
- 1maven scope 的作用_maven scope作用
- 2如何通过内网穿透实现无公网IP远程访问内网的Linux宝塔面板_linux无公网ip远程
- 3Navicat 无限适用
- 4elasticsearch中创建索引模板_index_template_elasticsearch 创建索引模板
- 5高级前端开发工程师的爬虫实战指南_前端爬虫
- 6【数据结构】三万字图文讲解带你手撕八大排序(附源码)
- 7ISO 26262功能安全标准体系解读(上)_iso26262
- 8词嵌入(word embedding)(pytorch)
- 9AI绘画入门实践|Midjourney:使用 --no 去除不想要的物体
- 10前后端性能测试的指标_性能测试指标有哪些
Python数据分析与程序设计(五):Matplotlib数据可视化_某农业学校python(七)第3题:matplotlib数据可视化 (1)利用numpy和panda
赞
踩
一、前言
欢迎阅读《Python数据分析与程序设计》系列的第五篇博客——“Matplotlib数据可视化”。在前面的系列博客中,我们深入探讨了Python数据分析的两大基石:NumPy和Pandas。通过这些博客,我们学习了如何使用NumPy进行高效的数值计算,以及如何利用Pandas进行灵活的数据处理和清洗。
在本篇博客中,我们将把焦点转向数据的另一关键方面——数据可视化。数据可视化是理解数据和传达分析结果的有效手段。通过将数据以图形的形式展现出来,我们可以更容易地识别趋势、模式和异常值。而Matplotlib正是Python中实现数据可视化的一个强大库。
在接下来的文章中,我们将介绍我们如何使用Matplotlib绘制常见的图表类型,例如线图、散点图、柱状图和饼图等,让图表更加专业和个性化。
二、导入相应的包和正确设置
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置支持中文的字体
- plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
三、绘制点和线,并设置样式
- # 创建一个大小为 10x8 英寸的图形
- plt.figure(figsize=(10, 8))
-
- # 绘制单点 plt.scatter(x,y)
- plt.scatter(4,6,color = 'blue')
-
- # 绘制单线 plt.plot(x列表,y列表)
- plt.plot((1,1),(2,3),color = 'red',linewidth = 3,linestyle = '--')
-
- # 添加文字说明 plt.text(x,y,text)
- plt.text(1.2,3,'文字说明',fontdict={'size':16,'color':'b'})
-
- # 都可以自由设置样式
-
- # 每次完成绘图都要显示图像
- plt.show()
四、使用figure绘制多图
- # (1)使用figure绘制多图
- # 一个figure代表一张图;
- # 上面的例子,直接调用scatter(),默认为用户创建了一张图figure;如果要定制图的属性,比如:大小,就要显示的创建一个figure;
- # plt.figure()用于创建一张图,之后的图元都在这张图上;
- # 创建第一张图并绘制一个散点
- plt.figure()
- plt.scatter(1, 1)
- plt.show() # 显示第一张图
-
- # 创建第二张图并绘制一条线段
- plt.figure()
- x1 = np.array([1, 3])
- y1 = np.array([2, 4])
- plt.plot(x1, y1, color='red', linewidth=3, linestyle='--')
- plt.show() # 显示第二张图
五、使用subplot绘制多图
- x1 = np.array([1, 3])
