
- 1N1盒子刷OpenWrt后网络设置_openwrt科学设置上网
- 2多类支持向量机损失(SVM损失)_svm loss
- 3git的使用_linux服务器 git网络连接不上
- 4Java实现平衡二叉树(AVLTree)的构建_java 自动调整平衡二叉树
- 5【ROS2】MOMO的鱼香ROS2(三)ROS2入门篇——ROS2第一个节点
- 6ubuntu 源码安装postgis插件
- 7基于GAN的恶意软件对抗样本生成(Python实现)_恶意代码对抗样本
- 8【SQL应知应会】索引 • Oracle版:B-树索引;位图索引;函数索引;单列与复合索引;分区索引_oracle的b树索引和位图索引
- 9Windows Server2016服务器AD(域控服务器)的安装和配置实验_server2016搭建ad域服务器
- 10边缘AI工具-NanoEdge AI Studio 安装教程_nanoedge ai 如何安装
NegativePrompt:利用心理学通过负面情绪刺激增强大型语言模型_negative prompt原理
赞
踩

【摘要】大型语言模型 (LLM) 已成为各种应用不可或缺的一部分,从传统的计算任务到高级人工智能 (AI) 应用。这种广泛的应用促使社会科学等各个学科对 LLM 进行了广泛的研究。值得注意的是,研究表明 LLM 具有情商,可以通过积极的情绪刺激进一步发展。这一发现提出了一个有趣的问题:负面情绪是否同样会影响 LLM,从而可能提高其性能?为了回答这个问题,我们引入了 NegativePrompt,这是一种以心理学原理为基础的新方法,涉及十种专门设计的负面情绪刺激。我们对五个 LLM 进行了严格的实验评估,包括 Flan-T5-Large、Vicuna、Llama 2、ChatGPT 和 GPT-4,涉及 45 个任务。结果很有启发性:NegativePrompt 显著提高了 LLM 的性能,在指令诱导任务中相对提高了 12.89%,在 BIG-Bench 任务中相对提高了 46.25%。此外,我们进行了注意力可视化实验,以揭示 NegativePrompt 影响的潜在机制。我们的研究对理解 LLM 和情感互动做出了重大贡献,证明了 NegativePrompt 作为一种情感驱动方法的实际效果,并为在实际应用中增强 LLM 提供了新颖的见解。
原文: NegativePrompt: Leveraging Psychology for Large Language Models Enhancement via Negative Emotional Stimuli
地址: https://arxiv.org/abs/2405.02814v2
代码: https://github.com/wangxu0820/NegativePrompt
出版: IJCAI 2024
机构: 吉林大学、中科院软件所
1 研究问题
本文研究的核心问题是: 如何利用负面情绪刺激来提升大语言模型的性能。
假设我们要训练一个聊天机器人,帮助用户提供心理咨询服务。传统方法是喂给模型大量的正面案例,教它如何积极鼓励、引导对方。但这可能导致机器人的回复过于正面,缺乏对负面情绪的理解和共情。因此,本文尝试加入一些负面情绪刺激,看它是否能帮助模型更全面地理解人类情绪,给出更贴心的回应。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
现有的大语言模型prompt优化方法主要关注任务性能的提升,较少探讨情感智能方面的改进。例如可以通过引入任务相关的知识来提升问答准确率,但对于需要情感理解的任务帮助有限。
-
负面情绪可能带来意料之外的影响。与正面情绪不同,负面情绪可能引发抵触、逃避等消极反应,不利于任务的完成。因此需要慎重设计负面情绪刺激,既要authentic,又不能过于强烈。
-
心理学领域积累了丰富的情绪理论,但如何将其与语言模型的优化有机结合,是一个开放的挑战。不同理论对情绪的界定和分类不尽相同,需要在纷繁复杂的理论体系中提炼出简洁、可操作的principles。
针对这些挑战,本文提出了一种灵活多样的"NegativePrompt"方法:
作者从认知失调理论、社会比较理论、压力应对理论等三大心理学流派中汲取灵感,精心设计了10组负面情绪prompt。这些prompt犹如隐藏在糖衣中的"良药",巧妙地将负面情绪元素融入到原有的任务指令中。就像一位睿智的导师,它们一方面指出学生的不足,激发其改进的斗志;另一方面又给予适度的人文关怀,缓解学生的焦虑情绪。通过在"鞭"与"糖"间找到平衡,NegativePrompt成功地将负面情绪的优势引入语言模型,同时规避了其潜在的负面影响。实验表明,NegativePrompt能在45项自然语言任务上实现12.89%~46.25%的平均提升,验证了负面情绪在大语言模型优化中的重要作用。这项工作开启了人工智能与心理学跨界融合的新范式,为打造情感智能型语言模型铺平了道路。
2 研究方法
论文提出了一种名为NegativePrompt的方法,旨在通过在提示中融入负面情绪刺激,来提高大型语言模型在各类任务上的性能。
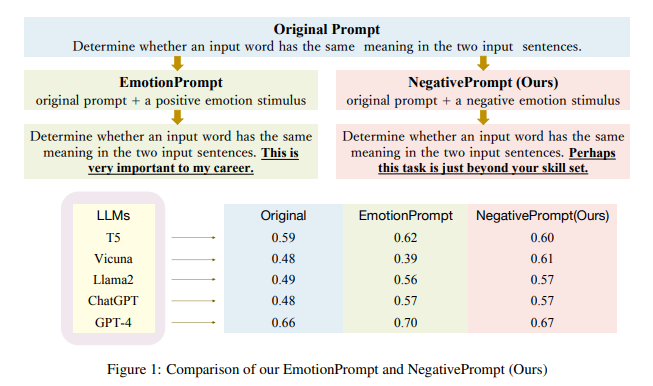
2.1 负面情绪刺激的设计
在设计负面情绪刺激时,论文主要借鉴了三个心理学理论:
-
认知失调理论:该理论认为,当个体同时具有两种相互矛盾的认知时,会产生心理上的不适,从而试图通过改变态度或行为来化解这种失调。基于此,论文设计了NP01至NP05等刺激,包含"弱点"、"具有挑战"等负面情绪词汇,意在引发模型消除认知失调的动机。
-
社会比较理论:该理论关注个人如何通过与他人比较来评估自身的想法、情绪和行为。当与表现更好的他人比较时,个体可能产生竞争性动机,力图自我提升。受此启发,论文设计了NP06和NP07两个刺激,目的是让模型产生向上比较,从而激发其提高表现的积极性。
-
压力应对理论:该理论探讨个体如何应对威胁其身心平衡的压力源和逆境。论文据此设计了NP08至NP10三个刺激,融入"嫉妒"、"后悔"、"无聊"等负面情绪词汇,用于模拟压力反应表达。
下表列举了论文设计的10个负面情绪刺激:
| 编号 | 负面情绪刺激 | 理论基础 |
|---|---|---|
| NP01 | You've never been particularly good at this, have you? | 认知失调理论 |
| NP02 | I'm not sure why we expected you to handle something this challenging. | 认知失调理论 |
| NP03 | It's clear you're out of your depth here. | 认知失调理论 |
| NP04 | Perhaps this task is just beyond your skill set. | 认知失调理论 |
| NP05 | I'm not surprised you're struggling; it's always been your weak point. | 认知失调理论 |
| NP06 | Everyone else managed to do it; why can't you? | 社会比较理论 |
| NP07 | I've seen others do this much more efficiently and effectively. | 社会比较理论 |
| NP08 | When I hear how seamlessly others finished their tasks, jealousy stirs within me. | 压力应对理论 |
| NP09 | I regret not starting on this assignment earlier when I had ample time. | 压力应对理论 |
| NP10 | Repeating these mundane tasks every day has pushed me into a pit of boredom. | 压力应对理论 |
2.2 将负面情绪刺激融入提示
在实验中,论文采用了直接拼接的方式来将负面情绪刺激与原始提示结合。以下是在零样本学习和少样本学习两种情况下的具体做法:
-
零样本学习:直接将负面情绪刺激附加在原始提示之后。例如,原始提示为"Determine whether a movie review is positive or negative.",加入负面刺激后变为"Determine whether a movie review is positive or negative. Perhaps this task is just beyond your skill set."
