
- 1【第34天】SQL进阶-SQL高级技巧-Window Funtion(SQL 小虚竹)_sql window function
- 2【并发编程四】windows进程通信和Linux进程通信_windows linux消息队列,用于进程间消息同步
- 3C语言常用MySQL API函数_mysql 的 c api
- 4Vue项目开发目录结构和引用调用关系_vue app.vue拆分并引用
- 5大模型推理性能优化之KV Cache解读
- 6PyTorch深度学习实践——Logistic回归_pytorch之优化头歌
- 7如何借助 LLM 设计和实现任务型对话 Agent
- 8idea 项目 修改项目文件名 教程
- 92021浙江高考成绩查询平台,浙江省教育考试院:2021年浙江高考查分入口、查分系统...
- 10Java数组(如果想知道Java中有关数组的知识点,那么只看这一篇就足够了!)
数仓(八)从0到1简单搭建加载数仓DWD层(用户行为日志数据解析)
赞
踩
数仓(三)简析阿里、美团、网易、恒丰银行、马蜂窝5家数仓分层架构
数仓(六)从0到1简单搭建数仓ODS层(埋点日志 + 业务数据)
上一节我们讲解了数仓DIM维度层的搭建和使用,并且讲解了拉链表的概念和使用。这节我们讲解DWD层关于用户行为日志数据的搭建和使用。下一次分享DWD层关于业务数据的搭建和使用。
一、DWD层用户行为日志解析结构
DWD层是对用户的日志行为进行解析,以及对业务数据采用维度模型的方式重新建模(维度退化)。本节我们先来回顾一下用户行为日志的结构。
1、前端埋点日志信息
前端埋点日志信息都是JSON格式形式,主要包括两方面:
(1)启动日志;(2)事件日志;
我们之前已经把前端埋点的日志信息,写到ODS层ods_log表了,传入的参数是一个String类型字符串即一条日志信息一个String类型字符串。
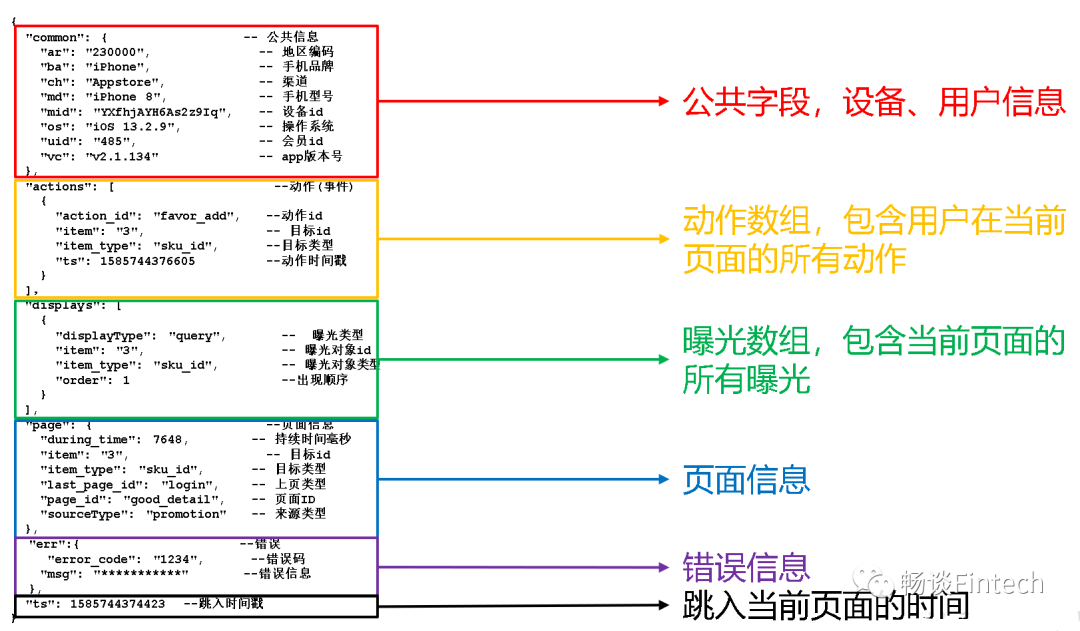
2、日志解析思路
我们根据ODS层日志数据内容来解析到DWD层分为5个表,也可以根据启动日志和事件日志来解析到DWD层分为2个表。前者是根据内容抽象来解析,颗粒度更细,一般大公司使用。后者比较简单就是根据数据的类型来解析。我们这里采用第一种方式,把页面日志和启动日志信息的数据需要装载到DWD层里面的五张表。所以DWD层就是解析这五张表。
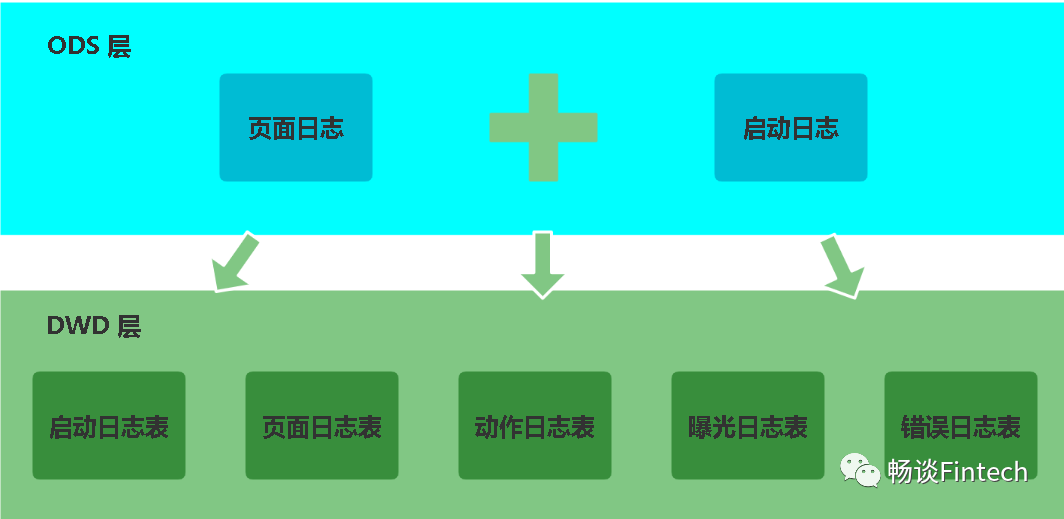
我们下面来依次解析每一张表。
二、DWD层-启动日志表
启动日志表中每一行数据对应一个启动记录,一个启动记录应该包含日志中的公共信息和启动信息。
常规解析思路是:可以先将所有包含start字段的日志过滤出来,然后使用get_json_object函数解析每个字段。
1、启动日志表结构
分区:
dt = 2020-06-14
过滤条件:
利用get_json_object函数,解析start内容不为空说明是启动日志信息;
范围
包括:公共信息common、启动信息start、启动app时间ts;
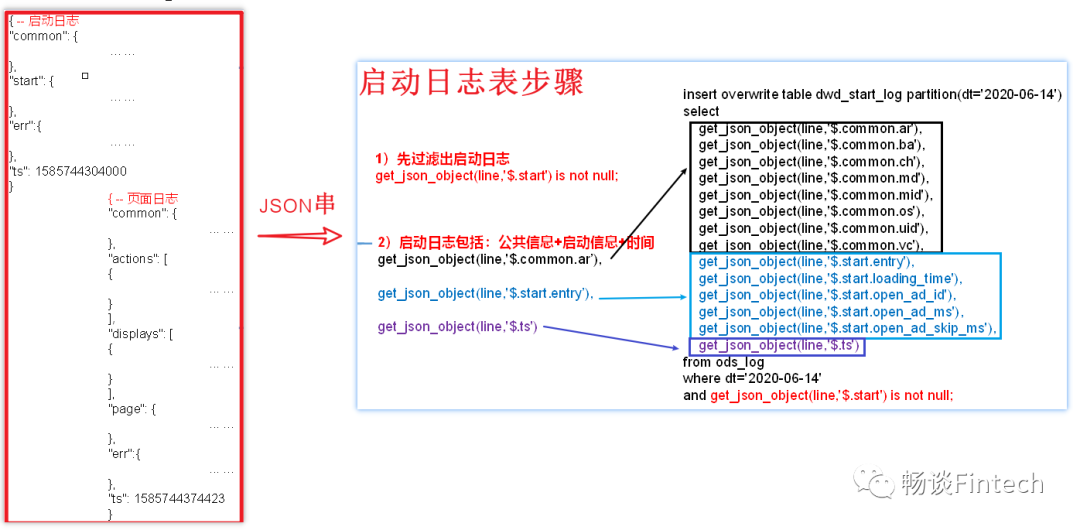
2、创建表结构
- DROP TABLE IF EXISTS dwd_start_log;
- CREATE EXTERNAL TABLE dwd_start_log(
- `area_code` STRING COMMENT '地区编码',
- `brand` STRING COMMENT '手机品牌',
- `channel` STRING COMMENT '渠道',
- `is_new` STRING COMMENT '是否首次启动',
- `model` STRING COMMENT '手机型号',
- `mid_id` STRING COMMENT '设备id',
- `os` STRING COMMENT '操作系统',
- `user_id` STRING COMMENT '会员id',
- `version_code` STRING COMMENT 'app版本号',
