
- 1如何让一些文件的更改不同步到远程仓库但是在远程仓库保留_git想要在远程仓库但是不跟踪变化
- 2自定义React Native的RadioButton和RadioGroup(单选按钮)_react native 单选框
- 3Python学习_python中键盘输入的+号是字符串么
- 4解决高版本问题Cannot resolve org.springframework.cloud:spring-cloud-starter-bootstrap:unknown
- 5Linux 查看系统日志命令_btmp begins
- 6【重磅开源】MapleBoot线上demo环境初体验
- 7CVPR2017-如何在无标签数据集上训练模型_深度学习没有标签怎么训练?
- 8洞悉安全现状,建设网络安全防护新体系
- 9Linux基础命令-cp拷贝文件_linux cp命令复制文件夹
- 10git相关操作(一) —— git工作区域&基本信息设置&初始化init & git本地操作 & git分支管理_git工作目录
基于深度学习的目标图像检测【Yolov8】_yolov8目标检测流程图
赞
踩
研究工作
一、Yolo算法原理及流程
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2015年提出的基于单个神经网络的目标检测系统。在2017年CVPR上,Joseph Redmon和Ali Farhadi又发表的YOLO 2,进一步提高了检测的精度和速度。
图 1 yolo算法的网络结构
Yolo算法的核心思想:利用整张图片作为网格的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。
每一个bounding box要预测(x, y, w, h)和confidence共5个值
每个网格还要预测一个类别信息,记为C类
下述流程图是yolov8算法的流程:
 整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如下图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如下图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。

上图2为Yolo检测系统原理
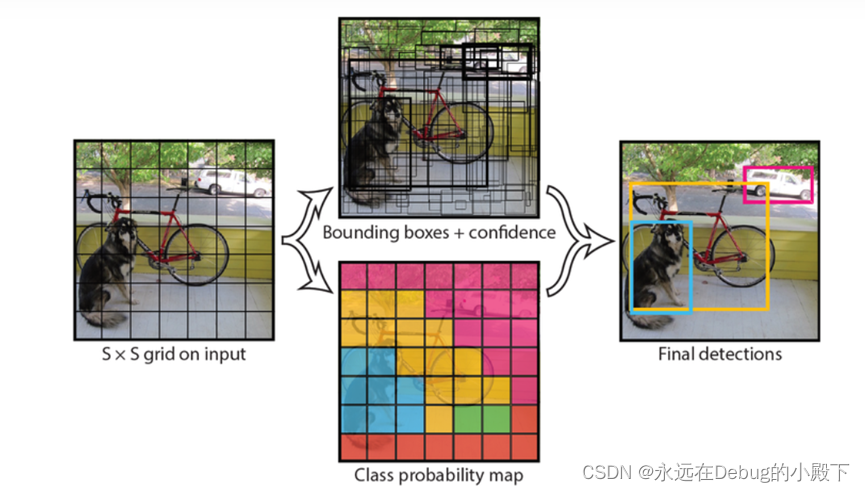
图 3模型预测值结构
二、建立Python虚拟运行环境
C:\Users\yonghu\Desktop>python -m venv yolo8三、安装yolo
用pip install ultralytics的方法安装yolov8

 在这里需要等待一段时间。
在这里需要等待一段时间。
四、使用labelImg进行图片标注
4.1安装labelImg
使用pip install labelimg的方法安装。

4.2对图片格式的统一
在下载之后,可能会碰到一些情况,比如测试数据【图片】格式不统一,这个时候需要进行以下统一,但是面对上百张照片,如果一张张改格式实在是太麻烦了,所以这里有一个小tips,使用
dir
ren *.jpg *.jpeg
进行图像格式的转换
- (yolo8) C:\Users\34025\Desktop\yolo8\data\images>dir
- (yolo8) C:\Users\34025\Desktop\yolo8\data\images>ren *.jpg *.jpeg
上图为案例测试。
4.3对图片进行标注
标注样例:
首先启动labelimg:


在此处进行图像标注
五、准备训练模型
5.1在官网下载相关预训练模型
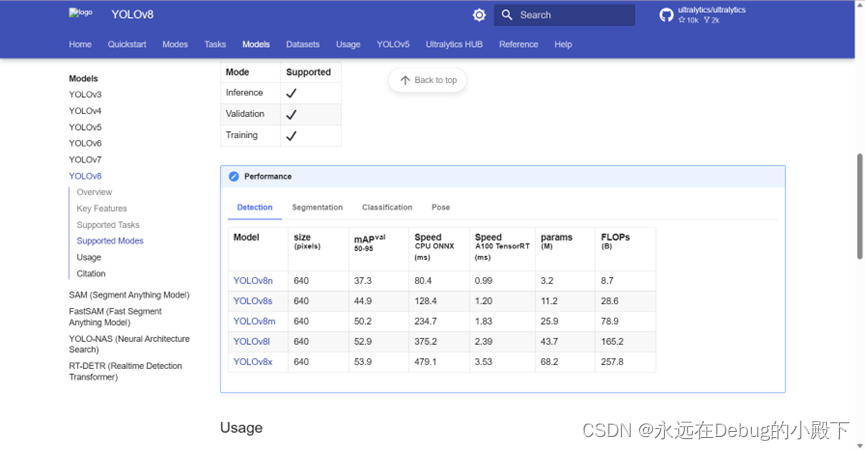
官网上关于yolo的训练模型种类繁多,下表为官方在 COCO Val 2017 数据集上测试的 mAP、参数量和 FLOPs 结果。可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少。
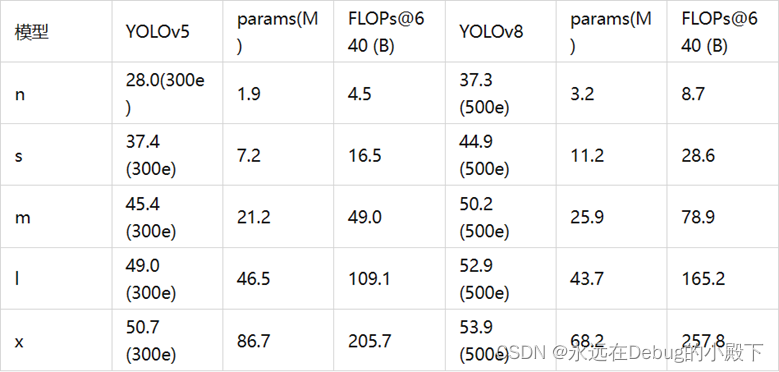
表 1YoloV5和YoloV8的对比
5.2进入yolo并展开训练
第一次训练时,考虑到图片工作量较大,因此应用的训练数据集与测试数据集相同。训练的数据集选用的是三千张图片,并将每一张照片通过labelImg进行标注。再通过yolo模型进行训练。
Yolo官网提出了yolov8n、yolov8s、yolov8m、yolov8l、yolov8x等五种模型,考虑到机器学习所需要的时间以及设备性能等方面的原因,在本次研究中研究这五个模型并分别考虑其训练数据集与测试数据集相同与不同的两种情况并做出对比。
环境配置:
i7-12700F + 1660Super + 32G
i5-12490F + 4070Ti + 32G
我是直接在终端上进入模型,开始训练的,代码在cmd上操作
- //对30张照片数据集的训练—仅做测试
- (yolo8)C:\Users\34025\Desktop\yolo8\data>yolo task=detect mode=train model=yolov8n.pt data=data.yaml epochs=1000
- //使用yolov8n进行预训练,训练1000次
-
- //对3000张照片数据集的训练-- yolov8n,记作train_n
- (yolo8)C:\Users\34025\Desktop\yolo8\data3000>yolo task=detect mode=train model=yolov8n.pt data=data.yaml epochs=1000
- //使用yolov8n进行预训练,训练1000次
-
-
参数解释:
TASK(可选) 是[detect、segment、classification]中的一个。如果没有显式传递,YOLOv8将尝试从模型类型中猜测TASK。
分类(classification)、检测(dection)、分割(segmentation)
MODE(必选) 是[train, val, predict, export]中的一个 (训练、评估、预测、导出)
ARGS(可选) 是任意数量的自定义arg=value对,如imgsz=320,覆盖默认值。

