
- 1我所理解的委托和匿名函数_委托与函数名
- 2打造自己的专属--VSCode主题(仿HBuilderX绿柔主题配色)_vscode绿色主题
- 3RabbitMQ(一)Windows下载安装_rabbitmq下载
- 4C++:十大排序
- 5Cloudstack_cloudstack系统架构
- 6软件测试到底在学什么_软件测试能学到什么
- 72024年安卓最新面试 100% 完全掌握:重新认识 View 的绘制流程(1),字节跳动面试官级别_view的绘制流程
- 8“心脏滴血漏洞”测评经验分享_heartbleed 测试方式
- 9力扣(leetcode)第168题Excel表列名称(Python)_力扣168
- 10【Java】【JDK】使用JDK自带的mail API实现邮件发送_java 邮件接口
论文阅读-DiT:Scalable Diffusion Models with Transformers_dit 原始论文
赞
踩
近来有一些基于扩散模型+transformer的视觉大模型,比如Sora,本文讲的就是背后原理。
前言
本文使用具有Transformer主干的扩散模型,实现高质量图像,如下确实很难分辨:

提示:以下是本篇文章正文内容,下面案例可供参考
一、摘要
探索了一类基于Transformer架构基础上的扩散模型。用Transfomer架构替换之前的U-Net,通过增加transformer的深度/宽度或input tokens实现比之前所有扩散模型更优秀的表现。
二、介绍
Transformers推动了机器学习的复兴,过去NLP,CV以及其他许多领域都受影响很大。但图像级生成任务还没有太多应用。扩散模型是图像级生成方法的主流解决方案,不过都是基于U-Net的。
原始的扩散模型中U-Net主要由resnet组成,不过额外加了空间自注意力块。本文的目的是为以后的生成模型提供一个baseline,并且想证明U-Net的归纳偏置并不重要。同时使用Transformer作为架构,为跨领域任务开辟可能性(确实,比如现在的多模态任务等,都统一在Transformer上)。
此类扩散模型称为DIT,遵循ViT,与传统卷积网络相比,ViT在视觉识别方面效果更好。此外研究了网络复杂度与样本质量之间的规模化行为,发现网络复杂度(以Gflops度量)与样本质量(以FID度量)之间存在强相关性。
三、相关工作
Transformers:在NLP,CV,强化学习,元学习等都影响重大,主要是作为自回归模型。最后,在DDPM中使用Transformer,比如在DALL.E2中生成CLIP的图像嵌入,本文用transformer为骨干探究扩散模型。
DDPMs:扩散模型和基于分数的生成模型作为图像的生成模型多数情况已经超越GAN。采样技术的进步很大程度上推动了DDPMs的改进。22年的一个工作Scalable adaptive computation for iterative generation基于注意力机制,本文基于Transformer。
架构复杂性:图像生成领域通常通过参数量评价架构复杂性,其中Gflops被广泛使用。
四、Diffusion Transformers

预备工作
扩散公式:前向加噪声与反向去噪过程。
无分类器引导:条件扩散模型需要额外的信息,比如类别标签作为输入,使得生成的样本更加符合特定的条件或类别。输出的模型会根据此信息进行调整。
此外直接在高分辨率像素空间训练扩散模型可能行不通,使用潜在扩散模型(LDM)解决此问题,先学习编码器将图像压缩,再训练一个表示,最后采样并解码为图像。
DiT设计空间
DiT基于ViT,保留对于补丁序列的操作。
补丁化:DiT的输入是空间表示z(对于256 × 256 × 3图像,z的形状为32 × 32 × 4),DiT的第一层是补丁化。
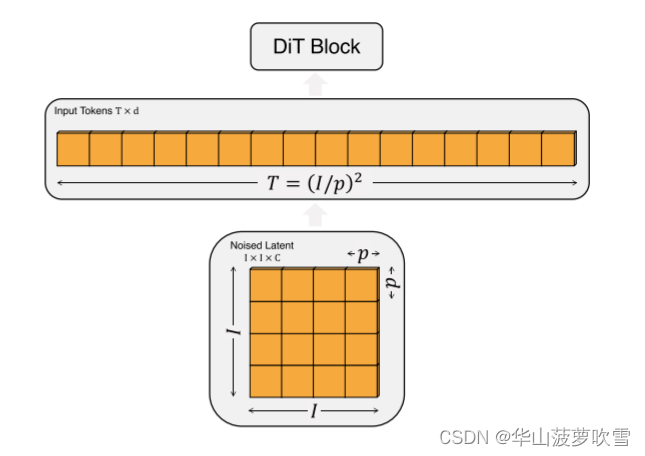 补丁化之后由一系列Transformer块处理。除了噪声图像,有时会有额外的如噪声步长以及类标签输入。有三种不同block,将t和c的嵌入与图像token分开,在多头自注意块之后包括额外的多头交叉注意层。最后使用的是adaLN-zero.
补丁化之后由一系列Transformer块处理。除了噪声图像,有时会有额外的如噪声步长以及类标签输入。有三种不同block,将t和c的嵌入与图像token分开,在多头自注意块之后包括额外的多头交叉注意层。最后使用的是adaLN-zero.

