总结:
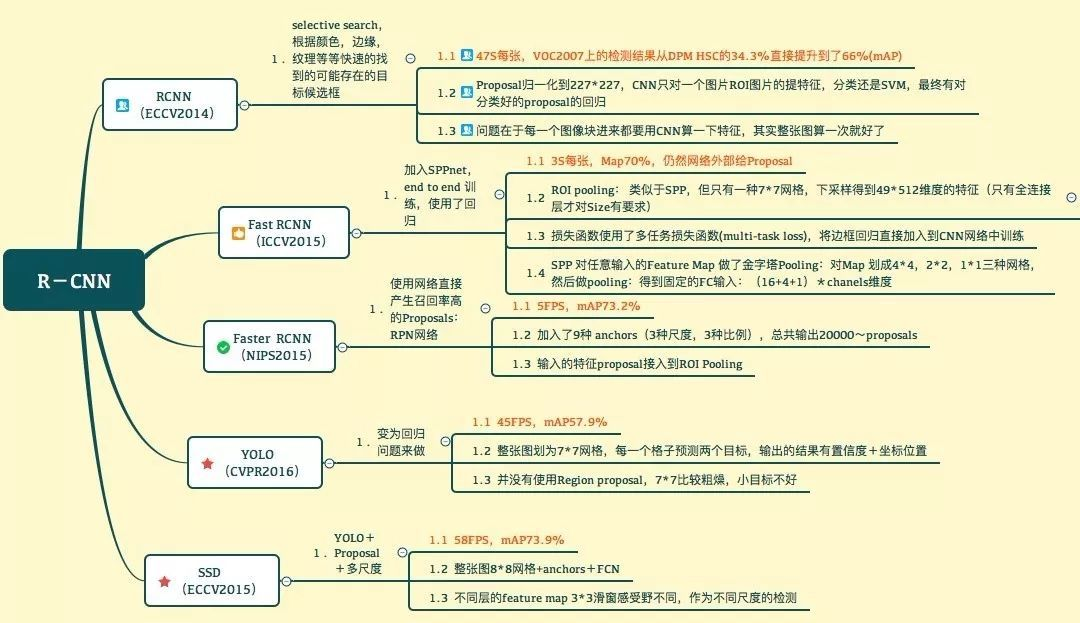
一、R-CNN
摘要:
在对象检测方面,其性能在前几年就达到了一个比较稳定的状态。性能最好的方法是一种复杂的整体系统,它将多个图片的低级特征通过上下文组合起来。
本文提出了一种简单、可扩展的算法,它在mAP上比VOC2012的最佳算法的结果高30%,达到53.3%。
这个方法包含两个方面:
1.利用大容量的CNN来提供自底向上的区域建议。
2.当带标签的训练数据不足时,使用附加任务提供监督的预训练,后面跟上特定区域的微调,这样产生一个显著的性能提升。
我们将R-CNN于OverFeat做了比较,我们发现在ILSVR2013的200分类任务中,R-CNN的性能高于OverFeat一大截。
参考:https://www.jianshu.com/p/5056e6143ed5
二、SPPnet
参考:https://blog.csdn.net/forever__1234/article/details/79910175
主要了解SPP和感受野的计算方法。
感受野:
1.padding不影响感受野,在计算时要忽略padding
2.从下向上计算感受野
3.pool层同样根据ksize和stride计算
卷积和pool计算输出尺度的公式:
W2 = (W1-F+2P)/S + 1
反过来:
W1 = (W2-1)*S+F-2P
忽略P:
W1=(W2-1)*S+F
用这个公式就可以从下往上计算每一层的感受野。
三、Fast R-CNN
参考:https://www.jianshu.com/p/fbbb21e1e390
相对于R-CNN,Fast R-CNN解决了三个问题。
1.测试速度慢
R-CNN中用CNN对每一个候选区域反复提取特征,而一张图片的2000个候选区域之间有大量重叠部分,这一设定造成特征提取操作浪费大量计算。
Fast R-CNN将整个图像归一化后直接送入CNN网络,卷积层不进行候选区的特征提取,而是在最后一个池化层加入候选区域坐标信息,进行特征提取的计算。
2.训练速度慢
3.训练所需空间大
R-CNN中目标分类与候选框的回归是独立的两个操作,并且需要大量特征作为训练样本。
Fast R-CNN将目标分类与候选框回归统一到CNN网络中来,不需要额外存储特征。
Fast R-CNN流程图:
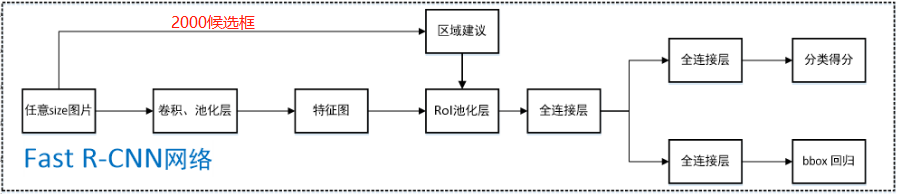
未改变的地方:
Fast同样适用了Selective Search来获取2000个候选框。
改变的地方(括号内为R-CNN的做法):
1.直接将图片归一化到规定尺寸,直接输入CNN。(2000个候选框图片resize再全部输入CNN)
2.在第五层池化层,将其替代为ROI池化层(假设适用VGG)。(普通池化层)