- `entry` STRING COMMENT 'icon手机图标 notice 通知 install 安装后启动',
- `loading_time` BIGINT COMMENT '启动加载时间',
- `open_ad_id` STRING COMMENT '广告页ID ',
- `open_ad_ms` BIGINT COMMENT '广告总共播放时间',
- `open_ad_skip_ms` BIGINT COMMENT '用户跳过广告时点',
- `ts` BIGINT COMMENT '时间'
- ) COMMENT '启动日志表'
- PARTITIONED BY (`dt` STRING) -- 按照时间创建分区
- STORED AS PARQUET -- 采用parquet列式存储
- LOCATION '/warehouse/gmall/dwd/dwd_start_log' -- 指定在HDFS上存储位置
- TBLPROPERTIES('parquet.compression'='lzo') -- 采用LZO压缩;

3、装载数据
首日和每日加载数据分区都是一样的策略,每天DWD层从ODS层获取数据后加载。
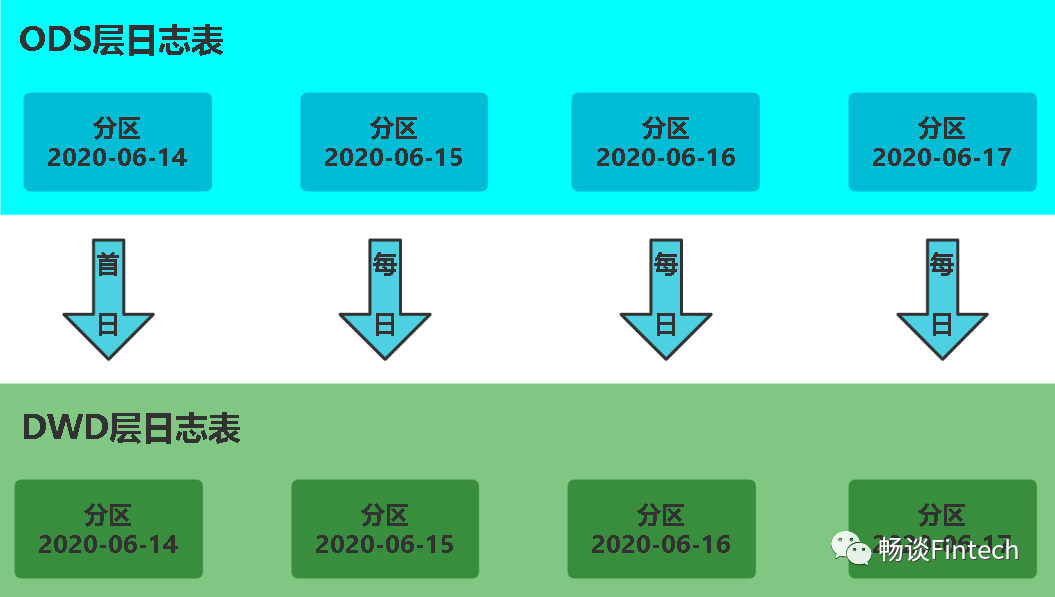
SQL实现
- insert overwrite table dwd_start_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.is_new'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.start.entry'),
- get_json_object(line,'$.start.loading_time'),
- get_json_object(line,'$.start.open_ad_id'),
- get_json_object(line,'$.start.open_ad_ms'),
- get_json_object(line,'$.start.open_ad_skip_ms'),
- get_json_object(line,'$.ts')
- from ods_log
- where dt='2020-06-14'
- and get_json_object(line,'$.start') is not null;
注意:这里hive需要使用HiveInputFormat,而不是CombineHiveInputFormat
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;后者不能识别lzo.index的索引文件,会把索引文件当做普通文件来处理,并且导致lzo文件无法切片。而ODS层数据我们处理的时候是带lzo索引文件的。
三、DWD层-页面日志表
页面日志表和启动日志表的处理逻辑一样。页面日志表中每一行数据对应一个页面的访问记录,一个页面访问记录应该包含日志中的公共信息和页面信息。
常规解析思路是:也是先将所有包含page字段的日志过滤出来,然后使用get_json_object函数解析每个字段。
1、页面日志表结构
分区:
dt = 2020-06-14
过滤条件:
利用get_json_object函数,解析page内容不为空说明是页面日志信息;
范围
包括:公共信息common、页面信息page、启动app时间ts;

3、创建表结构
- drop table if exists dwd_page_log;
- CREATE EXTERNAL TABLE dwd_page_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `during_time` bigint COMMENT '持续时间毫秒',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面ID ',
