
- 1【自然语言处理】正向、逆向、双向最长匹配算法的 切分效果与速度测评_自然语言处理速度测评代码
- 2Ubuntu 20.04安装Docker
- 3LaTeX-设置表格大小_latex表格宽度调整
- 4我作为一名软件测试工程师,需要具备哪些能力?_测试需要具备的能力 知乎
- 5QML 控件中修改ToolTip显示的位置_qml tooltip显示位置
- 6基于hive的酒店价格数据可视化分析系统设计和实现_基于hive的民宿价格分析系统
- 7当单片机遇到状态机(一) QP框架的入门_qp 框架工程
- 8Spring Boot 创建线程池并使用_springboot创建线程池和使用
- 9【Linux】Systemd 详解_linux systemd
- 10Python安装教程_python embeddable
Spark大数据技术(Scala)小白教程(一)——大数据技术概述以及环境配置_大数据scala
赞
踩
1.1大数据概念及技术
1.11 大数据的4V概念

大数据具有以下特点:
1. Volume(数据量):大数据指的是巨量的数据量,包括采集、存储和计算的量。大数据的起始计量单位至少是P(1000个T)级的,或者更高的E(100万个T)级或Z(10亿个T)级。
2. Variety(数据多样性):大数据包含非结构化数据,具有很大的多样性,例如文本、图片、视频、文档等。
3. Value(数据价值):大数据的数据价值密度较低,实际操作过程中可以使用的有价值数据量是海量的,但并不是所有的数据都是有价值的,很多的价值比例在10%以下,这是我们最需要解决的问题。
4. Velocity(数据速度):大数据的增长速度很快,处理速度也要求很高,具有较高的时效性要求。例如,交通监控需要对一段时间的数据进行采集、处理,并快速计算出结果,以有效缓解交通拥堵等问题。这与传统数据挖掘有显著的区别。
1.12 大数据关键技术
大数据技术涉及多个层面,包括数据采集与数据预处理、数据存储与管理、数据处理与分析、数据可视化以及数据安全与保护。下面是对每个层面的介绍及相关软件:
1. 数据采集与数据预处理:
- 数据采集:收集各种来源的数据,如传感器数据、日志文件、社交媒体数据等。常用的工具有Flume、Kafka等。
- 数据预处理:对原始数据进行清洗、去重、转换和规范化等操作,以提高数据质量。常用的工具有Hadoop、Spark等。
2. 数据存储与管理:
- 分布式文件系统:用于存储大规模数据,如Hadoop分布式文件系统(HDFS)。
- 列式数据库:适用于大规模数据的高效读取和分析,如Apache HBase。
- NoSQL数据库:非关系型数据库,适用于海量结构化和非结构化数据的存储和查询,如MongoDB、Cassandra等。
3. 数据处理与分析:
- 批处理:对大规模数据进行离线处理和分析,如Hadoop MapReduce、Apache Spark等。
- 流式处理:实时处理和分析数据流,如Apache Storm、Apache Flink等。
- 机器学习与深度学习:应用机器学习和深度学习算法进行数据挖掘和模型训练,如TensorFlow、PyTorch等。
4. 数据可视化:
- 数据可视化工具:将数据以图表、地图等形式展示,帮助用户更好地理解和分析数据,如Tableau、Power BI等。
- 数据仪表盘:提供实时数据监控和可视化展示,如Grafana、Kibana等。
5. 数据安全与保护:
- 数据加密:对敏感数据进行加密保护,如SSL/TLS协议、AES加密算法等。
- 访问控制:限制对数据的访问权限,如基于角色的访问控制(RBAC)。
- 数据备份与恢复:定期备份数据以防止数据丢失,如Hadoop的HDFS快照功能。
1.2 主流大数据技术
1.21 Hadoop
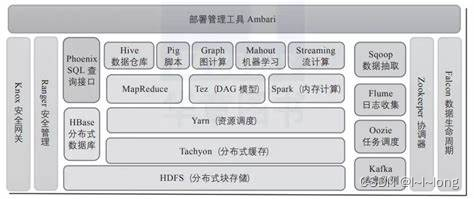