- y1 = np.array([2, 4])
-
- # 创建1行3列的子图集 选定第1个子图
- plt.subplot(1,3,1)
- plt.plot(x1, y1, color='red', linewidth=3, linestyle='--')
-
- # 在这个1行3列的子图集上 选定第3个子图
- plt.subplot(1,3,3)
- plt.plot(x1, y1, color='red', linewidth=3, linestyle='--')
-
- # 可以再次索引 添加图像内容
- plt.subplot(1,3,1)
- plt.scatter(1,2)
-
- plt.show()
一个figure是一张图,多个figure就是多张图;而多个subplot是一张图,使用subplot可以控制多图的布局。
六、设置坐标
1.坐标刻度
- # case1 数值是数值 但坐标是符号
- plt.xticks([1,2,3,4,5,6],['a','b','c','d','e','f'])
- plt.yticks([1,2,3,4,5,6],['差','普通','好','很好','特别好','666'])
- plt.scatter(3,5)
- # 设置x轴和y轴的显示范围
- plt.xlim(0,6)
- plt.ylim(0,6)
- # 如果您想要特别强调原点,可以通过添加一个特殊的标记或者在原点处绘制一个特殊的图形元素来实现。
- # 例如,您可以使用plt.plot函数在原点处绘制一个点:
- plt.scatter(0, 0,color = 'blue') # 在原点 (0, 0) 处绘制一个蓝色的圆点
- plt.show()
- # case2: 数据就是符号
- x = ['hhh','hh','h']
- y = [100,300,200] # 当全是数字时,坐标轴就会按照数值从小到大有序排序
- # 当然数据也可以是数值+字符串
- plt.plot(x,y)
- plt.scatter('hh',175)
- plt.show()
2.设置坐标说明
- # fontsize是一个关键字参数,用于指定标签文本的字体大小
- plt.xlabel('xxx',fontsize = 15)
- plt.ylabel('yyy',fontsize = 20, rotation=45)
- plt.show()
七、设置图例
前提是要设置了label
- # 绘制两条线,并为每条线指定一个标签
- plt.plot([1, 2, 3], label='Line 1')
- plt.plot([2, 3, 4], label='Line 2')
-
- # 添加图例,并将其放置在图形的右下角
- plt.legend(loc='lower right')
-
- # 显示图形
- plt.show()
- 不同的图例位置:
-
- 'upper right':图形的右上角。
- 'upper left':图形的左上角。
- 'lower left':图形的左下角。
- 'lower right':图形的右下角。
- 'right':图形的右侧。
- 'left':图形的左侧。
- 'center':图形的中心。
- 'center left':图形的左侧中间位置。
- 'center right':图形的右侧中间位置。
- 'lower center':图形的底部中间位置。
- 'upper center':图形的顶部中间位置。
- 'center bottom':图形的底部中间位置。
- 'center top':图形的顶部中间位置。
八、在图中做标注(文字、箭头)
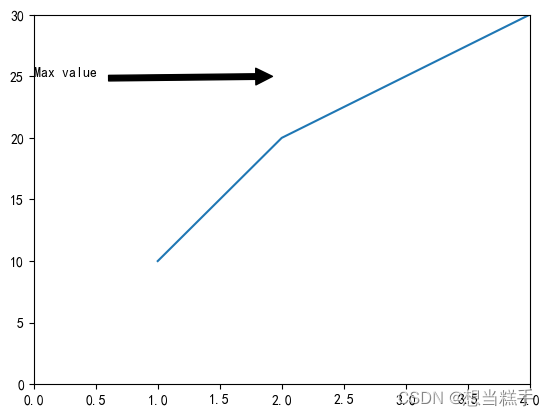
- # 创建一个简单的图表
- x = [1, 2, 3, 4]
- y = [10, 20, 25, 30]
- plt.plot(x, y)
-
- # 添加注释
- plt.annotate('Max value', xy=(2, 25), xytext=(0, 25),
