
- 1一文看懂人工智能行业
- 2Git常用操作入门——续(远程仓库)_git远程库别名怎么看
- 3WSL的安装及docker-desktop目录迁移_wsl --import docker-desktop
- 4uniapp 开发微信小程序 出现启用组件按需注入问题如何解决_微信小程序开发按需注入
- 5「iOS」怎么修改去掉Navigation Bar上的返回按钮文本颜色,箭头颜色以及导航栏按钮的颜色_消除颜色type_navigation_bar
- 6Ubuntu如何更换 PyTorch 版本
- 7【Python数据分析与可视化】Pandas统计分析-实训_用pandas完成以下操作:(2)查看数据的描述信息(3)分析男性顾客和女性顾客谁更慷慨
- 8【毕业设计】基于zigbee的智能家居系统 - 单片机 物联网 stm32_基于zigbee的物联网智能家居控制
- 9leetcode16-3Sum Closest
- 10OpenWrt网络配置详解_openwrt设置
Hadoop集群环境搭建与应用回顾_基于hadoop平台的搭建和应用
赞
踩
一、 实训项目名称
Hadoop集群环境搭建与应用
二、 学习情况小结
实操一部分:
- 通过为期两周的大数据实践,我学会了利用三台虚拟机作服务器搭建Hadoop集群环境,创建并使用脚本启动namenode、datanode等进程。
- 正确搭建集群环境需有以下进程:
第一台虚拟机上:NameNode、DataNode、NodeManager、JobHistoryServer;
第二台虚拟机上:DataNode、ResourceManager、NodeManager;
