
- 1新中特复习笔记一——论述题(上海交通大学)_交大中特
- 2Windows 和 Linux 下的Gradle配置_gradle linux
- 3Word2Vec词向量,python代码
- 4ModuleNotFoundError: No module named ‘ipykernel‘_modulenotfounderror: no module named 'ipykernel
- 5在pycharm免费版中创建编辑运行Django项目_免费版pycharm能做django吗
- 6docker容器_虚拟化_docker 虚拟 节点
- 7Python之Pycharm安装及pip导包_pycharm怎么安装导包
- 813、Flask实战第13天:SQLAlchemy操作MySQL数据库
- 9前端常见面试基础问题_前端齐刘海问题
- 10博士申请 | 美国西北大学李曼玲老师招收NLP方向全奖博士/博后/硕士/实习生
java web 集成log_JavaWeb项目架构之Kafka分布式日志队列
赞
踩
架构、分布式、日志队列,标题自己都看着唬人,其实就是一个日志收集的功能,只不过中间加了一个Kafka做消息队列罢了。
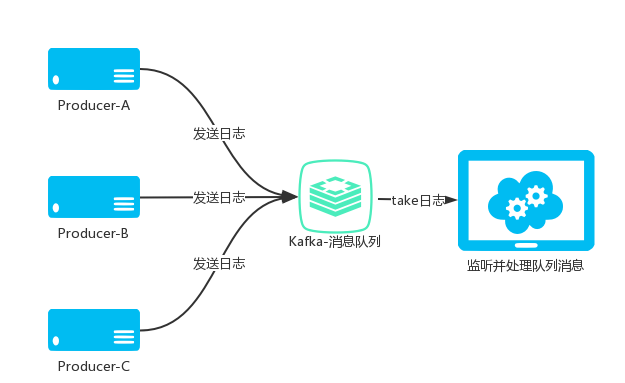
kafka介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
特性
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
支持通过Kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
主要功能发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
以容错的方式记录消息流,kafka以文件的方式来存储消息流
可以再消息发布的时候进行处理
使用场景在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
构建实时的流数据处理程序来变换或处理数据流,数据处理功能
消息传输流程
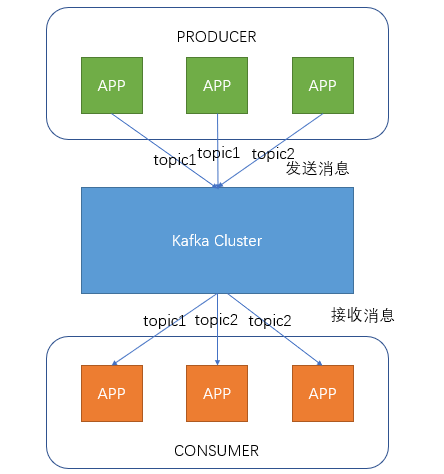
相关术语介绍Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
Kafka安装
环境
Linux、JDK、Zookeeper
下载二进制程序wget https://archive.apache.org/dist/kafka/0.10.0.1/kafka_2.11-0.10.0.1.tgz
安装tar -zxvf kafka_2.11-0.10.0.1.tgzcd kafka_2.11-0.10.0.1
目录说明bin 启动,停止等命令config 配置文件libs 类库
参数说明#########################参数解释##############################broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样port=9092 #当前kafka对外提供服务的端口默认是9092host.name=192.168.1.170 #这个参数默认是关闭的num.network.threads=3 #这个是borker进行网络处理的线程数num.io.threads=8 #这个是borker进行I/O处理的线程数log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小num.partitions=1 #默认的分区数,一个topic默认1个分区数log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天message.max.byte=5242880 #消息保存的最大值5Mdefault.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务replica.fetch.max.bytes=5242880 #取消息的最大直接数log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能zookeeper.connect=192.168.1.180:12181,192.168.1.181:12181,192.168.1.182:1218 #设置zookeeper的连接端口、如果非集群配置一个地址即可#########################参数解释##############################
启动kafka
启动kafka之前要启动相应的zookeeper集群、自行安装,这里不做说明。#进入到kafka的bin目录./kafka-server-start.sh -daemon ../config/server.properties
Kafka集成
环境
spring-boot、elasticsearch、kafka
pom.xml引入:org.springframework.kafka
spring-kafka
1.1.1.RELEASE
生产者import java.util.HashMap;import java.util.Map;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.common.serialization.StringSerializer;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.EnableKafka;import org.springframework.kafka.core.DefaultKafkaProducerFactory;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.core.ProducerFactory;/**
* 生产者
* 创建者 科帮网
* 创建时间2018年2月4日
*/@Configuration@EnableKafkapublic class KafkaProducerConfig { @Value("${kafka.producer.servers}")
private String servers; @Value("${kafka.producer.retries}")
private int retries; @Value("${kafka.producer.batch.size}")
private int batchSize; @Value("${kafka.producer.linger}")
private int linger; @Value("${kafka.producer.buffer.memory}")
private int bufferMemory; public Map producerConfigs() {
Map props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props;
} public ProducerFactory producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs());
} @Bean
public KafkaTemplate kafkaTemplate() { return new KafkaTemplate(producerFactory());
}
}