- arrowprops=dict(facecolor='black', shrink=0.05))
-
- plt.xlim(0,4)
- plt.ylim(0,30)
-
- # 显示图表
- plt.show()
九、散点图
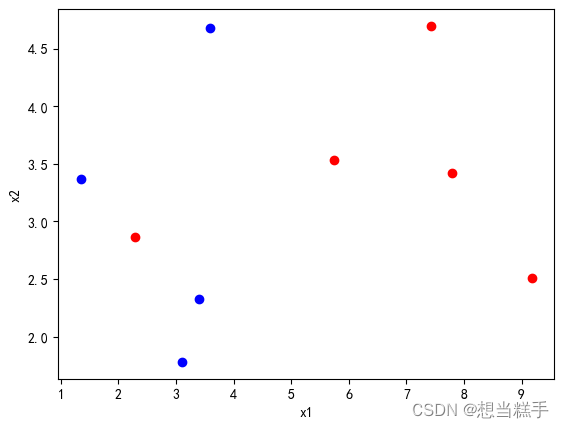
- # 定义x1和y1数据
- x1 = [
- [3.393533211, 2.331273381],
- [3.110073483, 1.781539638],
- [1.343808831, 3.368360954],
- [3.582294042, 4.679179110],
- [2.280362439, 2.866990263],
- [7.423436942, 4.696522875],
- [5.745051997, 3.533989803],
- [9.172168622, 2.511101045],
- [7.792783481, 3.424088941],
- [7.939820817, 0.791637231]
- ]
-
- y1 = [0, 0, 0, 0, 1, 1, 1, 1, 1]
-
- # 将列表转换为NumPy数组
- X_data = np.array(x1)
- y_data = np.array(y1)
-
- # 设置X轴和Y轴的标签
- plt.xlabel('x1') # x1轴坐标标签
- plt.ylabel('x2') # x2轴坐标标签
-
- # 使用np.where来获取满足条件的索引,并绘制散点图
- indices_zero = np.where(y_data == 0)[0] # 获取y_data中值为0的索引
- indices_one = np.where(y_data == 1)[0] # 获取y_data中值为1的索引
-
- plt.scatter(X_data[indices_zero, 0], X_data[indices_zero, 1], color='blue') # y=0的点用蓝色
- plt.scatter(X_data[indices_one, 0], X_data[indices_one, 1], color='red') # y=1的点用红色
-
- # 显示图表
- plt.show()
十、关于np.where的用法
- # 当 np.where 只有一个条件参数时,它返回输入数组中非零(或满足条件)元素的索引。
- # 这可以用来找出数组中满足特定条件的元素的位置。
- # 示例 1:返回满足条件的元素索引
-
- # 创建一个一维数组
- arr = np.array([1, 2, 3, 4, 5])
-
- # 找出数组中大于3的元素的索引
- indices = np.where(arr > 3)
- print(indices) # 输出:(array([3, 4]),),表示索引3和4的元素大于3
- ### 加上[0] 会返回一个列表 数组
(array([3, 4], dtype=int64),)- # 示例数组
- y_data = np.array([0, 1, 0, 1, 0])
-
- # 使用 np.where 获取值为 0 的索引
- indices = np.where(y_data == 0)
-
- # 输出结果 会返回array
- print(indices) # 输出:(array([0, 2, 4], dtype=int64),)
-
- 它会返回一个元组,其中第一个元素是一个数组,包含了所有满足条件(即元素值为 0)的索引。
-
- 当你执行 indices[0] 时,你实际上是在访问这个元组的第一个元素,
- 它是一个包含所有满足条件的索引的数组。
- 这就是为什么 indices_zero 会是一个包含索引 [0, 2, 4] 的数组
-
- # 获取索引数组
- indices_zero = indices[0]