在第三台虚拟机上:DataNode 、SecondaryNameNode、NodeManager。
- 使用脚本实现群起集群,需配置
SSH无密登录,需将本虚拟机机器上生成的公钥拷贝到要免密登录的目标机器上。 配置历史服务器和日志的聚集,需重新启动集群生效,从而查看查看程序的历史运行情况,方便开发调试。
实操二部分:
- 通过配置hadoop安装目录下的
capacity-scheduler.xml可配置多队列的容量调度器,重启Yarn刷新队列,就可以看到多条队列。 - 默认的任务提交都是提交到default队列的,向其他队列提交任务需自行指定目标队列。
- 在资源紧张时
为job任务设置优先级,优先级高的job任务会相对优先级低的job任务优先获取资源,从而更快的完成该任务。
三、 项目中用到的知识点
实操一部分:
- 所用Hadoop运行模式为本地模式,即单机运行,可用来演示一下官方案例,如wordcount计数每个单词出现的次数。
- 配置ssh免密登录可实现三台虚拟机之间的相互登录与切换,其原理是
将id_rsa.pub里的公钥存放到目标机器的authorized_keys(存放授权过的无密登录服务器公钥)上。 - 配置端口号部分:
HDFS NameNode内部端口:8020;
HDFS NameNode对外查询端口: 9870;
YARN 查看任务运行情况的端口:8088;
JobHistoryServer对外查询端口:19888。
实操二部分:
- 刷新队列也可执行
yarn rmadmin -refreshQueues刷新,就可以在yarn对应的Scheduler页面看到多条队列。 - 配置多队列后,向其他队列提交任务可使用
