
- 1黑马程序员——Java基础---String类和StringBuffer
- 2[图解]SysML和EA建模住宅安全系统-01_sysml和ea区别
- 3力扣 1888. 使二进制字符串字符交替的最少反转次数(前缀和+滑动窗口)_现有一个二进制串,你可以进行任意次操作,每次操作选择相邻的三个位置,将其翻转。
- 4最详细的 K8S 学习笔记总结
- 5八、SpringCloud-RabbitMQ + Spring AMQP 消息队列_rabbitmq 版本控制
- 6Linux repo包安装Nginx
- 7手把手教如何用Linux下IIO设备(附代码)
- 8哈希表&位图&topk&一致性哈希算法_布隆过滤器 topk
- 92005-2020年A股数据挖掘:谁是最大的牛股?【附Python分析源码】
- 10OpenCV 图像处理一(阈值处理、形态学操作【连通性,腐蚀和膨胀,开闭运算,礼帽和黑帽,内核】)_我在vscode学opencv 图像处理一
❀项目复现❀基于上下文的情绪识别论文项目实现_eeg情绪识别论文复现
赞
踩
2017年Emotion Recognition in context 情景中的情绪的感知论文中提出emotic数据集。
2019年Context Based Emotion Recognition Using EMOTIC Dataset是2017年的扩展,详情可参考这篇论文翻译
❀论文篇❀Context Based Emotion Recognition Using EMOTIC Dataset论文翻译_夏天|여름이다的博客-CSDN博客
项目下载地址:https://github.com/Tandon-A/emotic
老规矩用pycharm打开解压后的项目,

Github有很多类似的,这个更加适合win10,pycharm运行。
(环境设置,我的是在anaconda prompt打开虚拟环境,pip install (项目路径+)requirement.txt)
Step1:下载emotic数据集,和标签,预训练模型
新建一个文件夹dataset和一个文件夹models.
其中Annotations(mat文件)下载后解压到项目dataset文件夹下,emotic(jpg文件)下载后也解压到项目dataset文件夹下。models(预训练模型)下载后解压到model文件夹下。结构如图:

Step2:将数据集转为训练所需格式
将.m文件转为所需要的npy文件(numpy格式)和csv文件。(用cpu运行了很久,如果卡着不动了先别弄,至少等一个小时就好,最好是有GPU)

运行后dataset文件夹下多了一个emotic_pre的文件夹。

Step3:运行main.py
建议使用pycharm terminal:
如果直接运行的话需要改项目参数
- #可根据自己的电脑配置修改,原本的都是默认的(我的cuda为0)
- def parse_args():
- parser = argparse.ArgumentParser()
- parser.add_argument('--gpu', type=int, default='0', help='gpu id')
- parser.add_argument('--mode', type=str, default='train', choices=['train', 'test', 'train_test', 'inference'])
- parser.add_argument('--data_path', type=str, default='dataset/emotic_pre',help='Path to preprocessed data npy files/ csv files')
- parser.add_argument('--experiment_path', type=str, default='debug_exp', help='Path to save experiment files (results, models, logs)')
- parser.add_argument('--model_dir_name', type=str, default='models', help='Name of the directory to save models')
- parser.add_argument('--result_dir_name', type=str, default='results', help='Name of the directory to save results(predictions, labels mat files)')
- parser.add_argument('--log_dir_name', type=str, default='logs', help='Name of the directory to save logs (train, val)')
- parser.add_argument('--inference_file', type=str, help='Text file containing image context paths and bounding box')
- parser.add_argument('--context_model', type=str, default='resnet18', choices=['resnet18', 'resnet50'], help='context model type')
- parser.add_argument('--body_model', type=str, default='resnet18', choices=['resnet18', 'resnet50'], help='body model type')
- parser.add_argument('--learning_rate', type=float, default=0.01)
- parser.add_argument('--weight_decay', type=float, default=5e-4)
- parser.add_argument('--cat_loss_weight', type=float, default=0.5, help='weight for discrete loss')
- parser.add_argument('--cont_loss_weight', type=float, default=0.5, help='weight fot continuous loss')
- parser.add_argument('--continuous_loss_type', type=str, default='Smooth L1', choices=['L2', 'Smooth L1'], help='type of continuous loss')
- parser.add_argument('--discrete_loss_weight_type', type=str, default='dynamic', choices=['dynamic', 'mean', 'static'], help='weight policy for discrete loss')
- parser.add_argument('--epochs', type=int, default=100)
- parser.add_argument('--batch_size', type=int, default=8) # use batch size = double(categorical emotion classes)
- # Generate args
- args = parser.parse_args()
- return args

