- 117.应用负载压力测试
- 2CDP客户数据平台:构建S2B2C智能名片商城的核心引擎_2b cdp
- 3Cobaltstrike系列教程(一)简介与安装_cobalt strike汉化版
- 4Node.js 版本管理工具(Node Version Manager)
- 5Python控制键盘鼠标pynput的详细用法 (转载)_mouse.click(button.left, 1)
- 6若依(RuoYi)前后端分离版中的ruoyi-ui目录结构_ruoyi ui
- 7【leetcode】203. 移除链表元素(python)_python 移除链表元素完整代码
- 8智谱AI通用大模型:官方开放API开发基础_智普api
- 9跨境电商APP多商户商城源码搭建(快速搭建)_多商户源码
- 10DSPy入门:告别指令提示,拥抱编程之旅!
Hadoop,Spark,Scala伪分布式搭建(详细步骤)_hadoop、spark环境搭建
赞
踩
需要的安装包:
一,准备一台虚拟机:
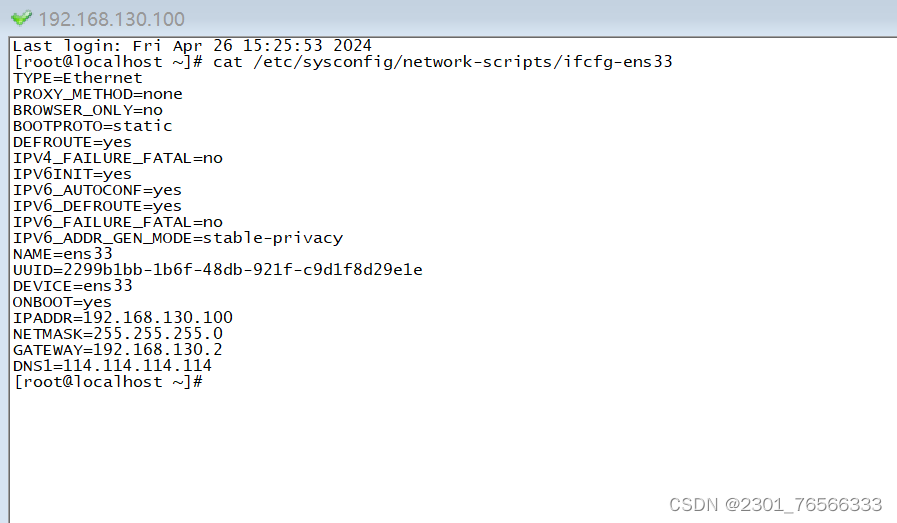
1,ip配置
2,防火墙设置

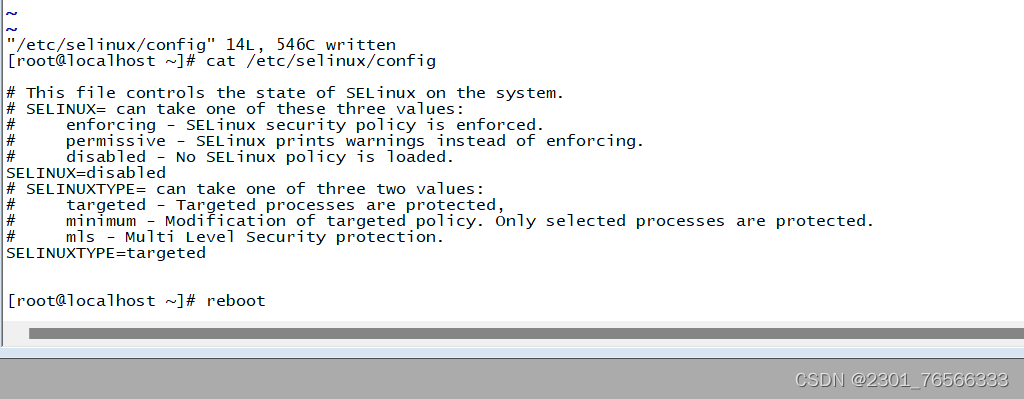
3,关闭seliux,并重启虚拟机
4,修改主机名

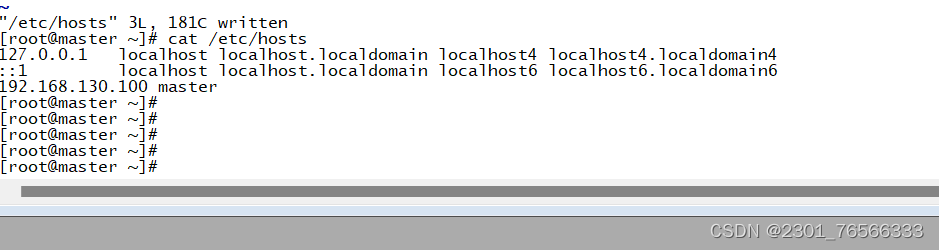
5,设置ip与主机映射
二,SSH无密码登录
1,生产秘钥

2,将秘钥发送给自己(本机)