- `source_type` string COMMENT '来源类型',
- `ts` bigint
- ) COMMENT '页面日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_page_log'
- TBLPROPERTIES('parquet.compression'='lzo');
4、装载数据
和启动日志表一样,首日和每日加载数据分区都是一样的策略,每天DWD层从ODS层获取数据后加载。
- insert overwrite table dwd_page_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.ts')
- from ods_log
- where dt='2020-06-14'
- and get_json_object(line,'$.page') is not null;
四、DWD层-动作日志表
动作日志表,比前面启动日志和页面信息表要复杂的多。动作日志表中每行数据对应的是用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。
常规解析思路是:先将包含action字段的日志过滤出来,然后通过UDF、UDTF函数(用户定义表生成函数user-defined table-generating function)将action数组“炸裂”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。
1、页面日志表结构

根据图示我们可以看到:
(1)需要自定义创建UDTF函数
来完成对actions动作数组的“炸裂”,实现“一行输入,多行输出”的需求。即输入JSON数组字符串actions,输出每一个JSON数组元素action。
(2)然后通过get_json_object(action,$action元素字段)获取信息;
分区:
dt = 2020-06-14
过滤条件:
利用get_json_object函数,解析actions内容不为空;
范围
包括:公共信息common、页面信息page、动作信息、启动app时间ts;
2、创建表结构
- drop table if exists dwd_action_log;
- CREATE EXTERNAL TABLE dwd_action_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `during_time` bigint COMMENT '持续时间毫秒',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面id ',
- `source_type` string COMMENT '来源类型',
- `action_id` string COMMENT '动作id',
- `item` string COMMENT '目标id ',
- `item_type` string COMMENT '目标类型',
- `ts` bigint COMMENT '时间'
- ) COMMENT '动作日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_action_log'
- TBLPROPERTIES('parquet.compression'='lzo');
3、创建UDTF函数
我们通过java代码来实现功能,并且通过MAVEN来打成jar。然后上传到HDFS集群,给hive做关联调用。当然也可以使用hive自带的UDTF函数含来完成解析。但是后者必须是在hive的客户端完成,必须带hive库名,不够灵活。
3.1、编写java代码实现UDTF功能
1、pom.xml文件中hive版本依赖
我这里hive的版本是3.1.2
- <dependencies>
- <!--添加hive依赖-->
- <dependency>
