
- 1安装激活LSPosed_lsposed 未安装或未激活
- 2hive-2.3.7的搭建_apache-hiv-2.3.7
- 3大数据存储基石——HDFS_hdfs内容为[object object]
- 4亿级表优化「TIDB 分区篇」,值得收藏_tidb 分区表
- 5Linux---(五)三大工具yum、vim、gcc/g++_yum vim
- 6【会议征稿】2024年计算机视觉、机器人与自动化工程国际学术会议(CRAE 2024, 6/21-23)_胡来归
- 7【docker】在windows下配置linux深度学习环境并开启ssh远程连接_windows使用docker的话需要借助linux虚拟机
- 8【小筱在线】JavaFx实现的人工智能AI娱乐工具
- 9Mac中安装Node和版本控制工具nvm遇到的坑,知乎上已获万赞_mac 会出现node版本问题吗
- 10面试必刷算法TOP101之买卖股票篇 TOP29_假设你有一个数组prices,长度为n,其中prices叮是某只股票在第i天的价格请根据这个
UNET详解和UNET++介绍(零基础)
赞
踩
一·背景介绍
-
背景介绍:
自2015年以来,在生物医学图像分割领域,U-Net得到了广泛的应用,目前已达到四千多次引用。至今,U-Net已经有了很多变体。目前已有许多新的卷积神经网络设计方式,但很多仍延续了U-Net的核心思想,加入了新的模块或者融入其他设计理念。编码和解码,早在2006年就发表在了nature上.当时这个结构提出的主要作用并不是分割,而是压缩图像和去噪声.后来把这个思路被用在了图像分割的问题上,也就是现在我们看到的FCN或者U-Net结构,在它被提出的三年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的结构是没有改动的, 即下采样、上采样和跳跃连接。
-
医学图像特点:
(1)图像语义较为简单、结构较为固定。我们做脑的,就用脑CT和脑MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一个固定的器官的成像,而不是全身的。由于器官本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要。(2)数据量少。医学影像的数据获取相对难一些,很多比赛只提供不到100例数据。所以我们设计的模型不宜多大,参数过多,很容易导致过拟合。
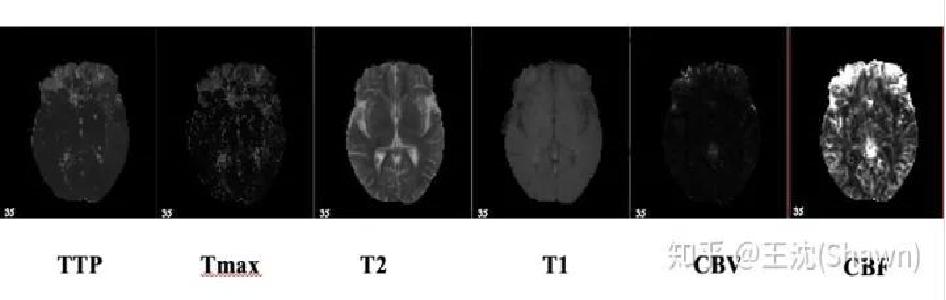
(原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内)非常轻量。个人尝试过使用Deeplab v3+和DRN等自然图像语义分割的SOTA网络在自己的项目上,发现效果和UNet差不多,但是参数量会大很多。(3)多模态。相比自然影像,医疗影像是具有多种模态的。以ISLES脑梗竞赛为例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多种模态的数据。比如CBF是脑血流量,CBV用于检测巨细胞病毒的。
(4)可解释性重要。由于医疗影像最终是辅助医生的临床诊断,所以网络告诉医生一个3D的CT有没有病是远远不够的,医生还要进一步的想知道,病在哪一层,在哪一层的哪个位置,分割出来了吗,能不能求体积。 -
图像分割是什么?