预训练模型内容示意:
- //train_xv中args.yaml代码
- task: detect
- mode: train
- model: runs/detect/train_x/weights/best.pt
- data: data.yaml
- epochs: 1000
- patience: 50
- batch: 8
- imgsz: 640
- save: true
- save_period: -1
- cache: false
- device: null
- workers: 8
- project: null
- name: null
- exist_ok: false
- pretrained: true
- optimizer: auto
- verbose: true
- seed: 0
- deterministic: true
- single_cls: false
- rect: false
- cos_lr: false
- close_mosaic: 10
- resume: false
- amp: true
- fraction: 1.0
- profile: false
- overlap_mask: true
- mask_ratio: 4
- dropout: 0.0
- val: true
- split: val
- save_json: false
- save_hybrid: false
- conf: null
- iou: 0.7
- max_det: 300
- half: false
- dnn: false
- plots: true
- source: null
- show: false
- save_txt: false
- save_conf: false
- save_crop: false
- show_labels: true
- show_conf: true
- vid_stride: 1
- line_width: null
- visualize: false
- augment: false
- agnostic_nms: false
- classes: null
- retina_masks: false
- boxes: true
- format: torchscript
- keras: false
- optimize: false
- int8: false
- dynamic: false
- simplify: false
- opset: null
- workspace: 4
- nms: false
- lr0: 0.01
- lrf: 0.01
- momentum: 0.937
- weight_decay: 0.0005
- warmup_epochs: 3.0
- warmup_momentum: 0.8
- warmup_bias_lr: 0.1
- box: 7.5
- cls: 0.5
- dfl: 1.5
- pose: 12.0
- kobj: 1.0
- label_smoothing: 0.0
- nbs: 64
- hsv_h: 0.015
- hsv_s: 0.7
- hsv_v: 0.4
- degrees: 0.0
- translate: 0.1
- scale: 0.5
- shear: 0.0
- perspective: 0.0
- flipud: 0.0
- fliplr: 0.5
- mosaic: 1.0
- mixup: 0.0
- copy_paste: 0.0
- cfg: null
- v5loader: false
- tracker: botsort.yaml
- save_dir: runs\detect\train18

5.3得到完成训练的模型

5.4 Yolo模型的停止训练的条件
- 达到指定训练次数
- 未达到指定训练次数但是训练结果检测达到预期(0.99)
- 连续五十次迭代寻找不到更好的训练结果,持续低识别度
5.5测试训练效果
- // train_n
- (yolo8) C:\Users\34025\Desktop\yolo8>cd data
- (yolo8) C:\Users\34025\Desktop\yolo8\data3000>yolo task=detect mode=predict model=../data/runs/detect/train_n/weights/best.pt conf=0.1 source=..\data\test
- // Results saved to runs\detect\predict

结果储存的文件夹如下所示:

将会在最后进行集中不同模型的识别准确率对比。
六、YOLO-V8训练结果的对比
在本次研究中,我分别下载了yolov8n、yolov8s、yolov8m、yolov8l、yolov8x这五个模型,并将每一个模型都进行了两种不同的实验:训练集与测试集相同、训练集与测试集不同。在理论上应该是后者的准确度更好,接下来将根据实验结果对其进行比较。
在本次实验中,分别命名为:train_n、train_nv、train_s、train_sv、train_m、train_mv、train_l、train_lv、train_x、train_xv
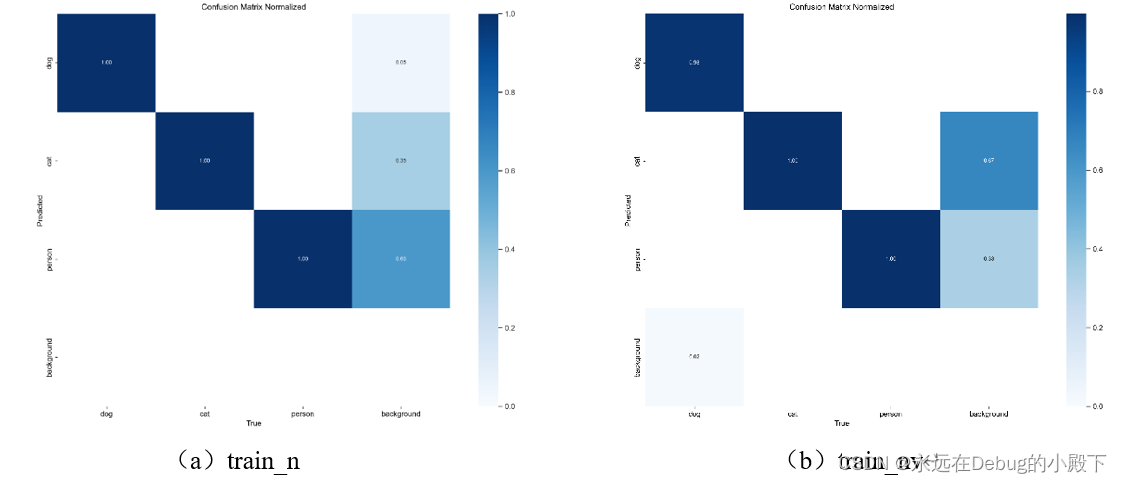
6.1 confusion_matrix混淆矩阵归一化