3.2000个候选框映射到经5个卷积层后得到的特征图上,在特征图上获取映射后的候选框。
4.对应候选区域经ROI池化层提取为固定长度特征向量,送入全连接层。(第五个普通池化层输出作为特征)
5.Fast在ROI层后使用全连接层同时对类别和BBox框的属性进行预测。(分别使用SVM预测类别,回归微调BBox)
RoI池化层:
RoI:Regions of Interest 感兴趣区域。
RoI池化层可以说是SPP(spatial pyramid pooling)的简化版,关于SPPnet的总结见另一篇文章 https://www.jianshu.com/p/90f9d41c6436。RoI池化层去掉了SPP的多尺度池化,直接用MxN的网格,将每个候选区域均匀分成M×N块,对每个块进行max pooling。从而将特征图上大小不一的候选区域转变为大小统一的特征向量,送入下一层。RoI:Regions of Interest 感兴趣区域
Fast R-CNN结合分类和回归:
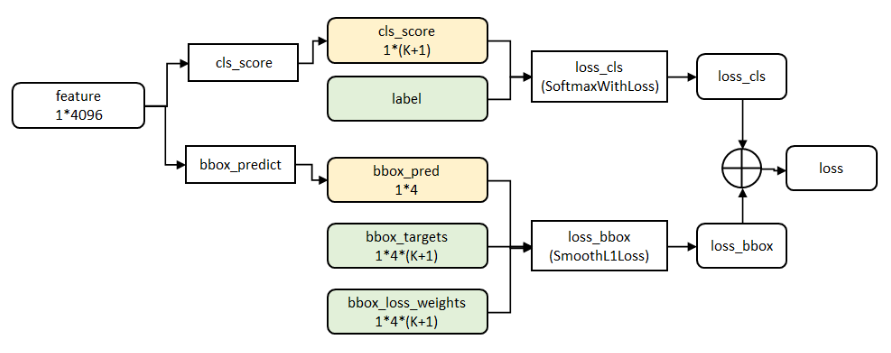
在R-CNN中的流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression进行候选框的微调;Fast R-CNN则是将候选框目标分类与bbox regression并列放入全连接层,形成一个multi-task模型。
cls_ score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。 bbox_predict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
Loss函数:
loss_cls层评估分类代价。由真实分类u对应的概率决定:
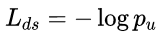
loss_bbox评估检测框定位代价。比较真实分类对应的预测参数tu和真实平移缩放参数为v的差别:
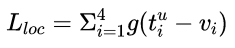
g为Smooth L1误差,对outlier不敏感:
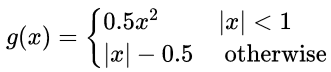
总代价为两者加权和,如果分类为背景则不考虑定位代价:
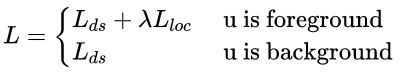
训练:
首先用ILSVRC 20XX数据集进行预训练,预训练是进行有监督的分类的训练。然后在PASCAL VOC样本上进行特定调优(fine tunning),调优的数据集中25%的正样本(与真实框IoU在0.5-1的候选框)、75%的负样本(与真实框IoU在0.1-0.5的候选框)。PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;正样本仅表示前景,负样本仅表示背景;回归操作仅针对正样本进行。