3,验证登录(无密码)

三,Hadoop伪分布式搭建
1,jdk配置
①上传jdk安装包到/opt/install目录下

②解压jdk到/usr/local/src/目录下

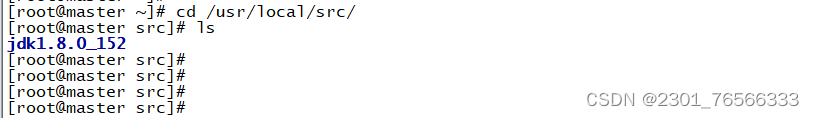
2,设置Java环境变量
vi /etc/profire
在最后添加以下两行:

执行source命令,使文件配置生效:

检查Java是否可用:能够正常显示版本号,说明jdk安装并配置成功

3,Hadoop环境的配置和安装
上传Hadoop安装包到/opt/install/目录下:

解压Hadoop到/usr/local/src/目录下:
 修改环境变量:
修改环境变量:
vi /etc/profile
添加以下两行配置:

source使配置文件生效:

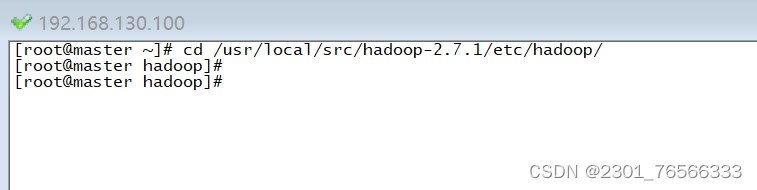
进入/usr/local/src/hadoop-2.7.1/etc/hadoop/ 目录下:
①编辑hadoop-env.sh文件:vi hadoop-env.sh
 注意:jdk路径不要写错
注意:jdk路径不要写错
②编辑core-site.xml文件:vi core-site.xml

③编辑hdfs-site.xml文件:vi hdfs-site.xml

④编辑mapred-site.xml文件:vi mapred-site.xml
先备份mapred-site.xml.tmplate文件 并改名为mapred-site.xml


