- 1第5章 软件质量标准概述
- 2Python中的split()函数_python split()函数
- 3深度强化学习DDPG实现路径跟踪(局部规划器)方法讲解与PyTorch代码实现_ddpg路径规划
- 4【Android面试八股文】Fragment的add和replace的区别,分别对Fragment的生命周期有什么影响?
- 5什么是EM算法_em算法是指什么
- 6redis连接Unable to connect to Redis_noauth hello must be called with the client alread
- 7ROS2自学笔记:话题_ros2 subscription
- 8python学习(第七章)_python语言程序设计第7章答案
- 9AIGC大模型必备知识——LLM ,你知道它是如何训练的吗?小白必读深度好文_llm 训练
- 10Anroid Studio工具UI设计默认切换焦点顺序原则_改变focus 顺序
hive 常用函数总结_hive coalesce 最多几个
赞
踩
1.各种数据类型的基础知识点
数值类型
int代表整数(hive常用bigint);float代表小数,double代表双精度,比float精度更高,小数位更多。下面括号中M代表总位数,D代表小数位数 整数
-
int
有符号(signed)的和无符号(unsigned)的。有符号大小-2147483648~2147483647,
无符号大0~4294967295。 宽度最多为11个数字 int(11)
-
tinyint
有符号的和无符号的。有符号大小 -128~127,无符号大小为0~255。宽度最多为4个数字 tinyint(4)
-
smallint
有符号的和无符号的。有符号大小-32768~32767,无符号大小为0~65535。宽度最多为6个数字 smallint 6)
-
mediumint
有符号的和无符号的。有符号大小-8388608~8388607,无符号大小为0~16777215。
宽度最多为9个数字-mediumint(9)
-
bigint(常用)
有符号的和无符号的。宽度最多为20个数字 bigint(20)
小数
-
float
代表小数,默认为(10,2)
-
double(常用)
代表双精度,默认为(16,4)
-
decimal(针对高精度)
比float精度更高,小数位更多,默认为(16,4)
-
日期类型
-
date
YYYYY-MM-DD格式,例如:1973-12-30
-
datetime
YYYY-MM-DD HH:MM:SS格式,例如:1973-12-30 15:30:00
-
timestamp
称为时问戳,1973年12月30日下午15:30,则在数据库中存储为:19731230153000
-
time
以HH:MM:SS格式
-
year
以2位或4位格式存储年份值。如果是2位,1970~2069:如果是4位,1901~2155。默认长度为4
-
字符串类型
-
char
固定长度字符串(可以是汉字或字母),长度为1-255。 如果内容小于指定长度,右边填充空格。如果不指定长度,默认为1。
-
varchar / varchar2
可变长度字符串,长度为1-255。定义该类型时必须指定长度
-
blob / text
最大长度65535。存储二进制大数据,如图片。不能指定长度。两者区别:BLOB 大小写敏感
-
tinyblob / tinytext
最大长度255。不能指定长度
-
mediumblob / mediumtext
最大长度16777215 字符
-
longblob / longtext
最大长度4294967295 字符
-
string(常用
长度大概2w长度
补充


2.常用函数(hive)
1.数值转换类型函数
1.取整
语法:round(double e)
返回值:BIGINT
说明:返回值double类型的数值整数部分(遵循四舍五入)
举例:hive > select round(3.1415926) 返回值为3
2.精度取整函数
语法:round(double e,int d)
返回值:DOUBLE
说明:返回指定精度d的double类型
举例:hive > select round(3.1415926,4) 返回值为3.1416
3.floor(向下取整函数)
语法:floor(double e)
返回值:BIGINT
说明:返回等于或者小于该double变量的最大的整数
举例:hive > select floor(3.1415926) 返回值为3
4.ceil(向上取整函数)
语法:ceil(double e)
返回值:BIGINT
说明:返回值等于或者大于该double变量的最小整数
举例:hive > select ceil(3.1415926) 返回值为4
5.abs(绝对值函数)
语法:abs(double a) abs(int a)
返回值:double int
说明:返回数值a的绝对值
举例:hive > select abs(-3.9) 返回值为3.9 hive > select abs(10.9) 返回值为10.9
6.rand(取随机数函数)
语法:rand() rand(int seed)
返回值:double
说明:返回一个0 到 1 范围内的随机数。 如果指定种子seed,则会等到一个稳定的随机数序列
举例:hive > select rand() 返回值 0.6035916654143063 每次执行都不同
hive >select (100) 返回值 0.7220096548596434
2.日期函数
-
from_unixtime(时间戳转日期函数)
-
语法:from_unixtime(bigint unixtime,string format)
