
- 1Python项目打包与部署(三):打包与部署的实际操作流程_python -m build
- 2datastage 11.7.4 win10安装客户端报错Caused by: java.security.ProviderException: Failed to initialize IBMJCE_windows安装datastage
- 3强大好用的低代码开发工具,yyds!
- 4Verilog 奇数分频实现_利用计数器实现奇分频器
- 5当前读和快照读的区别
- 6自然语言处理的未来发展趋势
- 7redis(window下)设置密码_windows redis设置密码
- 8Shiro反序列化550漏洞复现
- 9漫谈:C语言 C++ 所有编程语言 =和==的麻烦_c语言==符号底层
- 10基于微信小程序的英语记单词微信小程序
自然语言处理 学习笔记(一)
赞
踩
个人学习nlp笔记:学习材料CS124、COSC572和《Speech and Language Processing》第三版

自然语言处理 学习笔记(一)
1.正则表达式和文本标准化
Regular Expressions, Text Normalization & Edit Distanc
1.1正则表达式
在线正则测试: 连接
一段英文文本: 连接
相关文字推荐推荐: 连接
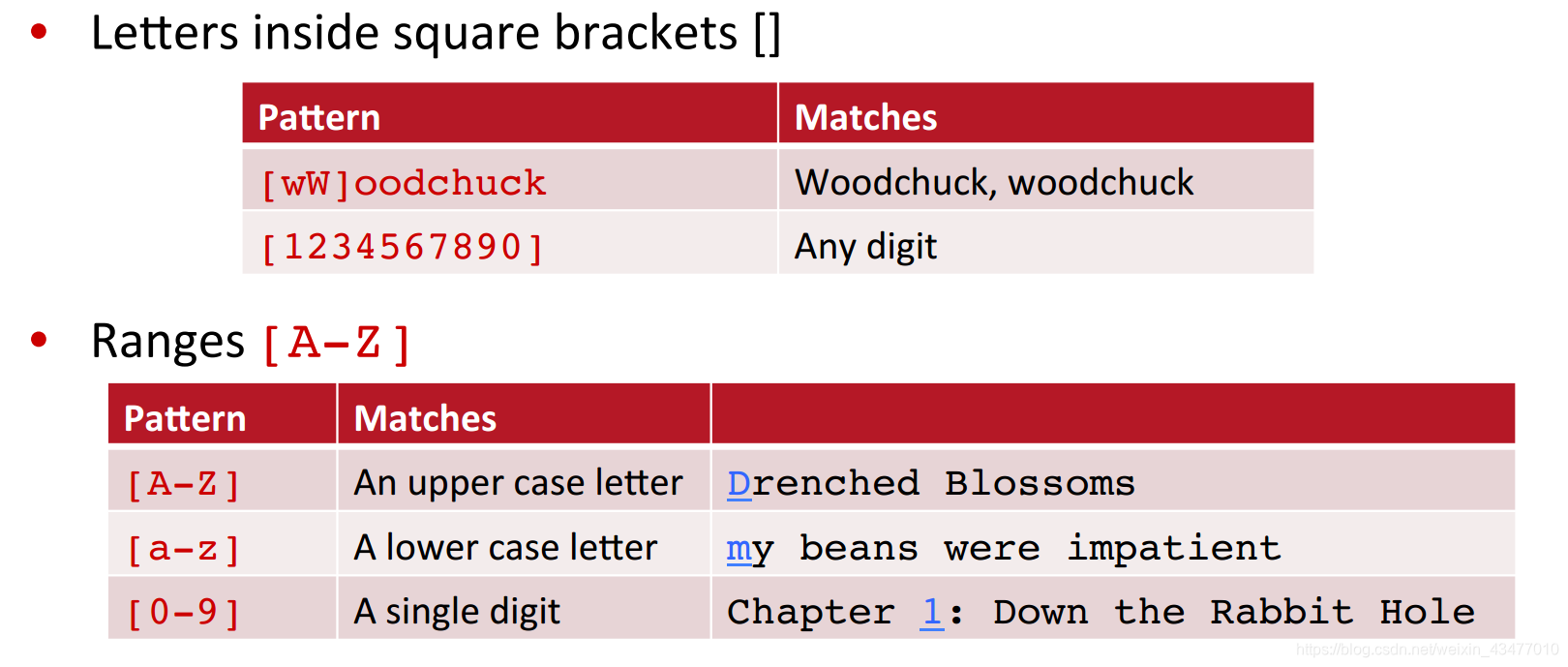
[]表示字符集合,仅代表一个字符,在regexpal上使用[Oon]和[Oo]n就明白了