-
- # 输出索引数组
- print(indices_zero) # 输出:[0,2,4]一个列表
- (array([0, 2, 4], dtype=int64),)
- [0 2 4]
十一、折线图:点图+线图
1.单折线图
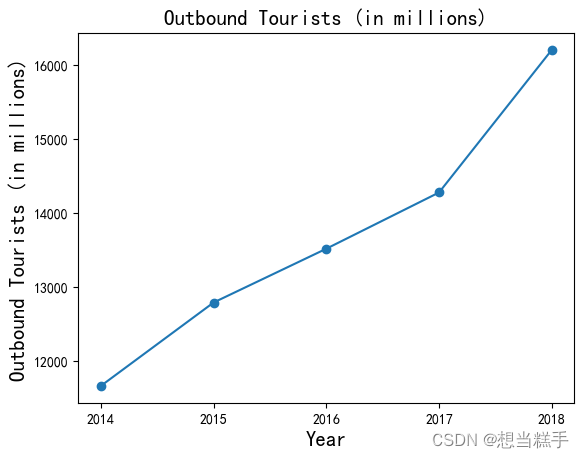
- # 定义数据
- x3_1 = np.array(['2014', '2015', '2016', '2017', '2018'])
- y3_1 = np.array([11659.32, 12786, 13513, 14272.74, 16199])
-
- # 绘制散点图
- plt.scatter(x3_1, y3_1)
-
- # 设置X轴和Y轴的标签,并指定字体大小
- plt.xlabel("Year", fontsize=15) # 设置X轴标签为"Year"
- plt.ylabel("Outbound Tourists (in millions)", fontsize=15) # 设置Y轴标签,并说明单位
-
- # 设置图表的标题,并指定字体大小
- plt.title("Outbound Tourists (in millions)", fontsize=15)
-
- # 绘制折线图
- plt.plot(x3_1, y3_1)
-
- # 显示图表
- plt.show()
2.双折线图
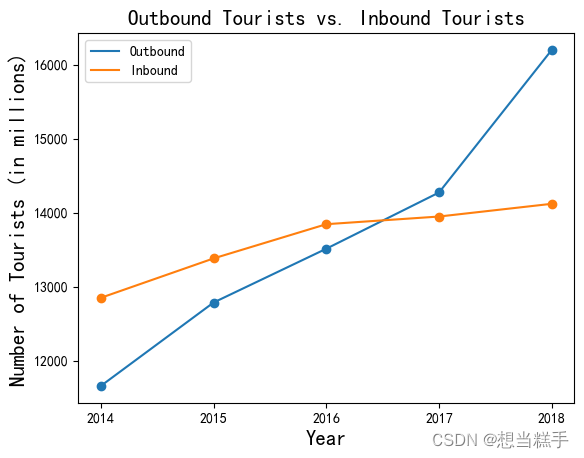
- # 定义数据
- x3_1 = np.array(['2014', 2015, 2016, 2017, '2018'])
- y3_1 = np.array([11659.32, 12786, 13513, 14272.74, 16199])
- y3_2 = np.array([12849.83, 13382.04, 13844.38, 13948, 14119.83])
-
- # 绘制散点图
- plt.scatter(x3_1, y3_1)
- plt.scatter(x3_1, y3_2)
-
- # 设置X轴和Y轴的标签,并指定字体大小
- plt.xlabel("Year", fontsize=15) # 设置X轴标签为"Year"
- plt.ylabel("Number of Tourists (in millions)", fontsize=15) # 设置Y轴标签,并说明单位
-
- # 设置图表的标题,并指定字体大小
- plt.title("Outbound Tourists vs. Inbound Tourists", fontsize=15)
-
- # 绘制折线图,并添加图例
- plt.plot(x3_1, y3_1, label='Outbound') # 出境游客折线图
- plt.plot(x3_1, y3_2, label='Inbound') # 入境游客折线图
-
- # 显示图例
- plt.legend()
-
- # 显示图表
- plt.show()
十二、柱图
柱图与散点图和折线图的一个主要区别,在于柱子有宽度。
柱子的宽度范围是0-1。不管横坐标是数字还是字符串,相邻两点的宽度都是1;
plt.bar的第一个参数是x,可以直接赋值数据,如,'January';即使是字符串型也可以。
但如果在一个刻度上画2个或多个柱子,就得计算柱子宽度,
那么就要用xticks在数值和字符串间映射,然后用数值计算第2根柱子的位置。
这里的数字型x多少都行,只要两个x之间差1就行,就可以计算柱子的位置了,参见下面第2个例子。
1.单柱图
- # 准备一组数据,表示公司在不同年份的收入和支出。
- years = ['2014', '2015', '2016', '2017', '2018']
- income = [200, 300, 150, 350, 800]
-
- plt.figure()
-
- rects = plt.bar(years,income,width=0.4,label='income')
