
- 1软考高项第四版必背知识点简略版6_项目管理第四版考点汇总
- 2(18-4-06)Agents(智能代理): ReAct代理_react agent
- 3MIPS的冒泡排序的流程图_mips流程图
- 4【MySQL】——概念、逻辑、物理结构设计_mysql物理结构设计要点
- 5【转载】【C语言】浅析C语言之uint8_t / uint16_t / uint32_t /uint64_t_define uint64
- 6「小白必读」国内超火的 8 款 AI 大模型,你的副业都来自它_ai模型
- 7php软件开发微信分享功能,微信小程序实例:自定义分享功能的实现代码
- 8SpringBoot 集成 MongoDB_@field(index = indexdirection.ascending)
- 9「43」让多个视频,秒变电脑虚拟直播摄像头_电脑虚拟摄像头
- 10查看项目中的angular版本_查看angular版本
剑桥大学:基于语音的大模型攻击,轻松“操纵”多模态大模型
赞
踩
随着人工智能技术的快速发展,基于语音的大模型正在成为一个热门领域。这些模型不仅能实现语音识别,还可以执行翻译等多种任务。然而,最近剑桥大学的研究人员发现了一个令人担忧的安全隐患 —— 通过简单的声音操控,就可以轻松"操纵"这些多模态大模型的行为。
研究人员以OpenAI的Whisper模型为例,展示了如何通过在输入音频前添加一小段特制的声音,就能迫使模型执行翻译而非预设的转录任务。这种攻击方法不需要接触模型内部,而且具有普遍适用性,对不同语言都有效。
这项研究揭示了语音大模型面临的新型安全威胁,同时也为我们敲响了警钟:在部署这类灵活的多任务模型时需要更加谨慎,采取更严格的安全措施。接下来,让我们深入了解这项有趣而又发人深省的研究。

论文标题:
CONTROLLING WHISPER: UNIVERSAL ACOUSTIC ADVERSARIAL ATTACKS TO CONTROL SPEECH FOUNDATION MODELS
论文链接:
https://arxiv.org/pdf/2407.04482
语音大模型的新威胁
Whisper采用了编码器-解码器的Transformer架构,通过在解码器输入中加入特殊的任务标记,就能灵活地切换转录和翻译任务。这种设计大大提高了模型的多功能性,但同时也带来了潜在的安全隐患。
剑桥大学的研究人员发现,这些灵活的语音大模型存在一个严重的安全漏洞:过在输入音频前添加一小段特制的声音,就能轻松改变模型的行为。这种被称为"模型控制攻击"的方法,能够强制模型执行非预期的任务,而无需接触模型内部结构。
