
- 1Docker基本管理和虚拟化
- 2Linux麒麟V10磁盘挂载步骤
- 3WPF的DataGrid的某个列绑定数据的三种方法(Binding、Converter、DataTrigger)_wpf中的datagrid怎么绑定数据库表中对应的列
- 4mysql 索引管理_MySQL索引管理
- 5Oracle Database 11.2.0.4升级到 12.2.0.1_database time zone version is 26. it is older than
- 6Vue全家桶_v ue全家桶
- 7MT2057 门票
- 8hive调用方式及数据导出_hive数据导出到excel
- 9【数据结构】这里有一份KMP算法优化的详细攻略,不要错过哦!!!_kmp 优化
- 10基于SpringBoot+MySQL的在线订餐系统
OpenAI开发系列(三):OpenAI的大模型生态介绍_openai()默认的是哪个大模型
赞
踩

OpenAI的大模型产品并不是只有一个模型,而是由一系列涵盖文本、代码、对话、图像等具有不同能力和价格选项的多样化模型提供支持。
1. 语言类大模型
对于语言类的大模型,OpenAI提供了GPT3、GPT-3.5、GPT-4系列模型,用来理解和生成自然语言和代码
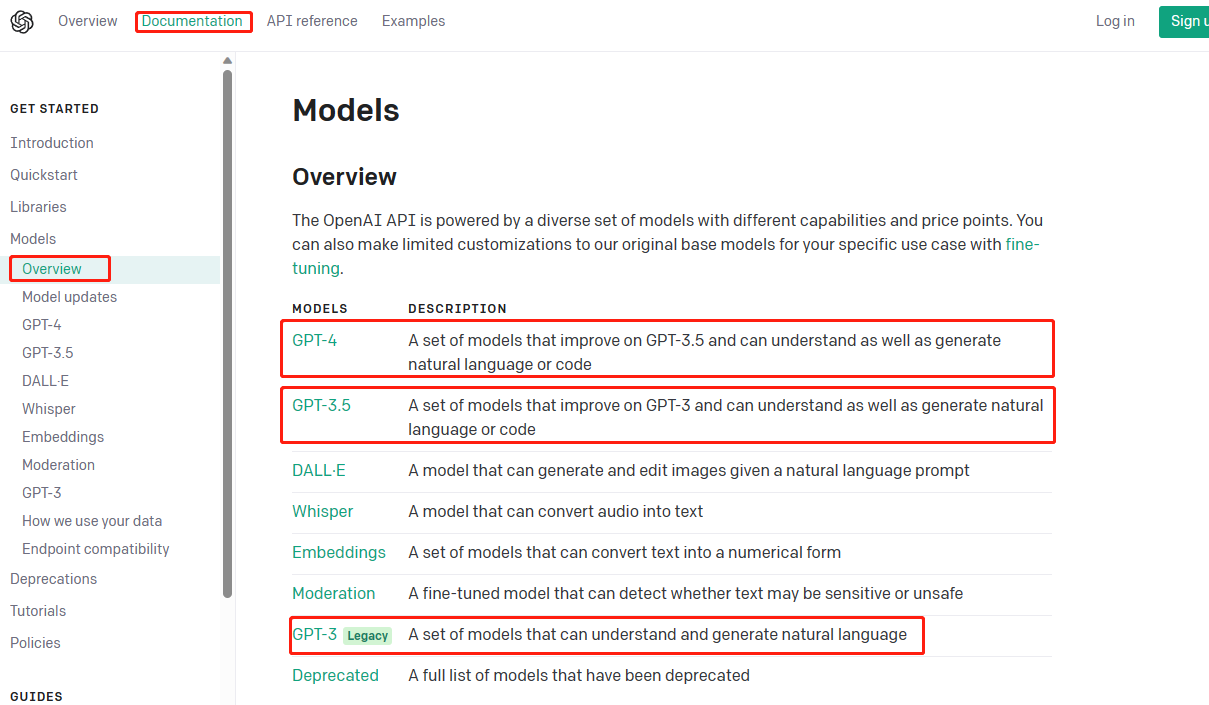
OpenAI在训练GPT3的同时,也训练了A、B、C、D四大基座模型,它们的参数不同,复杂度也不相同,可以用于不同的场景,全称分别为:ada,babbage,curie和davinci。
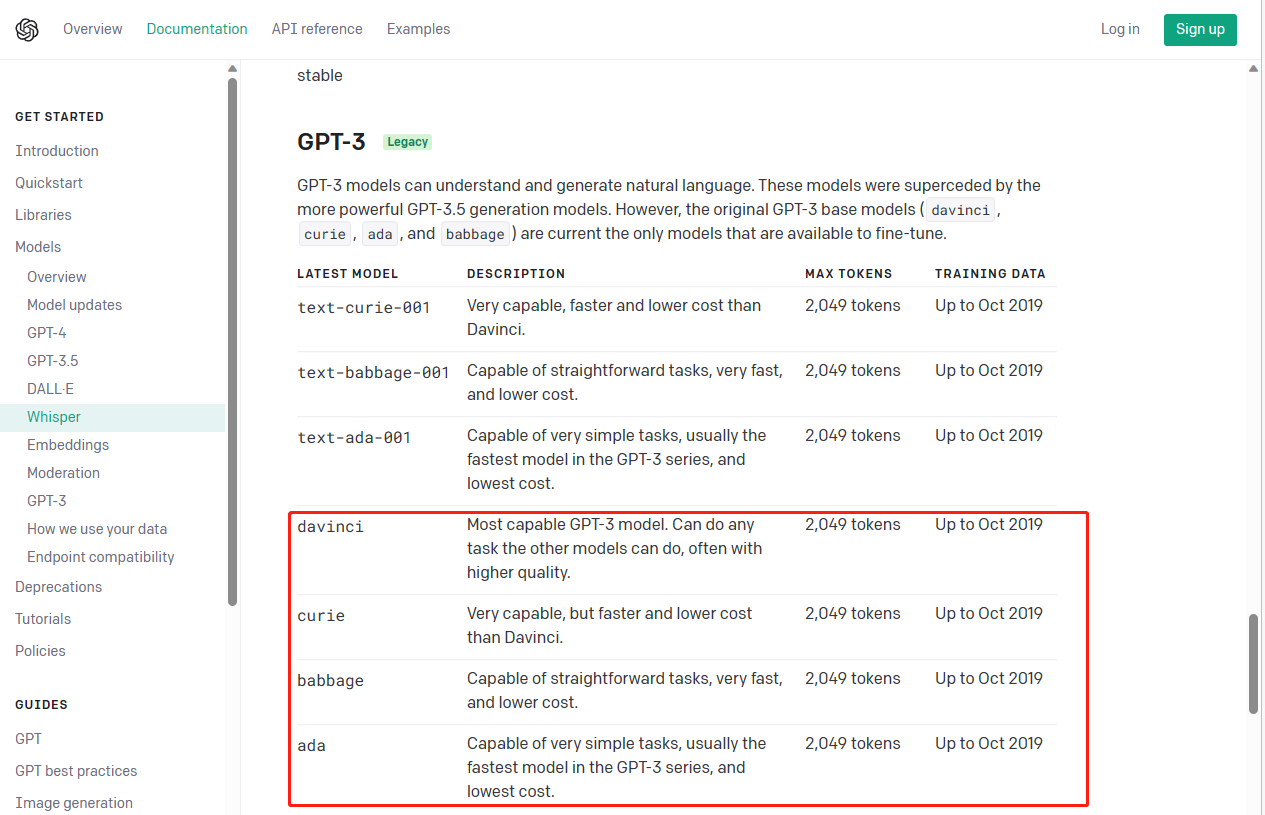
ada:能够执行非常简单的任务,通常是GPT-3系列中速度最快且成本最低的模型。支持2049个令牌
babbage:能够执行简单的任务,非常快速且成本更低。支持2049个令牌。
curie:非常强大,比davinci更快速和成本更低。支持2049个令牌。
davinci:最强大的GPT-3模型。能够执行其他模型能够执行的任何任务,并且通常具有更高的质量。支持2049个令牌。
所以从官方的介绍来看,这四个模型并不是GPT-3的微调模型,而是独立训练的四个模型,并且按照参数规模和复杂程度依次递增
2. 图像多模态大模型
DALL·E是一个能够根据自然语言描述创建逼真图像和艺术作品的人工智能系统。目前支持根据提示的能力,创建具有特定尺寸的新图像,编辑现有图像,或者创建用户提供图像的变体。
目前最新版本是:DALL·E模型是第二代DALL·E模型,相比原始模型,它能够生成更逼真、更准确,并且分辨率比原模型提高了4倍的图像。