-D mapreduce.job.queuename=指定目标队列。 - 可使用
-D mapreduce.job.priority=n来设置该任务的优先级,n为优先级数,在资源紧张时,优先级高的任务将优先获取资源完成该任务。
四、 实训项目中负责功能板块
实操一部分:
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
2)安装1.8版本的JDK
3)配置/etc/profile.d/目录下my_env.sh的linux系统可识别的环境变量
4)安装hadoop-3.1.3
5)配置hadoop安装目录下hadoop-env.sh里的环境变量
6)配置hadoop集群
7)单点启动
8)配置ssh免密登录
9)群起并测试集群
实操二部分:
10)配置多队列
11)测试提交任务
12)设置任务优先级
五、 实训项目实现
实操一部分:
- Java版本:
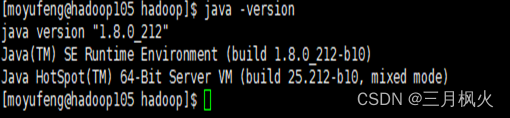
- 配置
/etc/profile.d/目录下my_env.sh的linux系统可识别的环境变量
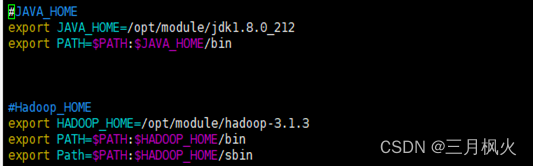
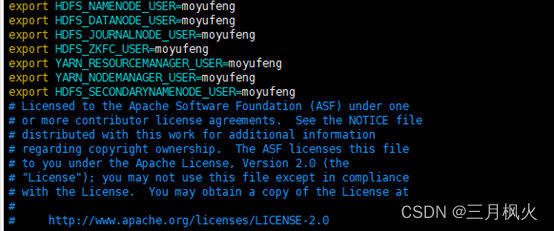
- 配置hadoop安装目录下
hadoop-env.sh里的环境变量(设置namenode等进程启动所需的权限用户)
- 新创建Hadoop集群,三台服务器分别命名hadoop105、hadoop106、hadoop107。