消费者mport java.util.HashMap;import java.util.Map;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.common.serialization.StringDeserializer;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.EnableKafka;import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;import org.springframework.kafka.config.KafkaListenerContainerFactory;import org.springframework.kafka.core.ConsumerFactory;import org.springframework.kafka.core.DefaultKafkaConsumerFactory;import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;/**
* 消费者
* 创建者 科帮网
* 创建时间2018年2月4日
*/@Configuration@EnableKafkapublic class KafkaConsumerConfig {@Value("${kafka.consumer.servers}")
private String servers; @Value("${kafka.consumer.enable.auto.commit}")
private boolean enableAutoCommit; @Value("${kafka.consumer.session.timeout}")
private String sessionTimeout; @Value("${kafka.consumer.auto.commit.interval}")
private String autoCommitInterval; @Value("${kafka.consumer.group.id}")
private String groupId; @Value("${kafka.consumer.auto.offset.reset}")
private String autoOffsetReset; @Value("${kafka.consumer.concurrency}")
private int concurrency; @Bean
public KafkaListenerContainerFactory> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(concurrency);
factory.getContainerProperties().setPollTimeout(1500); return factory;
} public ConsumerFactory consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs());
} public Map consumerConfigs() {
Map propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); return propsMap;
} @Bean
public Listener listener() { return new Listener();
}
}
日志监听import org.apache.kafka.clients.consumer.ConsumerRecord;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.stereotype.Component;import com.itstyle.es.common.utils.JsonMapper;import com.itstyle.es.log.entity.SysLogs;import com.itstyle.es.log.repository.ElasticLogRepository;/**
* 扫描监听
* 创建者 科帮网
* 创建时间2018年2月4日
*/@Componentpublic class Listener { protected final Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private ElasticLogRepository elasticLogRepository;
@KafkaListener(topics = {"itstyle"})
public void listen(ConsumerRecord, ?> record) {
logger.info("kafka的key: " + record.key());
logger.info("kafka的value: " + record.value()); if(record.key().equals("itstyle_log")){ try {
SysLogs log = JsonMapper.fromJsonString(record.value().toString(), SysLogs.class);
logger.info("kafka保存日志: " + log.getUsername());
elasticLogRepository.save(log);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
测试日志传输/**
* kafka 日志队列测试接口
*/
@GetMapping(value="kafkaLog")
public @ResponseBody String kafkaLog() {
SysLogs log = new SysLogs();
log.setUsername("红薯");
log.setOperation("开源中国社区");
log.setMethod("com.itstyle.es.log.controller.kafkaLog()");
log.setIp("192.168.1.80");
log.setGmtCreate(new Timestamp(new Date().getTime()));
log.setExceptionDetail("开源中国社区");
log.setParams("{'name':'码云','type':'开源'}");
log.setDeviceType((short)1);
log.setPlatFrom((short)1);
log.setLogType((short)1);
log.setDeviceType((short)1);
log.setId((long)200000);
log.setUserId((long)1);
log.setTime((long)1);//模拟日志队列实现
String json = JsonMapper.toJsonString(log);
kafkaTemplate.send("itstyle", "itstyle_log",json);return "success";
}
Kafka与Redis
之前简单的介绍过,JavaWeb项目架构之Redis分布式日志队列,有小伙伴们聊到, Redis PUB/SUB没有任何可靠性保障,也不会持久化。当然了,原项目中仅仅是记录日志,并不是十分重要的信息,可以有一定程度上的丢失
Kafka与Redis PUB/SUB之间最大的区别在于Kafka是一个完整的分布式发布订阅消息系统,而Redis PUB/SUB只是一个组件而已。
使用场景Redis PUB/SUB
消息持久性需求不高、吞吐量要求不高、可以忍受数据丢失
Kafka
高可用、高吞吐、持久性、多样化的消费处理模型

