
热门标签
热门文章
- 1AR增强现实汽车装配仿真培训系统开发降低投入费用
- 2Parallels DeskTop 19 新功能介绍及PD19激活安装图文教程
- 3Gson的用法详解_java gson
- 4前沿重器[34] | Prompt设计——LLMs落地的版本答案
- 5java面试_java面试配置相关
- 6JVM常用概念之安全点_jvm安全点
- 7SpringBoot 集成WebSocket_springboot集成websocket
- 8AI绘画安装krita+comfyUI过程总因为缺ControlNet 问题报错,而无法使用插件?_aux集成预处理器报错
- 91.Echarts的简单使用_echarts连接数据库
- 10软件设计师-23年上半年-上午答案
当前位置: article > 正文
大模型常用微调数据集_大模型微调数据集
作者:喵喵爱编程 | 2024-07-15 12:55:04
赞
踩
大模型微调数据集
为了增强模型的任务解决能力,大语言模型在预训练之后需要进行适应性微调,通常涉及两个主要步骤,即指令微调(有监督微调)和对齐微调。
指令微调数据集
在预训练之后,指令微调(也称为有监督微调)是增强或激活大语言模型特定能力的重要方法之一(例如指令遵循能力)。本小节将介绍几个常用的指令微调数据集,并根据格式化指令实例的构建方法将它们分为三种主要类型,即自然语言处理任务数据集、日常对话数据集和合成数据集。
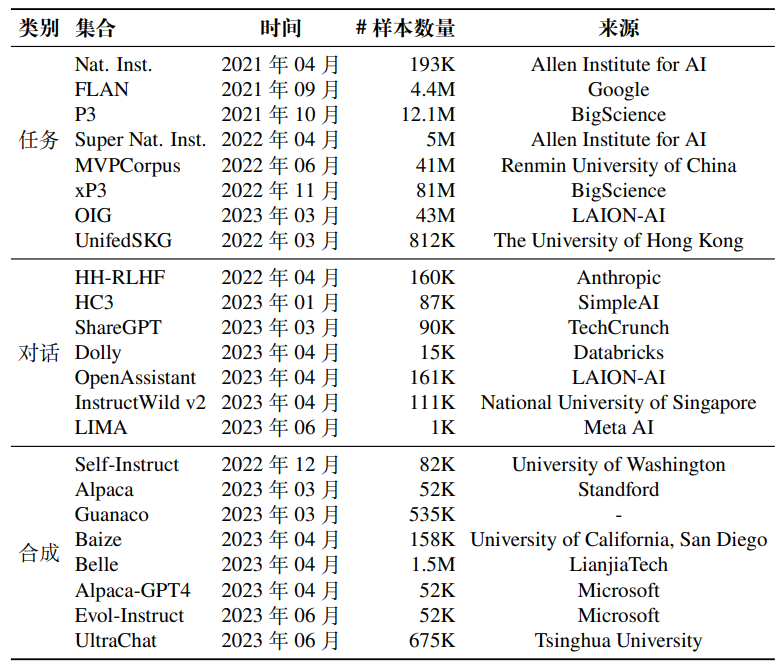
在指令微调被提出前,早期的研究通过收集不同自然语言处理任务(如文本分类和摘要等)的实例,创建了有监督的多任务训练数据集。这些多任务训练数据集成为了构建指令微调数据集的重要来源之一。一般的方法是使用人工编写的任务描述来扩充原始的多任务训练数据集,从而得到可以用于指令微调的自然语言处理任务数据集。其中,P3和 FLAN是两个代表性的基于自然语言处理任务的指令微调数据集。
P3(Public Pool of Prompts)是一个面向英文数据的指令微调数据集,由超过 270 个自然语言处理任务数据集和 2,000 多种提示整合而成(每个任务可能不止一种提示),全面涵盖多选问答、提取式问答、闭卷问答、情感分类、文本摘要、主题分类、自然语言推断等自然语言处理任务。P3 是通过 Pr
推荐阅读
相关标签