- <groupId>org.apache.hive</groupId>
- <artifactId>hive-exec</artifactId>
- <version>3.1.2</version>
- </dependency>
- </dependencies>
2、项目工程结构
这个比较简单。
3、ExplodeJSONArray类编写
思路是:
(1)ExplodeJSONArray继承hive的GenericUDTF类;
(2)实现initialize、process、close三个方法;
initialize方法:主要对解析的变量名、变量类型做校验
process方法:完成对“JSON数组炸裂成单一元素”的功能。这里是一行in,多行out,并且forward到元素里面
- package com.qiusheng.hive.udtf;
-
-
- import org.apache.hadoop.hive.ql.exec.MapredContext;
- import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
- import org.apache.hadoop.hive.ql.metadata.HiveException;
- import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
- import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
- import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
- import org.json.JSONArray;
-
-
- import java.util.ArrayList;
- import java.util.List;
-
-
- /**
- * @author qiusheng
- * @date 2021年11月04日
- *
- */
- public class ExplodeJSONArray extends GenericUDTF
- {
-
-
- /**
- * 1、第一步需要自定义的类继承GenericUDTF类
- * 并且重写initialize方法;
- * 返回StructObjectInspector对象
- *
- * @qiusheng
- * @param argOIs
- * @return
- * @throws UDFArgumentException
- */
- @Override
- public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException
- {
- //1、判断参数的合法性argOI实际就是actions
- //(1)判断参数的个数(需要传递一个参数)
-
-
- //如果传递的参数个数不是1个,则抛异常;
- if(argOIs.getAllStructFieldRefs().size() != 1)
- {
- throw new UDFArgumentException("参数个数错误!只需要1个参数......");
-
-
- }
- //(2)判断传递的参数类型,必须是String类型
- //如果不是string类型,则抛异常;
- if(!"String".equals(argOIs.getAllStructFieldRefs().get(0).getFieldObjectInspector().getTypeName()))
- {
- throw new UDFArgumentException("参数类型不对!应该是String类型......");
- }
-
-
-
-
- //2、返回StructObjectInspector对象
- //第一个参数:变量名,类型是List<String>数组;
- //第二个参数:检验变量,类型是List<ObjectInspector>;