主流大数据技术包括很多工具和框架,其中 Hadoop 生态系统是其中最为知名和常用的一部分。以下是关于 Hadoop 生态系统中主要组件的简要介绍:
1. HDFS(Hadoop Distributed File System):Hadoop 分布式文件系统,用于存储大规模数据集,并提供高容错性、高吞吐量的数据访问。
2. MapReduce:Hadoop 中的分布式计算框架,用于并行处理大规模数据集。MapReduce 将计算任务分解为 Map 和 Reduce 两个阶段,适用于批处理任务。
3. HBase:Hadoop 生态系统中的 NoSQL 数据库,提供实时读写访问大规模数据的能力,适合低延迟和随机访问的场景。
4. Hive:基于 Hadoop 的数据仓库工具,提供类似 SQL 的查询语言 HiveQL,用于在 Hadoop 上进行数据分析和查询。
5. Flume:Hadoop 生态系统中的数据采集、聚合和移动工具,用于实时收集、聚合和传输大规模数据流。
6. Sqoop:Hadoop 数据导入导出工具,用于在 Hadoop 和传统数据库之间进行数据的快速导入和导出。
这些工具和框架共同构成了 Hadoop 生态系统,为大数据处理提供了全面而强大的解决方案。在实际应用中,可以根据具体需求选择适合的组件组合,构建符合业务需求的大数据处理平台。
1.22 Spark
Spark 简介: Apache Spark 是一个基于内存计算的大数据处理框架,提供了高性能和灵活性,支持多种数据处理模式。Spark 提供了丰富的 API,包括 Spark Core、Spark SQL、Spark Streaming、MLlib(机器学习库)和 GraphX(图计算库),使得用户可以方便地进行数据处理、数据分析和机器学习等任务。
Spark 与 Hadoop 对比:
-
Hadoop 的缺点:
- 高延迟: Hadoop MapReduce 是一种批处理模式,处理实时数据时存在较高的延迟,不适合需要快速响应的应用场景。
- 磁盘读写: Hadoop 的 MapReduce 框架在数据处理过程中需要频繁读写磁盘,导致性能较低。
- 复杂性: Hadoop 的配置和管理相对复杂,需要较多的人力和资源投入。
-
Spark 的优点:
- 内存计算: Spark 采用内存计算方式,将数据存储在内存中,大大提高了数据处理速度,适合需要低延迟的实时数据处理需求。
- 多种数据处理模式: Spark 支持批处理、流处理、交互式查询、机器学习和图计算等多种数据处理模式,更加灵活。
- 易用性: Spark 提供了丰富的 API 支持,编程模型简单易懂,开发效率高。
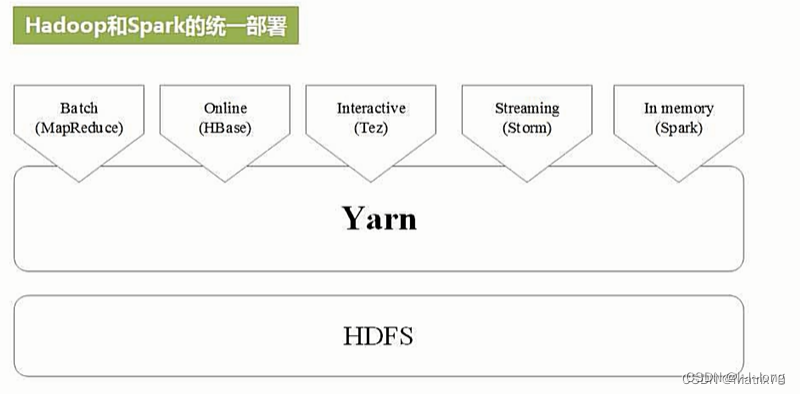
Spark 与 Hadoop 的统一部署: Spark 相对于 MapReduce 具有更高的性能、更灵活的数据处理模式、更简单易用的编程模型和更高效的资源管理。在实时数据处理、交互式查询和复杂数据处理任务中,Spark 更具优势。然而,MapReduce 在某些场景下仍然有其优势,如对于简单的批处理任务和对稳定性要求较高的任务。因此,根据具体需求和场景选择合适的框架是很重要的。因此许多企业在实际应用中通常采用统一部署的形式。Spark 与 Hadoop 可以统一部署在同一个集群中,实现共享资源和数据的优势。通过 YARN(Hadoop 的资源管理器)或者 Spark 自带的 Standalone 模式,可以在同一个集群上同时运行 Hadoop 和 Spark 作业。这种统一部署方式可以充分利用集群资源,减少资源的浪费,简化集群管理,并提高数据处理的整体性能。同时,Spark 可以直接读取 HDFS(Hadoop 分布式文件系统)中的数据,实现数据共享和互操作性。
1.3 Spark的编程语言——Scala
1.31为什么选择 Scala 作为 Spark 的编程语言?