-
- # 给每根柱子添加文字说明
- for rect in rects:
- height = rect.get_height()
- plt.text(rect.get_x()+rect.get_width()/2,height+10,str(height),\
- ha="center", va="bottom")
-
- # 获取每根柱子->获取柱子高度->在“柱子起始点+柱子宽度/2 , 柱子高度高一点”的位置\
- # 添加文本:内容就是柱子高度->水平对齐和垂直对齐
-
- plt.ylim(0,1000)
-
- plt.show()
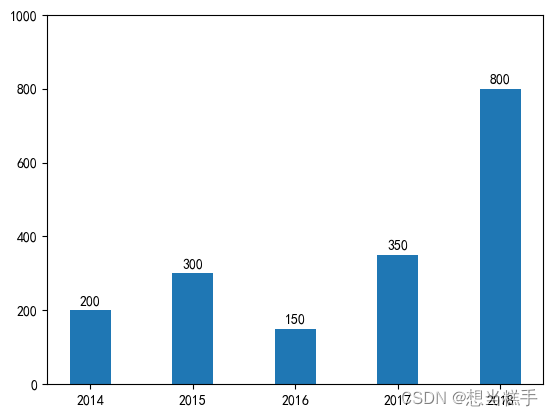
2.双柱图
- # 定义数据
- x4 = ['2014', '2015', '2016', '2017', '2018'] # 横坐标刻度显示值
- y4 = [200, 300, 150, 350, 800] # 纵坐标值
- y4_1 = [220, 320, 150, 350, 800] # 纵坐标值
- # 绘制条形图
- # height: 长条形高度
- # width: 长条形宽度,默认值0.8
-
- x5_index = np.array(range(len(x4)), dtype=np. float32)
- # 将年份映射为数字 0 1 2 3 4
-
- rects = plt.bar(x5_index, y4, width=0.4, alpha=0.8, color='g',label='一本部')
- rects1 = plt.bar(x5_index+0.4, y4_1, width=0.4, alpha=0.8, color='r',label='二本部')
- # 设置 y 轴取值范围
- plt.ylim(0, 900) # y 轴取值范围
-
- # 调整x5_index使得横坐标标签位于两个柱子中间
- x5_index_centered = x5_index + 0.4 / 2
- plt.xticks(x5_index_centered, x4)
- # 在这段代码中,x5_index_centered是一个新的数组,
- # 它的每个元素都是x5_index的元素加上width / 2。
- # 这样,当您调用plt.xticks时,传入的是x5_index_centered,
- # 它会使横坐标标签正好位于两个柱子的中间位置。
-
- # 设置 y 轴标签
- plt.ylabel("销售额(万元)", fontsize=15)
-
- # 设置 x 轴标签
- plt.xlabel("年份", fontsize=15)
-
- # 设置图表标题
- plt.title("公司年收入", fontsize=15)
-
- # 给每个柱子添加标签
- for rect in rects:
- height = rect.get_height()
- plt.text(rect.get_x() + rect.get_width()/2, height + 10, str(height), ha="center", va="bottom")
- # 接下来,plt.text()函数用于在图表上添加文本。文本的位置由rect.get_x() + rect.get_width()/2和height + 10确定。
- # 这里,rect.get_x() + rect.get_width()/2计算的是柱子中心的x坐标位置,确保文本标签水平居中。height + 10则是将文本放在柱子的上方一点,以便清晰显示。
- # 文本内容是柱子的高度值,使用str(height)将其转换为字符串格式。
- # ha="center"和va="bottom"分别是水平对齐和垂直对齐的参数,确保文本在水平方向上居中对齐,垂直方向上靠近底部。
-
- plt.legend(loc='upper left') # 关键是要给柱图设置label