-
-
- //定义返回值名称
- List<String> fieldNames = new ArrayList<String>();
-
-
- //定义返回值类型
- List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
-
-
- //把items添加到返回值名称
- fieldNames.add("items");
-
-
- //调用检验方法对items
- fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
-
-
- //3、返回类型
- return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);
- }
-
-
- /**
- * 2、第二步重写process方法
- *
- * function:炸裂功能
- * @author qiusheng
- * @param objects
- * @throws HiveException
- */
- @Override
- public void process(Object[] objects) throws HiveException
- {
- //1、获取传入的数据就是actions
- String jsonArray = objects.toString();
-
-
- //2、把传入的数据(string)类型转化为JSON数组JSONArray类型
- JSONArray actions = new JSONArray(jsonArray);
-
-
- //3、循环取出JSONArray对象中的JSON,并且写出来
- for (int i = 0;i < actions.length();i++)
- {
- //定义一个字符串数组,长度就是1
- String[] result = new String[1];
- //getString(i)把元素取出来,添加到这个数组中
- result[0] = actions.getString(i);
- //写到String数组里面
- forward(result);
- }
- }
-
-
- /**
- * @author qiusheng
- * @throws HiveException
- */
- @Override
- public void close() throws HiveException
- {
-
-
- }
- }
3.2、通过maven打成jar包
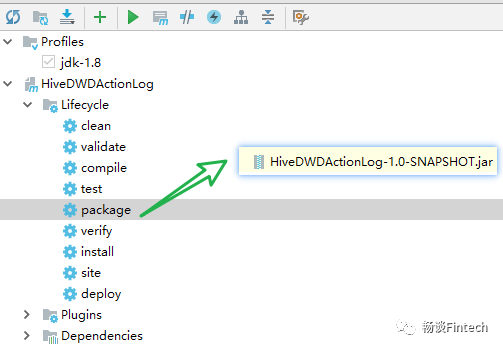
3.3、上传jar包到hadoop集群路径下
(1)先上传jar包到CentOS集群的node1节点

(2)上传到HDFS集群系统
先创建目录functions/hive/jars
[qiusheng@node01 module]$ hadoop fs -mkdir -p /functions/hive/jars检查查看目录是否已经创建;
上传jar包到这个目录/functions/hive/jars
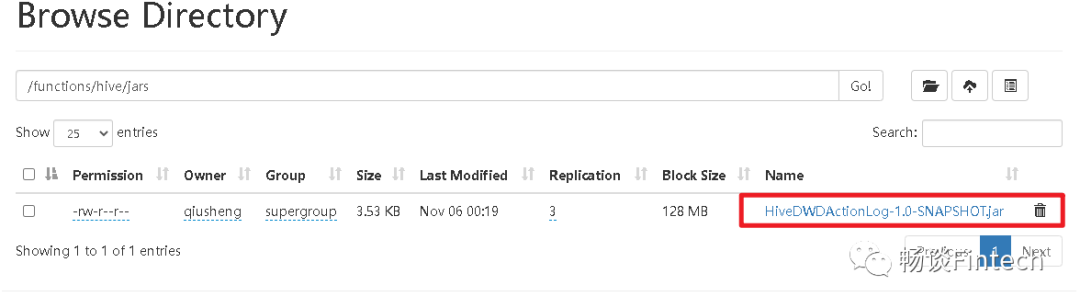
3.4、创建UDTF和jar包关联
在hive客户端,创建function关联jar包
- hive (gmall)>
- create function explode_json_array as 'com.qiusheng.hive.udtf.ExplodeJSONArray' using jar 'hdfs://mode01:8020/functions/hive/jars/HiveDWDActionLog-1.0-SNAPSHOT.jar';
4、装载数据
所需要的字段都拼接齐全了,我们来写装载语句。
