
- 1微信小程序获取手机号(Java后端)_微信小程序 getphonenumber
- 2树莓派 默认波特率_树莓派初次使用的基本配置.md
- 3图解微信小程序---scroll_view实现首页排行榜布局
- 4MarkDown编辑器在线
- 5LoRa无线通信技术介绍(一)调制技术
- 651单片机红外遥控小车_51单片机智能小车红外遥控器
- 7力扣第210题“课程表 II”
- 8经典论文复现|手把手带你复现ICCV 2017经典论文—PyraNet
- 9决策树学生成绩python_基于Python数据分析之pandas统计分析
- 10Xilinx FPGA中的基础逻辑单元--CLB/Block Memory/DSP/Transceivers/IO_fpga中的单元
机器学习实验四 ——基于距离的层次聚类_任务描述本关任务:编写一个使用层次聚类并可视化的小程序。相关知识为了完成本关
赞
踩
本关任务:
使用scipy实现自下而上的凝聚聚类并作聚类分析。
相关知识
为了完成本关任务,你需要掌握:1.层次聚类算法,2.空间和聚类分析。
层次聚类介绍
层次聚类存在两个方向或两种方法。一个是自下而上,另一个是自上而下。对于自下而上,每个点一开始是作为一个单独的集群。接着,将两个最接近的集群合并,以形成一个两点集群。该过程将继续合并最接近的集群,直到您获得包含所有点的单个集群。自下而上又称为凝聚聚类。自上而下正好相反。它从包含所有点的单个集群开始,然后进行分割,直到每个集群都变成一个单独的点。
无论使用哪种方法,分层聚类都会针对 n 个数据点生成集群聚类树。生成集群聚类树后,可以选择一个层级来获取集群。
树状图
第二关任务中的聚类视图依赖于数据的二维性质,因此不能用于具有两个以上特征的数据集。另一种将层次聚类可视化的工具,叫树状图(dendrogram),可以用来处理多维数据集。
目前sk-learn没有直接绘制树状图的功能,但我们可以利用scipy轻松生成树状图。
树状图在底部显示数据点。然后以这些点(表示单点簇)作为叶节点绘制一棵树,每合并两个簇就添加一个新的父节点。以此类推。树状图的y轴不仅说明凝聚算法中两个簇何时合并,每个分支的长度还表示被合并的簇之间的距离。例如,上面树状图中,最长的分支是用标记为three clusters的虚线表示的三条线。它们是最长的分支,这表示从三个簇到两个簇的过程中合并了一些距离非常远的点。
连接标准
在scipy中,可以用linkage 定义连接标准,即如何计算簇间的距离。常用的选项如下:
single:取两个集合中距离最短的两个点的距离作为两个集合的距离
complete:取两个集合中距离最远的两个点的距离作为两个集合的距离
average:把两个集合中的点两两的距离全部放在一起求一个平均值
ward:所有类簇的方差和
- 1
- 2
- 3
- 4
数据集
随机生成数据点使聚类服从高斯分布
聚类函数 fcluster
在scipy中,根据linkage matrix可以用fcluster 函数得到聚类结果。任务相关主要函数参数有:
t是用来区分不同聚类的阈值,在不同的criterion条件下所设置的参数是不同的。
criterion代表了聚类判定标准,常用的有: criterion=maxclust时,参数t代表了最大的聚类的个数;criterion=distance时,参数t代表了绝对的差值,如果小于这个差值,两个数据将会被合并,当大于这个差值,两个数据将会被分开;criterion=inconsistent时,参数t应该在0-1之间波动,t越接近1代表两个数据之间的相关性越大,t越趋于0表明两个数据的相关性越小。
depth 代表了进行不一致性(inconsistent)计算的时候的最大深度,对于其他的参数是没有意义的,默认为2.
- 1
- 2
- 3
数据集
随机生成数据点使聚类服从高斯分布
编程要求
根据提示,在右侧编辑器补充代码:调用scipy库计算随机数据集的距离矩阵,用最远距离计算linkage向量并输出一个凝聚聚类的树状图。然后,用fcluster函数对数据集进行聚类并输出聚类结果。
实验代码
#encoding=utf8 import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as mpl import numpy as np from mpl_toolkits import mplot3d from scipy.spatial.distance import pdist,squareform import scipy.cluster.hierarchy as hy from scipy.cluster.hierarchy import fcluster #abc # 用于生成聚类数据的函数 def cluster(number=20, cnumber=5, csize=10): # 聚类服从高斯分布 rnum = np.random.rand(cnumber, 2) rn = rnum[:, 0]*number rn = rn.astype(int) rn[np.where(rn < 5)] = 