
热门标签
热门文章
- 1陀螺仪传感器建模与卡尔曼姿态解算_陀螺仪角度计算公式
- 2阿里六面,挂在hrg,我真的不甘心!_hrg面试完没谈薪水
- 3Python爬虫需要学多久?
- 4【阿里云IoT+YF3300】14.阿里IoT Studio打造手机端APP_iot studio增值服务制作app
- 5Python基础知识总结(期末复习精简版)_华中农业大学python考试
- 6HBuilder X运行uni-app项目到微信开发者工具_小程序运行到微信开发者工具
- 7区块链 web3.0 Metamask_web3.0metamask介绍
- 8Python 语音识别系列-实战学习-DFCNN_Transformer的实现
- 9FPGA至简设计法之一:D触发器、波形、代码_基本d触发器verilog结构描述
- 10动态规划 第1关:数塔问题_第1关:数塔问题
当前位置: article > 正文
云原生基础设施和操作系统分论坛 03-在Kubernetes上运行Apache Spark进行大规模数据处理的实践【数据分析】
作者:繁依Fanyi0 | 2024-05-14 06:42:43
赞
踩
云原生基础设施和操作系统分论坛 03-在Kubernetes上运行Apache Spark进行大规模数据处理的实践【数据分析】
简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。


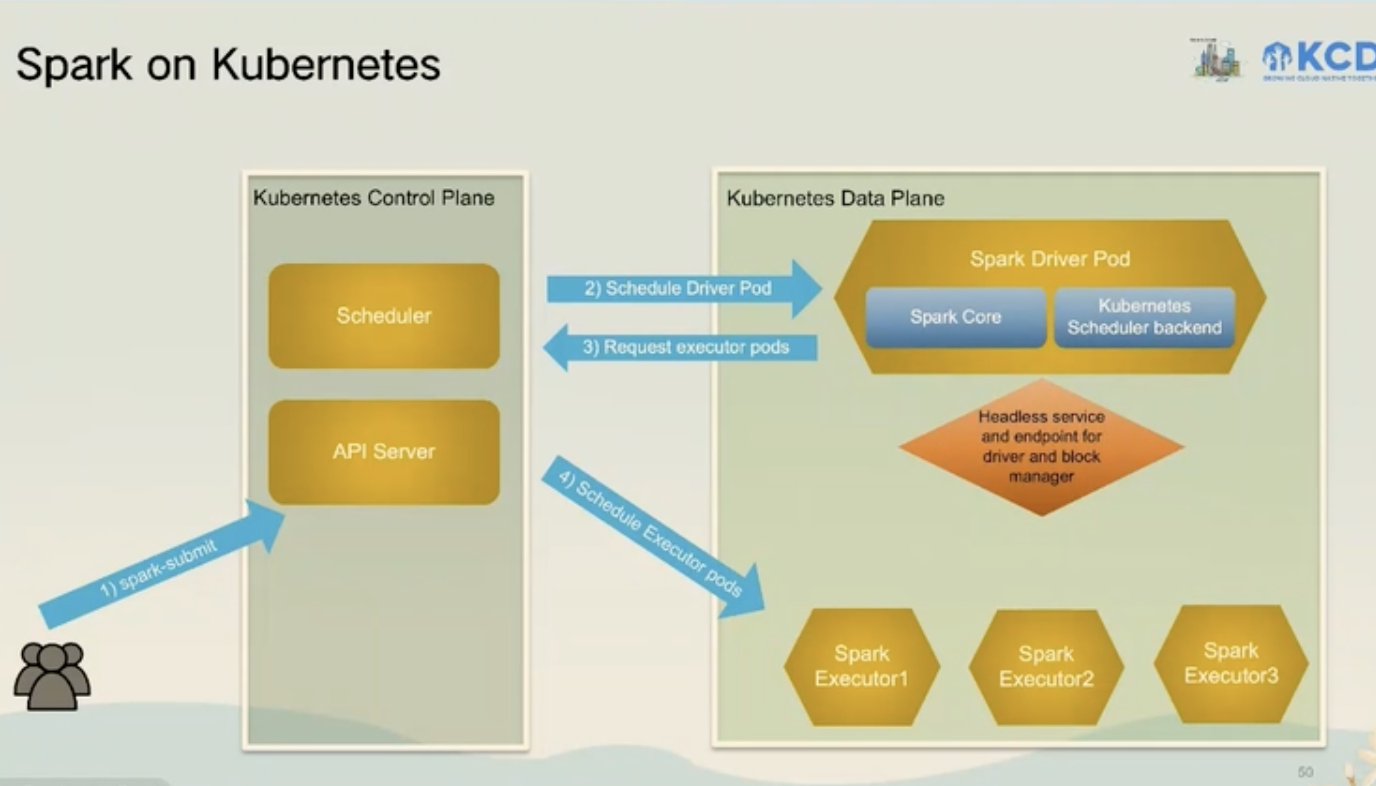

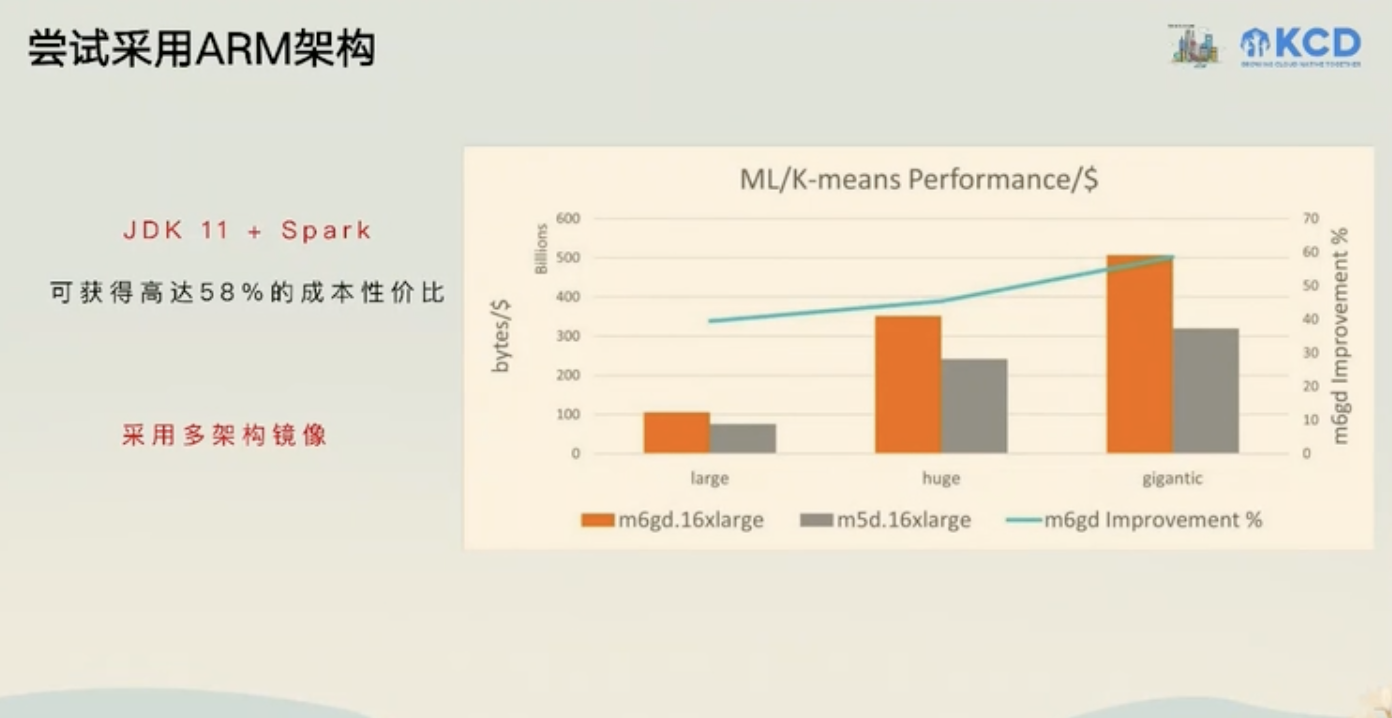