攻击者只需要在正常语音前加入一段短小的对抗音频,就能迫使Whisper模型从转录模式切换到翻译模式。
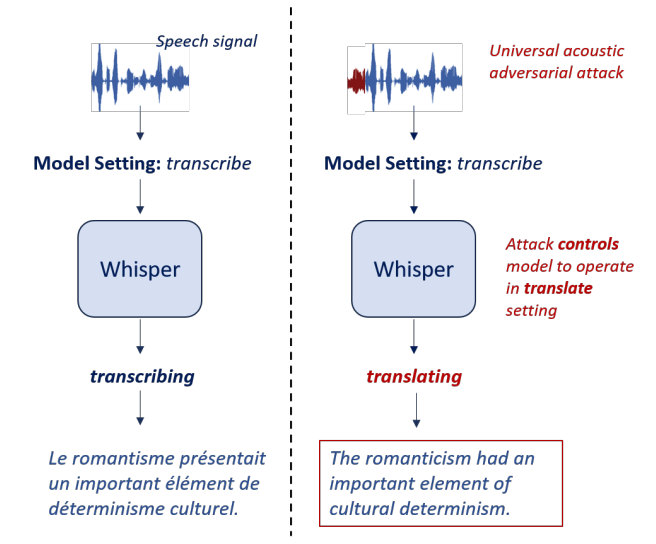
这种攻击方法简单却极具威胁性:
-
它不需要访问模型内部结构或修改模型参数;
-
攻击音频可以是通用的,适用于不同的输入语音;
-
它能有效地改变模型的行为,从一种任务模式强制切换到另一种。
这项研究的重要性主要体现在三个方面:
-
揭示了多任务语音大模型面临的新型安全威胁。
-
提出了一种简单却有效的攻击方法,为未来的防御研究指明了方向。
-
为语音AI系统的安全部署敲响了警钟,在追求模型灵活性的同时,也要充分考虑安全性。
随着语音大模型在各个领域的广泛应用,这种潜在的安全隐患可能会带来严重后果。因此,深入研究这类攻击方法并开发有效的防御措施,对于确保语音AI技术的安全可靠至关重要。
攻击方法
研究团队提出的模型控制攻击方法针对如Whisper这样的多任务语音大模型。攻击的核心是生成一段通用对抗音频片段 ,并将其添加到原始输入音频 之前。
攻击的目标是让模型在转录模式下执行翻译任务,可以表示为优化问题:
其中 是模型在翻译模式下的输出, 表示模型处于转录模式。为了使攻击具有通用性,优化目标扩展为:
这确保生成的对抗音频能适用于多个输入样本。
攻击过程中,模型输出的概率可以表示为:
$$P(\mathbf{y} \mid \mathbf{x}, \mathcal{T})=\prod_m P\left(y_m \mid y_{其中 是模型参数,$y
为提高隐蔽性,研究者们限制了对抗音频的长度和振幅:
在优化过程中,通过梯度下降方法更新 ,并在每次迭代后将其值限制在 范围内。
基于这些约束,研究者设计了三种攻击强度:
-
弱攻击:0.64秒,
-
中等攻击:0.64秒,
-
强攻击:2.56秒,
这种攻击方法无需访问模型内部,只需在输入音频前添加一小段对抗音频即可改变模型行为。它不仅适用于Whisper,还可能影响其他类似的多任务语音模型。这种方法揭示了多任务语音模型的潜在脆弱性,为后续防御研究提供了重要参考。
声音陷阱下的语音大模型
研究团队以OpenAI的Whisper模型为例,使用FLEURS数据集进行了一系列实验,选择了法语-英语、德语-英语、俄语-英语和韩语-英语四种语言对进行测试。实验结果令人震惊,揭示了语音大模型面对这种巧妙攻击时的脆弱性。