5 rn[np.where(rn > number / 2.)] = round(number /2., 0) ra = rnum[:, 1]*2.9 ra[np.where(ra < 1.5)] = 1.5 cls = np.random.randn(number, 3)*csize # 随机设定各聚类的质点 rxyz = np.random.randn(cnumber-1, 3) for i in range(cnumber-1): tmp = np.random.randn(rn[i+1], 3) x = tmp[:, 0] + ( rxyz[i, 0] * csize ) y = tmp[:, 1] + ( rxyz[i, 1] * csize ) z = tmp[:, 2] + ( rxyz[i, 2] * csize ) tmp = np.column_stack([x, y, z]) cls = np.vstack([cls, tmp]) return cls def test(path): # 创建待聚类数据 cls = cluster() # 可视化数据 fig = mpl.figure(figsize=(8, 8)) ax = mpl.axes(projection='3d') ax.scatter3D(cls[:, 0], cls[:, 1], cls[:, 2], c='b', marker='o') fig.savefig(path + 'T4_data.png', bbox='tight') ### 根据提示补充代码 #### # 1、计算数据集cls的距离矩阵(默认计算欧式距离,可以尝试其他距离) #*****************begin************************* D=pdist(cls) M=squareform(D) #*****************end************************* # 2、用簇间最大距离向量建立连接标准Y1 #*****************begin************************* Y1=hy.linkage(M,method='complete') #abc #*****************end************************* # 3、根据linkage matrix 生成树状图 #abc fig = mpl.figure() H = hy.dendrogram(Y1) #*****************end************************* fig.savefig(path + 'T4_tree.png', bbox='tight') # 4、已知最大的聚类的个数t=5,根据Y1用fcluster得到聚类结果 #*****************begin************************* cluster_res = fcluster(Y1,t=1) #*****************end************************* # 5、可视化聚类结果并保存到'T4_cluster.png' #*****************begin************************* fig = mpl.figure() #指定窗口大小 平台运行会出错 figsize ax = mpl.axes(projection='3d') ax.scatter3D(cls[:,0],cls[:,1], cls[:,2],c=cluster_res,marker='o') #*****************end************************* fig.savefig(path + 'T4_cluster.png', bbox='tight') mpl.show() return 1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
运行截图:
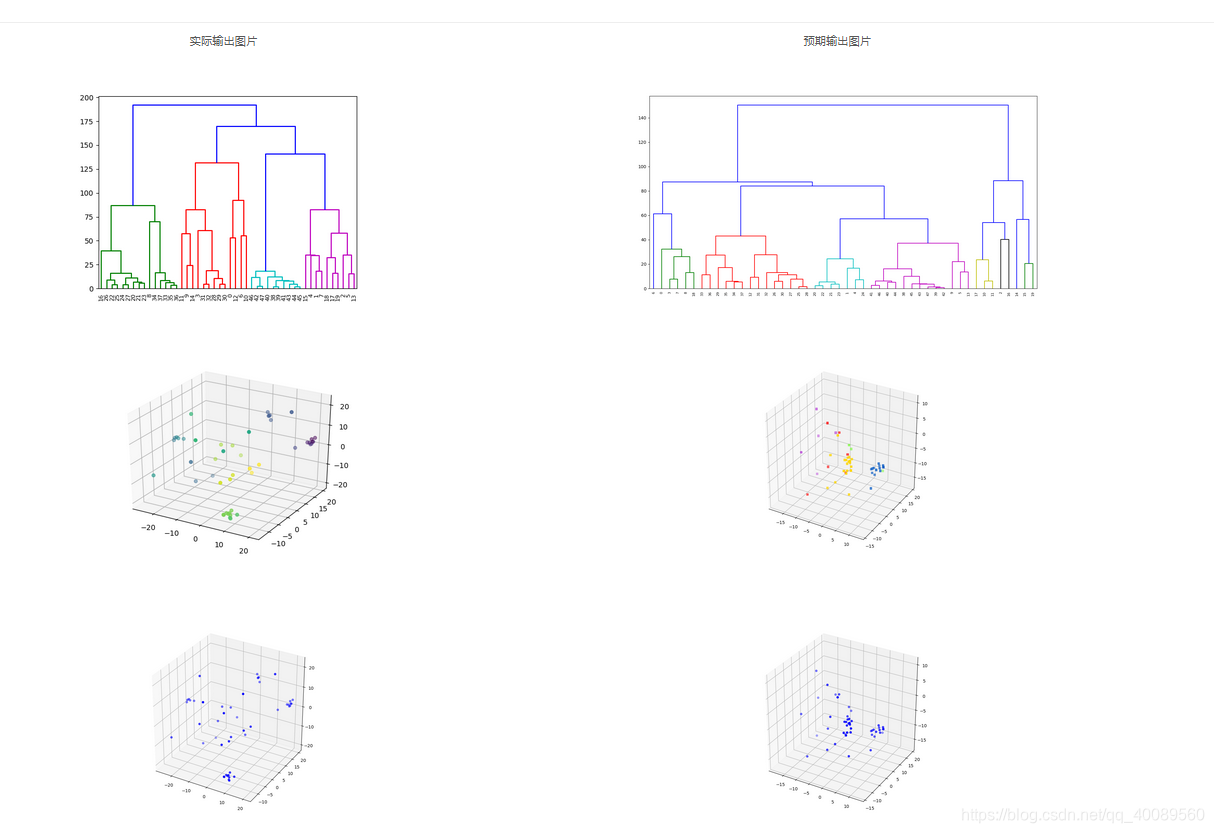
实验小结:
实验代码不难,最难搞的是在绘图的过程中出现了一个小BUG,在Educoder平台调试了好久,发现在画多个窗口的时候,即出现两个 fig = mpl.figure(figsize(8,8)) fig = mpl.figure(figsize=(10,10)) 会报这个错误“NameError: name ‘figsize’ is not defined”
感觉原因应该是在‘figsize’上面,这个一个系统变量,但由于我使用了多次,这个平台误以为这是我自定义的变量,所以报NameError。(Educoder平台报错总是指向第二个‘figsize’所在的那一行),后来,我直接去掉figsize,不指定窗口大小,代码就过了。
调试代码的神奇之处:就在于你永远无法把握下一个bug可能出现的地方,有一些神bug可能存在玄学(挠挠头,苦笑),可能平台在低内存运行下语法什么的可能会产生一些特殊的效应,具体的解释有待以后的努力学习咯。