-
返回值:string
-
说明:转化UNIX时间戳(从1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式
-
举例:hive >select from_unixtime(122308943,'yyyyMMdd') 返回值:19740312
-
-
unix_timestamp(日期转时间戳函数)
-
语法:unix_timestamp(string data) / unix_timestamp(string data, string pattern)
-
返回值:bigint
-
说明:转化格式为"yyyy-MM-dd HH:mm:ss"的日期到UNIX时间戳,如果转换失败则返回0
-
举例:hive >select unix_timestamp('2023-08-28 10:53:03') ; 返回值:1693219983
或者 hive >select unix_timestamp('2023-08-28 10:53:03','yyyy-MM-dd HH:mm:ss') ;
返回值1693219983 注意 'yyyy-MM-dd HH:mm:ss' 需要单引号,且格式和前面对应
-
-
to_date(日期时间转日期函数)
-
语法:to_date(string timestamp)
-
返回值:string
-
说明:返回日期时间字段中的日期部分
-
举例:hive >select to_date('2023-08-28 10:53:03'); 返回值:2023-08-28
-
-
year(日期转年函数)
-
语法:year(string date)
-
返回值:int
-
说明:返回日期中的年
-
举例:hive >select year('2023-08-28 10:53:03'); 返回值:2023
select year('2023-08-28'); 返回值:2023
-
-
month(日期转月函数)
-
语法:month(string date)
-
返回值:int
-
说明:返回日期中的月份
-
举例:hive >select month('2023-08-28 10:53:03'); 返回值:8
select year('2023-08-28'); 返回值:8
-
-
day(日期转天函数)
-
语法:day(string date)
-
返回值:int
-
说明:返回日期中天
-
举例:hive >select day('2023-08-28 10:53:03'); 返回值:28
select day('2023-08-28'); 返回值:28
-
-
hour(日期转小时函数)
-
语法:hour(string date)
-
返回值:int
-
说明:返回日期中的小时
-
举例:hive >select hour('2023-08-28 10:53:03'); 返回值:10
-
-
minute(日期转分钟函数)
-
语法:minute(string date)
-
返回值:int
-
说明:返回日期中的分钟
-
举例:hive >select minute('2023-08-28 10:53:03'); 返回值:53
-
-
second(日期转秒函数)
-
语法:second(string date)
-
返回值:int
-
说明:返回日期中的秒
-
举例:hive >select second('2023-08-28 10:53:03'); 返回值:3
-
-
datediff(日期比较函数)
-
语法:datediff(string enddate,string startdate)
-
返回值:int
-
说明:返回结束日期减去开始日期的天数
-
举例:hive >select datediff('2023-08-28','2023-08-20'); 返回值:8
-
-
date_add(日期增加函数)
-
语法:date_add(string startdate,string int day)
-
返回值:string
-
说明:返回开始日期startdate增加days后的日期
-
举例:hive >select date_add('2023-08-28',10); 返回值:2023-09-07
-
-
date_sub(日期减少函数)
-
语法:date_sub(string startdate,string int day)
-
返回值:string
-
说明:返回开始日期startdate减少days后的日期
-
举例:hive >select date_sub('2023-08-28',10); 返回值:2023-08-18
months_between(月份比较函数)
-
语法:months_between(string enddate,string startdate)
-
返回值:double
-
说明:返回结束日期减去开始日期的差值
-
举例:hive >select months_between('2023-08-28','2023-07-28'); 返回值:1.0
-
3.条件函数
-
If
-
语法:fi( boolean testCondition,T valueTrue,T valueFalseNull )
-
返回值:T
-
说明:当条件testCondition为TRUE时,返回valueTrue,否则返回 valueFalseNull
-
举例:hive >select if(1=2,100,200); 返回值:200
hive >select if(1=1,100,200); 返回值:100
-
-
coalesce/nvl(非空函数)
-
语法:fi(T v1, T v2,...)