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征,文章中N=2,R=128。微调前,需要对有监督预训练后的模型进行3步转化:
-
RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
-
两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层;
-
上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;
测试:
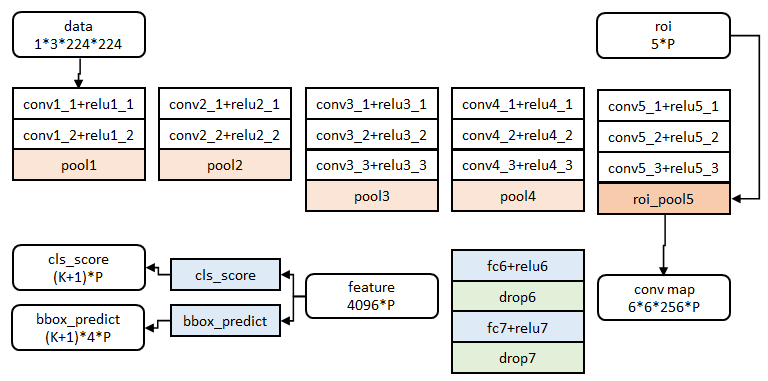
其他亮点:
1.SVD全连接层加速网络
图像分类任务中,用于卷积层计算的时间比用于全连接层计算的时间多,而在目标检测任务中,selective search算法提取的建议框比较多【约2k】,几乎有一半的前向计算时间被花费于全连接层,就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次【每个建议框都要计算】,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算,具体实现如下:
① 物体分类和窗口回归都是通过全连接层实现的,假设全连接层输入数据为x,输出数据为y,全连接层参数为W,尺寸为u×v,那么该层全连接计算为:
y=Wx(计算复杂度为u×v)
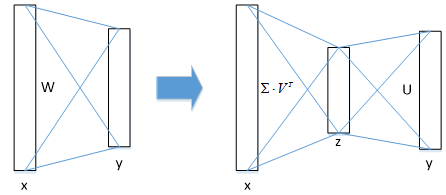
② 若将W进行SVD分解,并用前t个特征值近似代替,即:
W=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)T
那么原来的前向传播分解成两步:
y=Wx=U⋅(∑⋅VT)⋅x=U⋅z
计算复杂度为u×t+v×t,若t<min(u,v),则这种分解会大大减少计算量;
在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作。
2.图片中心化采样image-centric sampling
R-CNN和SPPnet中采用RoI-centric sampling:从所有图片的所有候选区域中均匀取样,这样每个SGD的mini-batch中包含了不同图像的样本,不同图像之间不能共享卷积计算和内存,运算开销大。
Fast R-CNN中采用image-centric sampling: mini-batch采用层次采样,即先对图像采样【N个】,再在采样到的图像中对候选区域采样【每个图像中采样R/N个,一个mini-batch共计R个候选区域样本】,同一图像的候选区域卷积共享计算和内存,降低了运算开销。
