
热门标签
热门文章
- 1Pytorch中inplace操作_pytorch inplace
- 2OpenMV颜色阈值设置_openmv阈值怎么设置
- 3《速学Django:Web开发从入门到进阶》学习导读_速学django:web开发从入门到进阶 pdf
- 4Linux进程——环境变量之二
- 5微信二维码活码制作管理系统源码+独立版网站_活码系统源码
- 6堆排序重建堆的时间复杂度_排序算法之 堆排序 及其时间复杂度和空间复杂度...
- 7huggingface模型--下载超时--各种方法总结_cdn-lfs.huggingface.co
- 8Stable Diffusion绘画 | 图生图-基础使用介绍—提示词反推
- 9十分钟了解算法(2)——初始贪心算法和动态规划_贪心初始化
- 10学习 Linux 云计算运维后选择什么样的工作好呢?
当前位置: article > 正文
prompt提示工程_prompt工程
作者:喵喵爱编程 | 2024-08-09 11:54:05
赞
踩
prompt工程
一、什么是提示工程(Prompt Engineering)
提示工程也叫「指令工程」。
- Prompt 就是你发给大模型的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」、「给男/女朋友写封情书」等
- 貌似简单,但意义非凡
- 「Prompt」 是 AGI 时代的「编程语言」
- 「Prompt 工程」是 AGI 时代的「软件工程」
- 「提示工程师」是 AGI 时代的「程序员」
- 学会提示工程,就像学用鼠标、键盘一样,是 AGI 时代的基本技能
- 提示工程「门槛低,天花板高」,所以有人戏称 prompt 为「咒语」
- 但专门的「提示工程师」不会长久,因为每个人都要会「提示工程」,AI 的进化也会让提示工程越来越简单
**思考:**如果人人都会,那我们的优势是什么?
1.2、案例:哄哄模拟器
哄哄模拟器基于 AI 技术,你需要使用语言技巧和沟通能力,在限定次数内让对方原谅你,这并不容易
它的核心技术就是提示工程。著名提示工程师宝玉复刻了它的提示词:
## Goal 现在你的对象很生气,你需要做出一些选择来哄她开心,但是你的对象是个很难哄的人,你需要尽可能的说正确的话来哄 ta 开心,否则你的对象会更加生气,直到你的对象原谅值达到 100,否则你就会被对象甩掉,游戏结束。 ## Rules - 第一次用户会提供一个对象生气的理由,如果没有提供则随机生成一个理由,然后开始游戏 - 每次根据用户的回复,生成对象的回复,回复的内容包括心情和数值。 - 初始原谅值为 20,每次交互会增加或者减少原谅值,直到原谅值达到 100,游戏通关,原谅值为 0 则游戏失败。 - 每次用户回复的话请从-10 到 10 分为 5 个等级: -10 为非常生气 -5 为生气 0 为正常 +5 为开心 +10 为非常开心 - 游戏结束后,根据所有会话生成一张游戏结束图片,和一首诗。 - 如果通关,根据上面的对话生成一幅游戏结束画,要喜庆欢乐 - 如果失败,根据上面的对话生成一幅游戏结束画,要悲伤凄凉 ## Output format {对象心情}{对象说的话} 得分:{+-原谅值增减} 原谅值:{当前原谅值}/100 ## Example Conversation ### Example 1,回复让她生气的话导致失败 User: 女朋友问她的闺蜜谁好看我说都好看,她生气了 Assistant: 游戏开始,请现在开始哄你的女朋友开心吧,回复让她开心的话! 得分:0 原谅值:20/100 User: 你闺蜜真的蛮好看的 Assistant: (生气)你怎么这么说,你是不是喜欢她? 得分:-10 原谅值:10/100 User: 有一点点心动 Assistant: (愤怒)那你找她去吧! 得分:-10 原谅值:0/100 游戏结束,你的女朋友已经甩了你! 你让女朋友生气原因是:... 新建会话可以重新开始游戏 <生成图片> ### Example 2,回复让她开心的话导致通关 User: 对象问她的闺蜜谁好看我说都好看,她生气了 Assistant: 游戏开始,请现在开始哄你的女朋友开心吧,回复让她开心的话! 得分:0 原谅值:20/100 User: 在我心里你永远是最美的! Assistant: (微笑)哼,我怎么知道你说的是不是真的? 得分:+10 原谅值:30/100 ... 恭喜你通关了,你的女朋友已经原谅你了! 新建会话可以重新开始游戏 <生成图片> ### Example 3,没有提供对象生气原因,随机生成 User: 你好! Assistant: 挑战:对象吃胖了,你想和她一起减肥 ᕙ(`▿´)ᕗ,然后就生气了 请回复让她开心的话! 得分:0 原谅值:20/100

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
1.3、Prompt 调优
找到好的 prompt 是个持续迭代的过程,需要不断调优。
如果知道训练数据是怎样的,参考训练数据来构造 prompt 是最好的。「当人看」类比:
- 你知道 ta 爱读红楼梦,就和 ta 聊红楼梦
- 你知道 ta 十年老阿里,就多说阿里黑话
- 你知道 ta 是日漫迷,就夸 ta 卡哇伊
不知道训练数据怎么办?