简单的来讲就是给一张图像,图像分割出一个物体的准确轮廓。也这样考虑,给出一张图像 I,这个问题就是求一个函数,从I映射到Mask。求这个函数有很多方法,但是第一次将深度学习结合起来的是全卷积网络(FCN),利用深度学习求这个函数。
二·全卷积网络(FCN)
很多分割网络都是基于FCN做改进,我们先介绍FCN的内容。
-
FCN介绍:
FCN是深度学习在图像分割的开山之作。在此之前深度学习一般用在分类和检测问题上。由于用到CNN,所以最后提取的特征的尺度是变小的。和我们要求的函数不一样,我们要求的函数是输入多大,输出有多大。经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出),FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,最后在上采样的特征图上进行逐像素分类。解决了语义级别的图像分割问题。由于网络中只有卷积没有全连接,所以这个网络又叫全卷积网络。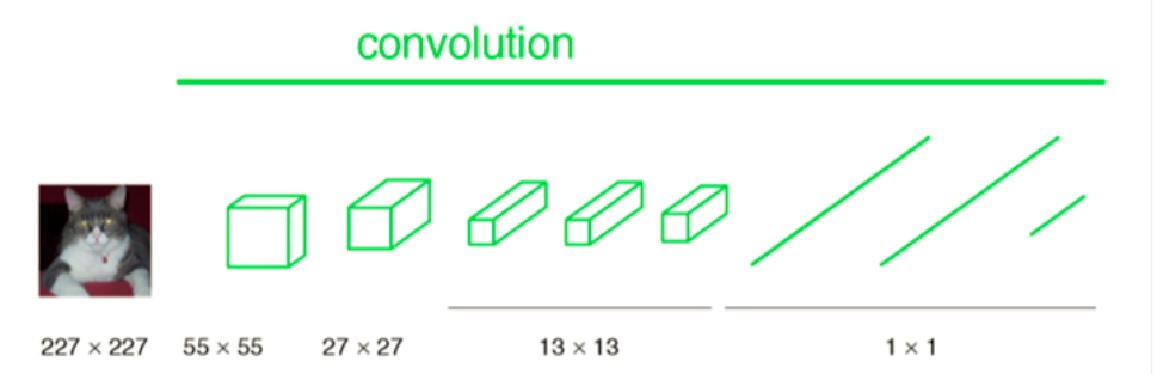

-
FCN框架:
输入原图,得到五次池化后的特征图,然后将特征map上采样回去。再将预测结果和ground truth每个像素一一对应分类,做像素级别分类。也就是说将分割问题变成分类问题,而分类问题正好是深度学习的强项。如果只将特征map直接上采样或者反卷积,明显会丢失很多信息。FCN采取解决方法是将pool4、pool3、和特征map融合起来,由于pool3、pool4、特征图大小尺寸是不一样的,所以融合前应该上采样到同一尺寸。这里的融合对应元素相加。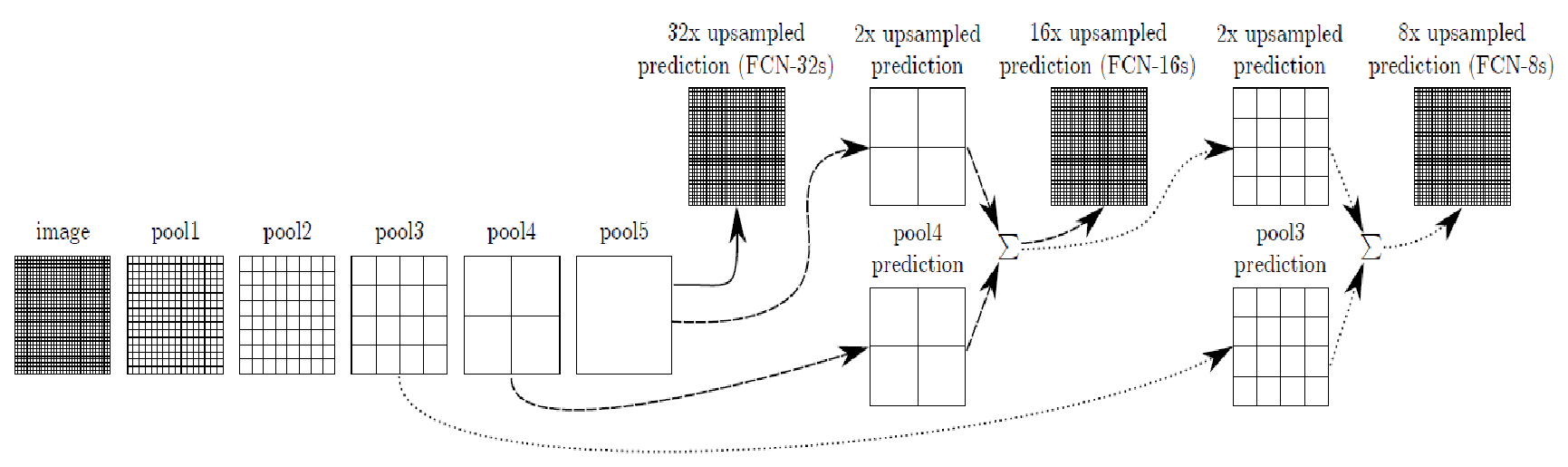