⑤编辑yarn-site.xml文件:vi yarn-site.xml

⑥编辑/usr/local/src/hadoop-2.7.1/etc/hadoop/slaves 文件

格式化hdfs
[root@master ~]# hdfs namenode -format

启动hadoop集群
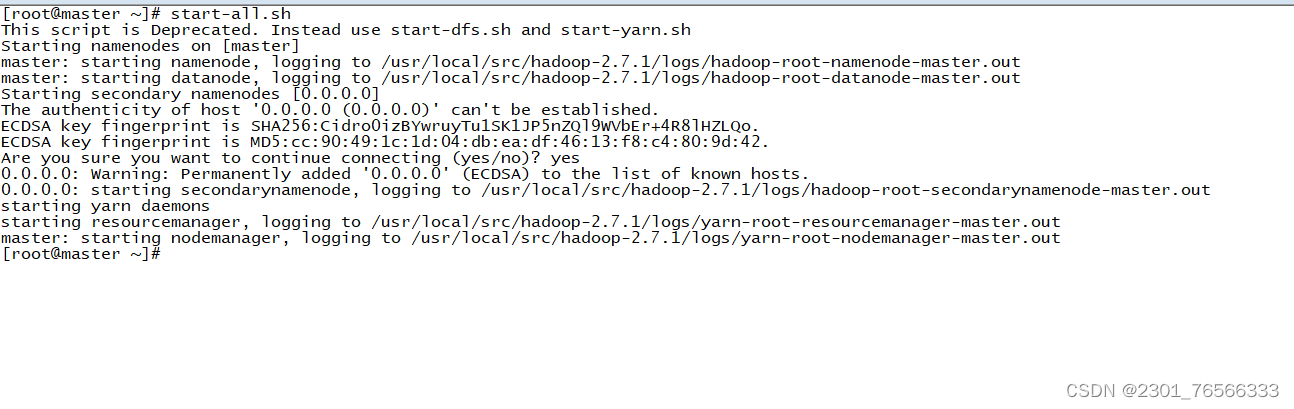
jps查看

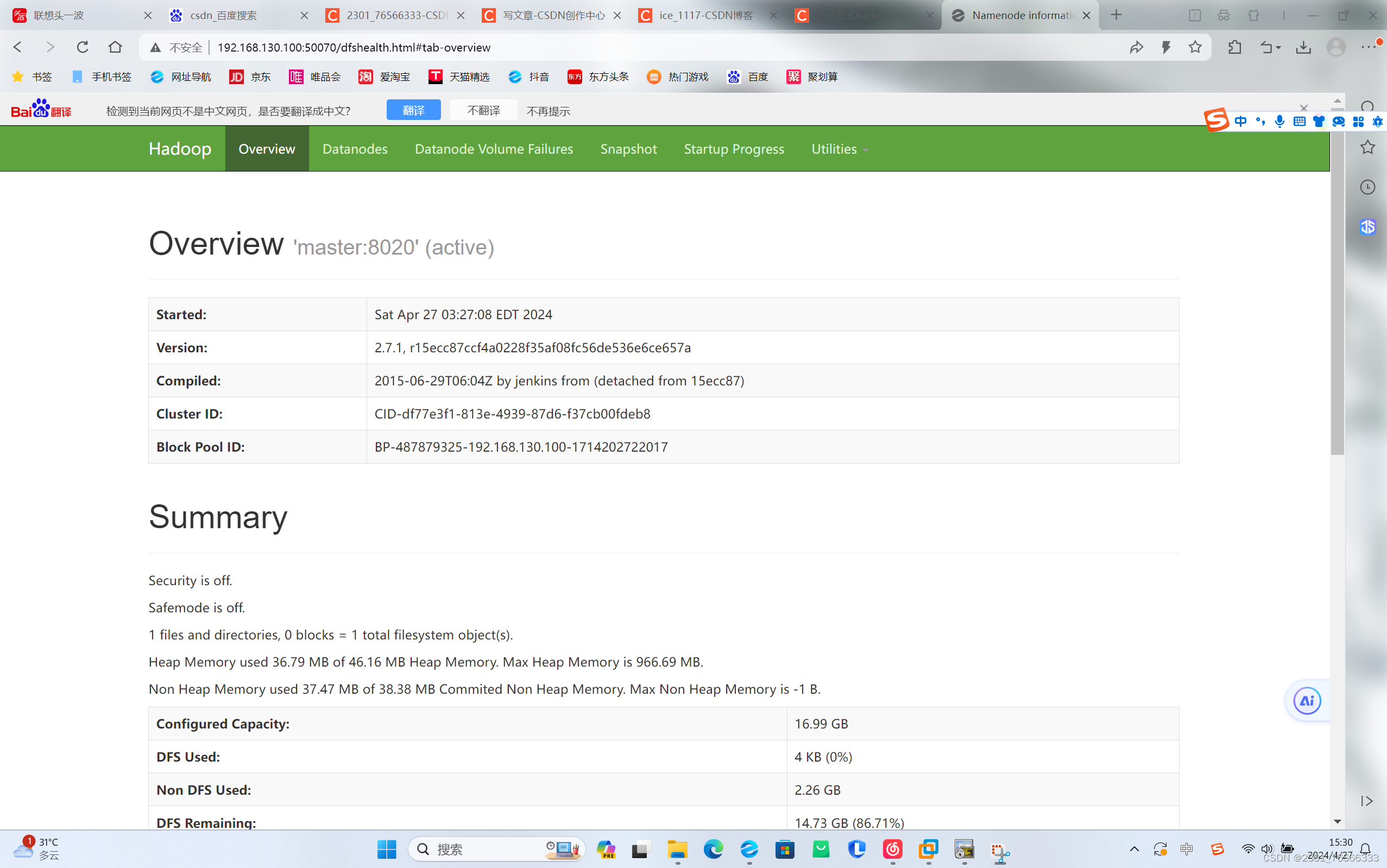
在浏览器地址里输入 http://192.168.130.100:50070 或 http://master:50070
四,Spark伪分布式搭建
1,上传spark安装包到 /opt/install
2,解压该安装包到 /usr/local/src

3,进入conf 目录下
备份spark-env.sh.template文件,改名为spark-env.sh
[root@master bin]# cd /usr/local/spark-2.0.0-bin-hadoop2.6/conf/
[root@master conf]# cp spark-env.sh.template spark-env.sh
4,编辑 spark-env.sh 文件 :vi spark-env.sh

