}h_t^{\mathcal{OPT}})
ztOPT=p(ytOPT∣xt)=Softmax(WOPThtOPT)
3. 训练
前面的过程会输出
z
t
T
z_t^{\mathcal{T}}
ztT、
z
t
T
S
z_t^{\mathcal{TS}}
ztTS、
z
t
T
G
z_t^{\mathcal{TG}}
ztTG和
z
t
O
P
T
z_t^{\mathcal{OPT}}
ztOPT,这里使用交叉熵计算损失函数
L
I
=
−
1
T
∑
t
=
1
T
I
(
y
t
I
,
g
)
∘
l
o
g
(
z
t
I
)
\mathcal{L}^{\mathcal{I}}=-\frac{1}{T}\sum_{t=1}^T\mathbb{I}(y_t^{\mathcal{I,g}})\circ log(z_t^{\mathcal{I}})
LI=−T1t=1∑TI(ytI,g)∘log(ztI)
其中,
I
\mathcal{I}
I是任务指示符和其可能的取值
T
,
T
S
,
T
G
,
O
P
T
\mathcal{T,TS,TG,OPT}
T,TS,TG,OPT,
I
(
y
)
\mathbb{I}(y)
I(y)表示one-hot编码,
y
t
I
,
g
y_t^{\mathcal{I,g}}
ytI,g表示任务
I
\mathcal{I}
I在时间步t处的标签。总的损失函数为所有损失函数之和
J
(
θ
)
=
L
T
+
L
T
S
+
L
T
G
+
L
O
P
T
\mathcal{J}(\theta)=\mathcal{L}^{\mathcal{T}}+\mathcal{L}^{\mathcal{TS}}+\mathcal{L}^{\mathcal{TG}}+\mathcal{L}^{\mathcal{OPT}}
J(θ)=LT+LTS+LTG+LOPT
总结:
L
T
\mathcal{L}^{\mathcal{T}}
LT用于计算aspect的边界,
L
T
S
\mathcal{L}^{\mathcal{TS}}
LTS用于结合opinion信息计算apsect边界和情感极性,
L
T
G
\mathcal{L}^{\mathcal{TG}}
LTG用于结合apsect边界信息计算opinion的边界,
L
O
P
T
\mathcal{L}^{\mathcal{OPT}}
LOPT用于直接计算opinion的边界。
六、第二阶段
经过第一阶段后,每个句子都会输出两个标签集合,分别是apsect和opinion,记为 { T 1 , T 2 , … , T n } \{T_1,T_2,\dots,T_n\} {T1,T2,…,Tn}和 { O 1 , O 2 , … , O m } \{O_1,O_2,\dots,O_m\} {O1,O2,…,Om},其中 n n n和 m m m表示数量。枚举所有可能的aspect-opinion对来生成候选对池 { ( T 1 , O 1 ) , ( T 2 , O 2 ) , … , ( T n , O m ) } \{(T_1,O_1),(T_2,O_2),\dots,(T_n,O_m)\} {(T1,O1),(T2,O2),…,(Tn,Om)},接下来就是判断每个aspect-opinion对是否有效。
1. 位置嵌入(position embedding)
为了能够利用aspect和opinion的位置关系,这里会计算aspect中心词至opinion中心词之间单词的数量,用于表示两者的距离。为了便于训练,将aspect和opinion间的距离当做其位置索引,从而创建出position embedding(位置嵌入)。索引为0表示该单词既不是apsect,也不是opinion。可以观察下表中的 ( W a i t e r , f r i e n d l y ) (Waiter,friendly) (Waiter,friendly)和 ( f u g u s a s h i m i , f r i e n d l y ) (fugu sashimi,friendly) (fugusashimi,friendly)的位置索引。

2. 成对编码与分类
这里将Glove词向量和position embedding进行拼接,然后输入至BiLSTM层来编码aspect和opinion上下文信息。将aspect和opinion位置输出的词向量进行各自平均,并将得到的2个向量进行拼接。最后将拼接后的向量送至softmax层进行分类。
训练时使用标注好的aspect-opinion对,测试时直接使用模型在候选对池上进行预测。