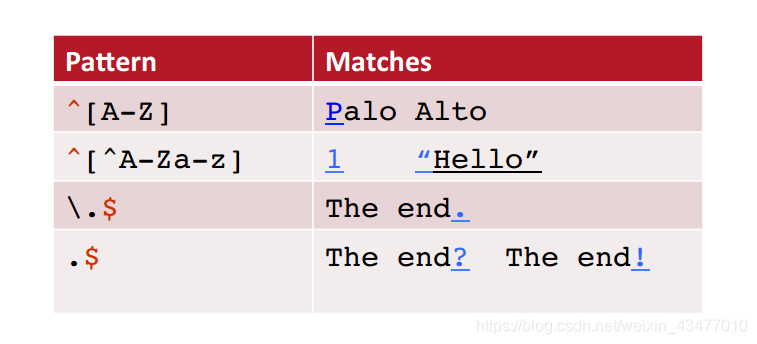
^表示否定,[^Oo ]匹配满足条件“开头不为O、o或空格,第二字符为n”的字符**,**[^e^]匹配满足条件既不是e也不是^的字符,[^a-x .,-\]’”“],匹配y和z,用\来表示转义字符,[^A-Za-z][Tt]he[^A-Za-z]表示定位the同时剔除other, there…

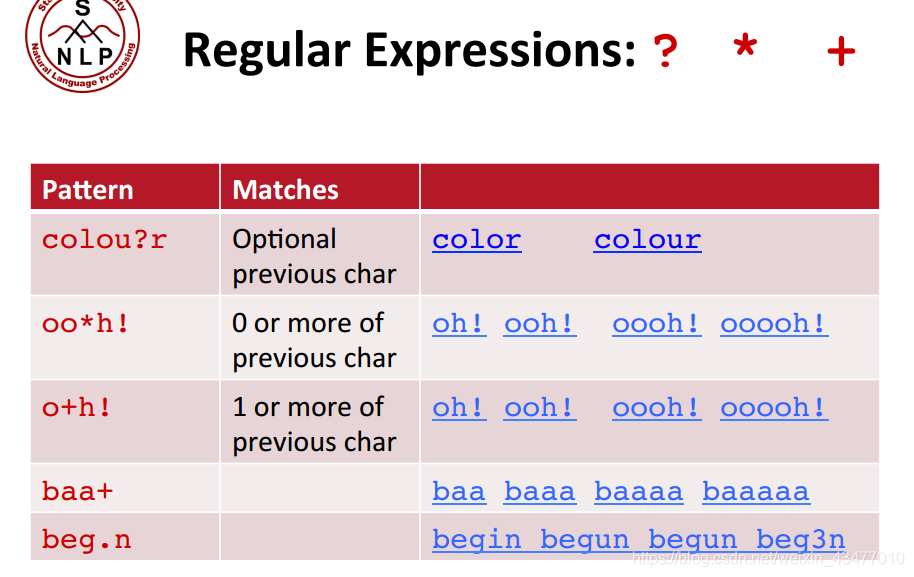
^和$用于表示开头和结尾
| Error type | 匹配"the" | 错误原因 | 解决办法 |
|---|---|---|---|
| False positive | the | 没有匹配大写的The | 提高准确率(accuracy & precision) |
| False negative | [tT]he | 把其他词也给一起匹配了(there) | 提高召回率(recall) |
正确方法: [^a-zA-Z][tT]he[^a-zA-Z]!
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。
召回率和准确率的理解
1.2文本标准化(text normalization)
文本标准化本质就是把所有文本转化为一个更方便处理和标准化的形式,比如把U.S.A和USA匹配。
每一个NLP的工作都需要做文本标准化:
- 对文本进行分词(Segmenting\tokenizing words)
- Normalizing word formats
- Segmenting sentences in running text
1.2.1词语切分(word tokenization)
tokenization指词语的词语切分,比如在中文中没有空格符一句话应该这样切分,已得到词语数据:
我/今天/很/开心
在英文或其他语言中也存在着这样的问题,比如单词San Francisco应当理解成一个词而不是因为空格而被切分,不过一般都用Segmentation来表示中文的分词。

一些英文分词会遇到的问题,大都和符号以及缩写有关

在cs124中介绍了一种非常简单的中文分词方法,大致就是一次找到词典中最长的词,但是对英文显然效果不好。
1.2.2大写转换(Case folding)
字母在句子开头为大写,如The和the,因此需要进行标准化处理, 比如把所有字符都转为小写,统一大小写(当然有的词大小写的化意思不一样如china和China)。
1.2.3词型还原(lemmatization)
把形式发生变化的单词转换为最原始的形态,比如are,is都为be,这样对查找表达中心意思词的情况下会很有帮助。(在一些机器翻译的场景下)
I [wanted] to learn -> I want to learn
want 就能轻松被定位和翻译为想要…
Stemming看一看做简化版的lemmatization,只对单