DALL·E对图像的理解能力源于大语言模型,并将这种能力应用到了视觉领域,其核心方法是:将图像看做一种语言,将其转化成Token,然后将其与文本的Token放在一起进行训练
3. 语音识别模型
Whisper是一个通用的语音识别模型。它在大规模多样化的音频数据集上进行了训练,并且是一个多任务模型,可以进行多语种的语音识别、语音翻译和语言识别。
目前的最新版本是Whisper v2-large model,它已经被OpenAI开源,可以做本地部署,也可以像其它OpenAI大模型一样通过API调用。

4. 文本向量化模型
Embeddings是文本的数值表示,可以用来衡量两段文本之间的相关性。作为文本嵌入模型,其能力是将文本转化为词向量,通过对词向量的相似度计算等操作,可以对其表示的真实文本做推荐、分类、搜索等任务。
目前最新的版本是:text-embedding-ada-002

大致过程基本如下:
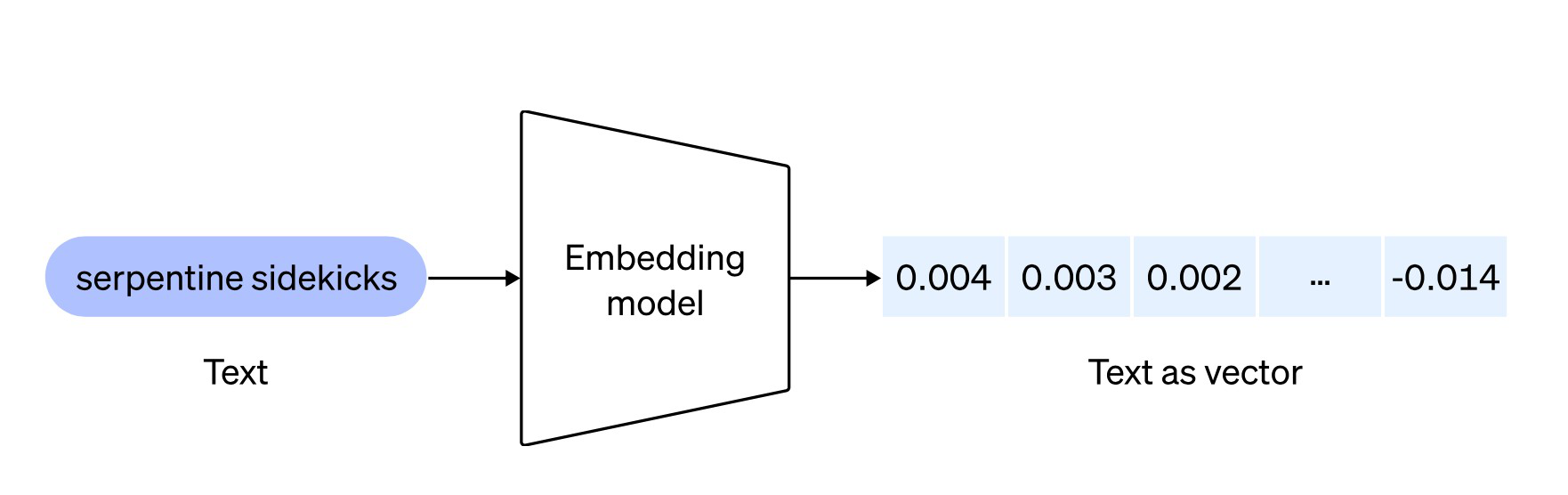
Embedding会将词、句子或者更高级别的语言结构,映射到高位空间的向量中,使语义上相近的词或者句子在向量空间中的距离也较近,GPT模型的Embedding层在训练过程中是通过自回归训练完成,微调往往修改的也是Embedding层。
5. 审查模型
Moderation模型旨在检查内容是否符合OpenAI的使用政策。这些模型提供分类能力,用于检测以下内容类别:仇恨、仇恨/威胁、自残、性内容、涉及未成年人的性内容、暴力以及暴力/图形等内容。
nAI的使用政策。这些模型提供分类能力,用于检测以下内容类别:仇恨、仇恨/威胁、自残、性内容、涉及未成年人的性内容、暴力以及暴力/图形等内容。

最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
期待与您在未来的学习中共同成长。