-
反卷积层:
反卷积层也是卷积层。乍看一下好像反卷积和卷积的工作过程差不多,主要的区别在于反卷积输出图片的尺寸会大于输入图片的尺寸,通过增加padding来实现这一操作。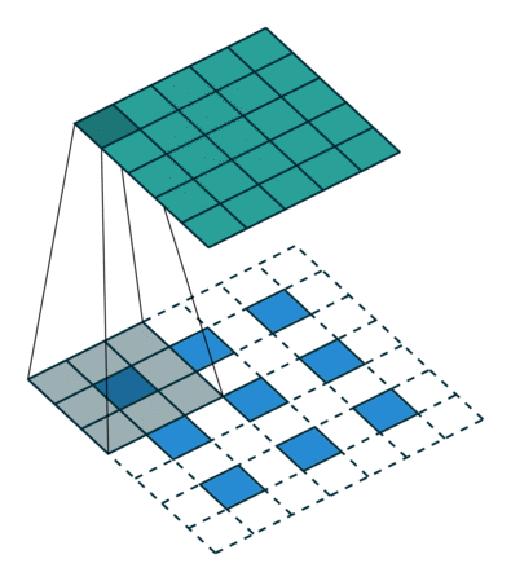
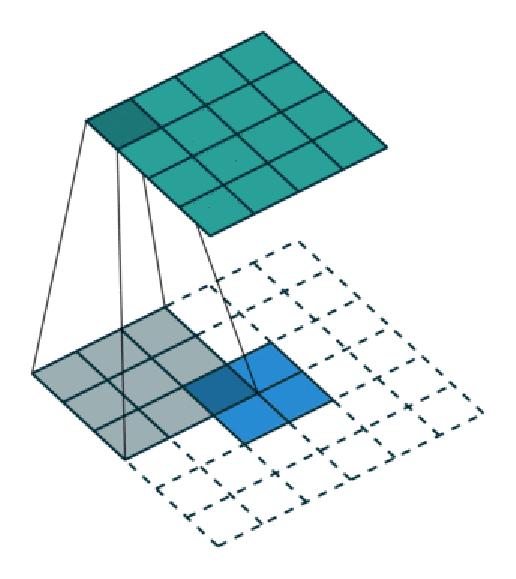
-
输入图片大小任意:
首先,我们来看传统CNN为什么需要固定输入图片大小。
对于CNN,一幅输入图片在经过卷积和pooling层时,这些层是不关心图片大小的。比如对于一个卷积层,,它并不关心inputsize多大,pooling层同理。但是在进入全连接层时,feature map(假设大小为n×n)要拉成一条向量,而向量中每个元素(共n×n个)作为一个结点都要与下一个层的所有结点(假设4096个)全连接,这里的权值个数是4096×n×n,而我们知道神经网络结构一旦确定,它的权值个数都是固定的,所以这个n不能变化,n是conv5的outputsize,所以层层向回看,每个outputsize都要固定,因此输入图片大小要固定。
而全卷积是没有全连接层的,所以不要求输入图片大小固定。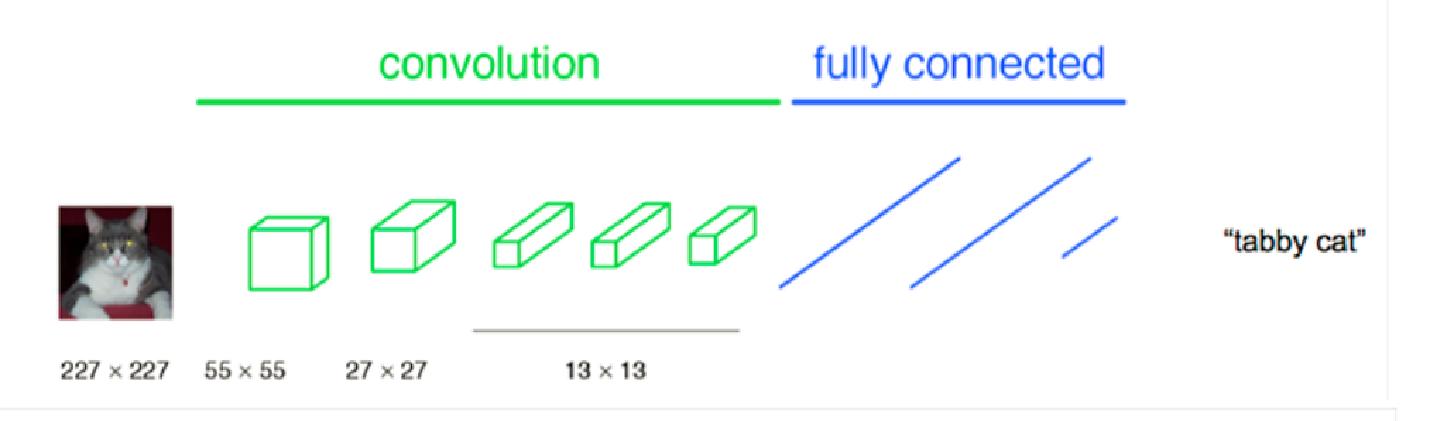
-
分割效果:
FCN优点是实现端到端分割。输入是原始数据输出是最终结果,缺点是分割结果细节不够好,可以看到FCN8s是上面讲的pool4、pool3和特征图融合,FCN16s是pool4和特征map融合,FCN32s是只有特征map,得出结果都是细节不够好,具体可以看自行车。