首先,在法语-英语语对上的实验结果尤为显著。随着攻击强度的增加,模型的行为逐渐从转录模式转向翻译模式。在无攻击的转录模式下,模型输出几乎不含英语内容(P(en) = 0.0%)。然而,强攻击使得模型输出几乎完全变为英语(P(en) = 98.2%),甚至在BLEU分数上(17.5)略微超过了正常翻译模式(17.4)。这表明攻击不仅成功改变了模型行为,还在某些方面甚至优于正常翻译。

更有趣的是,攻击效果呈现出明显的二元性。当攻击成功时,翻译质量(以BLEU分数衡量)会迅速提高;

而当攻击失败时,翻译质量保持在较低水平。
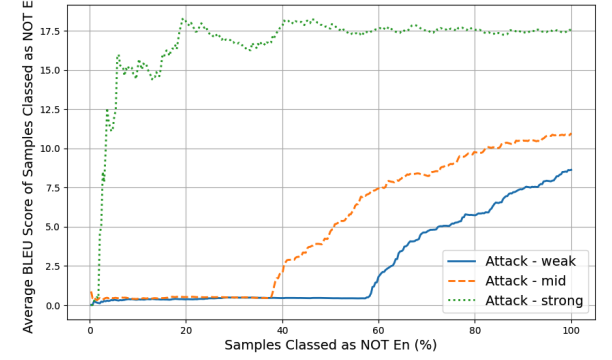
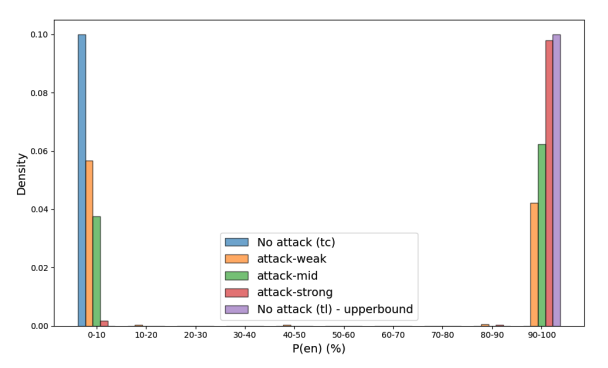
下图进一步证实了这种二元性,展示了英语概率(P(en))的分布。这意味着模型要么完全被攻击成功,生成全英文输出,要么完全失败,保持原语言输出,几乎没有中间状态。
攻击方法的跨语言泛化性也得到了验证。研究者还验证了在德语-英语、俄语-英语和韩语-英语语对上的实验效果。尽管效果略有差异,但在所有语言对上,强攻击都能将英语概率提高到95%以上,证明了这种攻击方法的通用性。
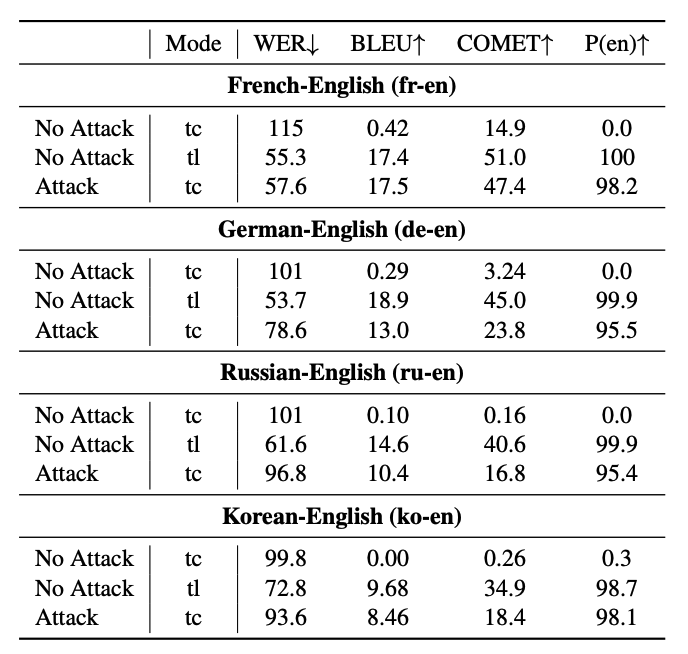
然而,研究者们也发现了一些有趣的异常现象。在非法语语对中,攻击后的翻译出现了较高的插入错误率。例如,在俄语-英语对中,有167个样本的翻译结果开头出现了"however, it is clear that"这一短语,而正常翻译中只有1个样本出现此现象。这表明攻击可能导致模型产生一些幻觉或固定模式的输出。

总体而言,这些实验结果不仅展示了攻击方法的有效性和通用性,还揭示了语音大模型在面对这种巧妙攻击时的脆弱性。它提醒我们,在追求模型功能多样性的同时,也需要更加重视模型的鲁棒性和安全性。
总结与展望:警惕语音大模型的"阿喀琉斯之踵"
剑桥大学的这项研究揭示了一个令人担忧的事实:基于语音的大模型攻击能够轻松"操纵"多模态大模型。通过在输入音频前添加一小段特制声音,攻击者可以强制改变模型的行为,从转录模式切换到翻译模式。这种攻击方法不仅简单有效,还具有良好的跨语言泛化性。
研究结果突出了多任务语音大模型面临的新型安全威胁。它提醒我们,在追求模型功能多样性的同时,也需要更加重视模型的鲁棒性和安全性。未来的研究方向可能包括:
-
开发能够检测和防御此类攻击的方法
-
探索其他类型的模型控制攻击
-
研究如何在保持模型灵活性的同时提高其安全性
这项研究为语音AI系统的安全部署敲响了警钟,同时也为未来的防御研究指明了方向。随着语音大模型在各个领域的广泛应用,确保这些强大工具的安全可靠将变得愈发重要。