-
返回值:T
-
说明:返回参数中第一个非空值;如果所有的值都为NULL,那么返回NULL
-
举例:hive >select coalesce(null,'100','200'); 返回值:100
-
俩者区别:
-
nvl函数语法: nvl(默认值,表达式); 如果 默认值 不为空返回默认值,默认值为空
返回表达式,如果俩者都为空 返回空
-- 处理参数个数有限,只能传俩个参数。
使用时注意: 默认值,表达式的值数据类型没有要求,可相同可不同。
-
coalesce函数语法: coalesce(表达式1,表达式2 ..... 表达式n); coalesce函数的
返回结果是第一个非空表达式,如果全是空,则返回空。
-- 处理参数个数没有限制。
使用时注意:对处理参数的数据类型有严格的要求,所有的表达式值是同一类型
(转换为同一类型即可)。
-
-
-
case
-
语法:CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
-
返回值:T
-
说明:如果a 等于b ,那么返回c;如果a 等于 d,那么返回 e ;否则返回 f
-
举例:select case 100 when 500 then 'tom' when 100 then 'smy' else 'tim' end; 返回值 : smy
-
-
cast(强制类型转换函数)
-
语法:CAST (expression AS data_type)
-
返回值:AS 后面的类型
-
说明:expression:任何有效的SQServer表达式。 AS:用于分隔两个参数,在AS之前的是要处理的数据,在AS之后是要转换的数据类型。 data_type:目标系统所提供的数据类型,包括bigint和sql_variant,不能使用用户定义的数据类型。
-
举例:select cast('9.5' as decimal); 返回值 : 10 (四舍五入)
select cast('9.5' as decimal(10,2)); 返回值 : 9.50
-
4.字符串函数
-
Length(字符串长度函数)
-
语法:length(string A)
-
-
返回值:int
说明:返回字符串A的长度
举例:hive >select length('abcdefg') ; 返回值:7
reverse(字符串反转函数)
-
语法:reverse(string A)
-
返回值:string
-
说明:返回字符串A的反转结果
-
举例:hive > select reverse('abcdefg') ; 返回值:gfedcba
concat(字符串连接函数)
-
语法:concat(string A,string B ...)
-
返回值:string
-
说明:返回输入字符串连接后的结果,支持任意个输入字符串
-
举例:hive > select concat('abc','de','fg') ; 返回值:abcdefg
concat_ws(带分隔符字符串连接函数)
-
语法:concat_ws(string SEP,string A, string B ...)
-
返回值:string
-
说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
-
举例:hive > select concat_ws('-','abc','adf','qwe'); 返回值:abc-adf-qwe
substr/substring(字符串截取函数)
-
语法:substr(string A,int start),substring(string A,int start)
-
说明: 返回字符串A从start位置到结尾的字符串
-
举例:select substr('abcdefg',3); 返回值:cdefg
-
语法:substr(string A,int start,int end),substring(string A,int start,int end) 前开后闭[start,end)
-
说明:返回字符串A从start位置到end的字符串,前开后闭[start,end)
-
举例:hive > select substr('abcdefg',0,2) 返回值:ab
upper/ucase(字符串转大写函数)
-
语法:upper(string A) ucase(string A)
-
返回值:string
-
说明:返回字符串A的大写格式
-
举例:hive > select upper('abCdeF'); select ucase('abCdeF'); 返回值:ABCDEF
lower/lcase(字符串转小写函数)
-
语法:lower(string A) lcase(string A)
-
返回值:string
-
说明:返回字符串A的小写格式
-
举例:hive > select lower('abCdeF'); select lcase('abCdeF'); 返回值:abcdef
trim(去空格函数)
-
语法:trim(string A)
-
返回值:string
-
说明:去除字符串俩边的空格
-
举例:hive > select trim(' a '); 返回值:a
regexp_replace(正则表达式替换函数)
-