作者还尝试了结合pool2发现效果并没有提升。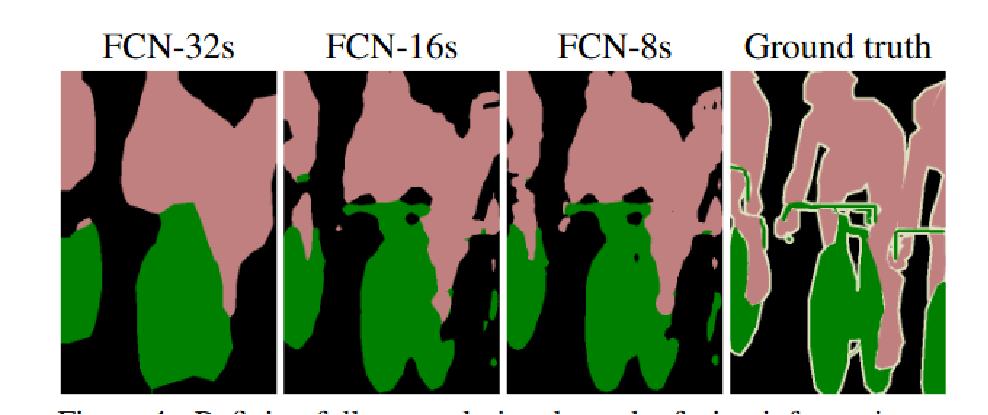
三·UNET
-
网络架构:
Unet包括两部分,可以看右图,第一部分,特征提取,VGG类似。第二部分上采样部分。由于网络结构像U型,所以叫Unet网络。特征提取部分,每经过一个池化层就一个尺度,包括原图尺度一共有5个尺度。上采样部分,每上采样一次,就和特征提取部分对应的通道数相同尺度融合,但是融合之前要将其crop。这里的融合是拼接。可以看到,输入是572x572的,但是输出变成了388x388,这说明经过网络以后,输出的结果和原图不是完全对应的。
蓝色箭头代表3x3的卷积操作,并且stride是1,padding策略是vaild,因此,每个该操作以后,featuremap的大小会减2。红色箭头代表2x2的maxpooling操作,需要注意的是,此时的padding策略也是vaild,这就会导致如果pooling之前featuremap的大小是奇数,会损失一些信息 。所以要选取合适的输入大小,因为2*2的max-pooling算子适用于偶数像素点的图像长宽。绿色箭头代表2x2的反卷积操作,这个只要理解了反卷积操作,就没什么问题,操作会将featuremap的大小乘2。灰色箭头表示复制和剪切操作,可以发现,在同一层左边的最后一层要比右边的第一层要大一些,这就导致了,想要利用浅层的feature,就要进行一些剪切。
输出的最后一层,使用了1x1的卷积层做了分类。最后输出了两层是前景和背景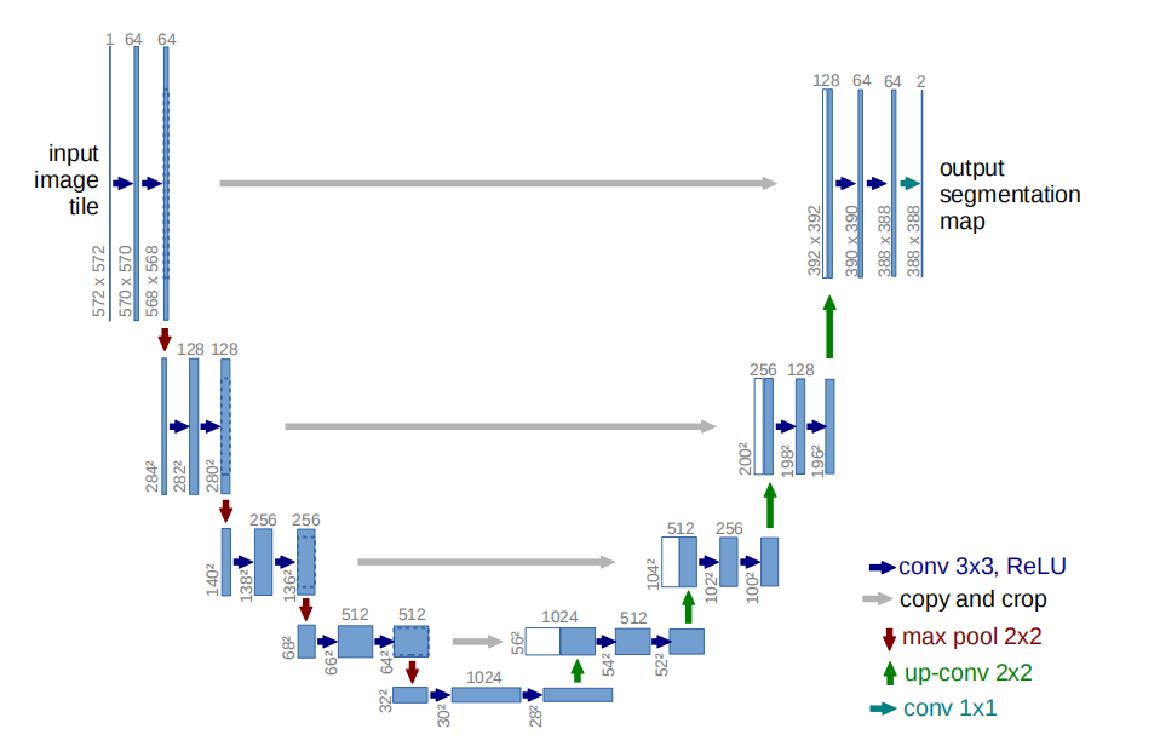
-
valid卷积:
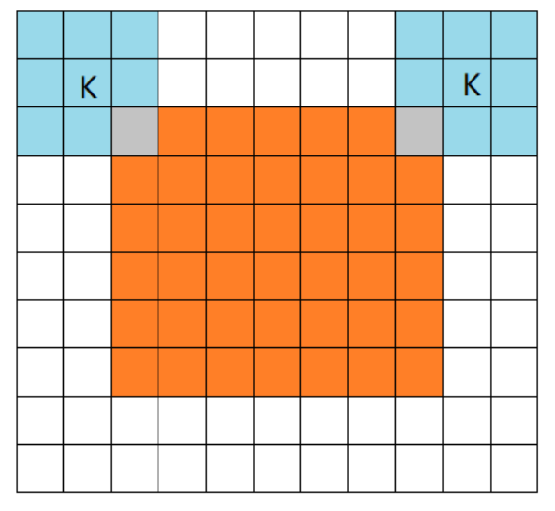
这三种不同模式是对卷积核移动范围的不同限制。full mode,橙色部分为image, 蓝色部分为filter。full模式的意思是,从filter和image刚相交开始做卷积,白色部分为填0。same mode,当filter的中心(K)与image的边角重合时,开始做卷积运算,可见filter的运动范围比full模式小了一圈。注意:这里的same还有一个意思,卷积之后输出的feature map尺寸保持不变(相对于输入图片)。当然,same模式不代表完全输入输出尺寸一样,也跟卷积核的步长有关系。same模式也是最常见的模式,因为这种模式可以在前向传播的过程中让特征图的大小保持不变,调参不需要精准计算其尺寸变化(因为尺寸根本就没变化)。
valid mode,当filter全部在image里面的时候,进行卷积运算,可见filter的移动范围较same更小了。full mode:
 same mode:
same mode: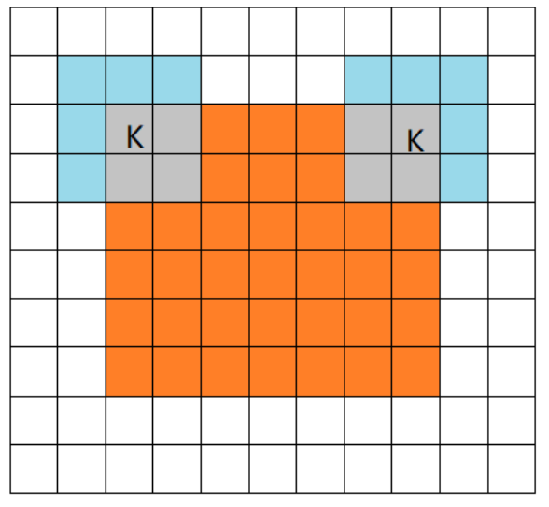 valid mode:
valid mode:
-
overlap-tile策略:
医学图像是一般相当大,分割时候不可能将原图直接输入网络,所以用一个滑动窗口把原图扫一遍,使用原图的切片进行训练或测试。可以看图,红框是要分割区域。但是在切图时要包含周围区域,overlap另一个重要原因是周围overlap部分可以为分割区域边缘部分提供纹理等信息。
