
- 1Linux内核系统架构介绍_linux是什么架构
- 2第61天-服务攻防-中间件安全&CVE 复现&K8s&Docker&Jetty&Websphere_cve-2021-28164
- 3使用PyQt实现XAMPP或phpStudy类似功能
- 4面向对象思想实现图书管理系统_现需要开发以“图书管理系统”,请采用第四章学习的面向对象方法进行设计,并提
- 5【计算机毕业设计】基于微信小程序的大学生心理测评系统_心理测试 小程序 设计
- 6机器学习面试题_高度相关关系可以用支持向量机吗
- 7内涵:YOLO系列解读(上)-----YOLOv1到YOLOv3梳理_2015年yolo
- 8React----中后台管理项目开发_中后台开发
- 9四、Flink使用广播状态和定时器实现word_join_count有效时间1分钟_flink 定时器
- 10北林计算机分数,2021北京林业大学录取分数线-北京林业大学分数线-2021北京林业大学录取查询网址...
Python课程设计,爬取保险公司相关信息进行数据分析(包括数据清洗、数据处理和可视化)_保险理赔数据集特点分析
赞
踩
一、选题背景
研究保险领域。现已知保险公司的相关数据,研究数据表的相关信息,找出各元素之间的相关关系,并判断未来保险投保的年龄群体,投保人的年收入情况,以及年收入、年龄等元素对是否购买保险的影响,以及所买保险种类的影响,预测未来的保险发展趋势,安排提供给不同年龄、不同收入群体的保险。
二、数据集特点分析
保险公司理赔数据集,已对姓名、电话号码进行脱敏处理。 性别 SEX 地区 REGION 年龄 AGE 月收入 MONTHLY_INCOME 年收入 ANNUAL_INCOME 学历 EDUCATIONAL_BACKGROUND 身体状态 PHYSICAL_STATE 保险理赔日期 INSURANCE_CLAIM_DATA 理赔状态 STATE 保险单号 INSURANCE_UNID 索赔失败原因 REASON 保险赔付费 PAYMENT_AMOUNT 保险种类 INSURANCE_TYPE 有效时间 EFFECTIVE_TIME。
大部分人的年收入中等偏下,极少部分人收入高。姓名、年龄、性别、地区等基本信息有相同的。索赔失败原因有空值。
三、数据导入及清洗
1数据源
https://tianchi.aliyun.com/dataset/142922
2导入包、导入数据集。
data = pd.read_excel("D:/课设/data.xls",header = None,names=['sex','NAME','AGE','REGION','INSURANCE_CLAIM_DATA','MONTHLY_INCOME','ANNUAL_INCOME','TELEPHONEs','PHYSICAL_STATE','INSURANCE_UNID','STATE','REASON','PAYMENT_AMOUNT','INSURANCE_TYPE'])3数据清洗
1、去重
利用drop函数按姓名去重。(最好使用具有唯一标识的属性去重,例如:手机号,到由于存在一些问题,因此这里使用按姓名去重。)
data.drop_duplicates(subset=['NAME'],keep='first',inplace=True)2、删除空值
利用dropna函数进行删除有空值的数据。
- data=data.dropna(axis=0,subset=['SEX'])
- data=data.dropna(axis=0,subset=['NAME'])
- data=data.dropna(axis=0,subset=['AGE'])
- data=data.dropna(axis=0,subset=['REGION'])
- data=data.dropna(axis=0,subset=['INSURANCE_CLAIM_DATA'])
- data=data.dropna(axis=0,subset=['MONTHLY_INCOME'])
- data=data.dropna(axis=0,subset=['ANNUAL_INCOME'])
- data=data.dropna(axis=0,subset=['PHYSICAL_STATE'])
- data=data.dropna(axis=0,subset=['INSURANCE_UNID'])
- data=data.dropna(axis=0,subset=['STATE'])
- data=data.dropna(axis=0,subset=['REASON'])
- data=data.dropna(axis=0,subset=['PAYMENT_AMOUNT'])
- data=data.dropna(axis=0,subset=['INSURANCE_TYPE'])
3、条件删除
利用loc函数删除年收入小于等于0的数据。
- query =data.loc[:,'ANNUAL_INCOME']>0
- data=data.loc[query,:]
4、重置索引
利用reset函数进行索引的重置