Namenode和JobHistory在hadoop105启动,yarn在hadoop106启动,2NN在hadoop107启动。集群中以自己名字拼音设置用户名。
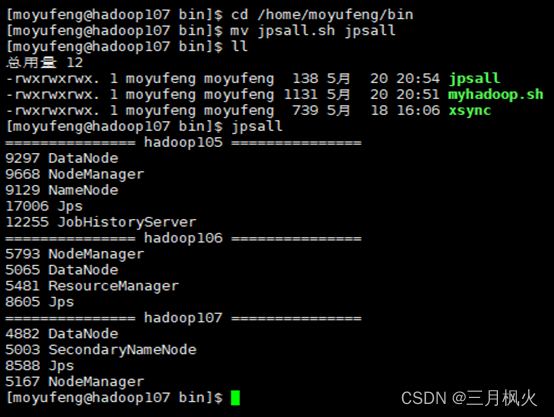
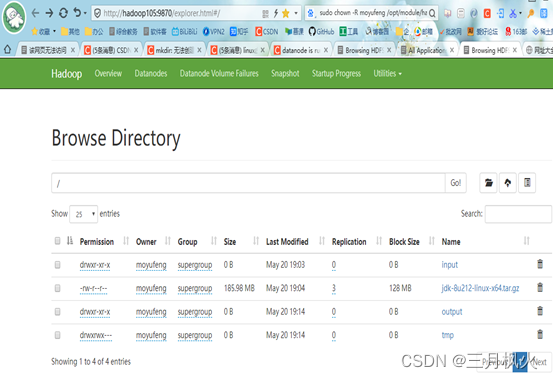
- hadoop105环境依次输入命令
jps、hostname、ifconfig截图:
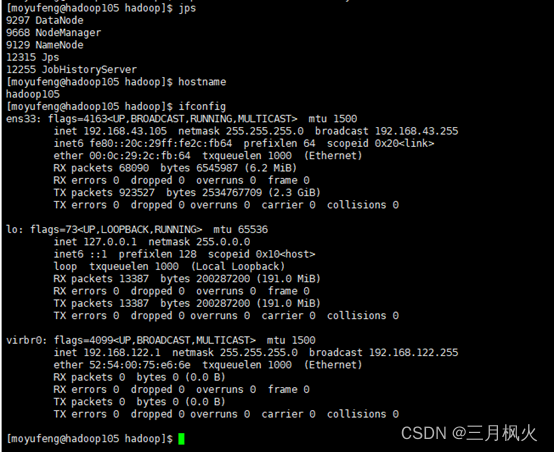
- hadoop106环境依次输入命令
jps、hostname、ifconfig截图:
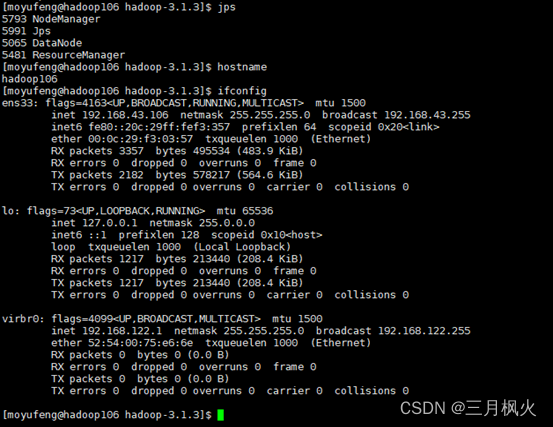
- hadoop107环境依次输入命令
jps、hostname、ifconfig截图:
- MapReduce执行结果截图:
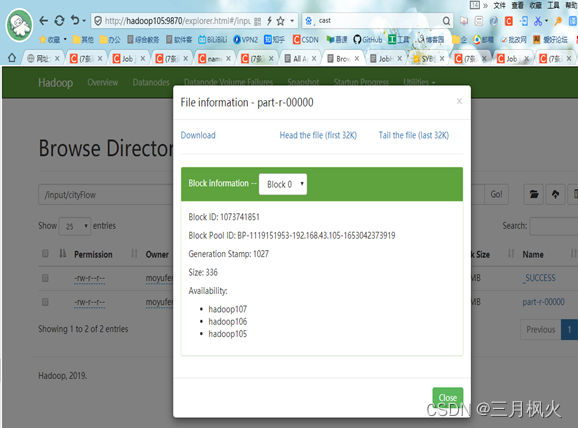
-
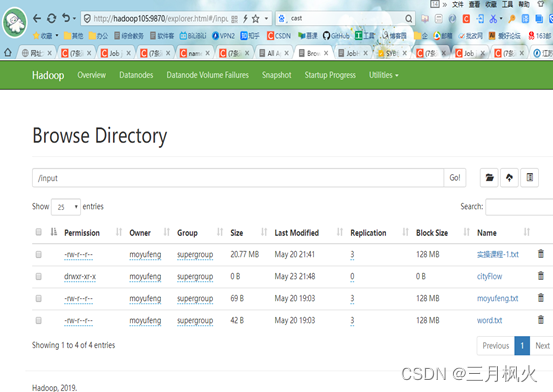
打开http://hadoop105:9870/explorer.html#/进入input文件夹,截图:
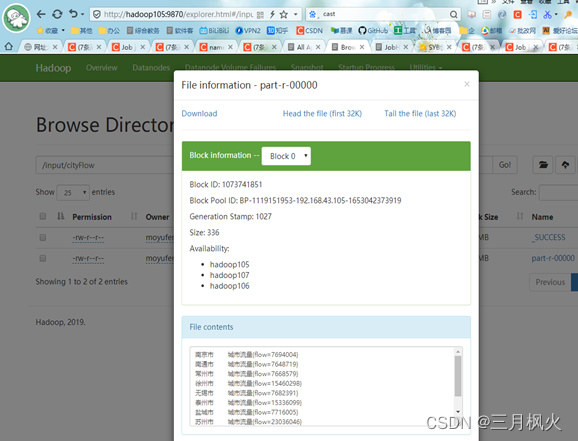
-
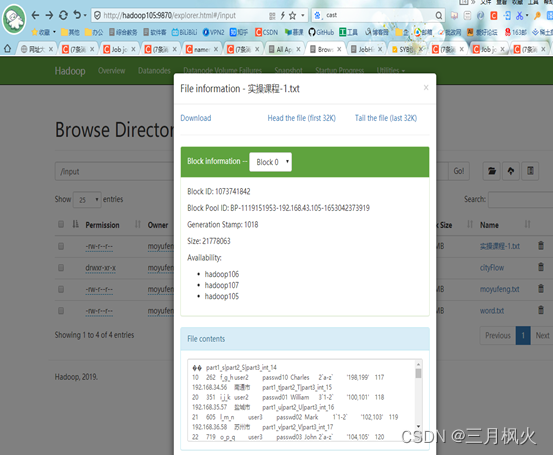
Input文件夹中,打开上传文件信息截图:
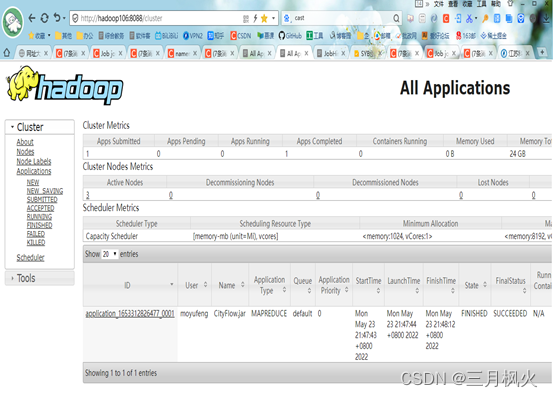