5,启动spark集群:
[root@master conf]# cd /usr/local/spark-2.0.0-bin-hadoop2.6/sbin/
[root@master sbin]# ./start-all.sh

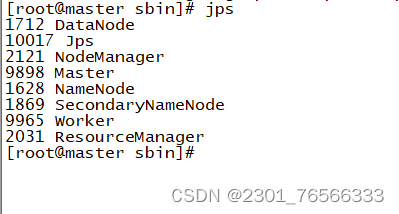
6,jps查看:
多了master和worker,说明成功
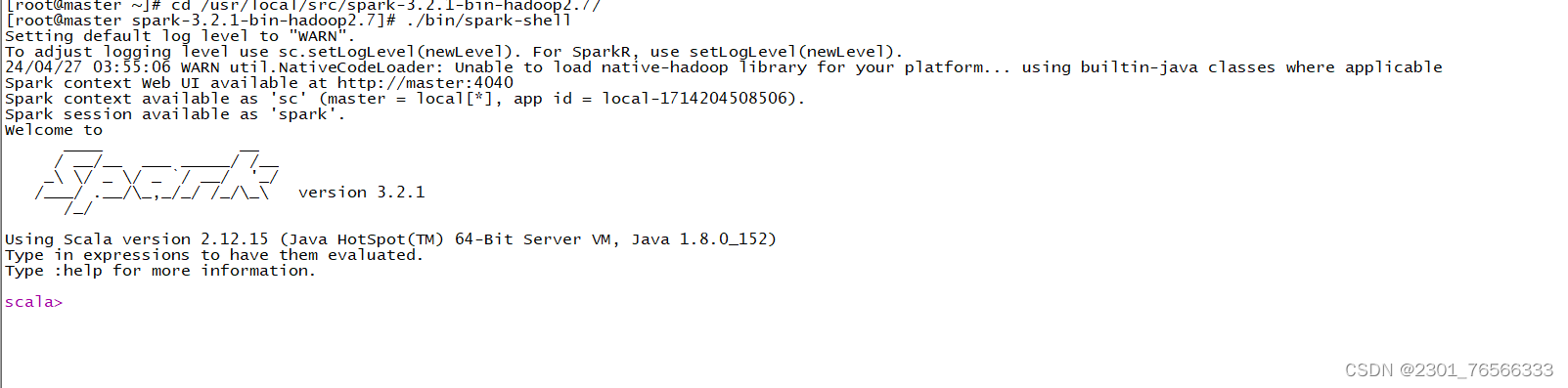
7,启动spark-shell
[root@master ~]# cd /usr/local/spark-2.0.0-bin-hadoop2.6/
[root@master spark-2.0.0-bin-hadoop2.6]# ./bin/spark-hell
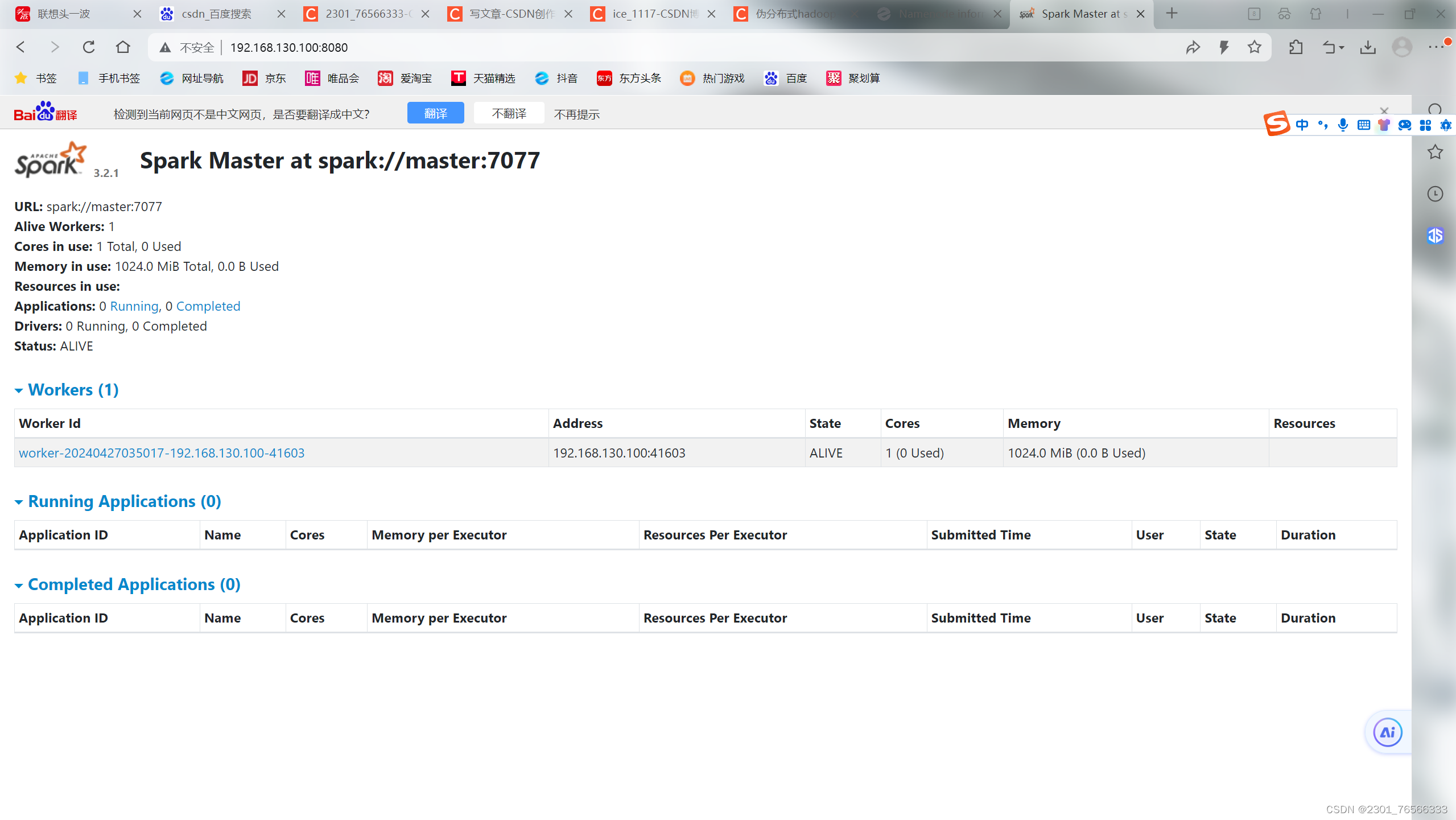
8,查看网页 http://master:8080
五,Scala伪分布式安装
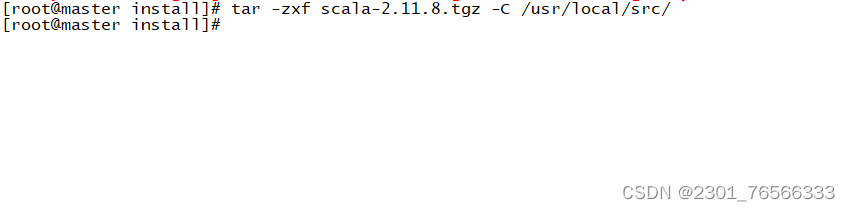
1,上传scala安装包