data=data.reset_index()5、排序
利用sort函数按年收入排序。
data=data.sort_values(by='ANNUAL_INCOME',ascending=False,na_position='last')四、数据分析及可视化
数据分析
1、定义分隔函数
定义函数splityear函数,获得投保的年份。
- #分隔
- def splityear(timeseries):
- timelist=[]
- for val in timeseries:
- timelist.append(str(val).split('-')[0])
- res=pd.Series(timelist)
- return res
- data['INSURANCE_CLAIM_DATA']=splityear(data['INSURANCE_CLAIM_DATA'])
2、获取一共的保险理赔年份的信息。
- #先对所有记录按照年份降序排序
- data=data.sort_values(by='INSURANCE_CLAIM_DATA',ascending=False,na_position='last')
- #获取第一行记录减去最后一行记录
- min=data.loc[data.shape[0]-1,'INSURANCE_CLAIM_DATA']
- max=data.loc[0,'INSURANCE_CLAIM_DATA']
- year=int(max)-int(min)+1
- print(year)
3、求所求数据的平均年收入
- #求平均
- sum=data.loc[:,'ANNUAL_INCOME'].sum()
- prople=data.shape[0]
- average=sum/prople
- print(average)
4、求非贫困率(富有率)PS:不具有代表性,只希望能够掌握方法。
定义年收入大于40000即为非贫困人口。
- #非贫困率
- st=data.loc[data['ANNUAL_INCOME']>40000]
- feipin=st.shape[0]/prople
- print(str(feipin*100)+'%')
- print(str(int(feipin*100))+'%')
可视化
1生成图表,设置可以正常显示中文和负数。并确定画布的大小。
画布根据自己的需要确定
- #生成图表
- plt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签
- plt.rcParams['axes.unicode_minus']=False # 默认是使用Unicode负号,设置正常显示字符,如正常显示负号
- plt.figure(figsize=[12,4])
2、生成散点图
按照横坐标为年龄,纵坐标为年收入,判断年龄和年收入的关系。
- x=data['AGE']
- y = data['ANNUAL_INCOME']
- plt.scatter(x,y)
- plt.title('年龄和年收入的关系')
- plt.xlabel('年龄')
- plt.ylabel('年收入')
3、展示图表
plt .show()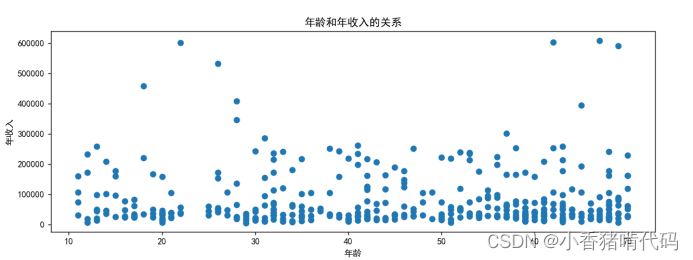
试着分析一下图标,由图表分析可知,每一个年龄的收入,大部分人的收入都为中等偏下,少部分人年收入很高。
代码清单
现在这里注释一下
请确定下载好第三方库
pandas
numpy
matplotlib
openpxyl
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- #读取文件
- data = pd.read_excel("D:/课设/data.xls",header = None,names=['sex','NAME','AGE','REGION','INSURANCE_CLAIM_DATA','MONTHLY_INCOME','ANNUAL_INCOME','TELEPHONEs','PHYSICAL_STATE','INSURANCE_UNID','STATE','REASON','PAYMENT_AMOUNT','INSURANCE_TYPE'])
-
- #随机抽取数据
- data = data.take(indices=np.random.permutation(data.shape[0]))[0:5000]
-
- #修改列名称
- changename ={'sex':'SEX'}
-
- #重命名列名称
- data.rename(columns=changename,inplace=True)
-
- #去重 NAME
- data.drop_duplicates(subset=['NAME'],keep='first',inplace=True)
-
- #删除空值
- data=data.dropna(axis=0,subset=['SEX'])
- data=data.dropna(axis=0,subset=['NAME'])