-
Scala 是 JVM 语言:
- Scala 是一种运行在 Java 虚拟机(JVM)上的编程语言,与 Java 无缝集成。由于 Spark 本身就是用 Scala 编写的,因此选择 Scala 作为编程语言可以更好地与 Spark 内部代码集成,提高开发效率。
-
函数式编程支持:
- Scala 是一种支持函数式编程的语言,具有强大的函数式编程特性,如高阶函数、不可变性和模式匹配等。这些特性使得在 Spark 中进行数据处理更加简洁、高效和易于理解。
-
静态类型系统:
- Scala 是一种静态类型语言,可以在编译时捕获更多的错误,提高代码的可靠性和稳定性。在大规模的数据处理任务中,静态类型系统可以帮助开发人员更好地管理复杂性。
-
并发性能:
- Scala 提供了强大的并发编程支持,通过 Actor 模型等机制可以更好地处理并发任务。在 Spark 中,处理大规模数据时并发性能尤为重要,Scala 的并发特性有助于提高 Spark 作业的性能和效率。
-
丰富的函数库:
- Scala 拥有丰富的函数库和工具,可以帮助开发人员更快地构建复杂的数据处理逻辑。这些函数库可以与 Spark 的 API 结合使用,为开发人员提供更多的选择和灵活性。
-
社区支持:
- Scala 拥有一个庞大而活跃的社区,有大量的开发者为其贡献代码和工具。Spark 作为 Scala 的主要应用之一,能够充分利用 Scala 社区的资源和支持,保证了 Spark 的持续发展和改进。
综上所述,Scala 作为 Spark 的编程语言,不仅与 Spark 内部代码更好地集成,还具有强大的函数式编程支持、静态类型系统、并发性能和丰富的函数库,这些特性使得 Scala 成为 Spark 开发的理想选择。
1.4 安装Linux系统
1.41使用 Spark 为什么要安装 Linux 系统?
-
原生支持:
- Spark 最初是在 Linux 环境下开发和测试的,因此在 Linux 上运行 Spark 可以获得最好的兼容性和性能。Spark 在 Linux 上的部署更为稳定和高效。
-
开发者社区支持:
- 大多数 Spark 的开发者和用户选择在 Linux 上进行开发和部署,因此在 Linux 上更容易获得社区支持和解决问题。开发者可以更快地获得帮助和资源。
-
性能优势:
- Linux 系统通常比 Windows 系统更适合用于大数据处理和分布式计算,因为 Linux 具有更好的性能、稳定性和可靠性。Spark 在 Linux 上可以更好地发挥其性能优势。
-
容易部署分布式环境:
- 在 Linux 系统上部署分布式环境更为简单和灵活,可以更好地管理集群节点、配置网络和调优系统性能。Spark 的分布式计算需要一个可靠的操作系统来支持。
-
资源管理和调度:
- Linux 系统提供了更多的资源管理和调度工具,如 YARN、Mesos 等,这些工具可以更好地管理集群资源、调度作业和监控任务。Spark 在 Linux 上可以更好地与这些工具集成。
-
安全性和稳定性:
- Linux 系统通常比 Windows 系统更安全和稳定,可以更好地保护数据和系统免受攻击。在大数据处理中,安全性和稳定性是至关重要的。
1.42 安装Linux虚拟机——VMware17
Linux 虚拟机可以在不同的主机系统上运行,如 Windows、macOS 等,提供了跨平台兼容性。考虑到目前许多读者使用的都是window或者mac系统,因此为了后续学习,这里出一个Linux虚拟机安装教程。
安装步骤:
1.打开网站https://www.vmware.com/products/workstation-player/workstation-player-evaluation.html
2.点击红色边框的立即下载
3.将下载好的文件打开

打开后会出现这个界面:
4.点击下一步直到出现这个界面,将第二个勾选上,如下图:
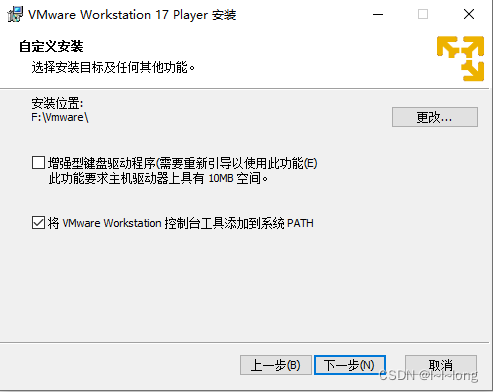
5.勾选下面两个选项,点击下一步

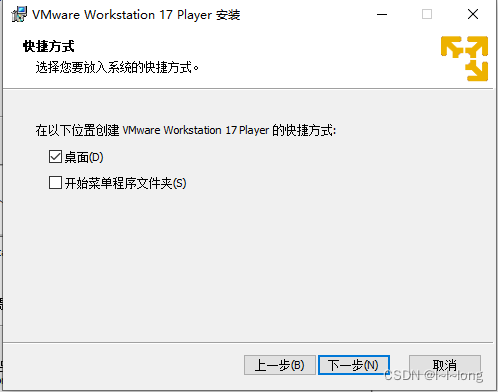
6. 点击安装,等待安装
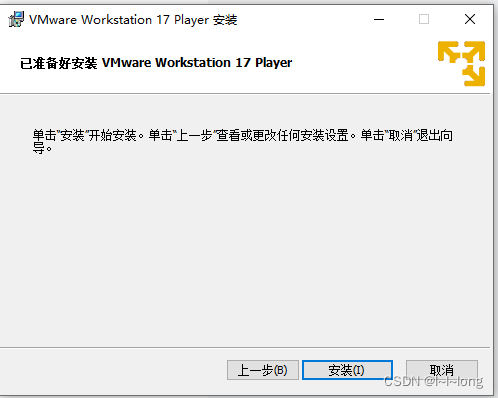
7.安装完成后点击完成:
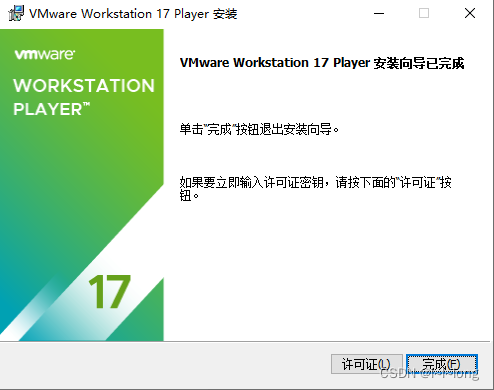
8.在桌面上会出现这个图标 ,说明安装完成,打开后出现这个界面
,说明安装完成,打开后出现这个界面
9 .下载ubuntu镜像文件,这里本文使用的是Ubuntu16.04版本
官网地址:http://www.ubuntu.com,页面如下,点击红色方框
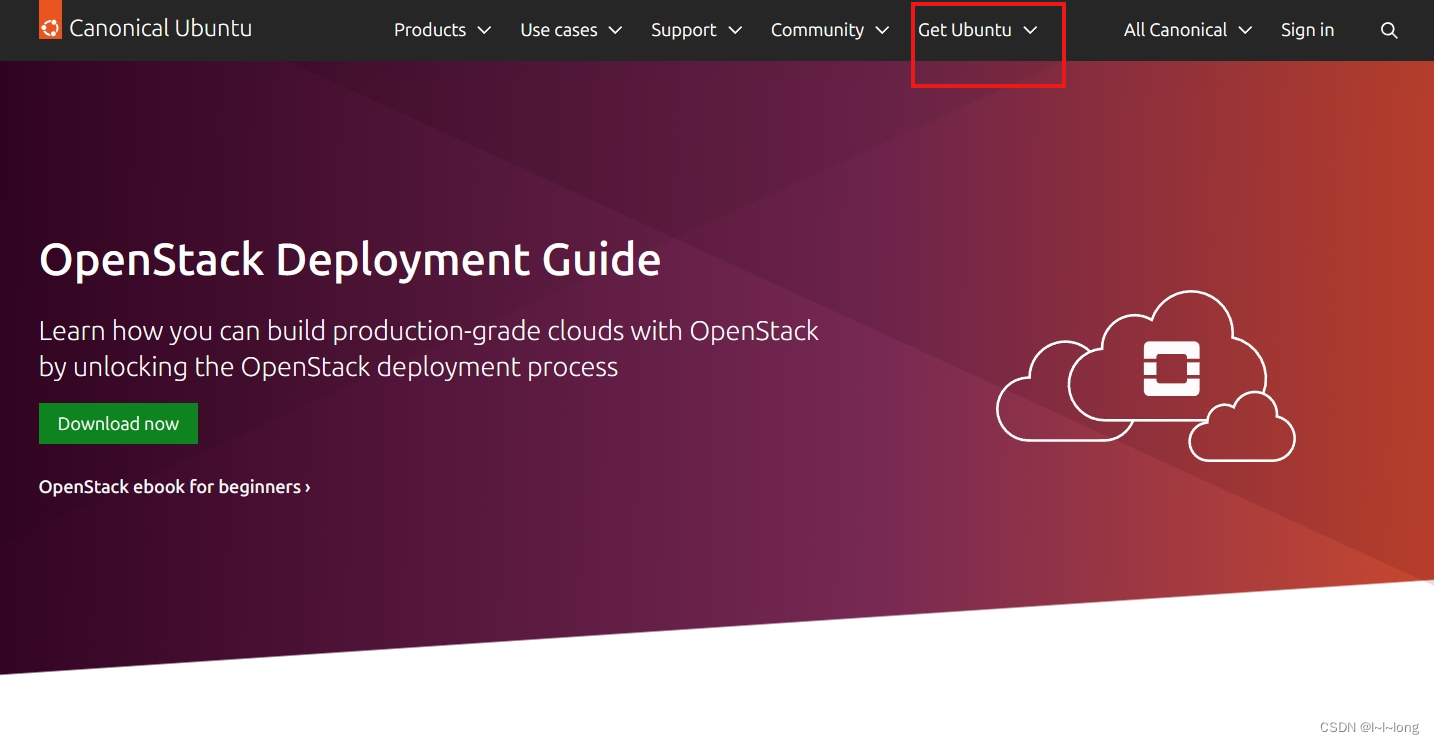 点击红色框的下载,版本为22.04,其他版本网站里也有,这里不赘述,读者可自行探索。
点击红色框的下载,版本为22.04,其他版本网站里也有,这里不赘述,读者可自行探索。


若官网的速度较慢,下面介绍更快的方法,首先,在刚刚的界面上点击红色框框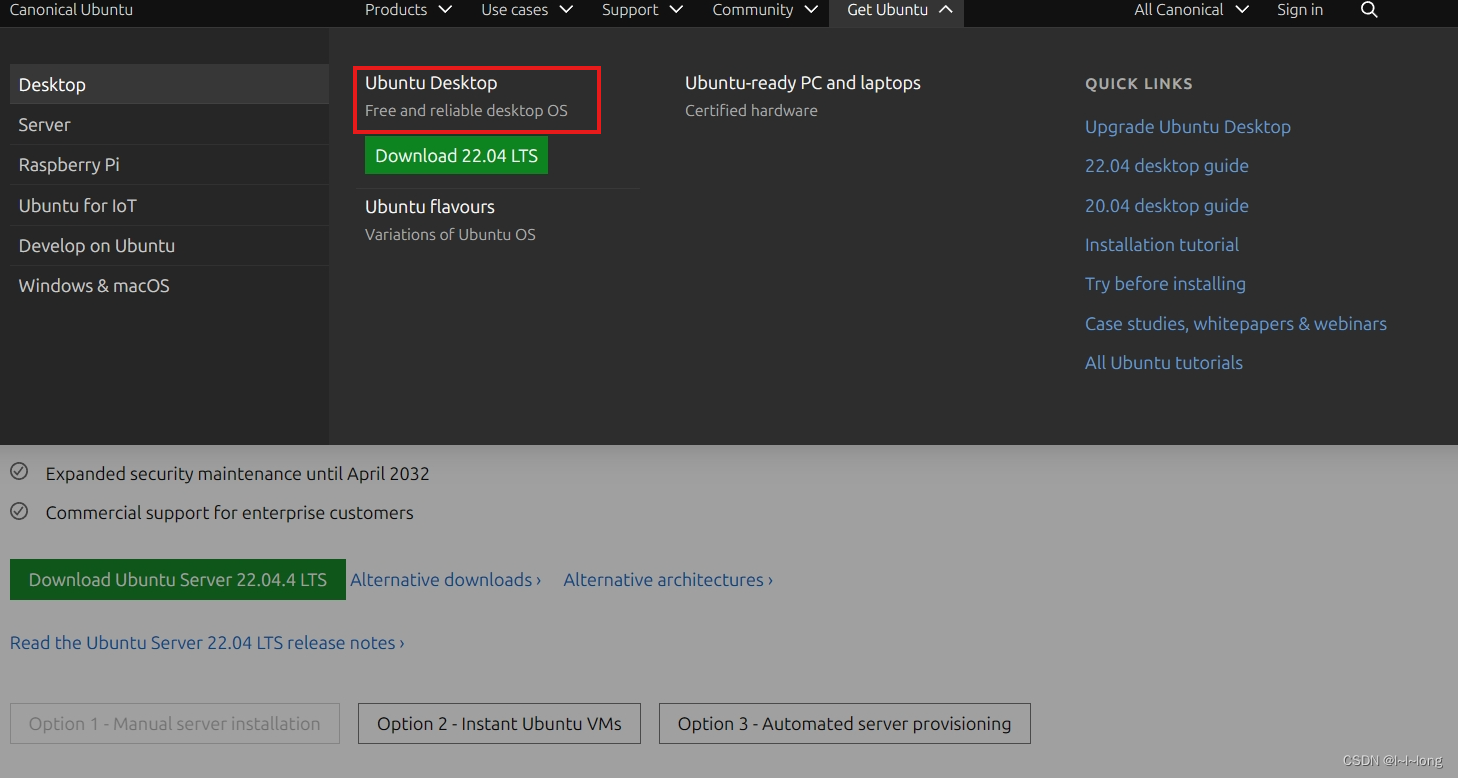
