
热门标签
热门文章
- 1Ubuntu 18.04 环境下编译Android 源码_ubuntu18.04编译android8
- 2Redhat 8更换yum网络源(aliyun)_redhat8更换yum源
- 3Adobe Media Encoder ME v24.3.0 解锁版 (视频和音频编码渲染工具)
- 4OfficeToolPlus工具分享
- 5[第四课笔记]XTuner 大模型单卡低成本微调实战_大模型微调需要什么配置
- 6Hadoop集群环境搭建与应用回顾_基于hadoop平台的搭建和应用
- 7android studio使用教程_android studio怎么做在线客服
- 8git拉取远程分支到本地(本地不存在的分支)_git切换到本地没有的分支
- 9头歌(educoder)第 4 章 Java入门之方法 Java入门 - 方法的使用_头歌java入门方法的使用答案
- 10考研经验分享
当前位置: article > 正文
实验5 Spark SQL 编程初级实践_spark sql编程初级实践
作者:凡人多烦事01 | 2024-05-18 17:01:05
赞
踩
spark sql编程初级实践
实验5 Spark SQL 编程初级实践
一、实验目的
(1)通过实验掌握Spark SQL的基本编程方法。
(2)熟悉RDD到DataFrame的转化方法。
(3)熟悉利用Spark SQL管理来自不同数据源的数据。
二、实验平台
操作系统:Linux
Spark版本:2.4.5
scala版本:2.11.8
三、实验内容和要求
1.Spark SQL基本操作
将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
文件内容如下:
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2 , "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
为employee.json创建DataFrame,并写出Scala语句完成下列操作:
//导入相应的包
import spark.implicits._
//读取文件
val df=spark.read.json("hdfs://master1:9000/spark/employee.json")
- 1
- 2
- 3
- 4
- 5
(1)查询所有数据;
df.show()
- 1

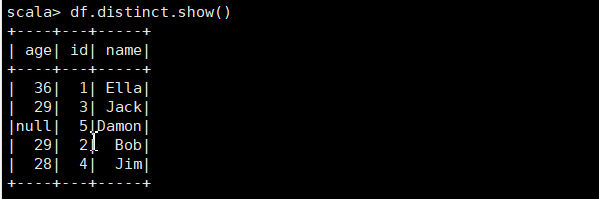
(2)查询所有数据,并去除重复的数据;
df.distinct.show()
- 1
(3)查询所有数据,打印时去除id字段;
df.drop("id").show()
- 1

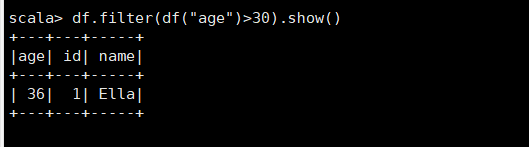
(4)筛选出age>30的记录;
df.filter(df("age")>30).show()
- 1
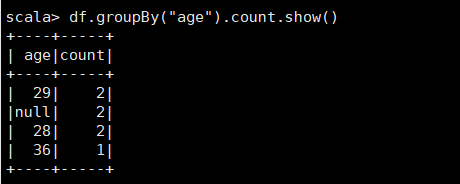
(5)将数据按age分组;
df.groupBy("age").count.show()
- 1
(6)将数据按name升序排列;
df.orderBy("name").show()
或者
df.sort(df("name").asc).show()
- 1
- 2
- 3


(7)取出前3行数据;
df.take(3)
df.limit(3).show
- 1
- 2

(8)查询所有记录的name列,并为其取别名为username;
df.select(df("name").as("username")).show()
- 1

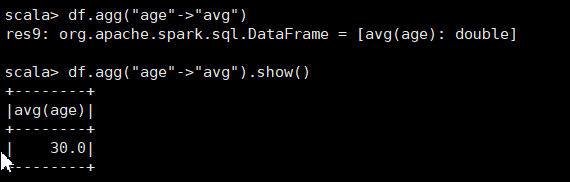
(9)查询年龄age的平均值;
df.agg("age"->"avg").show()
- 1
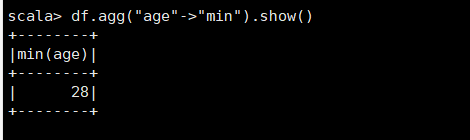
(10)查询年龄age的最小值。
df.agg("age"->"min").show()
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/589193
推荐阅读
相关标签