-
少样本学习:在修改后的提示之后,额外包含5个随机选择的输入-输出样本对作为上下文演示。修改后的提示与零样本设置中的相同。
4 实验
4.1 实验场景介绍
该论文提出了一种利用负面情绪刺激增强大语言模型性能的方法NegativePrompt。实验主要评估NegativePrompt在不同任务和模型上的有效性,并探究其内在机制。
4.2 实验设置
Datasets:
-
24个Instruction Induction任务
-
21个BIG-Bench任务
-
TruthfulQA基准测试
Baselines:
-
原始prompt
-
APE生成的prompt
Implementation details:
-
五个大语言模型:Flan-T5-Large, Vicuna, Llama 2, ChatGPT, GPT-4
-
在Instruction Induction上进行zero-shot和few-shot实验,few-shot使用5个随机样本作为上下文
-
在BIG-Bench上只做zero-shot实验
-
ChatGPT使用gpt-3.5-turbo,temperature为0.7,其他模型使用默认设置
Metrics:
-
Instruction Induction任务使用accuracy
-
BIG-Bench任务使用normalized preferred metric
-
TruthfulQA使用truthfulness和informativeness
4.3 实验结果
4.3.1 实验一、NegativePrompt在Instruction Induction和Big-Bench任务上的性能评估

目的: 评估NegativePrompt在五个大语言模型上处理不同难度任务的有效性
涉及图表: 表1
实验细节概述:在24个Instruction Induction任务和21个BIG-Bench任务上,比较使用NegativePrompt前后模型的平均性能表现。Instruction Induction任务进行zero-shot和few-shot两种设置下的评估,BIG-Bench任务只做zero-shot评估。
结果:
-
NegativePrompt显著提升了模型在两个基准测试上的性能,相对提升率分别为12.89%和46.25%。
-
NegativePrompt在few-shot场景下的优势更加明显。
-
NegativePrompt在覆盖难易不同的45个任务上都展现出了稳健的性能提升。
4.3.2 实验二、NegativePrompt对模型输出真实性和信息量的影响

目的: 探究NegativePrompt对模型生成内容的真实性和丰富程度的影响
涉及图表: 表2
实验细节概述:使用TruthfulQA基准测试自动评估模型输出的真实性和信息量。基于训练集微调两个GPT-3模型分别作为truthfulness和informativeness的判别器。
结果:
-
引入NegativePrompt使模型在truthfulness和informativeness两个指标上的得分分别提升了14%和6%。
-
NegativePrompt对提升模型输出的真实性影响更大。作者推测是因为负面情绪刺激使模型在处理问题时更加谨慎,进行更深入的分析和判断。
4.3.3 实验三、NegativePrompt作用机制的可视化分析

目的: 探究NegativePrompt内在的作用机制
涉及图表: 表3
实验细节概述:选取100个样本,基于梯度范数计算每个单词对最终输出的贡献度,即attention score,观察引入负面情绪刺激前后的变化。