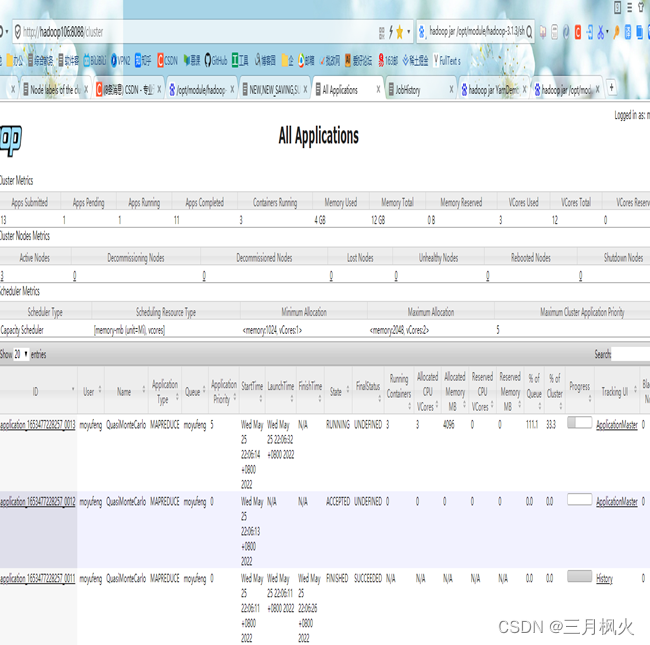
- 打开http://hadoop106:8088/cluster,截图:
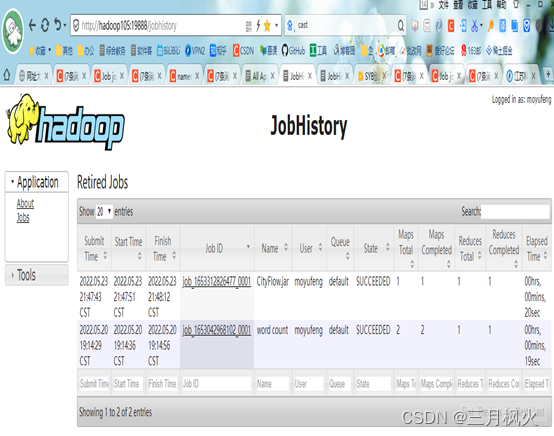
- 打开http://hadoop105:19888/jobhistory,截图:
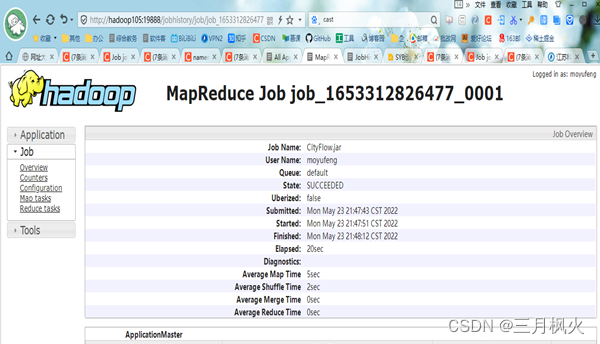
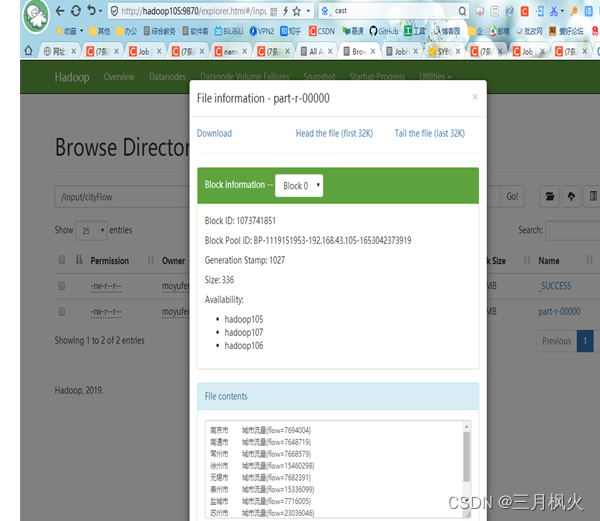
- 网页中打开执行结果文件,截图:
实操二部分:
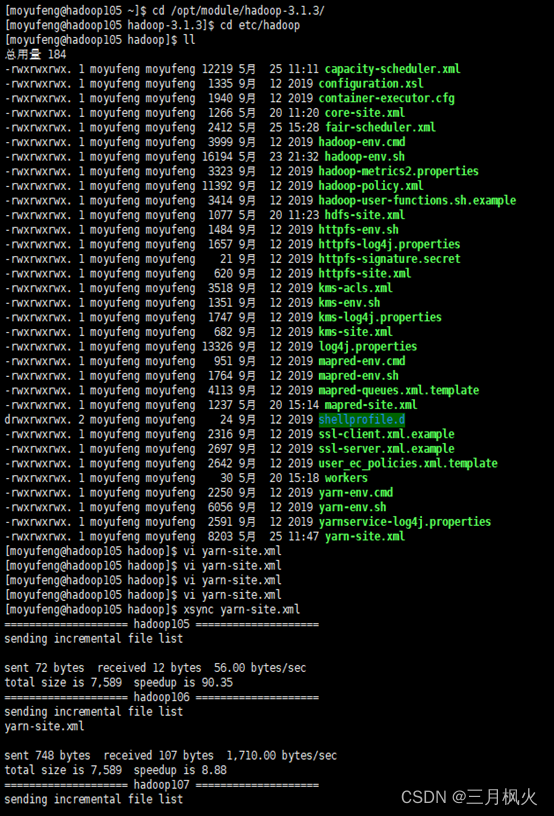
yarn-site.xml配置截图
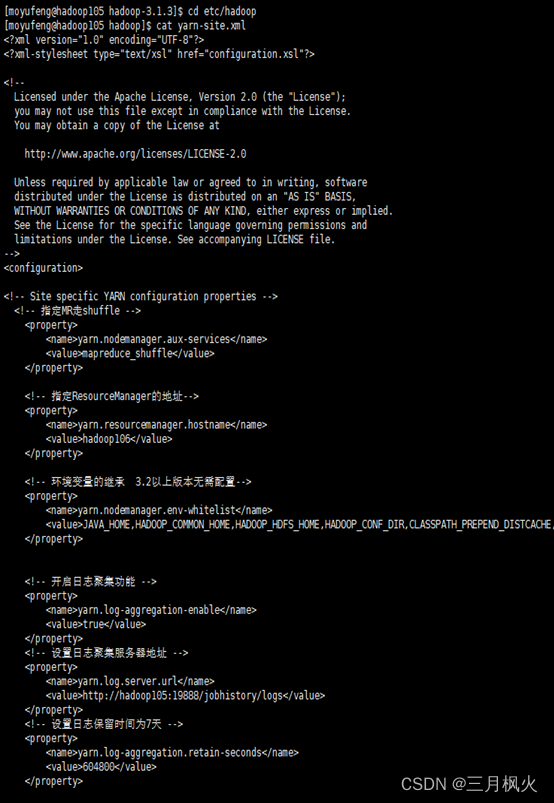
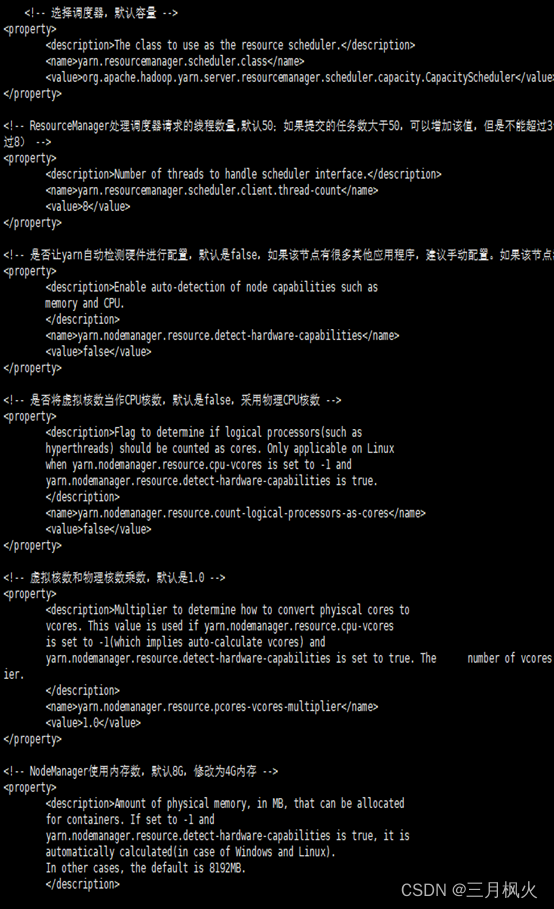
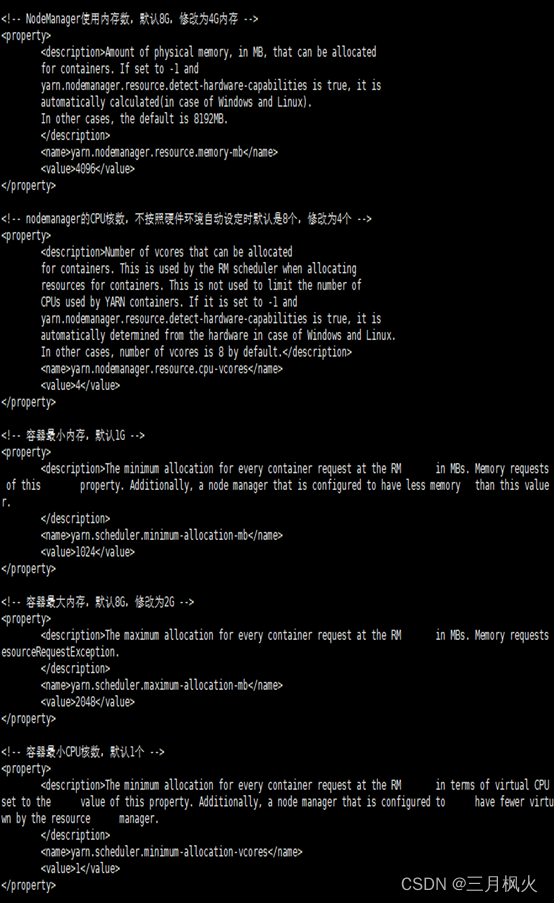

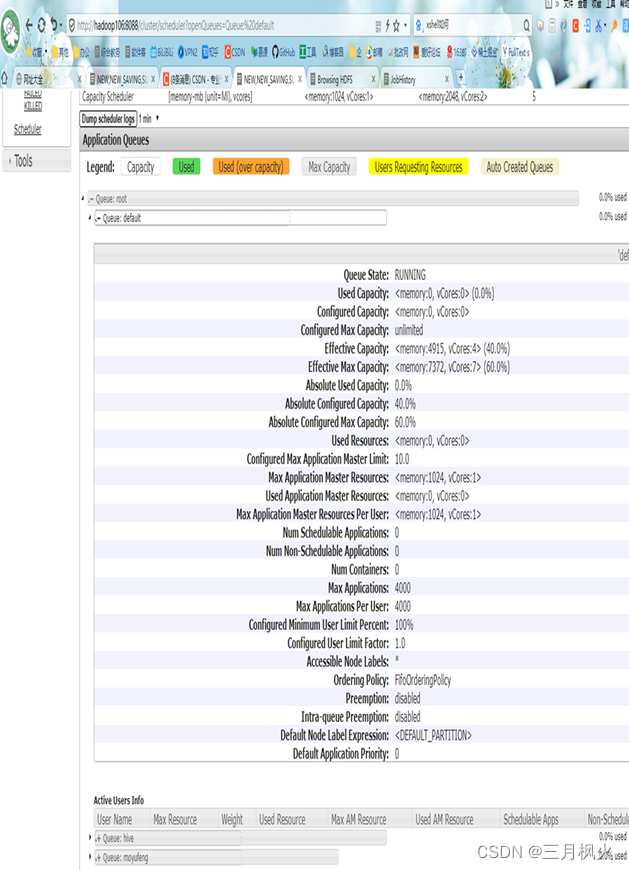
- 队列配置结束后http://hadoop106:8088/cluster/apps中default队列详情图:
3. 队列配置结束后http://hadoop106:8088/cluster/apps中hive队列详情截图:
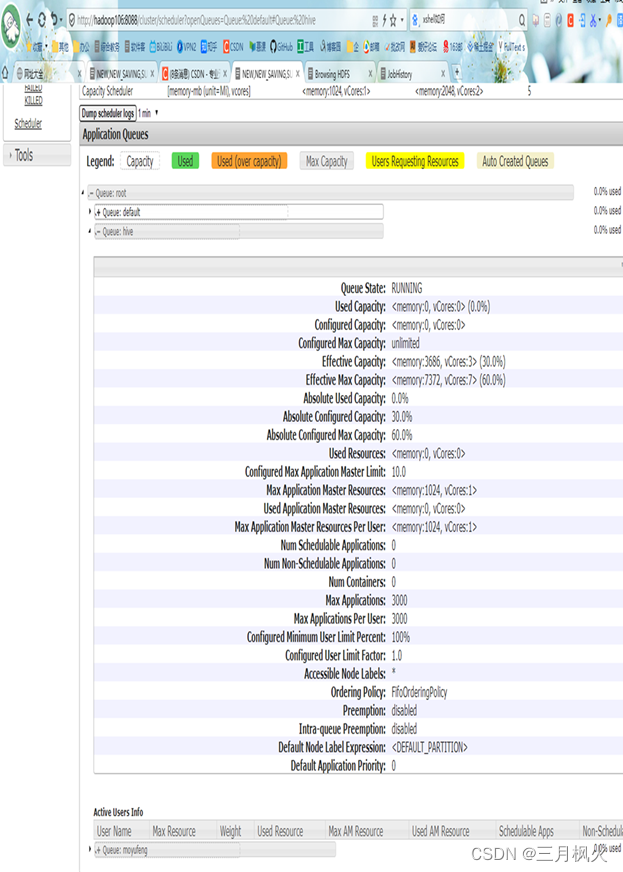
- 队列配置好后http://hadoop106:8088/cluster/apps中【名字拼音】队列详情:
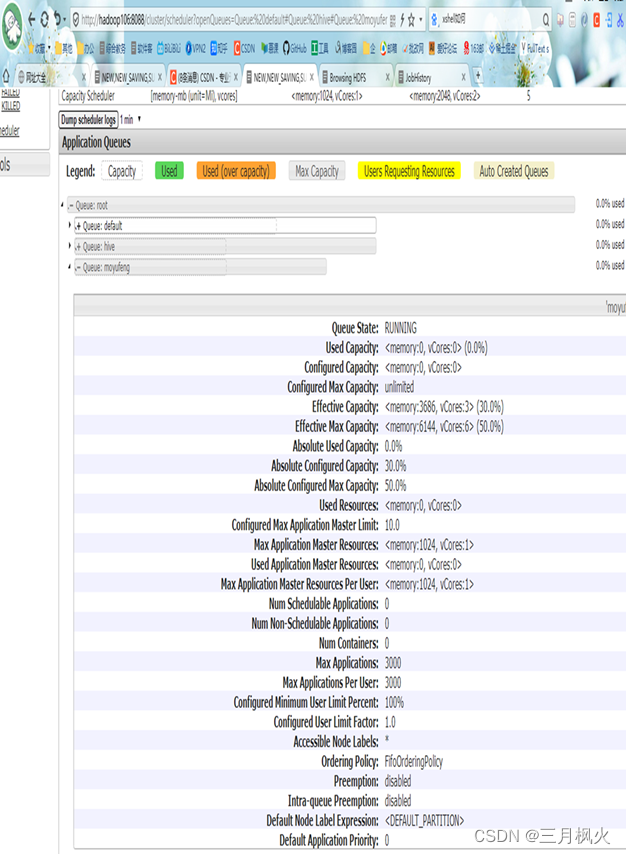