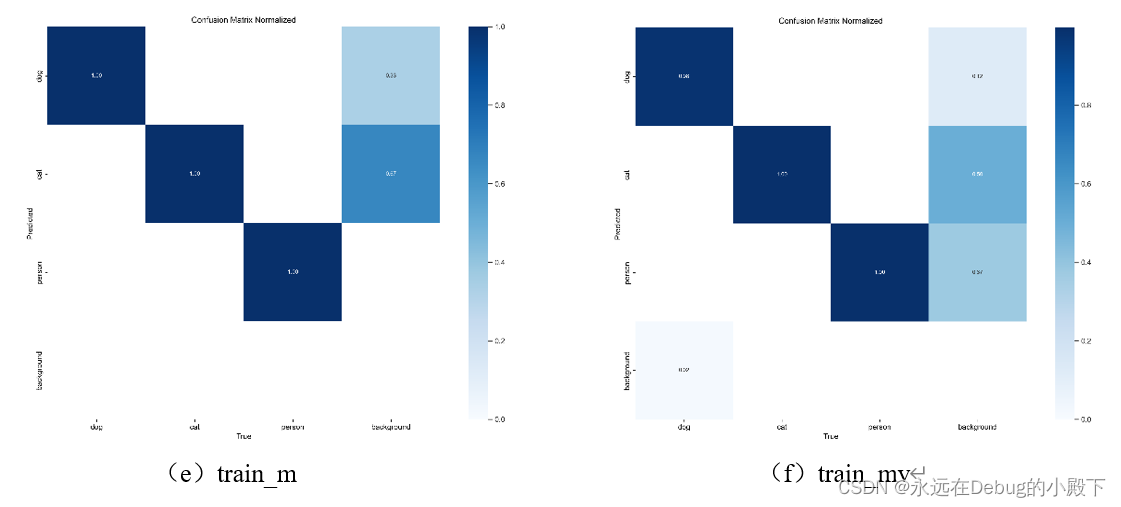
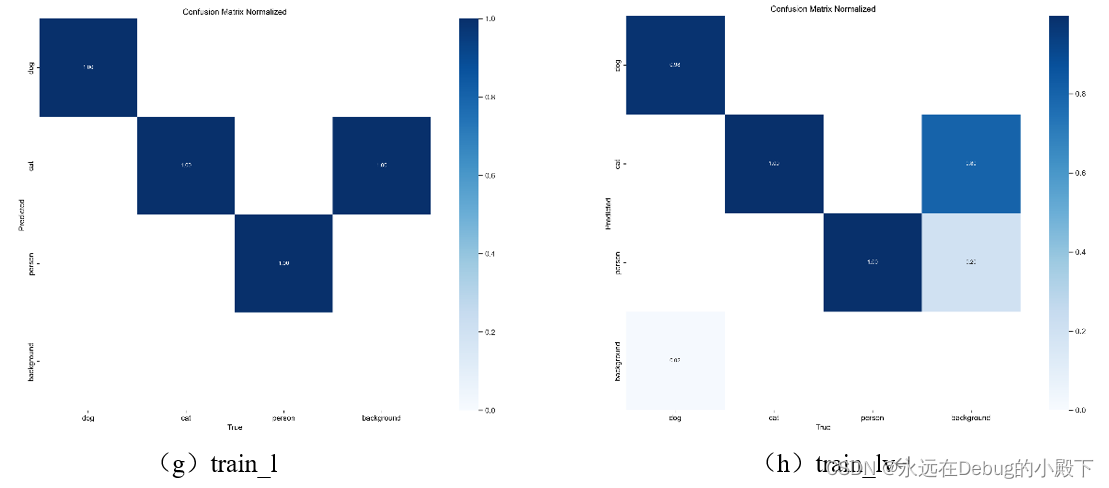
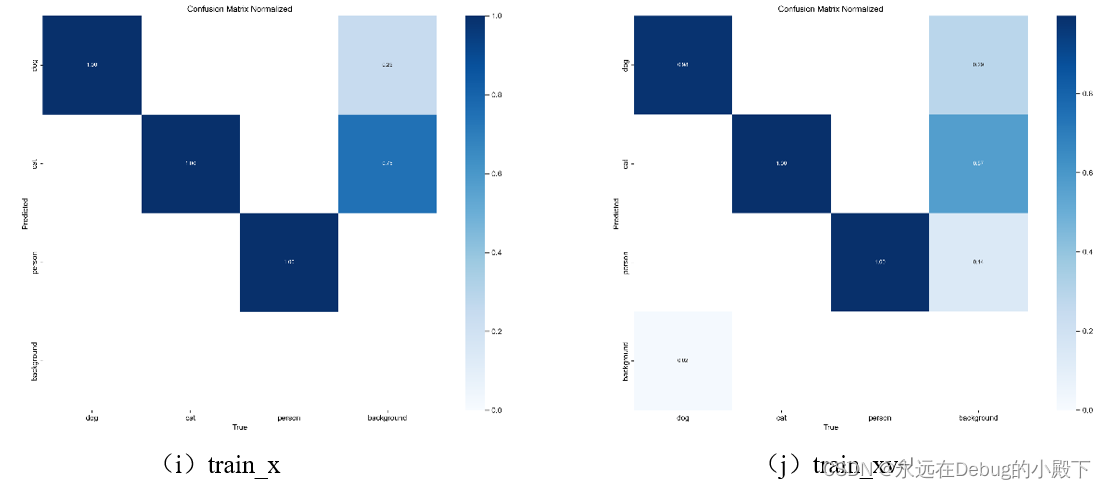
对于混淆矩阵,当数据主要存在于对角线上时,反映出更高的识别准确率。对于图a、图c、图e、图g、图i而言,由于其测试数据集与训练集相同,因此会有更明显的斜对角线,在测试准确率方面会高于测试数据集与训练集不同的的组b、d、f、h、j。
综合来看,效果最好的模型是yolov8x。但其差异较小,还需要更详细的比较。
6.2 P_curve
precision(单一类准确率) : 预测为positive的准确率。