-
- # 显示图表
- plt.show()
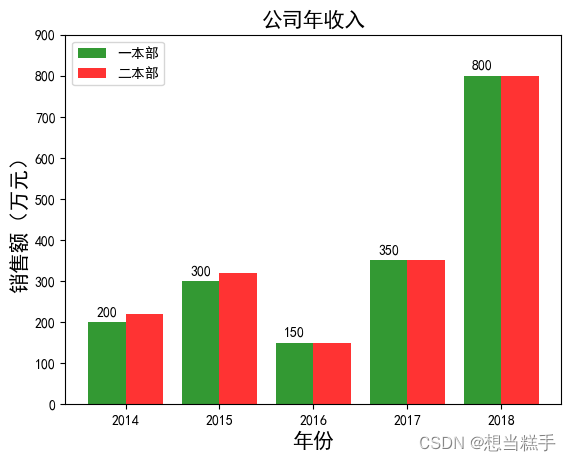
3.叠加柱图 :在原柱图的基础上再画柱图
- days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
- temperatures = [22, 24, 26, 23, 25, 20, 21] # 平均温度(摄氏度)
- high_temps = [28, 30, 32, 29, 31, 27, 24] # 最高温度(摄氏度)
-
- # 设置图形大小
- plt.figure(figsize=(10, 6))
-
- # 计算每个柱子的位置
- ind = np.arange(len(days))
-
- # 绘制平均温度柱状图
- plt.bar(ind, temperatures, width=0.4, color='skyblue', label='平均温度', alpha=0.7)
-
- # 绘制最高气温柱状图,将其叠加在平均温度柱状图之上
- plt.bar(ind, high_temps, width=0.4, color='orange', label='最高温', alpha=0.7, bottom=temperatures)
- # botton = temperatures的作用 就是把两根柱子摞起来
-
- # 设置图形标题和轴标签
- plt.title('一周内每天的平均温度和最高气温对比', fontsize=16)
- plt.xlabel('', fontsize=14)
- plt.ylabel('温度(摄氏度)', fontsize=14)
-
- # 添加图例
- plt.legend(loc='upper left')
-
- # 添加数值标签
- for i in range(len(days)):
- plt.text(i, temperatures[i] + (high_temps[i] - temperatures[i]) / 2, f'{high_temps[i]} / {temperatures[i]}', ha='center', va='bottom')
-
- plt.xticks(ind, days)
-
- # 显示图形
- plt.show()
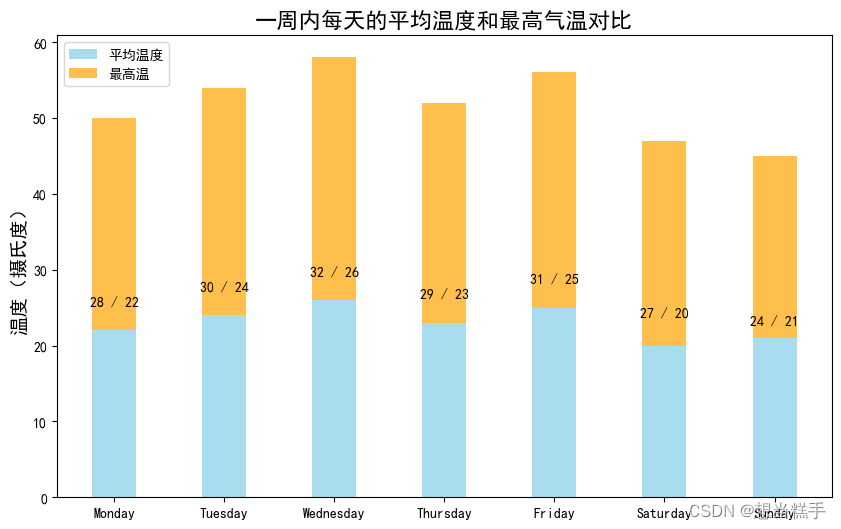
4.横向柱图
- departments = ['销售部', '市场部', '研发部', '人力资源部', '财务部']
- sales = [2500, 1800, 3200, 1500, 1200] # 单位:万元
-
- # 创建一个新的图形
- plt.figure(figsize=(10, 8))
-
- # 绘制横向柱状图
- plt.barh(departments, sales, color='lightblue', edgecolor='black')
-
- # 设置图形标题
- plt.title('不同部门的年度销售额', fontsize=18, fontweight='bold')
-
- # 设置x轴标签
- plt.xlabel('销售额(万元)', fontsize=14)
-
- # 设置y轴标签,即部门名称
- plt.yticks(ticks=range(len(departments)), labels=departments, fontsize=12, va='center')
-
- # 旋转x轴的刻度标签,以便更容易阅读
- plt.xticks(rotation=45)
-
- # # 遍历每个柱子,添加数值标签
- # for index, value in enumerate(sales):
- # plt.text(value, index, f'{value:.0f}', va='center', ha='right')
-
- # 显示图形
- plt.show()