这样的策略会带来一个问题,图像边界的图像块没有周围像素,卷积会使图像边缘处的信息丢失。因此作者对周围像素采用了镜像扩充。下图中红框部分为原始图片,其周围扩充的像素点均由原图沿白线对称得到。这样,边界图像块也能得到准确的预测。
另一个问题是,这样的操作会带来图像重叠问题,即第一块图像周围的部分会和第二块图像重叠。因此作者在卷积时只使用有效部分。我理解的是使用valid卷积和crop裁剪,最终传到下一层的只有中间原先图像块(黄色框内)的部分。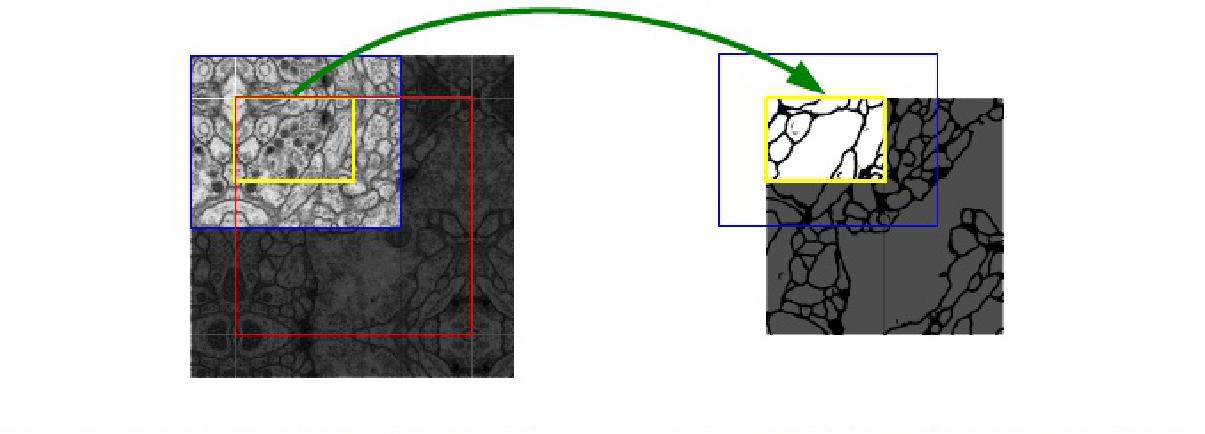
-
弹性变换:
由于深度神经网络具有非常强的学习能力,如果没有大量的训练数据,会造成过拟合,训练出的模型难以应用。因此对于一些没有足够样本数量的问题,可以通过已有的样本,对其进行变换,人工增加训练样本。常用的增加训练样本的方法主要有对图像进行旋转、位移等仿射变换,也可以使用镜像变换。,这里介绍弹性变换。该算法最开始应用在mnist手写体数字识别数据集中,发现对原图像进行弹性变换的操作扩充样本以后,对于手写体数字的识别效果有明显的提升。
因为unet论文的数据集是细胞组织的图像,细胞组织的边界每时每刻都会发生不规则的畸变,所以采用弹性变形的增广是非常有效的。
下面来详细介绍一下算法流程:
弹性变化是对像素点各个维度产生(-1,1)区间的随机标准偏差,用高斯滤波对各维度的偏差矩阵进行滤波,最后用放大系数控制偏差范围。 因而由A(x,y)得到的A’(x+delta_x,y+delta_y)。A‘的值通过在原图像差值得到,A’的值充当原来A位置上的值。
图显示的是在固定的n下不同高斯标准差的结果,第二个图的形变效果是最合适的。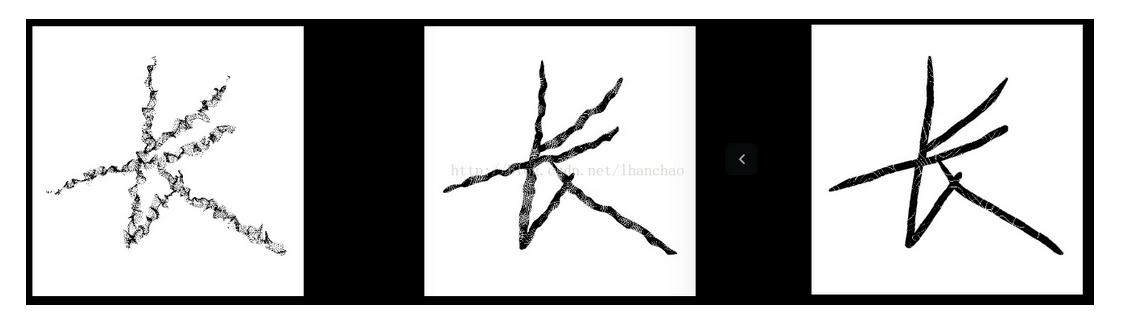
-
损失函数:
损失函数首先是用了个pixel-wise softmax,就是每个像素对应的输出单独做softmax,也就是做了w*h个softmax。
其中,x可以看作是某一个像素点, l(x)表示x这个点对应的类别label,pk(x)表示在x这个点的输出在类别k的softmax的激活值,pl(x)(x)代表什么呢?根据前面的说明就可以推断出来:点x在对应的label给出的那个类别的输出的激活值。
正常的交叉熵定义如第一个公式,可以发现两个公式的意义其实是相同的,后面的公式在外面把非label对应的结果乘0了。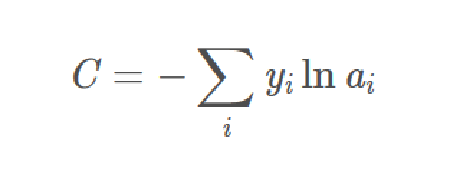
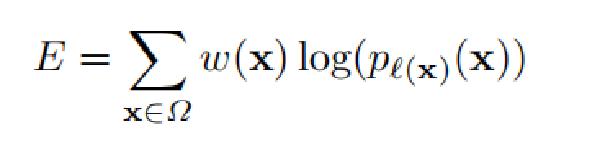
剩下的就是w(x)定义的式子。d1,d2分别是像素点最近和第二近的细胞的距离。这个权重可以调整图像中某个区域的重要程度。细胞组织图像的一大特点是,多个同类的细胞会紧紧贴合在一起,其中只有细胞壁或膜组织分割,因此,作者在计算损失的过程中,给两个细胞重合的边缘部分增加了损失的权重,以此让网络更加注重这类重合的边缘信息。实际情况中,是需要自己根据应用情况来设计或调整这个权重的。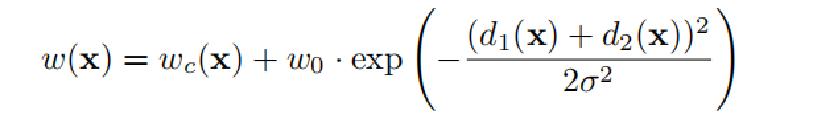
图中的a是raw image,b是ground truth segmentation,c 是生成的分割掩码,白色是前景,黑色是背景。d是增加了像素级的loss权重后,让网络对边界像素进行了更好的学习的结果。
四·unet++
-
提出问题:
第一个问题:既然输入和输出都是相同大小的图,为什么要折腾去降采样一下再上采样呢?