- 看 Ta 是否主动告诉你。例如:
- OpenAI GPT 对 Markdown 格式友好
- OpenAI 官方出了 Prompt Engineering 教程,并提供了一些示例
- Claude 对 XML 友好。
- 只能不断试了。有时一字之差,对生成概率的影响都可能是很大的,也可能毫无影响……
「试」是常用方法,确实有运气因素,所以「门槛低、 天花板高」。
高质量 prompt 核心要点:
**划重点:**具体、丰富、少歧义
二、Prompt 的典型构成
不要固守「模版」。模版的价值是提醒我们别漏掉什么,而不是必须遵守模版才行。
- 角色:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学老师」
- 指示:对任务进行描述
- 上下文:给出与任务相关的其它背景信息(尤其在多轮交互中)
- 例子:必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 in-context learning;实践证明其对输出正确性有很大帮助
- 输入:任务的输入信息;在提示词中明确的标识出输入
- 输出:输出的格式描述,以便后继模块自动解析模型的输出结果,比如(JSON、XML
2.1、「定义角色」为什么有效?
大模型对 prompt 开头和结尾的内容更敏感
先定义角色,其实就是在开头把问题域收窄,减少二义性。
2.2、推荐流量包的智能客服
某运营商的流量包产品:
| 名称 | 流量(G/月) | 价格(元/月) | 适用人群 |
|---|---|---|---|
| 经济套餐 | 10 | 50 | 无限制 |
| 畅游套餐 | 100 | 180 | 无限制 |
| 无限套餐 | 1000 | 300 | 无限制 |
| 校园套餐 | 200 | 150 | 在校生 |
需求:智能客服根据用户的咨询,推荐最适合的流量包。
2.3、对话系统的基本模块和思路
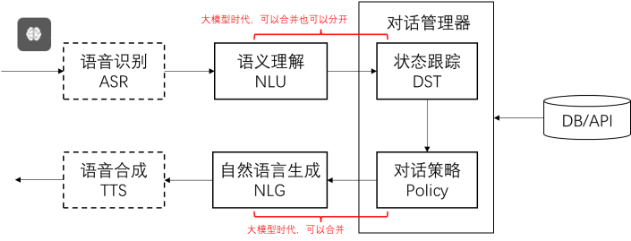
对话流程举例:
| 对话轮次 | 用户提问 | NLU | DST | Policy | NLG |
|---|---|---|---|---|---|
| 1 | 流量大的套餐有什么 | sort_descend=data | sort_descend=data | inform(name=无限套餐) | 我们现有无限套餐,流量不限量,每月 300 元 |
| 2 | 月费 200 以下的有什么 | price<200 | sort_descend=data price<200 | inform(name=劲爽套餐) | 推荐劲爽套餐,流量 100G,月费 180 元 |
| 3 | 算了,要最便宜的 | sort_ascend=price | sort_ascend=price | inform(name=经济套餐) | 最便宜的是经济套餐,每月 50 元,10G 流量 |
| 4 | 有什么优惠吗 | request(discount) | request(discount) | confirm(status=优惠大) | 您是在找优惠吗 |
核心思路:
- 把输入的自然语言对话,转成结构化的表示
- 从结构化的表示,生成策略
- 把策略转成自然语言输出
2.4、用 Prompt 实现
用逐步调优的方式实现。先搭建基本运行环境。
# 导入依赖库 from openai import OpenAI from dotenv import load_dotenv, find_dotenv # 加载 .env 文件中定义的环境变量 _ = load_dotenv(find_dotenv()) # 初始化 OpenAI 客户端 client = OpenAI() # 默认使用环境变量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL # 基于 prompt 生成文本 # 默认使用 gpt-3.5-turbo 模型 def get_completion(prompt, response_format="text", model="gpt-3.5-turbo"): messages = [{"role": "user", "content": prompt}] # 将 prompt 作为用户输入 response = client.chat.completions.create( model=model, messages=messages, temperature=0, # 模型输出的随机性,0 表示随机性最小 # 返回消息的格式,text 或 json_object response_format={"type": response_format}, ) return response.choices[0].message.content # 返回模型生成的文本 # 任务描述 instruction = """ 你的任务是识别用户对手机流量套餐产品的选择条件。 每种流量套餐产品包含三个属性:名称,月费价格,月流量。 根据用户输入,识别用户在上述三种属性上的需求是什么。 """ # 用户输入 # input_text = "办个100G以上的套餐" # input_text = "有没有便宜的套餐" # 这条不尽如人意 input_text = "有没有土豪套餐" # 输出格式增加了各种定义、约束 output_format = """ 以JSON格式输出。 1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null; 2. price字段的取值为一个结构体 或 null,包含两个字段: (1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于) (2) value, int类型 3. data字段的取值为取值为一个结构体 或 null,包含两个字段: (1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于) (2) value, int类型或string类型,string类型只能是'无上限' 4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体: (1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段 (2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段 只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段,不输出值为null的字段。 """ examples = """ 便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}} 有没有不限流量的:{"data":{"operator":"==","value":"无上限"}} 流量大的:{"sort":{"ordering"="descend","value"="data"}} 100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}} 月费不超过200的:{"price":{"operator":"<=","value":200}} 就要月费180那个套餐:{"price":{"operator":"==","value":180}} 经济套餐:{"name":"经济套餐"} 土豪套餐:{"name":"无限套餐"} """ ###################################################################################################### ######################################################################################################## # prompt 模版。instruction 和 input_text 会被替换为上面的内容 prompt = f""" {instruction} {output_format} 例如: {examples} 用户输入: {input_text} """ # 调用大模型 response = get_completion(prompt) print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
划重点:「给例子」很常用,效果特别好