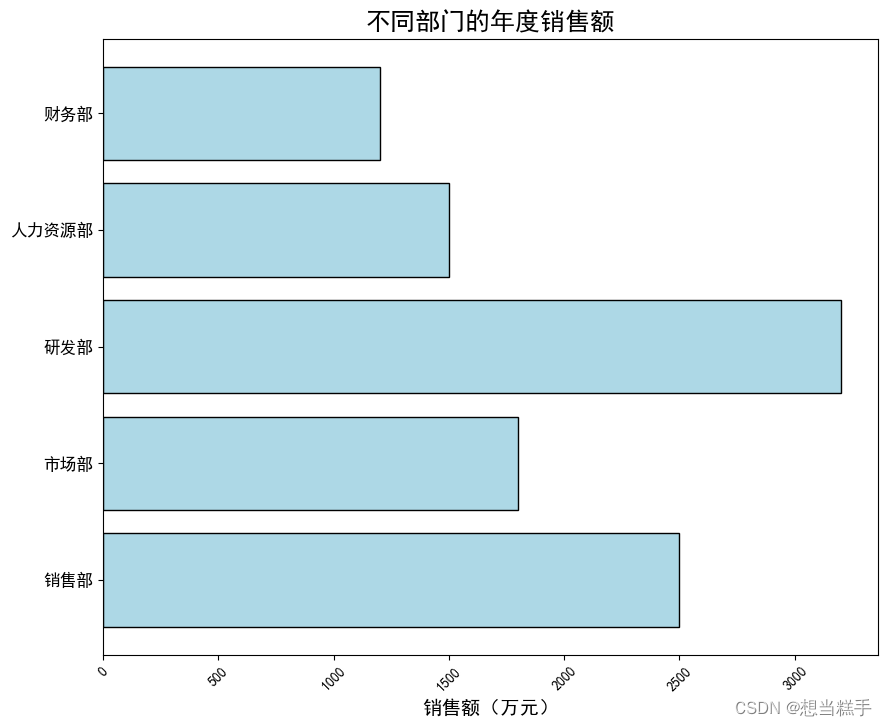
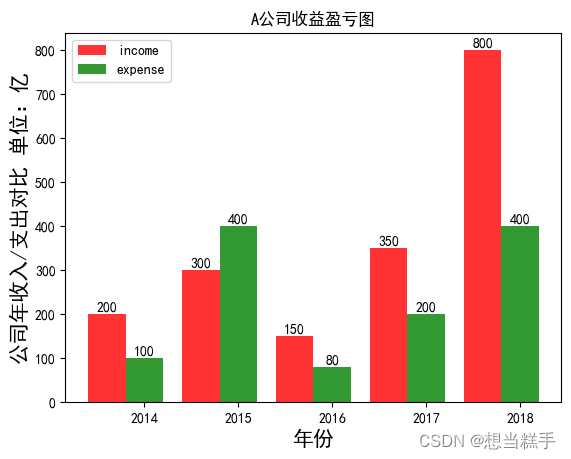
十三、综合实例1:收益盈亏图
- # 准备数据
- x = ['2014','2015','2016','2017','2018']
- y1 = [200,300,150,350,800]
- y2 = [100,400,80,200,400]
-
- # 画布
- plt.figure()
-
- # 双柱图更合适
- # ha="center"和va="bottom"分别是水平对齐和垂直对齐的参数,确保文本在水平方向上居中对齐,垂直方向上靠近底部。
- # alpha为透明度
- ind = np.array(range(len(x)), dtype=np.float32)
- rects1 = plt.bar(ind,y1,width=0.4,alpha=0.8,color='r',label='income')
- rects2 = plt.bar(ind+0.4,y2,width=0.4,alpha=0.8,color='g',label='expense')
-
- # 编辑柱图文本
-
- for rect in rects1:
- height = rect.get_height()
- plt.text(rect.get_x()+rect.get_width()/2,height+1,str(height),ha='center',va='bottom')
-
- for rect in rects2:
- height = rect.get_height()
- plt.text(rect.get_x()+rect.get_width()/2,height+1,str(height),ha='center',va='bottom')
-
- # 使x轴下标位于双柱图中间 同时进行替换
- plt.xticks(ind+0.4,x)
-
- # 找最佳位置显示图标
- plt.legend()
-
- # xlim...
-
- # 图标题 XY轴标题
- plt.xlabel('年份',fontsize = 15)
- plt.ylabel('公司年收入/支出对比 单位:亿',fontsize = 15)
- plt.title('A公司收益盈亏图')
-
- # 展示图表
- plt.show()
十四、直方图
1.直方图
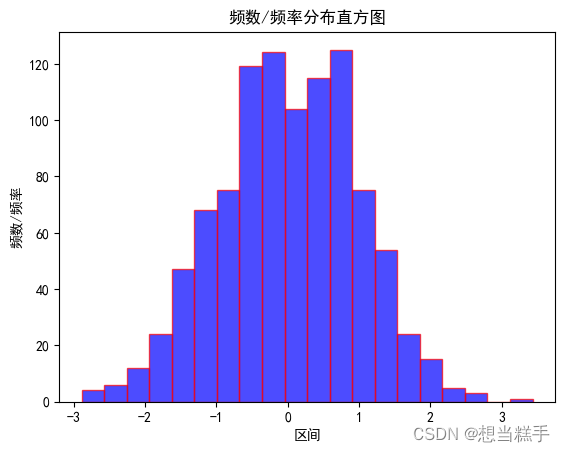
- 直方图(Histogram),又称质量分布图,是一种统计报告图,通过直方图可以直观看出数据的分布;
- 系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况(某数据类型出现的次数、频率)。
- 直方图举例:上面是yigu直方图的横轴表示亮度,从左到右表示亮度从低到高。直方图的纵轴表示像素数量,从下到上表示像素从少到多。直方图在某个亮度区间的凸起越高,就表示在这个亮度区间内的像素越多。比如这个直方图的凸起就主要集中在左侧,也就是说这张照片的亮度整体偏低。
- 使用plt.hist(数据,区间)绘制直方图
- # 生成1000个服从标准正态分布的随机数
- data = np.random.randn(1000)
-
- # plt.hist()函数用于绘制直方图。
- # bins参数指定了直方图的条形数目,这里设置为20。
- # facecolor参数设置了条形的填充颜色,
- # edgecolor设置了条形边框的颜色,
- # alpha设置了图形的透明度。
-
- # 绘制直方图
- plt.hist(data, bins=20, facecolor="blue", edgecolor="red", alpha=0.7)
-
- # 显示横轴标签
- plt.xlabel("区间")
-
- # 显示纵轴标签
- plt.ylabel("频数/频率")