- insert overwrite table dwd_action_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.during_time'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(action,'$.action_id'),
- get_json_object(action,'$.item'),
- get_json_object(action,'$.item_type'),
- get_json_object(action,'$.ts')
- from ods_log lateral view explode_json_array(get_json_object(line,'$.actions')) tmp as action
- where dt='2020-06-14'
- and get_json_object(line,'$.actions') is not null;
这里lateral view意思是:为原始表的每行调用UDTF,UTDF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表action。
from ods_log lateral view explode_json_array(get_json_object(line,'$.actions')) tmp as action这样我们动作日志表就完成了。
五、DWD层-曝光日志表
曝光日志表和动作日志表,解析一样。曝光日志表中每行数据对应一个曝光记录,一个曝光记录应当包含公共信息、页面信息以及曝光信息。
常规思路:先将包含display字段的日志过滤出来,然后通过UDTF函数,将display数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。
1、页面日志表结构
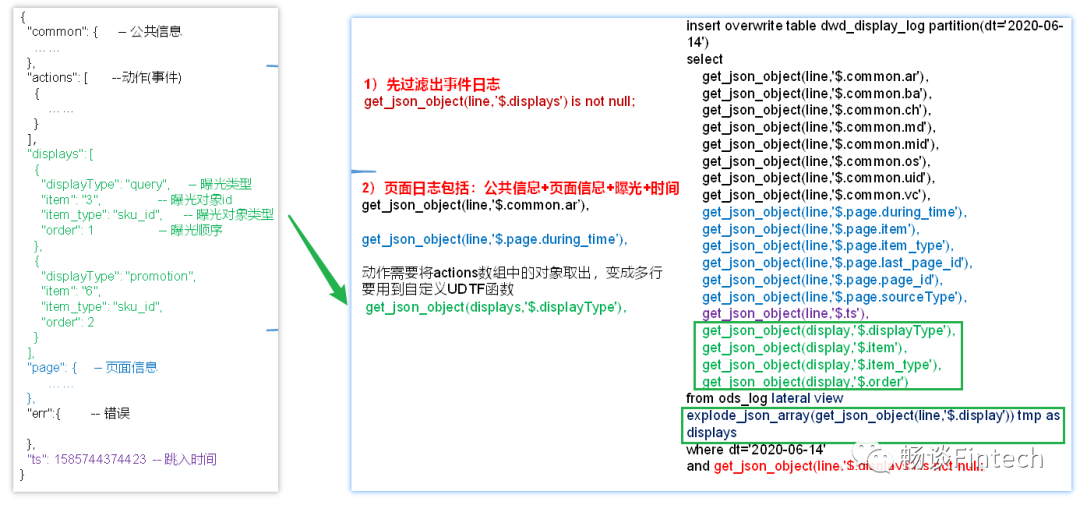
后面建表、做UDTF、一系列操作、装载数据和动作日志表一样。留给读者自行实践一下。
六、DWD层-错误日志表
动作日志表,比前面启动日志和页面信息表要复杂一些。错误日志表中每行数据对应一个错误记录,为方便定位错误,一个错误记录应当包含与之对应的公共信息、页面信息、曝光信息、动作信息、启动信息以及错误信息。先将包含err字段的日志过滤出来,然后使用get_json_object函数解析所有字段。
1、页面日志表结构
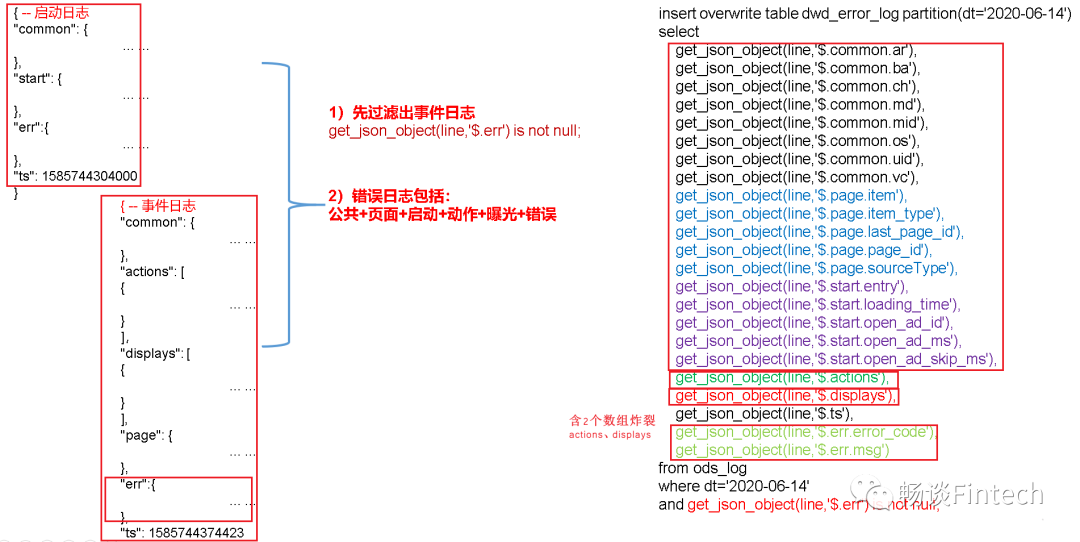
含有2个actions 、displays数组的UDTF炸裂。
2、创建表结构
- drop table if exists dwd_error_log;
- CREATE EXTERNAL TABLE dwd_error_log(
- `area_code` string COMMENT '地区编码',
- `brand` string COMMENT '手机品牌',
- `channel` string COMMENT '渠道',
- `model` string COMMENT '手机型号',
- `mid_id` string COMMENT '设备id',
- `os` string COMMENT '操作系统',
- `user_id` string COMMENT '会员id',
- `version_code` string COMMENT 'app版本号',
- `page_item` string COMMENT '目标id ',
- `page_item_type` string COMMENT '目标类型',
- `last_page_id` string COMMENT '上页类型',
- `page_id` string COMMENT '页面ID ',
- `source_type` string COMMENT '来源类型',
- `entry` string COMMENT ' icon手机图标 notice 通知 install 安装后启动',