- Hive队列中提交wordcount任务,hive队列详情截图:
输入的相关操作指令如下:
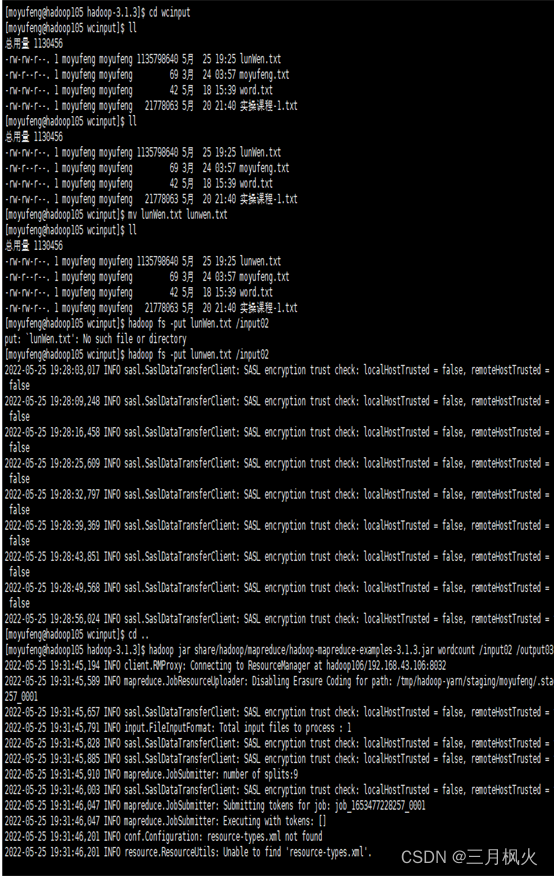
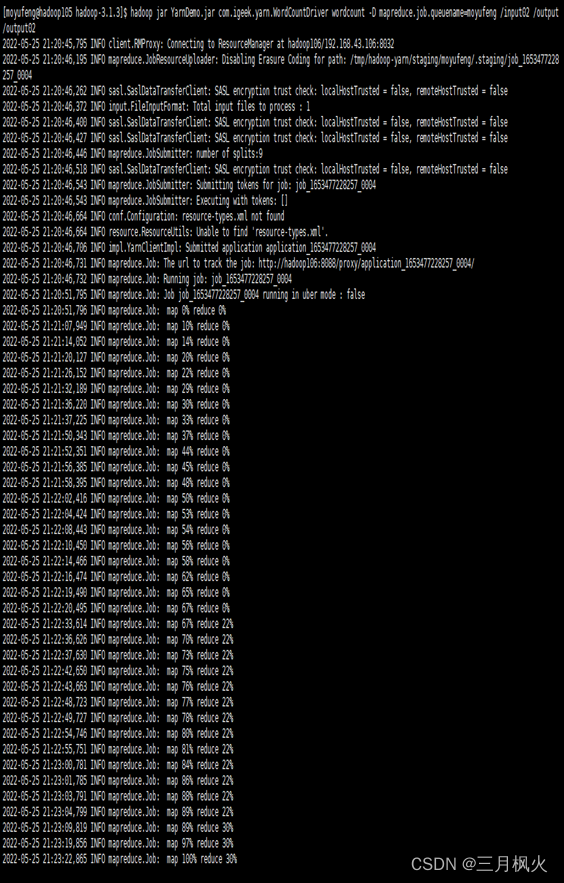
实现的队列执行效果如下:
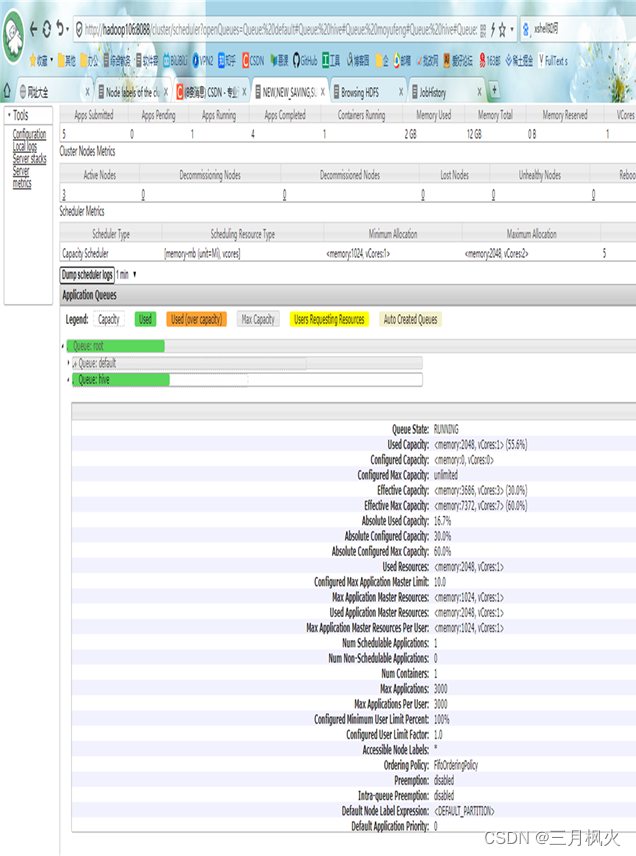
- 【学生名字】队列中提交wordcount任务,队列详情截图:
输入的相关操作指令如下:
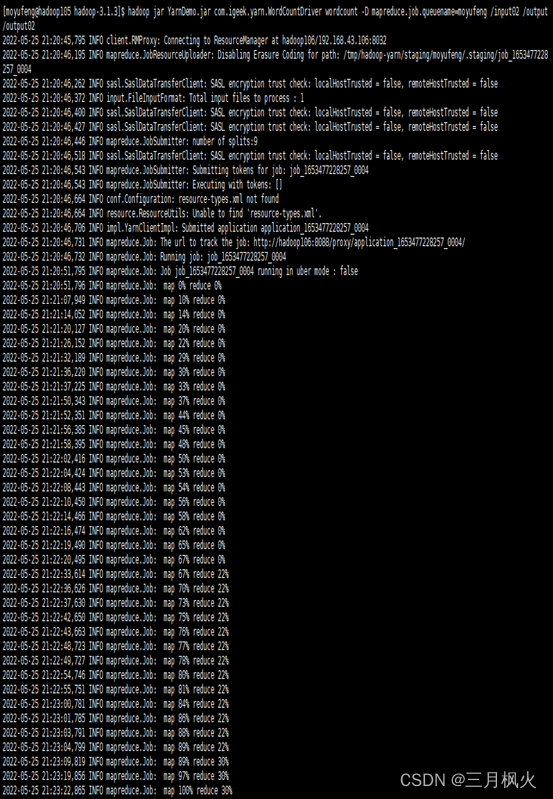
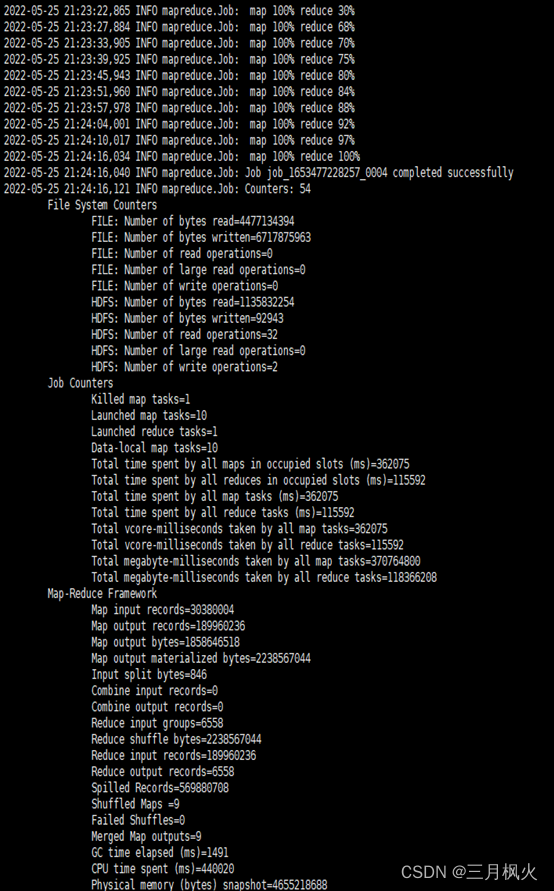
实现的队列执行效果如下:
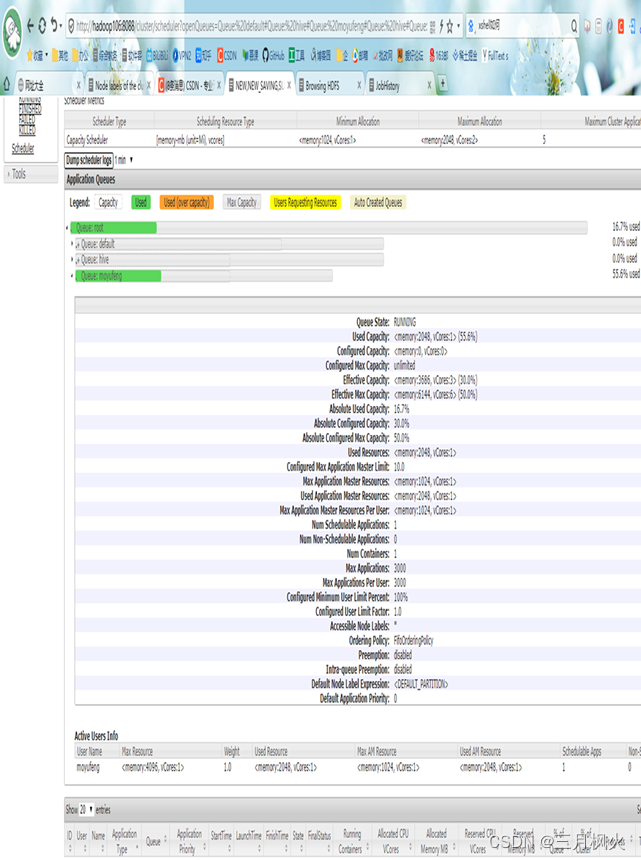
- 优先级测试结果截图,在优先级5运行时截取:
输入的相关操作指令如下:
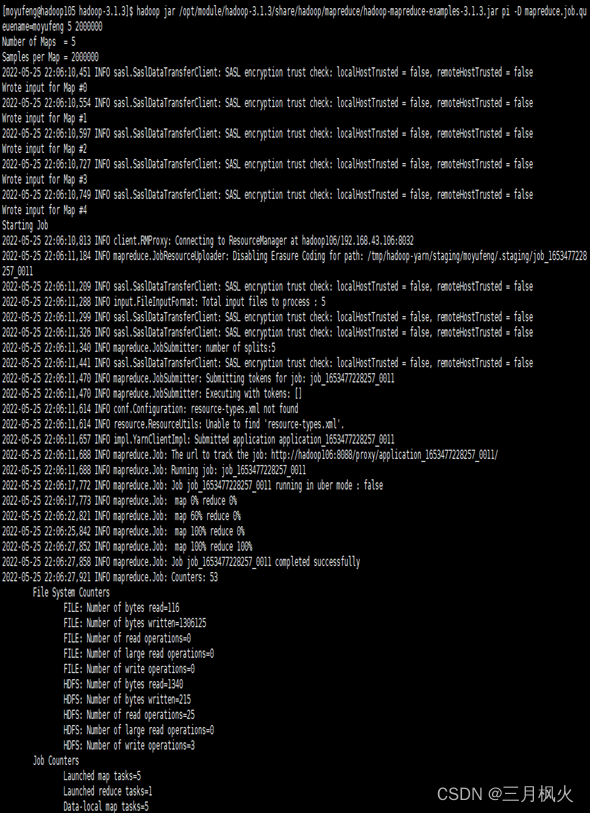
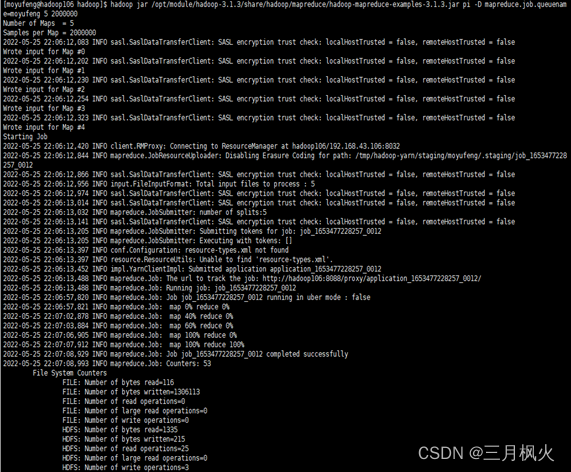
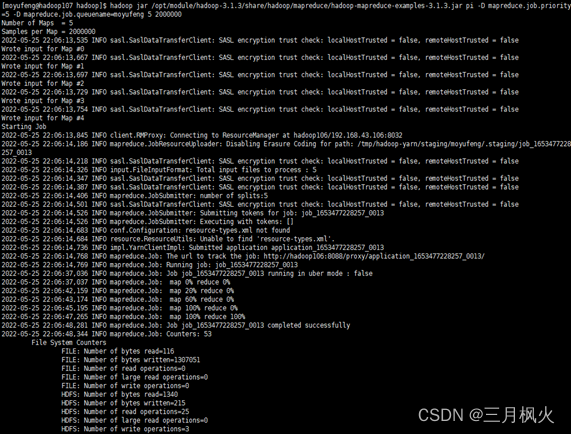
实现的执行效果如下:
六、 实训项目过程中遇到的问题及解决方法
所遇问题:
1)无法打开hadoop105、hadoop106所对应的网页
2)ssh没有配置好
3)粘贴Word中命令时,执行命令不生效
4)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。
5)jps不生效