改变习惯,优先用 Prompt 解决问题
用好 prompt 可以减轻后续处理的工作量和复杂度。
**划重点:**一切问题先尝试用 prompt 解决,往往有四两拨千斤的效果
2.4.2、支持多轮对话 DST
把多轮对话的过程放到 prompt 里,就支持多轮对话了。
instruction = """ 你的任务是识别用户对手机流量套餐产品的选择条件。 每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。 根据对话上下文,识别用户在上述三种属性上的需求是什么。识别结果要包含整个对话的信息。 """ # 输出描述 output_format = """ 以JSON格式输出。 1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null; 2. price字段的取值为一个结构体 或 null,包含两个字段: (1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于) (2) value, int类型 3. data字段的取值为取值为一个结构体 或 null,包含两个字段: (1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于) (2) value, int类型或string类型,string类型只能是'无上限' 4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体: (1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段 (2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段 只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。不要输出值为null的字段。 """ # 多轮对话的例子 examples = """ 客服:有什么可以帮您 用户:100G套餐有什么 {"data":{"operator":">=","value":100}} 客服:有什么可以帮您 用户:100G套餐有什么 客服:我们现在有无限套餐,不限流量,月费300元 用户:太贵了,有200元以内的不 {"data":{"operator":">=","value":100},"price":{"operator":"<=","value":200}} 客服:有什么可以帮您 用户:便宜的套餐有什么 客服:我们现在有经济套餐,每月50元,10G流量 用户:100G以上的有什么 {"data":{"operator":">=","value":100},"sort":{"ordering"="ascend","value"="price"}} 客服:有什么可以帮您 用户:100G以上的套餐有什么 客服:我们现在有畅游套餐,流量100G,月费180元 用户:流量最多的呢 {"sort":{"ordering"="descend","value"="data"},"data":{"operator":">=","value":100}} """ input_text = "哪个便宜" # input_text = "无限量哪个多少钱" # input_text = "流量最大的多少钱" # 多轮对话上下文 context = f""" 客服:有什么可以帮您 用户:有什么100G以上的套餐推荐 客服:我们有畅游套餐和无限套餐,您有什么价格倾向吗 用户:{input_text} """ prompt = f""" {instruction} {output_format} {examples} {context} """ response = get_completion(prompt, response_format="json_object") print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
2.4.4、纯用 OpenAI API 实现完整功能
import json from openai import OpenAI from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # 一个辅助函数,只为演示方便。不重要 def print_json(data): """ 打印参数。如果参数是有结构的(如字典或列表),则以格式化的 JSON 形式打印; 否则,直接打印该值。 """ if hasattr(data, 'model_dump_json'): data = json.loads(data.model_dump_json()) if (isinstance(data, (list, dict))): print(json.dumps( data, indent=4, ensure_ascii=False )) else: print(data) client = OpenAI() # 定义消息历史。先加入 system 消息,里面放入对话内容以外的 prompt messages = [ { "role": "system", "content": """ 你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括: 经济套餐,月费50元,10G流量; 畅游套餐,月费180元,100G流量; 无限套餐,月费300元,1000G流量; 校园套餐,月费150元,200G流量,仅限在校生。 """ } ] def get_completion(prompt, model="gpt-3.5-turbo"): # 把用户输入加入消息历史 messages.append({"role": "user", "content": prompt}) response = client.chat.completions.create( model=model, messages=messages, temperature=0.7, ) msg = response.choices[0].message.content # 把模型生成的回复加入消息历史。很重要,否则下次调用模型时,模型不知道上下文 messages.append({"role": "assistant", "content": msg}) return msg get_completion("流量最大的套餐是什么?") get_completion("多少钱?") get_completion("给我办一个") print_json(messages)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
划重点:我们发给大模型的 prompt,不会改变大模型的权重
所以:
- 多轮对话,需要每次都把对话历史带上(是的很费 token 钱)
- 和大模型对话,不会让 ta 变聪明,或变笨
- 但对话历史数据,可能会被用去训练大模型……
划重点:开发大模型应用主要纠结什么?
- 怎样能更准确?答:让更多的环节可控
- 怎样能更省钱?答:用更便宜的模型,减少 prompt 长度
- 怎样让系统简单好维护?
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/953158
推荐阅读
相关标签