然后在进入的页面往下拉,点击红色框框
进入页面后下滑找到这个选项,点击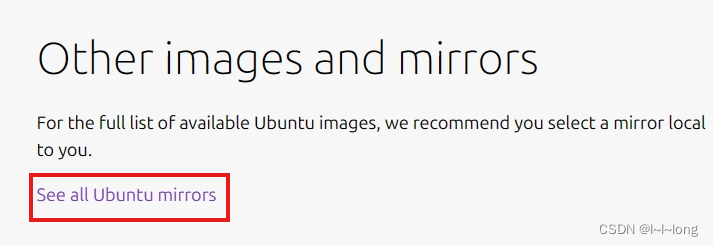 进入页面后下滑,找到我国的镜像,任意选择一个点击
进入页面后下滑,找到我国的镜像,任意选择一个点击
这里选择南洋理工大学实测更快![]()
选择下载的版本,这里我选择22.04.4,点击
![]()
选择红色方框文件,点击即可下载

但是有时候镜像也不一定更快,比如我这次官网竟然更快,可能是版本不同,根据情况定就好
不过通常来说,镜像网站的速度更快(网速有一个加速过程),网络更稳定,我后面下载的时候官网的直接断了
下载好之后,先把文件剪切到一个新文件夹里,防止找不到,后续要用文件地址
10.然后打开vm虚拟机,点击新建

然后选择你刚刚存放下载好的镜像文件的位置,点击浏览选中文件

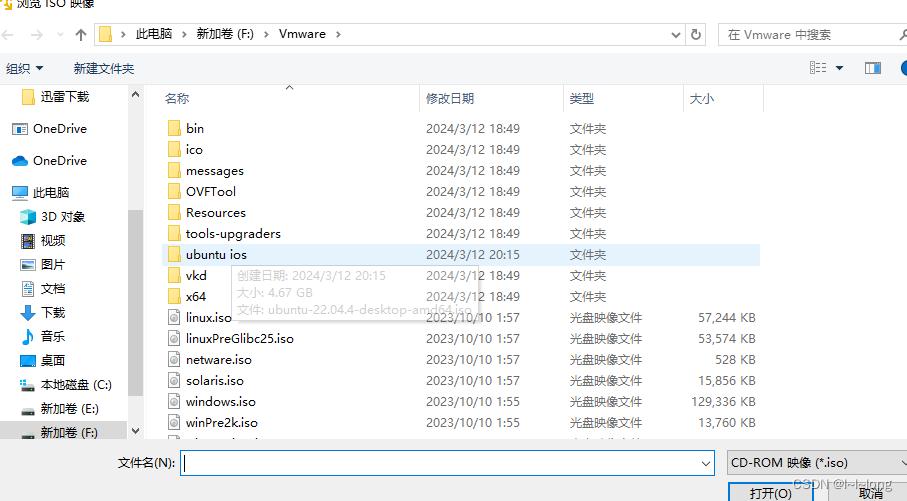
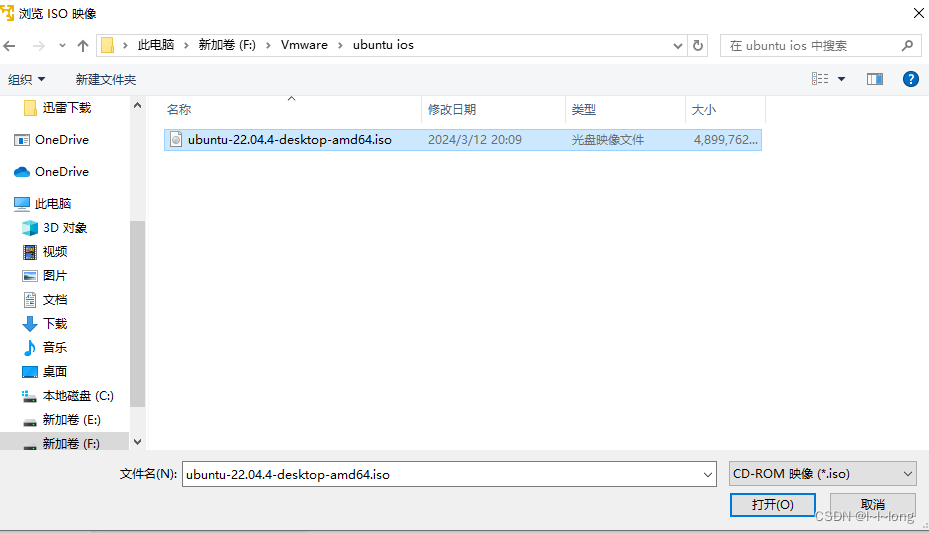
点击打开,然后选择下一步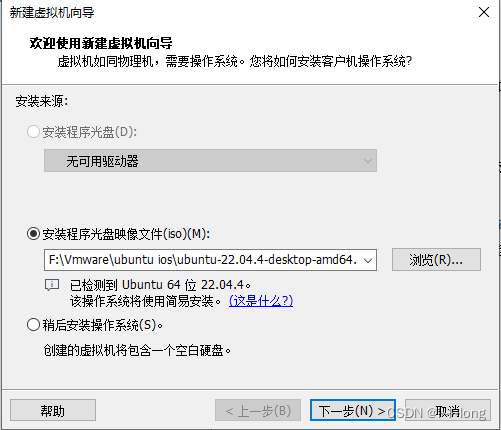
