
- 1windwos10搭建我的世界服务器,并通过内网穿透实现联机游戏Minecraft_mc内网穿透
- 2Win10内置Ubuntu重启Docker服务_win10重启docker服务
- 3Python 如何使用 HttpRunner 做接口自动化测试_python+httprunner
- 4搜索引擎之中文分词实现(java版)_java 文本转向量库
- 5Graph Convolutional Neural Networks for Web-Scale Recommender Systems(用于Web级推荐系统的图形卷积神经网络)
- 6jmeter 入门到精通
- 7动手学深度学习 21 卷积层里的多输入多输出通道_多输入输出通道卷积
- 84.1.HTTP网络请求原理_网络请求的原理
- 9使用Python对酷狗排行榜进行爬取 BeautifulSoup_爬取酷狗音乐 歌曲清单接口
- 10web期末作业网页设计实例代码 (建议收藏) HTML+CSS+JS (网页源码)_单页网站制作与设计源代码
SparkContext、SparkConf和SparkSession的初始化_sparksession初始化的sparksession
赞
踩
SparkContext 和 SparkConf
任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数。
初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。
val conf = new SparkConf().setMaster("master").setAppName("appName")
val sc = new SparkContext(conf)
或者
val sc = new SparkContext("master","appName")
Note:
Once a SparkConf object is passed to Spark, it is cloned and can no longer be modified by the user.
也就是说一旦设置完成SparkConf,就不可被使用者修改
对于单元测试,您也可以调用SparkConf(false)来跳过加载外部设置,并获得相同的配置,无论系统属性如何。
咱们再看看setMaster()和setAppName()源码:

根据上面的解释,setMaster主要是连接主节点,如果参数是"local",则在本地用单线程运行spark,如果是 local[4],则在本地用4核运行,如果设置为spark://master:7077,就是作为单节点运行,而setAppName就是在web端显示应用名而已,它们说到底都调用了set()函数,让我们看看set()是何方神圣
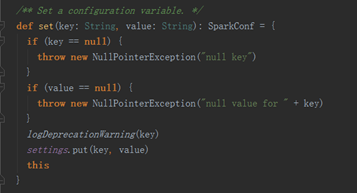
logDeprecation(key)是日志输出函数,防止输入参数名无效, 看看settings,是个HashMap结构,追溯一下:

果然,是个ConcurrentHashMap对象,ConcurrentHashMap主要作用是解决多线程并发下数据段访问效率,该类相对于hashMap而言具有同步map中的数据,对于hashTable而言,该同步数据对于并发程序提高了极高的效率,所以在使用缓存机制的时候如果对map中的值具有高并发的情况的话,那么我们就需要使用ConcurrentHashMap,ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点)
,CurrentHashMap的初始化一共有三个参数,一个initialCapacity,表示初始的容量,一个loadFactor,表示负载参数,最后一个是concurrentLevel,代表ConcurrentHashMap内部的Segment的数量,ConcurrentLevel一经指定,不可改变,这也是为什么SparkConf配置好了就无法更改的原因。
ConcurrentHashMap应用了锁分段技术,HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
另外,如果ConcurrentHashMap的元素数量增加导致ConrruentHashMap需要扩容,ConcurrentHashMap是不会增加Segment的数量的,而只会增加Segment中链表数组的容量大小,这样的好处是扩容过程不需要对整个ConcurrentHashMap做rehash,而只需要对Segment里面的元素做一次rehash就可以了。
SparkSession: SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
val sparkSession = SparkSession.builder
.master("master")
.appName("appName")
.getOrCreate()
或者
SparkSession.builder.config(conf=SparkConf())
上面代码类似于创建一个SparkContext,master设置为"xiaojukeji",然后创建了一个SQLContext封装它。如果你想创建hiveContext,可以使用下面的方法来创建SparkSession,以使得它支持Hive(HiveContext):
val sparkSession = SparkSession.builder
.master("master")
.appName("appName")
.enableHiveSupport()
.getOrCreate()
//sparkSession 从csv读取数据:
val dq = sparkSession.read.option("header", "true").csv("src/main/resources/scala.csv")
val sparkSession = SparkSession.builder
.master("master")
.appName("appName")
.enableHiveSupport()
.getOrCreate()
//sparkSession 从csv读取数据:
val dq = sparkSession.read.option("header", "true").csv("src/main/resources/scala.csv")
getOrCreate():有就拿过来,没有就创建,类似于单例模式:
s1 = SparkSession().builder.config("k1", "v1").getORCreat()
s2 = SparkSession().builder.config("k2", "v2").getORCreat()
return s1.conf.get("k1") == s2.conf.get("k2")
True