- data=data.dropna(axis=0,subset=['AGE'])
- data=data.dropna(axis=0,subset=['REGION'])
- data=data.dropna(axis=0,subset=['INSURANCE_CLAIM_DATA'])
- data=data.dropna(axis=0,subset=['MONTHLY_INCOME'])
- data=data.dropna(axis=0,subset=['ANNUAL_INCOME'])
- data=data.dropna(axis=0,subset=['PHYSICAL_STATE'])
- data=data.dropna(axis=0,subset=['INSURANCE_UNID'])
- data=data.dropna(axis=0,subset=['STATE'])
- data=data.dropna(axis=0,subset=['REASON'])
- data=data.dropna(axis=0,subset=['PAYMENT_AMOUNT'])
- data=data.dropna(axis=0,subset=['INSURANCE_TYPE'])
-
- #条件删除记录 年收入不为0
- query =data.loc[:,'ANNUAL_INCOME']>0
- data=data.loc[query,:]
-
- #重置索引
- data=data.reset_index()
-
- #排序
- data=data.sort_values(by='ANNUAL_INCOME',ascending=False,na_position='last')
-
- #分隔
- def splityear(timeseries):
- timelist=[]
- for val in timeseries:
- timelist.append(str(val).split('-')[0])
- res=pd.Series(timelist)
- return res
- data['INSURANCE_CLAIM_DATA']=splityear(data['INSURANCE_CLAIM_DATA'])
-
- #先对所有记录按照年份降序排序
- data=data.sort_values(by='INSURANCE_CLAIM_DATA',ascending=False,na_position='last')
- #获取第一行记录减去最后一行记录
- min=data.loc[data.shape[0]-1,'INSURANCE_CLAIM_DATA']
- max=data.loc[0,'INSURANCE_CLAIM_DATA']
- year=int(max)-int(min)+1
- print(year)
-
- #求平均
- sum=data.loc[:,'ANNUAL_INCOME'].sum()
- prople=data.shape[0]
- average=sum/prople
- print(average)
-
- #非贫困率
- st=data.loc[data['ANNUAL_INCOME']>40000]
- feipin=st.shape[0]/prople
- print(str(feipin*100)+'%')
- print(str(int(feipin*100))+'%')
-
- #生成图表
- plt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签
- plt.rcParams['axes.unicode_minus']=False # 默认是使用Unicode负号,设置正常显示字符,如正常显示负号
- plt.figure(figsize=[12,4])
-
- #画图
- #散点图
- x=data['AGE']
- y = data['ANNUAL_INCOME']
- plt.scatter(x,y)
- plt.title('年龄和年收入的关系')
- plt.xlabel('年龄')
- plt.ylabel('年收入')
-
- #展示图表
- plt .show()
-
- 生成新文件
- data.to_csv('D:/课设/2.excel')

六、课程设计总结
通过本次课程设计,我深刻掌握了python进行数据清晰、数据分析方面的知识。本学期实训课与Python语言课相结合,以上机实验操作为主,加深了我对Python语言的理解和运用能力,帮助我解决了许多Python语言学习时遇到的问题。通过在学习时遇到的问题查找资料使我接触和了解了更多课本以外的知识。特别是最后的大实训,让我对所学的知识进行了实战应用,加深了对知识的理解,让我认识到实践的重要性,同时还得出一个结论:知识必须通过应用才能实现其价值!有些东西以为学会了,但真正到用的时候才发现是两回事,所以我认为只有到真正会用的时候才是真的学会了。
在完成本次课设后,我会更加热爱Python语言的学习,广泛的把其应用到个个学习的地方,我会继续努力的!
朋友、加油,希望对你有一些帮助。