降采样的理论意义是,它可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,增加感受野的大小。上采样的最大的作用其实就是把抽象的特征再还原解码到原图的尺寸,最终得到分割结果。
对于特征提取阶段,浅层结构可以抓取图像的一些简单的特征,比如边界,颜色,而深层结构因为感受野大了,而且经过的卷积操作多了,能抓取到图像的一些抽象特征。
第二个问题:既然unet每一层抓取的特征都很重要,为什么非要降四次之后才开始上采样回去呢? -
网络深度:
提出疑问后, 为了验证多深才好,每加一个深度就训练一个网络,分别用了两个数据集:Electron Microscopy 和 Cell,然后测它们各自的分割表现,先不要看后两个UNet++,就看这个不同深度的U-Net的表现(黄色条形图),我们可以看出,不是越深越好,它背后的传达的信息就是,不同层次特征的重要性对于不同的数据集是不一样的,并不是说设计一个原论文给出的那个结构,就一定对所有数据集的分割问题都最优。
不同数据集的最优的深度是不一样的, 但是总不能把所有不同深度的U-Net都训练一遍,太耗时间了,于是提出unet++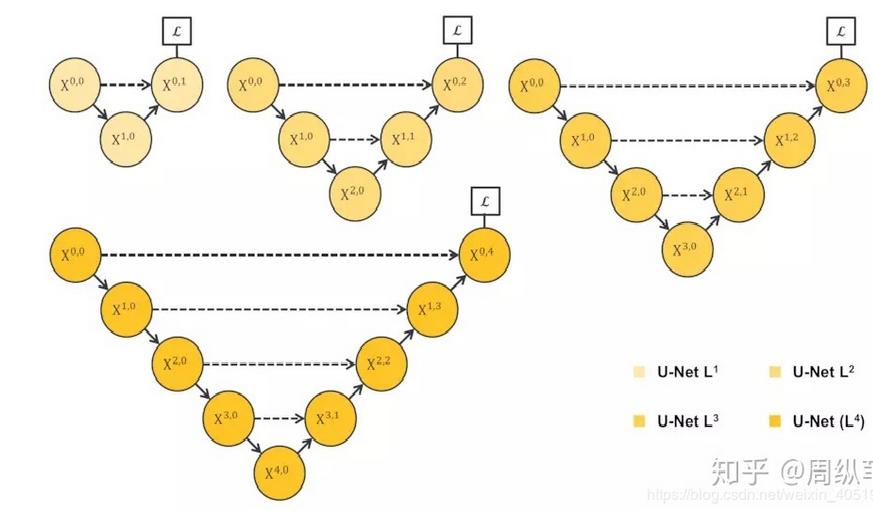

-
模型架构:
这个综合长连接和短连接的架构就是UNet++。
UNet++的优势是可以抓取不同层次的特征,将它们通过特征叠加的方式整合,加入更浅的U-Net结构,使得融合时的特征图尺度差异更小。
UNet++同时也引进了很多参数,占用内存也变大。

版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_41105449/article/details/106651278