一般项目都是train.py是单独的。此项目mode分为train,test,train_test,inference四种可选模式。
如果有下载预训练权重,可以直接测试,不用训练。训练命令:
python main.py --mode train --data_path dataset/emotic_pre --experiment_path debug_exp训练:因为这个电脑GPU显存不足,所以
epoch=100,batch_size=8
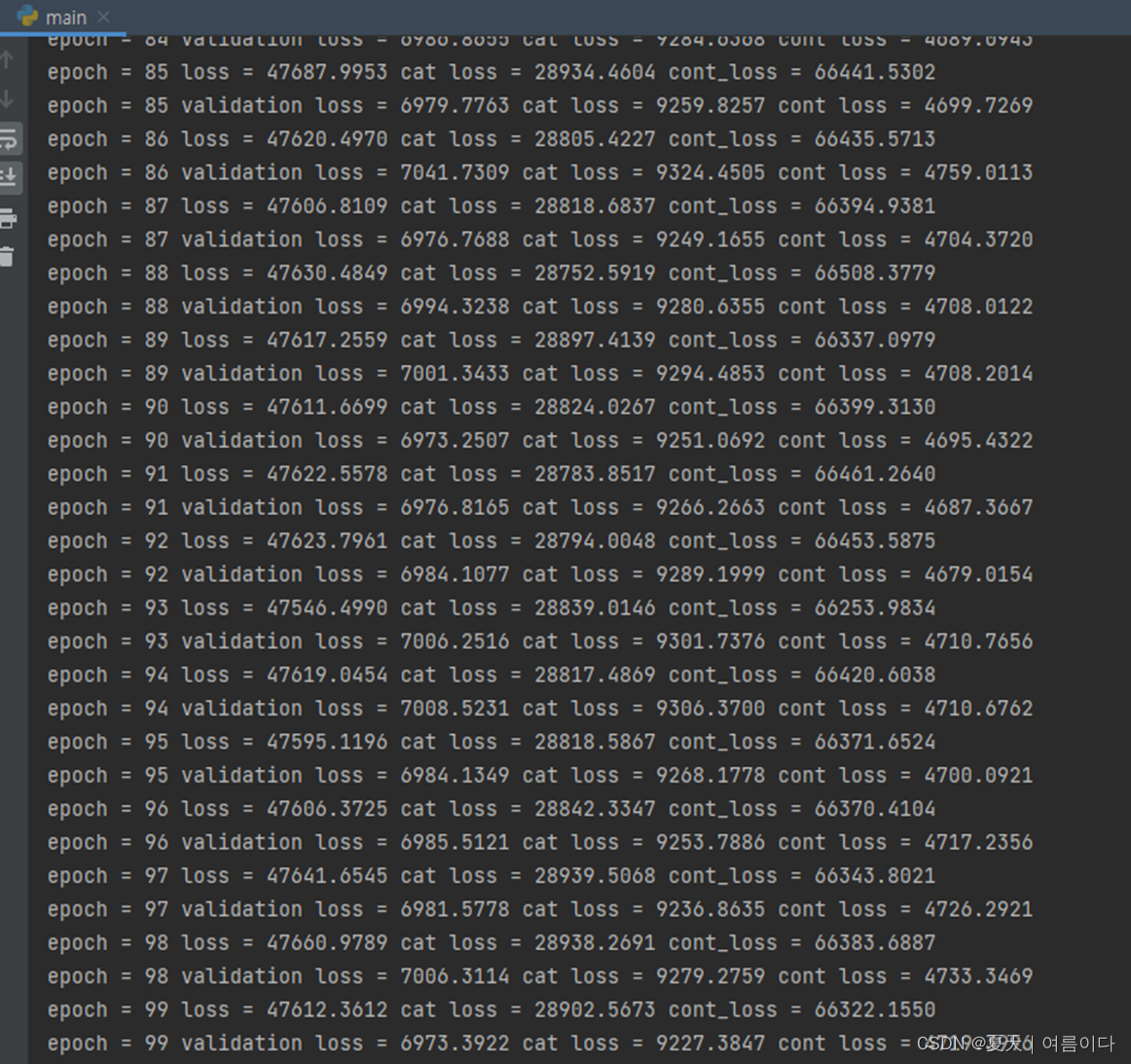
如果不训练,直接测试的话。
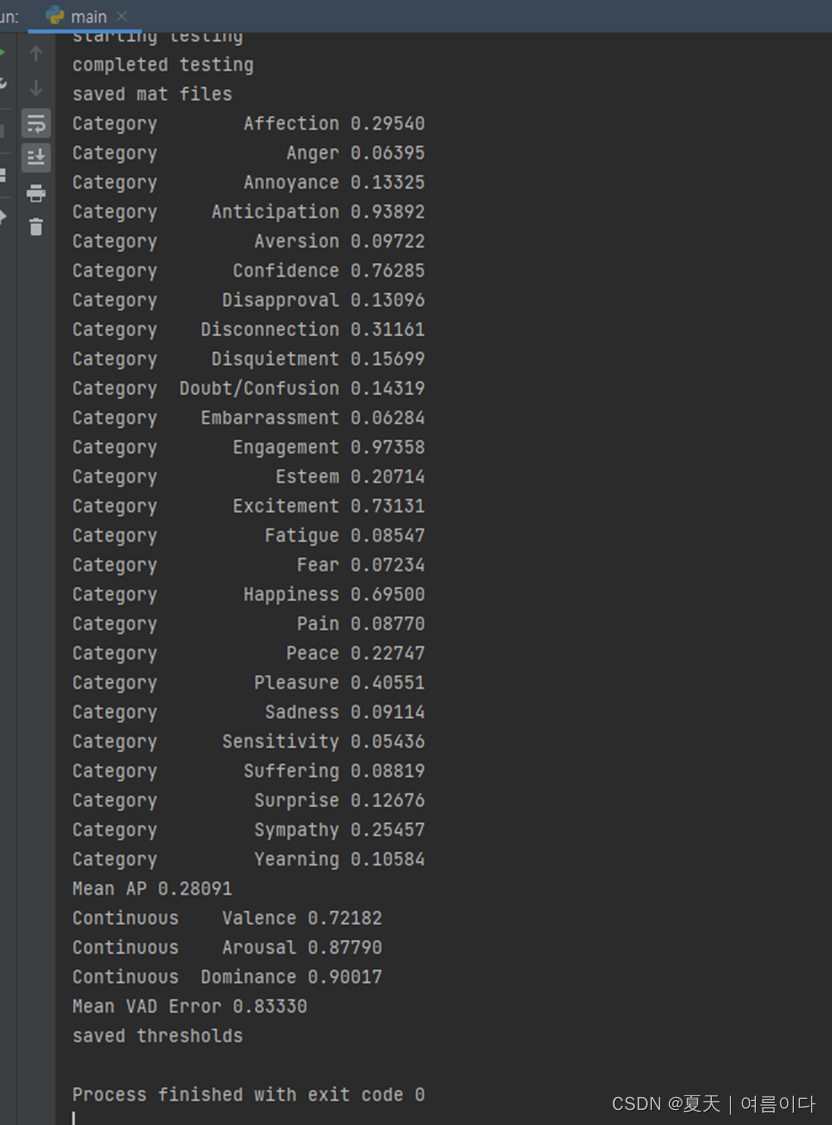
python main.py --mode test --data_path dataset/emotic_pre --experiment_path debug_exp运行结果为:

自动生成文件夹debug_exp,如图

这时候把之前的models复制到debug_exp文件夹下models,把之前的models删掉就可以啦。如图:

再次运行: 运行结果

cpu太卡啦。卡了一个点,有GPU的话都是直接出结果的![]() 。
。

因为没有训练,这个平均精度是真的很低。
如果要进行推理的话:一定要记得改sample_inference_list.txt里的路径
拿我的举例:
- /dataset/emotic/mscoco/images/COCO_val2014_000000562243.jpg 86 58 564 628
- /dataset/emotic/mscoco/images/COCO_train2014_000000288841.jpg 485 149 605 473
如果按我的步骤的话直接复制就可以,然后再推理。不过需要val_thresholds.npy文件。这个文件的话是训练后才会生成的。
python main.py --mode inference --inference_file sample_inference_list.txt --experiment_path debug_exp如果直接运行的话
需要修改自定义参数:
- def parse_args():
- parser = argparse.ArgumentParser()
- parser.add_argument('--gpu', type=int, default='0', help='gpu id')
- parser.add_argument('--experiment_path', type=str,default='debug_exp', help='Path of experiment files (results, models, logs)')
- parser.add_argument('--model_dir', type=str, default='models', help='Folder to access the models')
- parser.add_argument('--result_dir', type=str, default='results', help='Path to save the results')
- parser.add_argument('--inference_file', type=str,default='sample_inference_list.txt', help='Text file containing image context paths and bounding box')
- parser.add_argument('--video_file', type=str, help='Test video file')
- # Generate args
- args = parser.parse_args()
- return args
执行推理后后:

提示缺少yolov3.cfg,下载后
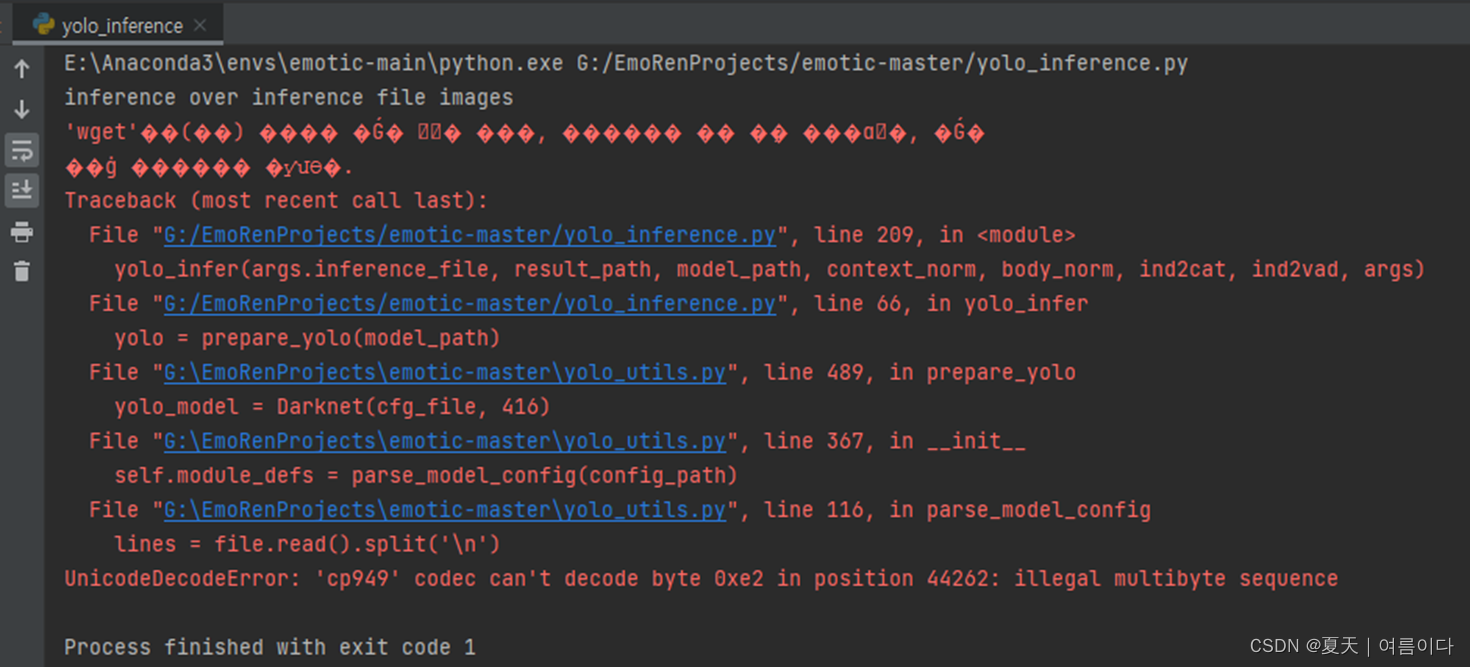
UnicodeDecodeError: 'cp949' codec不能解码位置44262的字节0xe2:非法多字节序列
项目参数详解:
main.py中:
* data_dir: 包含情感和注释文件夹的目录路径,如上述数据目录结构中所述。
* generate_npy: 用于指定生成npy文件(以后用于训练和测试)和CSV文件的参数。如果不通过,则只生成CSV文件。
* mode:运行主文件的模式。
* data_path: 包含第一步生成的预处理数据和CSV文件的目录路径。
* experiment_path: 实验目录的路径。该目录将保存结果、模型和日志。
* inference_file。推理文件,指定要执行推理的图像。一行是:'full_path_of_image x1 y1 x2 y2',其中(x1,y1)和(x2,y2)指定包围盒。参考[sample_inference_list.txt](https://github.com/Tandon-A/emotic/blob/master/sample_inference_list.txt)。
train.py中:
* opt。优化器对象。
* scheduler: 学习率调度器对象。
* models: 包含model_context、model_body和emotic_model(融合模型)的列表,按顺序排列。
* device: 如果有的话,用于发送张量到GPU。
* train_loader: 在训练数据集上迭代的数据加载器。
* val_loader: 迭代器在验证数据集上迭代。
* disc_loss: 离散损失。离散情绪类别预测和目标情绪类别之间的损失测量。
* cont_loss: 连续损失。连续VAD情感预测与目标VAD值之间的损失度量。
* train_writer: SummaryWriter对象,用于保存训练日志。
* val_writer: SummaryWriter对象,用于保存验证日志。
* model_path: 训练后保存模型的目录路径。
* args: 运行时参数。
个人总结:
emotic中,打印的精度是最后一次的输出精度。
通过识别people和场景的情感标识,利用CNN网络学习到各个标签的特征,从而进行识别。
优点:
打破传统的人脸情绪识别7分类,让人的情感更加丰富,感情中有26种表情可以包含人类情感的所有种类,可以很好的反映出人的情感。
提供了NLP领域的VAD接口。
缺点:
无法单纯从视觉角度识别26种心情,例如26种离散情感里,有一种是心理上的痛苦,有一种是生理上的痛苦,这种问题可以无法从视觉中识别。
无关算法,数据集中标签不是特别清晰,也是情感识别的难点之一。因为打的标签会根据我们每个人的看法会有不同的心情。没有固定的标准,会让机器无法识别到准确的信息,所以截止到2022年4月24日,最高精度35点多。