6)8088端口连接不上
7)再次格式化NameNode导致无法启动datanode进程
8)xshell连接虚拟机后,输入指令时从数字小键盘输入的数字无效
解决办法:
(1)防火墙没关闭、或者没有启动YARN,在/etc/hosts文件中添加192.168.10.105(ip地址) hadoop105之类
(2)配置文件的修改不细心,按文档重新仔细检查
(3)粘贴Word中命令时,执行命令不生效,遇到-和长–没区分开,导致命令失效
(4)在Linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
(5)全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
(6)输入指令:cat /etc/hosts
注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop102
(7)格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。可删除所有机器的data和logs目录,然后再进行格式化,或者进入namenode对应的clusterID所在的文件,复制其clusterID到datanode对应的clusterID即可。
(8)打开xshell,点击“默认属性”,打开对话框,在类别中选择“VT模式”,然后在右侧的选项中,选择:初始数字键盘模式中的“设置为普通”,最后点击“确定”即可。
七、实训体会与心得
-
通过为期两周的大数据实践,我学会了利用三台虚拟机作服务器搭建Hadoop集群环境,创建并使用脚本启动namenode、datanode等进程,感受到了hadoop的四大优势:高可靠性,高扩展性,高效性和高容错性。
-
正确搭建集群环境需有以下进程:
第一台虚拟机上:NameNode、DataNode、NodeManager、JobHistoryServer;
第二台虚拟机上:DataNode、ResourceManager、NodeManager;
在第三台虚拟机上:DataNode 、SecondaryNameNode、NodeManager。
-
使用脚本实现群起集群,需配置SSH无密登录,需将本虚拟机机器上生成的公钥拷贝到要免密登录的目标机器上,其原理是
将id_rsa.pub里的公钥存放到目标机器的authorized_keys(存放授权过的无密登录服务器公钥)上。 -
配置历史服务器和日志的聚集,需重新启动集群生效,从而查看查看程序的历史运行情况,方便开发调试。
-
通过配置hadoop安装目录下的
capacity-scheduler.xml可配置多队列的容量调度器,重启Yarn刷新队列,也可执行yarn rmadmin -refreshQueues刷新,就可以yarn对应的Scheduler页面看到多条队列。 -
默认的任务提交都是提交到default队列的,向其他队列提交任务可使用-Dmapreduce.job.queuename=指定目标队列。 -
在资源紧张时为job任务设置优先级,可使用
-D mapreduce.job.priority=n来设置该任务的优先级,其中n为优先级数,优先级高的job任务会相对优先级低的job任务优先获取资源,从而更快的完成该任务。