image-centric sampling方式采样的候选区域来自于同一图像,相互之间存在相关性,可能会减慢训练收敛的速度,但是作者在实际实验中并没有出现这样的担忧,反而使用N=2,R=128的image-centric sampling方式比R-CNN收敛更快。
这里解释一下为什么SPPnet不能更新spatial pyramid pooling层前面的卷积层,而只能更新后面的全连接层? 一种说法解释卷积特征是线下计算的,从而无法在微调阶段反向传播误差;另一种解释是,反向传播需要计算每一个RoI感受野的卷积层梯度,通常所有RoI会覆盖整个图像,如果用RoI-centric sampling方式会由于计算too much整幅图像梯度而变得又慢又耗内存。
四、Faster R-CNN
参考:
https://blog.csdn.net/liuxiaoheng1992/article/details/81843363
https://blog.csdn.net/qq_36269513/article/details/80421990
https://www.cnblogs.com/zyly/p/9247863.html
Faster R-CNN是将目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
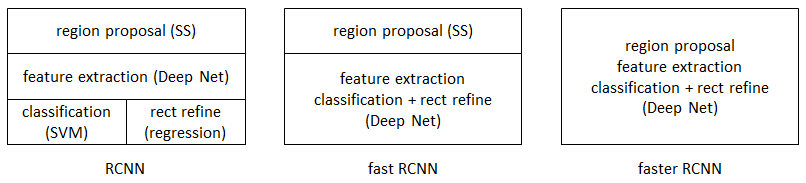
Faster R-CNN可以简单地看做“区域生成网络(RPN)+Fast RCNN“的系统,用区域生成网络代替Fast R-CNN中的Selective Search方法,网络结构如下图。
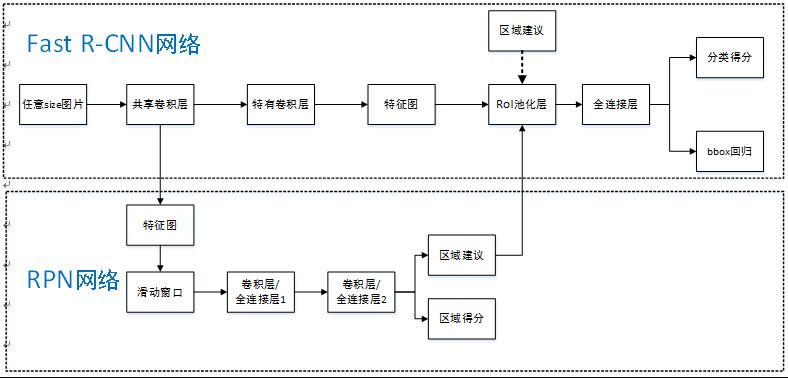
步骤如下:
- 首先向CNN网络【ZF或VGG-16】输入任意大小图片
-
经过CNN网络前向传播至最后共享的卷积层,一方面得到供RPN网络输入的特征图,另一方面继续前向传播至特有卷积层,产生更高维特征图;
- 供RPN网络输入的特征图经过RPN网络得到区域建议和区域得分,并对区域得分采用非极大值抑制【阈值为0.7】,输出其Top-N【文中为300】得分的区域建议给RoI池化层;
- 第2步得到的高维特征图和第3步输出的区域建议同时输入RoI池化层,提取对应区域建议的特征;
- 第4步得到的区域建议特征通过全连接层后,输出该区域的分类得分以及回归后的bounding-box。
RPN详解:
基本设想是:在提取好的特征图上,对所有可能的候选框进行判别。由于后续还有位置精修步骤,所以候选框实际比较稀疏。
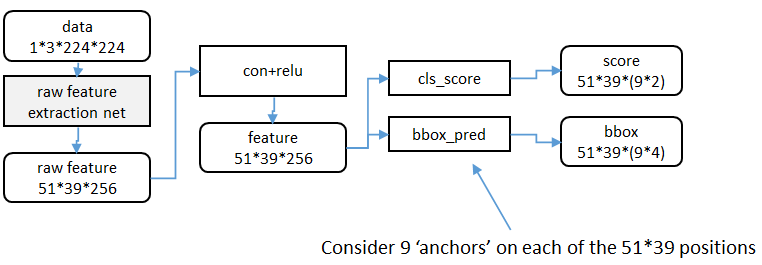
1、特征提取
RPN还是需要使用一个CNN网络对原始图片提取特征。为了方便读者理解,不妨设这个前置的CNN提取的特征为