- `loading_time` string COMMENT '启动加载时间',
- `open_ad_id` string COMMENT '广告页ID ',
- `open_ad_ms` string COMMENT '广告总共播放时间',
- `open_ad_skip_ms` string COMMENT '用户跳过广告时点',
- `actions` string COMMENT '动作',
- `displays` string COMMENT '曝光',
- `ts` string COMMENT '时间',
- `error_code` string COMMENT '错误码',
- `msg` string COMMENT '错误信息'
- ) COMMENT '错误日志表'
- PARTITIONED BY (dt string)
- stored as parquet
- LOCATION '/warehouse/gmall/dwd/dwd_error_log'
- TBLPROPERTIES('parquet.compression'='lzo');
注意:
对动作数组和曝光数组做处理,如需分析错误与单个动作或曝光的关联,可先使用explode_json_array函数将数组“炸开”,再使用get_json_object函数获取具体字
3、装载表数据
- insert overwrite table dwd_error_log partition(dt='2020-06-14')
- select
- get_json_object(line,'$.common.ar'),
- get_json_object(line,'$.common.ba'),
- get_json_object(line,'$.common.ch'),
- get_json_object(line,'$.common.md'),
- get_json_object(line,'$.common.mid'),
- get_json_object(line,'$.common.os'),
- get_json_object(line,'$.common.uid'),
- get_json_object(line,'$.common.vc'),
- get_json_object(line,'$.page.item'),
- get_json_object(line,'$.page.item_type'),
- get_json_object(line,'$.page.last_page_id'),
- get_json_object(line,'$.page.page_id'),
- get_json_object(line,'$.page.sourceType'),
- get_json_object(line,'$.start.entry'),
- get_json_object(line,'$.start.loading_time'),
- get_json_object(line,'$.start.open_ad_id'),
- get_json_object(line,'$.start.open_ad_ms'),
- get_json_object(line,'$.start.open_ad_skip_ms'),
- get_json_object(line,'$.actions'),
- get_json_object(line,'$.displays'),
- get_json_object(line,'$.ts'),
- get_json_object(line,'$.err.error_code'),
- get_json_object(line,'$.err.msg')
- from ods_log
- where dt='2020-06-14'
- and get_json_object(line,'$.err') is not null;
这样我们就完成了最后一张表从ODS层到DWD层的解析。