语法:regexp_replace(string A,string B,string C)
-
返回值:string
-
说明:将字符串A中符合java正则表达式B部分替换为C。
注意:有些情况下要使用转义字符,类似orcale中的regexp_replace函数
-
举例:hive > select regexp_replace('abcdefg','bcd',''); 返回值:aefg
-
regexp_extract(正则表达式解析函数)
-
语法:regexp_extract(string subject,string pattern,int index)
-
返回值:string
-
说明:将字符串subject 按照pattern正则表达式的规则拆分,返回index指定的字符。
-
-
get_json_object(json解析函数)
-
语法:get_json_object(string json_string,string path)
-
返回值:string
-
说明:解析json的字符串json_string,返回path 指定的内容。如果输入的json字符串无效,
那么返回null。
-
举例:hive > select get_json_object("json串","$.串主键"); 返回 主键所对应的值
-
-
split(切割字符串函数)
-
语法:split(string str,string pat)
-
返回值:array
-
说明:按照pat字符串分割str,会返回分割后的字符串数组
-
举例:hive > select split("abtcdtef") 返回值:["ab","cd","ef"]
-
-
explode(炸裂函数)
-
语法:lateral view explode(split(a,","))a1 as a2
-
返回值:string
-
说明:按照pat字符串分割str,并将数组中内容炸裂成多行字符串
-
举例:
-
-
posexplode(炸裂函数)
5.聚合函数
count(个数统计函数)
-
函数里面可以写去重
-
语法: select count(*) 或者 select count(distinct col)
sum(求和函数)
avg(平均值统计函数函数)
min(最小值统计函数)
max(最大值统计函数)
collect_list(将字段多个内容合并到一条 不去重)
-
语法: collect_list()
-
返回值:array
-
说明:体现在hive中就是把一个key的多个信息收集起来合成一个,不去重
-
举例: select collect_list(test_cube.oid) from test_cube; 返回值: [1,2,3,4,5,6]
collect_set(将字段多个内容合并到一条 去重)
-
语法: collect_set()
-
返回值:array
-
说明:体现在hive中就是把一个key的多个信息收集起来合成一个,去重
-
举例: select collect_set(test_cube.money) from test_cube; 返回值:[1000.0,2000.0,3000.0]
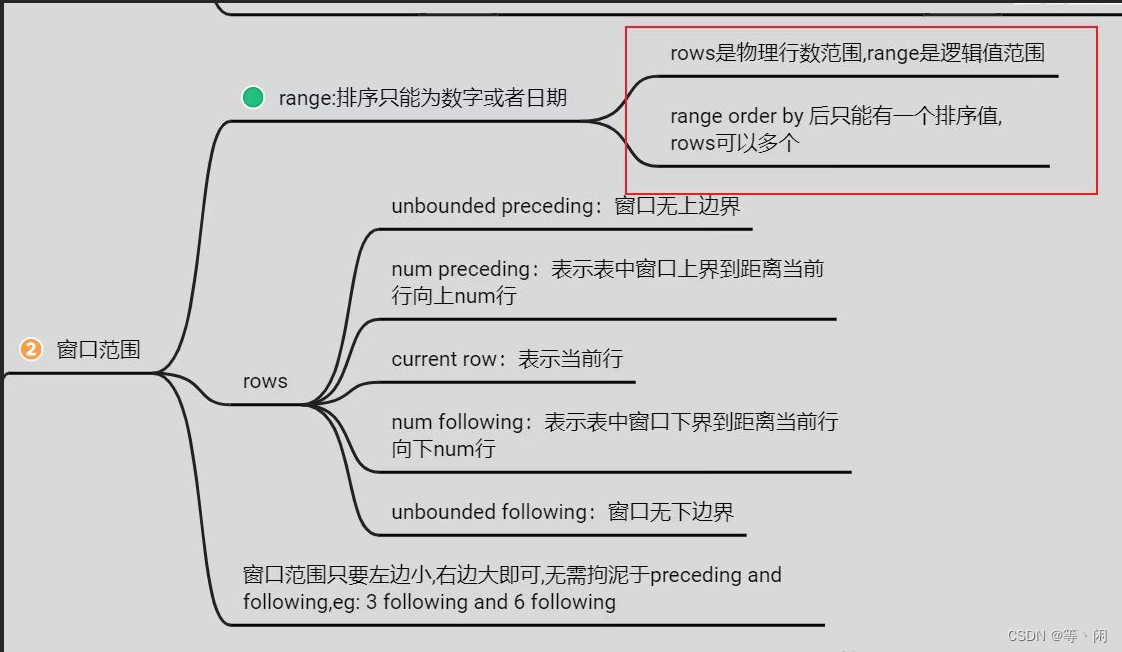
6.开窗函数
聚合开窗
-
承接上述聚合函数包括(count()、sum()、max()、min()、avg())
-
语法:函数() over(partition by col order by col rows/range between)
窗口函数
-
lag(向前取n 行)
-
lag(col,n,val) over (partition by col order by col),查询当前行前边第n行数据,如果没有为null
-
-
lead(向后取n 行)
-
lead(col,n,val) over (partition by col order by col),查询当前行后边第n行数据,如果没有为null
-
-
first_value(查看窗口第一条数据)
-
first_value(col,true/false) over (partition by col order by col),查询当前窗口第一条数据,
第二个参数为true,跳过空值
-
-
last_value(查看窗口最后一条数据)
-
last_value(col,true/false) over (partition by col order by col),查询当前窗口最后一条数据,
第二个参数为true,跳过空值
-
排名开窗
-
rank
-
rank() over(partition by col order by col),排名方式 例如 score 为100 100 90 ,排名分别如下
1(100) 1(100) 3(90)
-
-
row_number
-
row_number() over(partition by col order by col),排名方式 例如 score 为100 100 90 ,
排名分别如下 1(100) 2(100) 3(90)
-
-
dense_rank
-
dense_rank() over(partition by col order by col),排名方式 例如 score 为100 100 90 ,
排名分别如下 1(100) 1(100) 2(90)
-
窗口范围