设置账户和密码,用来登录Linux系统的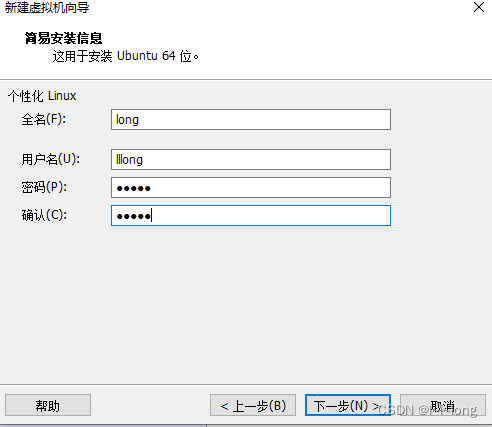
然后命名系统,设置存放位置,一般不用c盘,除非你c盘容量大比如我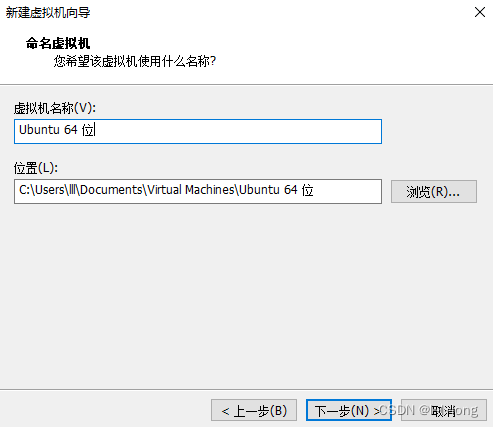
我选择30gb作为这个容量大小,然后选择单个文件,如下
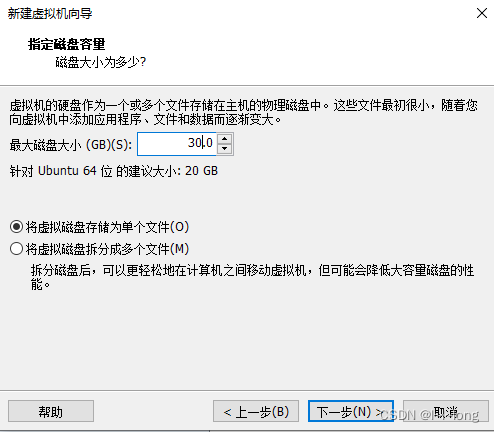
然后下一步就是直接点完成就行了,就会进入这个界面
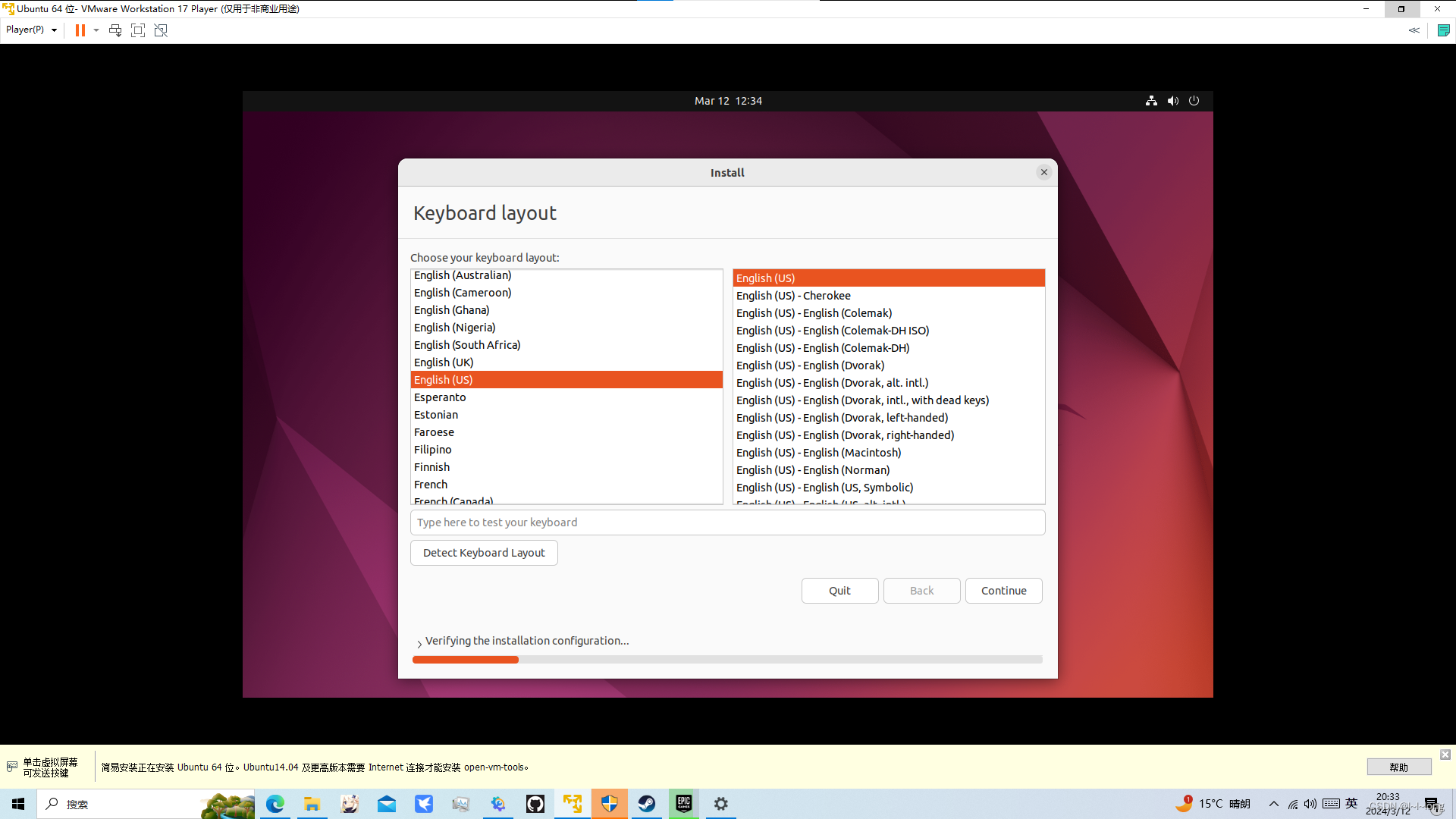
一直continue就行,然后install now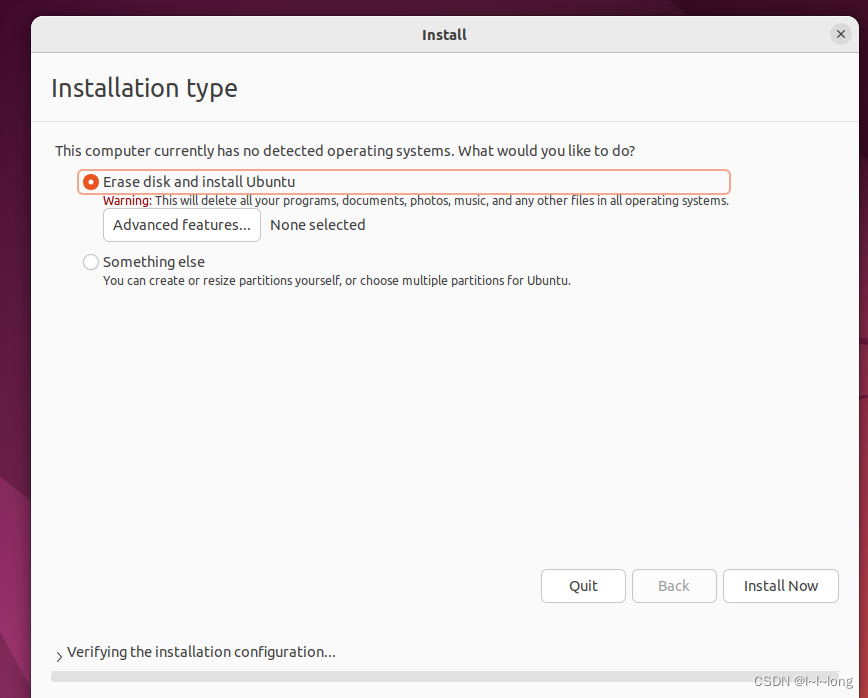
后面会有一个选地址的,我选的上海,然后就到这个页面,设置个人信息和密码
 然后点击重启即可
然后点击重启即可
根据刚刚设置的密码即可进入系统桌面
至此,Linux虚拟机的安装就全部完成了。
总结:本文简单介绍了大数据概念及相关技术,以此引入Spark技术,然后介绍了其编程语言Scala以及Linux系统的安装,为后续学习做了前置知识储备和环境搭建,后续我将继续根据所学知识,持续更新Spark技术的知识章节,本人水平有限,若文中有错误,欢迎各位指正,求关注点赞,这是我持续更新的动力!

