
- 1宝德服务器安装系统6,简洁强大的内部结构
- 2数据结构之排序_排序时若想以某个元素为界,将待排序的序列分为两部分,一部分是比该元素值小的,另
- 3ERROR: Repository not found. fatal: 无法读取远程仓库。
- 4Unity | Shader基础知识(第十八集:Stencil应用-透视立方盒子)_unity shader stencil
- 5docker启动显示Job for docker.service failed because the control process exited with error code. 报错
- 6SpringBoot框架的原理和使用_springboot框架工作原理及流程
- 7基于猫眼票房数据的可视化分析_猫眼电影数据可视化
- 8PMP和ACP敏捷项目管理有什么关联?一文说清楚
- 9Python-环境搭建_运行pycharm需要安装erlang吗
- 10记录kettle源码搭建的整体流程_pentaho-kettle 源码部署
聊聊大模型微调训练全流程的思考_模型微调 在整体训练中的流程
赞
踩
参考现有的中文医疗模型:MedicalGPT、CareGPT等领域模型的训练流程,结合ChatGPT的训练流程,总结如下:
在预训练阶段,模型会从大量无标注文本数据集中学习领域/通用知识;其次使用{有监督微调}(SFT)优化模型以更好地遵守特定指令;最后使用对齐技术使LLM更有用更安全的响应用户的提示。
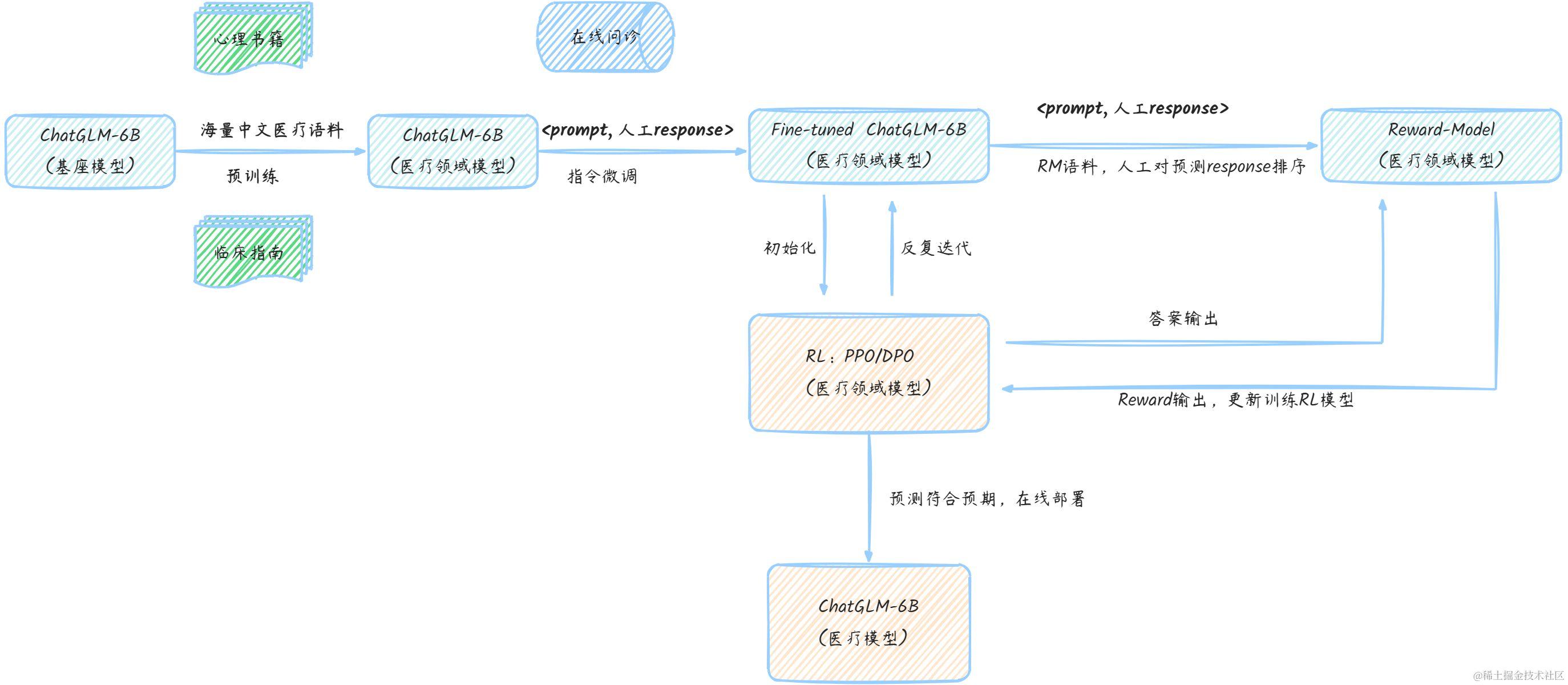
训练流程的四个阶段,分别如下:
- 预训练(pre-training,pt),基于基座模型,经过海量中文医疗预料训练,得到领域适配的ChatGLM-6B。
- 监督微调(supervised finetuning,sft),通过在线问诊等数据,构建训练数据完成指令微调。
- RM模型构建(reward modeling, rm),人工对预测答案排序,训练一个打分模型
- 强化学习阶段(reinforcement learning, rl),基于PPO算法,采用RL的方式,完成fine-tuned ChatGLM-6B模型的优化。
预训练阶段-PT
该阶段的训练数据格式如下。对应是非结构化的自然语言文本,通过设定max_seq_len和block_size等方式,实现文本数据的chunk,batch化,作为模型的训练数据,处理完的单条数据包含input_ids,attention_mask和labels;训练的目标是模型需要根据提供的文本来预测 下一个单词。

监督微调阶段-SFT
该阶段的训练数据格式如下。一般对应的结构采用instruction/input/output/history,根据不同的场景,input与history可以做缺省处理。但是需要人工标注的指令数据集。

对齐
该阶段的主要目标是将语言模型喻人类的偏好、价值观进行对齐,这也是RHLF机制的作用。
RLHF主要包括两步:
- 基于有监督微调模型基础上创建一个reward model(RM)模型;
- 基于RM模型使用PPO/DPO算法微调SFT模型,返回最佳response。
奖励模型-RM
该阶段是RHLF的第一个阶段,训练得到一个rm模型用于rl阶段的模型打分,其结构格式如下:


有多种格式的数据,可自己选择,但需要程序做额外的处理,且这些数据都是人工标注好的。
强化学习-RL
该阶段是RHLF的第二个阶段,也是核心部分,用于优化一个RM模型,并完成打分。数据格式同SFT。一般在此阶段会使用特定的算法(DPO/PPO)来实现;引导优化后的大模型生成更符合人类偏好的内容。
总结
对于模型的微调,一开始我是想的太简单了,觉得只要按照基座官方模型文档调试即可;随着了解的深入与不断的学习,微调是个大工程而且对于领域模型来说,其训练流程:预训练 --> 监督微调 --> RHLF 中包含的事项与知识太多。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/928370
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