为了方便叙述,先来定义一个“位置”的概念:对于一个
2、候选区域(anchor)
特征可以看做一个尺度
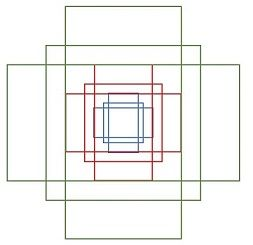
对于这
- 设
- 第一个卷积层将特征图每个滑窗位置编码成一个特征向量,第二个卷积层对应每个滑窗位置输出
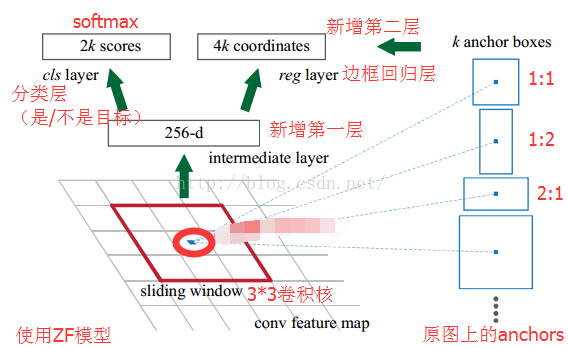
3.SOFTMAX的两支
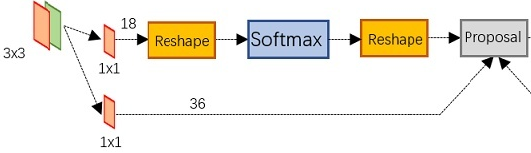
计算每个像素256-d的9个尺度下的值,得到9个anchor,我们给每个anchor分配一个二进制的标签(前景背景)。我们分配正标签前景给两类anchor:1)与某个ground truth(GT)包围盒有最高的IoU重叠的anchor(也许不到0.7),2)与任意GT包围盒有大于0.7的IoU交叠的anchor。注意到一个GT包围盒可能分配正标签给多个anchor。我们分配负标签(背景)给与所有GT包围盒的IoU比率都低于0.3的anchor。非正非负的anchor对训练目标没有任何作用,由此输出维度为(2*9)18,一共18维。
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
4.bounding box regression
前已经计算出foreground anchors,使用bounding box regression回归得到预设anchor-box到ground-truth-box之间的变换参数,即平移(dx和dy)和伸缩参数(dw和dh),由此得到初步确定proposal。
如下图所示绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。

对于窗口一般使用四维向量(x, y, w, h)表示,分别表示窗口的中心点坐标和宽高。对于下图,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G',即:给定A=(Ax, Ay, Aw, Ah),寻找一种映射f,使得f(Ax, Ay, Aw, Ah)=(G'x, G'y, G'w, G'h),其中(G'x, G'y, G'w, G'h)≈(Gx, Gy, Gw, Gh)。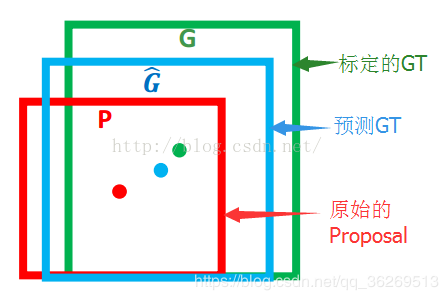
那么经过何种变换才能从图6中的A变为G'呢? 比较简单的思路就是:
1. 先做平移![]()
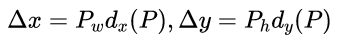
这就是R-CNN论文中的:
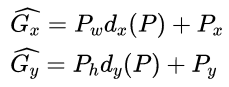
2. 再做缩放![]()
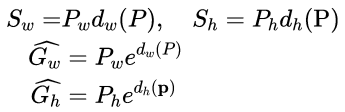
