
- 1centos7 通过端口转发实现代理中转_端口 中转
- 2PG与MySQL优劣势对比_mysql和pg
- 3重磅!金融监管总局出台《银行保险机构数据安全管理办法》!金融行业安全迎来新变革?_保险行业数据安全监管要求
- 4JDK8新特性-Lambda表达式_lamda是jdk几
- 5大数据的开源工具与平台_大数据平台和工具
- 6全球开源新王Qwen2-72B诞生,碾压Llama3-70B击败国产闭源模型!AI圈大佬转疯了 | 最新快讯_安筱鹏
- 7观点|通过短生命周期和最小权限原则保护软件供应链安全
- 8Postman进行Soap webservice接口测试_postman soap
- 9MongoDB 与 MySQL 的插入、查询性能测试_同等配置下mongodb的插入速度要比mysql高吗?高百分之多少
- 10Github上都在疯找的京东内部“JVM调优笔记”终于来了_jvm调优 guthub
一句话说明EM算法思想_em思想
赞
踩
一 、引入
1 . 概率模型参数估计
1.在实际概率问题中,若只有观测变量,那么只需要给定参数变量,应用极大似然估计法 就可以得到要估计的参数
2.当模型中含有隐变量的时候,即概率模型参数中有可观测变量和隐藏变量的时候,需要用到EM算法(EM算法是专门处理含有隐变量的概率模型参数的极大似然估计)
2. 一句话EM算法思想
1.若模型参数 Θ 已知,则可以根据训练数据推断出最优隐变量 Z 的值(E步 即:期望);反之若 Z 的值已知,则可以极大似然估计得到参数 Θ 。
- (拓展): 若不是直接求隐变量 Z 的期望,就是求隐变量的概率分布 P( Z | X , Θ )
二 、 从极大似然到EM 之 极大似然
1. 基本思想
事件已经发生意味着存在即合理,找到使得事件联合概率分布值最大的参数(事件的发生等价于时间联合概率,最大化联合概率分布)
2. 实例
1.假设我们需要调查我们学校的男生身高的分布情况,通过抽样得到的100个男生的身高。假设他们的身高是服从高斯分布的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作 θ = [ u , ∂ 2 ] θ=[u, ∂2] θ=[u,∂2]
- 用数学的语言来说就是:在学校中按照概率密度p(x|θ)抽取100了个(身高),样本集是X={x1,x2,…,xN},概率密度函数:高斯分布N(u,∂2),其中xi表示抽到的第i个人的身高,这里N就是100,表示抽到的样本个数。
- 似然函数(每一个男生的身高都是独立的,所以事件的联合概率分布就是每一位男生的概率密度乘积):
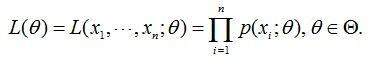
4.求解参数 u 和 ∂2
注意: 经常在遇到似然函数连乘形式,为方便计算取 对数似然
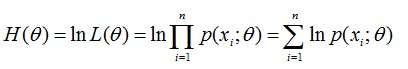
然后求导,然后让导数为0,解方程得到的值就是模型参数
三、 从极大似然到EM 之 EM算法
1. 基本思想(重要的事情最写一次)
1.若模型参数 Θ 已知,则可以根据训练数据推断出最优隐变量 Z 的值(E步 即:期望);反之若 Z 的值已知,则可以极大似然估计得到参数 Θ 。
- ** 拓展** : 若不是直接求隐变量 Z 的期望,就是求隐变量的概率分布 P( Z | X , Θ )
- 所以我们在求含有隐变量的模型参数时,不是不能用极大似然,而是由于极大似然的加入让我们的求解更加复杂,但是当知道隐变量的分布时,就能用极大似然来很好的求解。所以**E步 **:就是估计隐变量(在给定初始的 Θ 的值情况下)的概率分布,M步:就是在知道了隐变量的分布后,顺利的利用极大似然估计求取 Θ 。如此循环直到收敛
2. 实例
- 还是上面极大似然估计实例的拓展
这回我们随机抽取学校中男生100个,女生100个,得到他们的身高数据,放在一个样本集,样本集是X={x1,x2,…,xN} N = 200 没有男女性别信息,需要估计男女的身高概率分布 - 思路:
- 对于每一个样本或者你抽取到的人,就有两个东西需要猜测或者估计的了,一是这个人是男的还是女的?二是男生和女生对应的身高的高斯分布的参数是多少?
- 当知道了哪些人属于同一个高斯分布,才能够对这个分布的参数作出靠谱的预测,例如上面最大似然所说的,对于混合的数据集就没法估计这两个分布的参数。反过来,只有当我们对这两个分布的参数作出了准确的估计的时候,才能知道到底哪些人属于第一个分布,哪些人属于第二个分布(这里是EM算法思想的最通俗的解释了)。
- 上面两个想法与基本思想吻合
- 基本步骤
- 先随便给一个男生正态分布的参数,初始值的设置;然后计算出每个人更可能属于第一个还是第二个正态分布中的(E步)。
- 有了每个人的分类(基于此时的初始值)根据最大似然重新估计男生分布的参数,女生的分布同理。(M步)。有了新参数再来调整E步……循环直到收敛
- 这个思路也是GMM的基本思路
3. EM算法的数学推导
- 1)《统计学习方法》思路算法总览:


解析:可以看到Q函数中也提到了
P
(
Z
∣
Y
,
Θ
)
P(Z | Y , Θ)
P(Z∣Y,Θ)是给定观测数据 Y 和当前参数 Θ 下隐变量数据 Z 的条件概率分布,但是只是对 单样本计算,理解较为困难,E步感觉没有做什么事情
- 2) 基于实例的EM算法(笔者发现了一篇总结的很好的PDF,如参考4)学习后总结如下:
实例 一、三硬币模型
假设有3枚硬币,分别记作A、 B、 C,且这些硬币正面出现讹夺概率分别是 π 、 p 、 q π 、p、q π、p、q 进行如下抛硬币实验,先抛硬币A , 根据抛的结果先出硬币 B和 C 如,果A 为正面选B,如果A为反面选硬币C 。然后抛选中的硬币,出现正面记 1 ,反面记作 0.实验重复n(n = 10)次,其结果为{1, 1, 1, 1, 1, 0, 0, 0, 0, 0 },试估计3硬币模型的参数{} π 、 p 、 q π 、p、q π、p、q}
设X= {x1 , x2, …xm}是包含m个独立样本的的样本集,且 X 是服从参数 Θx 的概率分布
P
(
X
;
Θ
x
)
P(X ; Θx)
P(X;Θx),在样本集X 中的每一个样本xi 都对应着一个隐含样本 Zj ,有Z = {z1 ,z2 , z3, …zn },且Z 是服从参数为 Θz 的概率分布
P
(
Z
;
Θ
z
)
P(Z;Θz )
P(Z;Θz)
要找到一组参数Θ ,使得观察到的样本集 X 出现的概率最大,即
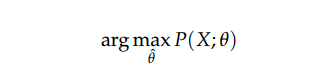
讲因变量显示出来为:(其中对 j 的累加是对隐变量求和得到关于X 的边缘概率)
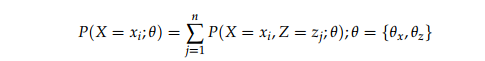
样本集出现的最大似然:
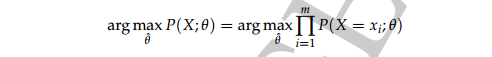
同样显示出隐变量:
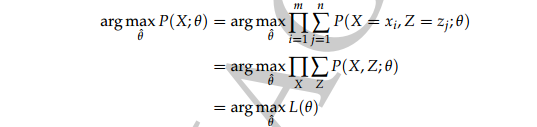
此时的似然函数:
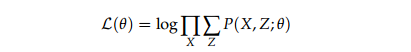
由于隐变量的存在我们不能直接采用极大似然估计求解(继续往下)
变换似然函数:
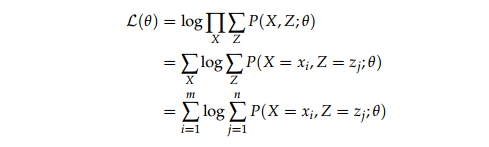
不能直接导数等于 0 ,我们求其近似解(通过寻找似然函数
L
(
Θ
)
L(Θ)
L(Θ)的下界,求下界的极大值来逼近
L
(
Θ
)
L(Θ)
L(Θ)的极大值):

可以看到
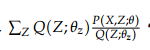
是
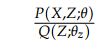
的期望
根据琴森不等式有:
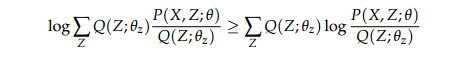
当让L(Θ)与下界相等时,任何使下界增大的Θ也可以使似然函数增大,琴森不等式中等号成立的条件是随机变量都相等即随机变量变为“常量”,下界函数的关键步骤是求
Q
(
Z
;
θ
z
)
Q(Z;θz)
Q(Z;θz),根据等号成立的条件
Q
(
Z
;
θ
z
)
Q(Z;θz)
Q(Z;θz)为在参数 θ 下,给定 X 后,Z的后验分布。
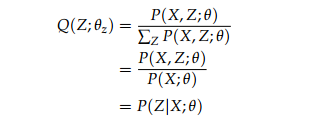
因此:E步 就是后验概率
Q
(
Z
;
θ
z
)
Q(Z;θz)
Q(Z;θz)
M步:就是已知后验分布
Q
(
Z
;
θ
z
)
Q(Z;θz)
Q(Z;θz)的
L
(
θ
)
L(θ)
L(θ)的极大似然
算法中给定初始参数 θ ,循环E步 和 M 步 直到收敛
算法的整体效果:通过优化对数似然当前的下界,来达到优化原函数的目的

四、 参考
- 《机器学习》. 周志华
- 《统计学习方法》. 李航
- https://blog.csdn.net/zouxy09/article/details/8537620 . zouxy09
- EM算法详解 by. 瞭望清晨