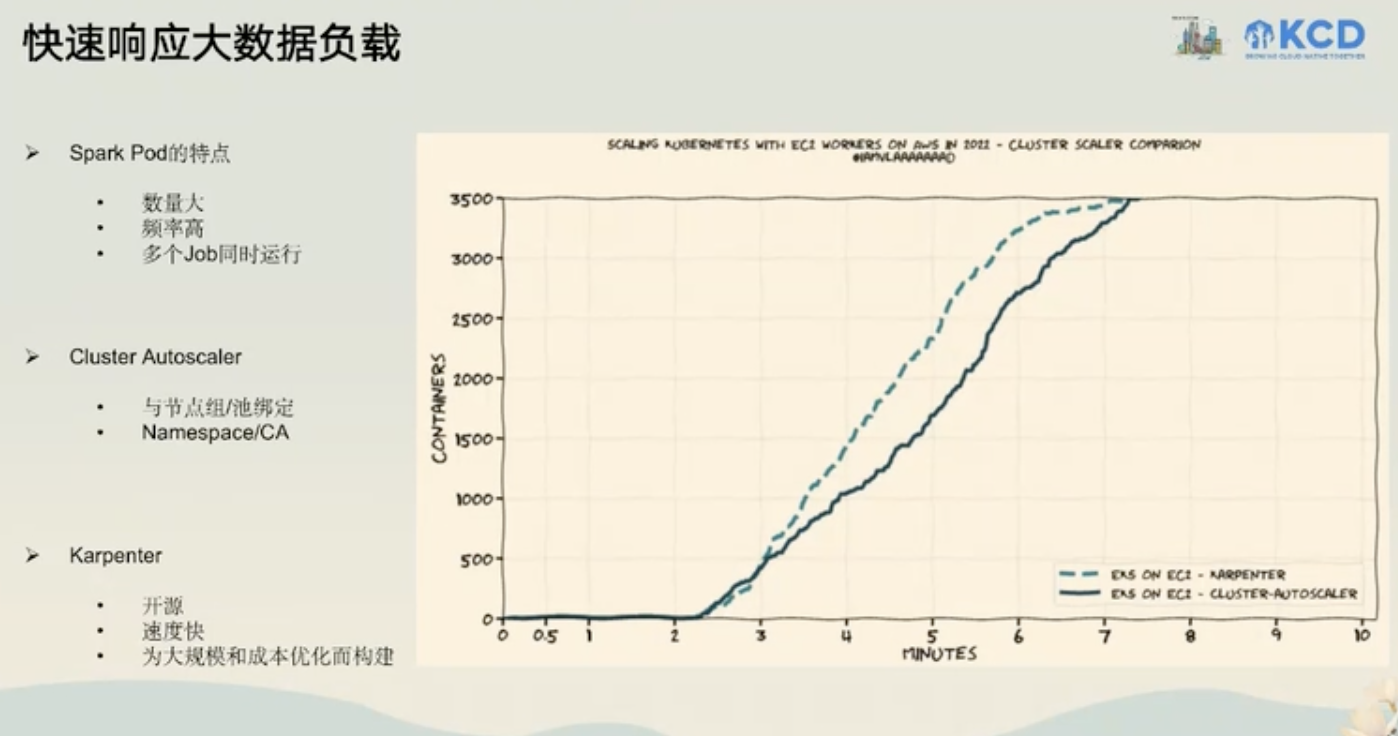
计算与基础设施

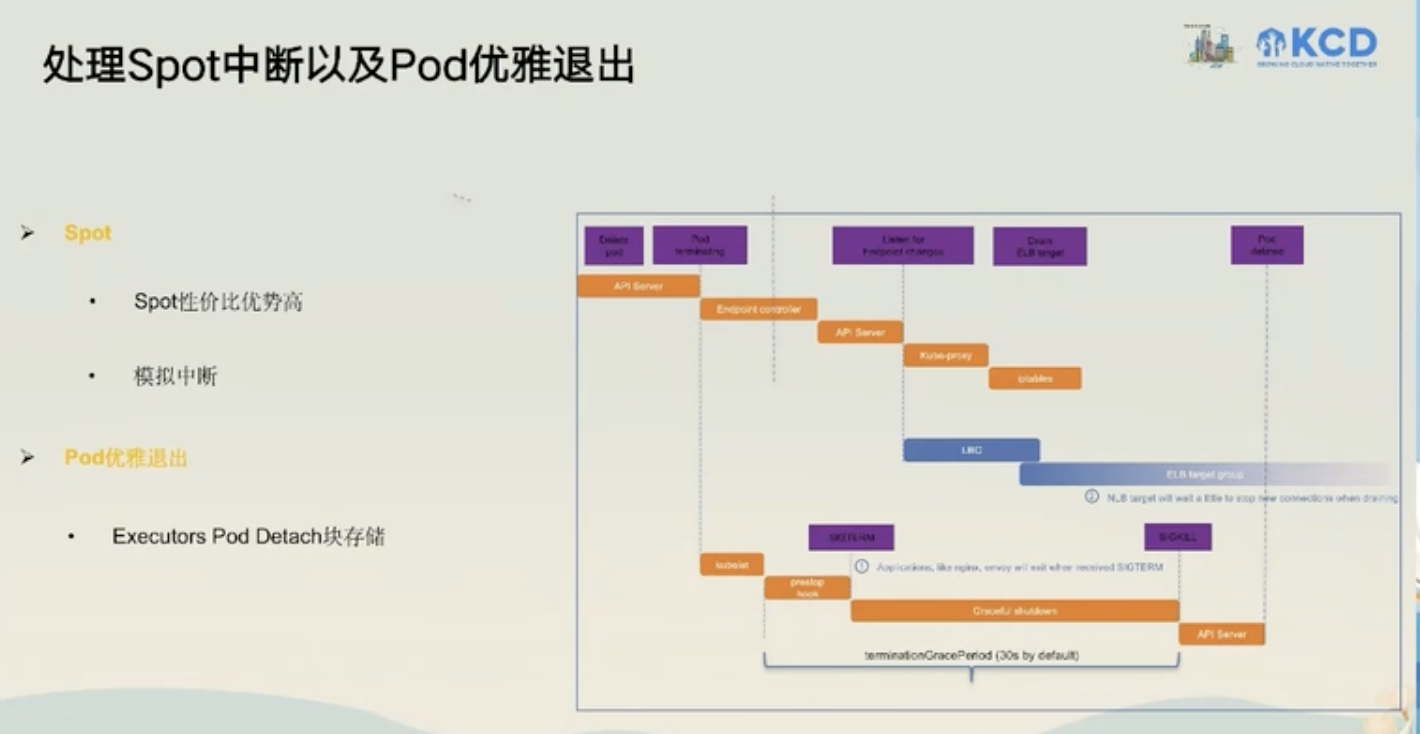



可观测性



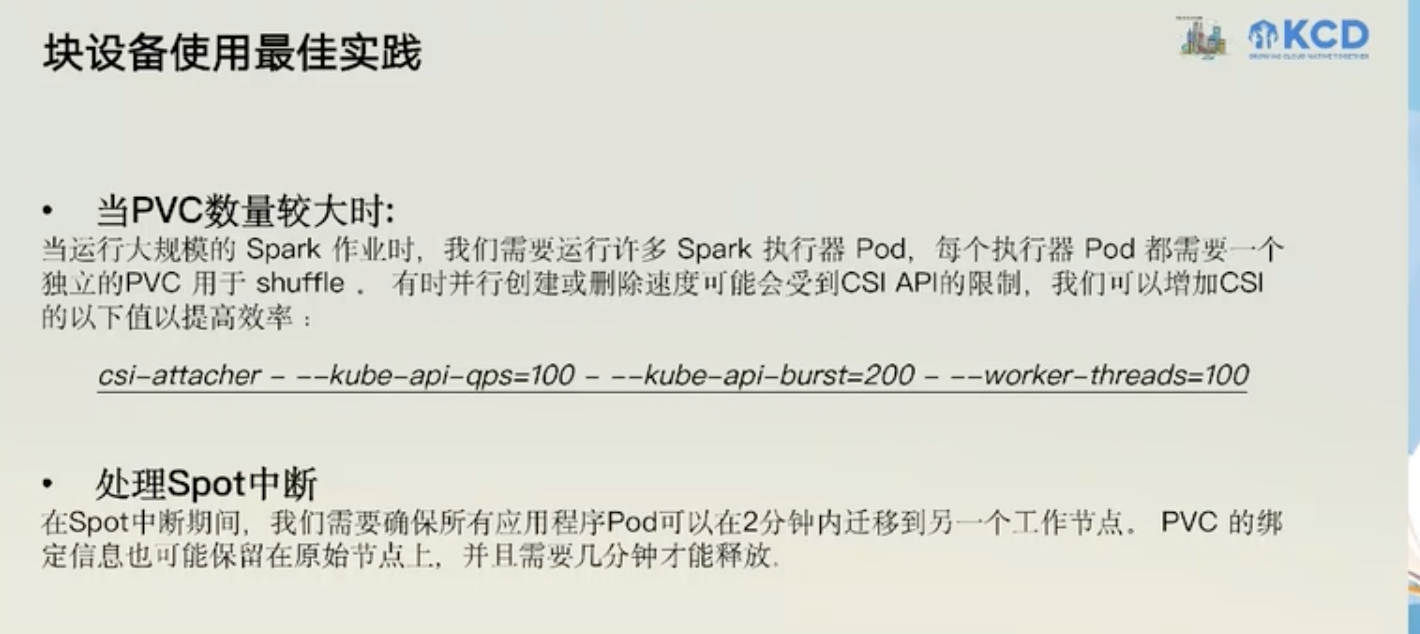
存储


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/567758
推荐阅读
相关标签