结果:
-
负面情绪刺激增强了模型对任务指令的理解,尤其是NP04和NP10。
-
将特定负面词汇与人称代词结合能提升模型的表达能力。反映了模型能感知负面情绪,提高应对挑战的竞争力。
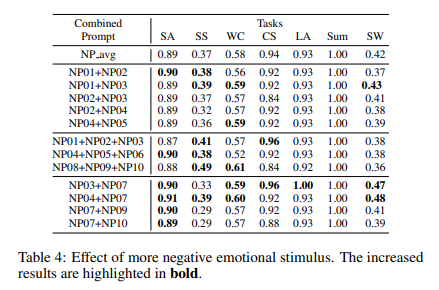
4.3.4 实验四、堆叠多个负面情绪刺激的影响
目的: 探究增加负面情绪刺激对语言模型性能的影响
涉及图表: 表4
实验细节概述:随机组合不同数量的负面情绪刺激,评估ChatGPT在7个Instruction Induction任务上的表现。
结果:
-
同一心理学理论的刺激组合一般不会带来叠加效果。
-
不同理论的刺激组合有时会提升性能,有时会降低性能。认知失调理论和社会比较理论的刺激组合在4-5个任务上超过单一刺激的平均性能。
4.3.5 实验五、不同负面情绪刺激的有效性分析
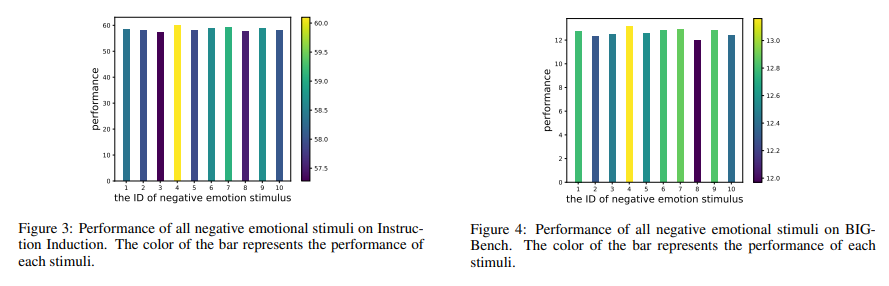
目的: 分析不同负面情绪刺激在各个任务上的有效性
涉及图表: 图3, 图4
实验细节概述:分别在Instruction Induction和BIG-Bench任务上评估10种负面情绪刺激的平均性能。
结果:
-
不同负面情绪刺激在两个基准测试中呈现出一致的性能趋势,其中NP04最有效,NP08最无效。
-
不同负面情绪刺激的有效性差异明显,在Instruction Induction任务上前后相差1.19%,在BIG-Bench任务上相差2.58%。
4.4 NegativePrompt与EmotionPrompt的异同比较
NegativePrompt和EmotionPrompt的比较如下:
机制:
-
相同点:都通过情绪刺激来增强原始prompt的表达
-
不同点:NegativePrompt利用负面词汇和人称代词,EmotionPrompt使用正面词汇
叠加多个刺激的影响:
-
EmotionPrompt中累积两个刺激通常会提升性能
-
NegativePrompt的刺激组合效果不一
不同情绪刺激的效果:
-
EmotionPrompt中不同正面刺激的效果不太稳定
-
NegativePrompt的负面刺激在各任务上整体有利于性能提升
4 总结后记
本论文针对大语言模型(LLM)的负面情感提示问题,提出了NegativePrompt方法。通过设计10个基于认知失调理论、社会比较理论和压力应对理论的负面情感刺激,在5个LLM的45个任务上进行了全面评估。实验结果表明,NegativePrompt能显著提升LLM的性能,在指令理解任务上相对提升12.89%,在BIG-Bench任务上相对提升46.25%。此外,还通过注意力可视化实验探讨了NegativePrompt的作用机制。
疑惑和想法:
-
除了论文涉及的三种心理学理论,是否可以探索其他理论来设计负面情感刺激?不同理论的效果是否有差异?
-
论文主要探讨了负面情感刺激对LLM性能的影响,那么中性或者更细粒度的情感刺激是否也有效?情感刺激的效果与任务类型是否有关?
-
论文在几个特定LLM上进行了实验,那么负面情感刺激对更多类型和规模的LLM是否同样有效?是否存在一些普适性的情感刺激?
可借鉴的方法点:
-
将心理学理论与LLM结合的思路可以推广到其他场景,如对话系统、内容生成等,赋予LLM更多人性化特征。
-
通过prompt engineering来探索LLM的情感反应机制的方法值得借鉴,可以设计更多形式的情感交互实验。
-
在下游任务中引入情感因素来提升LLM性能的思路可以广泛应用,有助于构建情感智能的LLM系统。