2,解压Scala安装包
3,配置Scala环境变量
[root@master ~]# vim /etc/profile
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin

source使配置生效

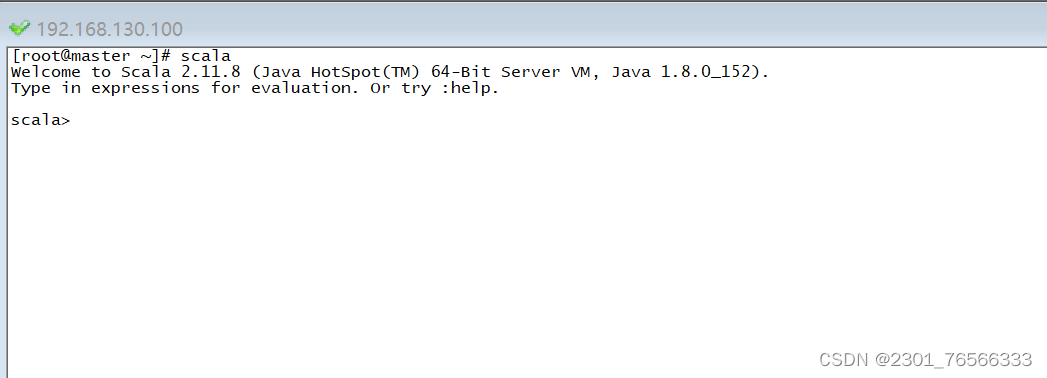
4,Scala验证