观察上面4个公式发现,需要学习的是dx(A),dy(A),dw(A),dh(A)这四个变换。当输入的anchor与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。对应于Faster RCNN原文,平移量(tx, ty)与尺度因子(tw, th)如下:
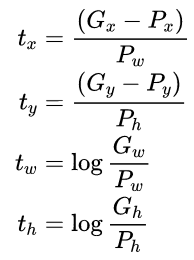
接下来的问题就是如何通过线性回归获得dx(A),dy(A),dw(A),dh(A)了。线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值Y(即GT)非常接近,即Y=WX。对于该问题,输入X是一张经过卷积获得的feature map,定义为Φ;同时还有训练传入的GT,即(tx, ty, tw, th)。输出是dx(A),dy(A),dw(A),dh(A)四个变换。那么目标函数可以表示为:
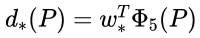
其中Φ(A)是对应anchor的feature map组成的特征向量,w是需要学习的参数,d(A)是得到的预测值(*表示 x,y,w,h,也就是每一个变换对应一个上述目标函数)。为了让预测值(tx, ty, tw, th)与真实值最小,得到损失函数:
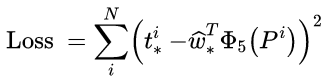
函数优化目标为:
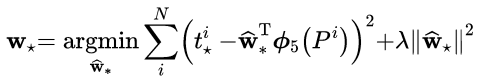
5.将预proposal利用feat_stride和im_info将anchors映射回原图,判断预proposal是否大范围超过边界,剔除严重超出边界的。
按照softmax score进行从大到小排序,提取前2000个预proposal,对这个2000个进行NMS(非极大值抑制),将得到的再次进行排序,输出300个proposal。
NMS(非极大值抑制)
由于锚点经常重叠,因此建议最终也会在同一个目标上重叠。为了解决重复建议的问题,我们使用一个简单的算法,称为非极大抑制(NMS)。NMS 获取按照分数排序的建议列表并对已排序的列表进行迭代,丢弃那些 IoU 值大于某个预定义阈值的建议,并提出一个具有更高分数的建议。总之,抑制的过程是一个迭代-遍历-消除的过程。如下图所示:
- 将所有候选框的得分进行排序,选中最高分及其所对应的BB;
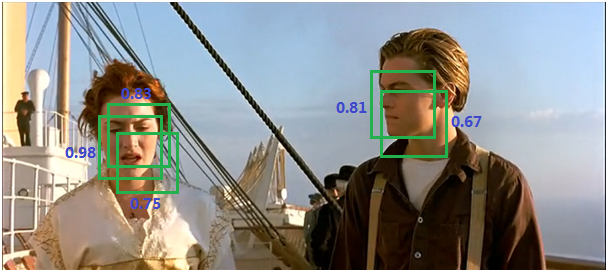
- 遍历其余的框,如果它和当前最高得分框的重叠面积大于一定的阈值,我们将其删除。
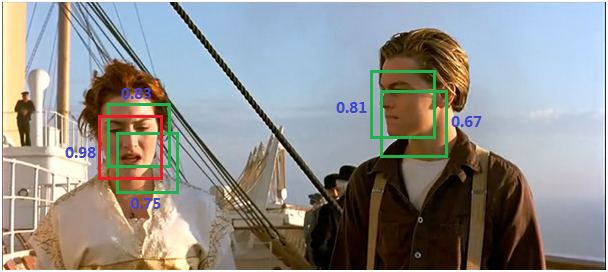
- 从没有处理的框中继续选择一个得分最高的,重复上述过程。