-
- # 显示图标题
- plt.title("频数/频率分布直方图")
-
- # 显示图形
- plt.show()
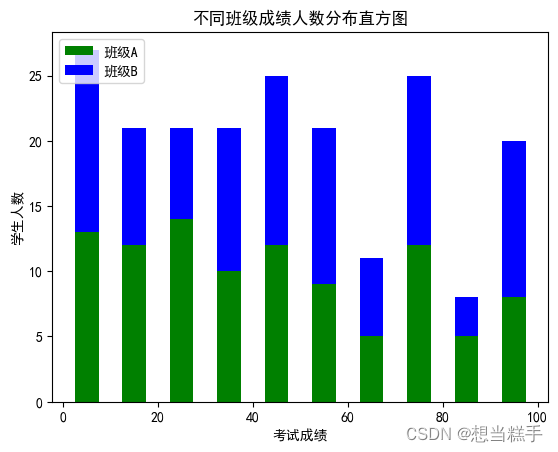
2.堆积直方图
传入数据x -> 传入数据列表[x,y]
- import matplotlib.pyplot as plt
- import numpy as np
-
- # 生成两个班级的成绩数据,每个班级有100名学生
- scoresT1 = np.random.randint(0, 100, 100)
- scoresT2 = np.random.randint(0, 100, 100)
-
- # 将两个班级的成绩数据合并为一个列表
- x = [scoresT1, scoresT2]
- print(x)
- # 定义每个班级的成绩数据所对应的颜色
- colors = ["g", "b"]
-
- # 定义每个班级的标签
- labels = ["班级A", "班级B"]
-
- # 定义直方图的统计区间,这里设置为0-10, 10-20, ..., 90-100
- bins = range(0, 101, 10)
-
- # 绘制堆积直方图 和叠加柱图相似
- # plt.hist()函数用于绘制堆积直方图。color参数指定了每个班级的颜色,histtype参数设置为"bar"表示使用条形表示数据,
- # rwidth参数设置为0.5表示条形的相对宽度,stacked参数设置为True表示创建堆积直方图,
- # label参数为每个班级指定了图例标签。
- plt.hist(x, bins=bins, color=colors, histtype="bar", rwidth=0.5, stacked=True, label=labels)
-
-
- # 显示横轴标签
- plt.xlabel("考试成绩")
-
- # 显示纵轴标签
- plt.ylabel("学生人数")
-
- # 显示图标题
- plt.title("不同班级成绩人数分布直方图")
-
- # 添加图例
- plt.legend(loc="upper left")
-
- # 显示图形
- plt.show()
3.直方图区间的两种表示:
- bin = [0,60,90,100]
- # 3个区间 : 0-59 60-89 90-100
- bin_1 = (0,101,10)
- # 10个区间 : 0--100的等差区间
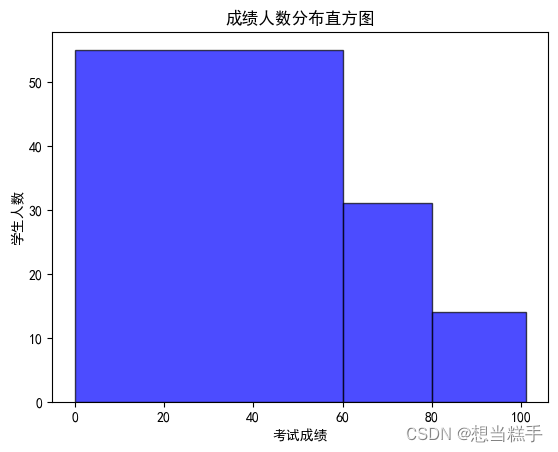
十五、综合实例2:考试成绩统计
- # 生成100个介于0到99之间的随机整数,代表学生的考试成绩
- data = np.random.randint(0, 100, 100)
-
- ### 定义直方图的统计区间,这里设置为0-60, 60-80, 80-101
- bins = [0, 60, 80, 101]
-
- # 绘制直方图
- plt.hist(data, bins=bins, facecolor="blue", edgecolor="black", alpha=0.7)
-
- # 显示横轴标签
- plt.xlabel("考试成绩")
-
- # 显示纵轴标签
- plt.ylabel("学生人数")
-
- # 显示图标题
- plt.title("成绩人数分布直方图")
-
- # 显示图形
- plt.show()
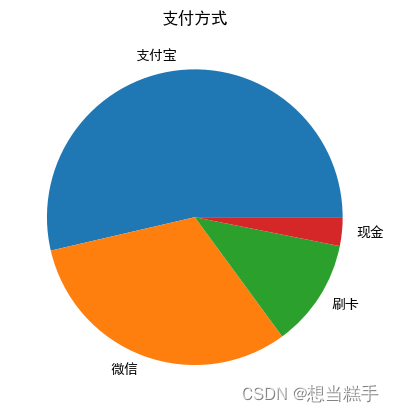
十六、饼图
- # 支付方式的标签和使用次数
- labels = ['支付宝', '微信', '刷卡', '现金']
- sizes = [20543, 12042, 4520, 1200]
-
- # 绘制饼图
- plt.pie(sizes, labels=labels)
-
- # 设置图表标题
- plt.title("支付方式")
-
- # 显示图表
- plt.show()
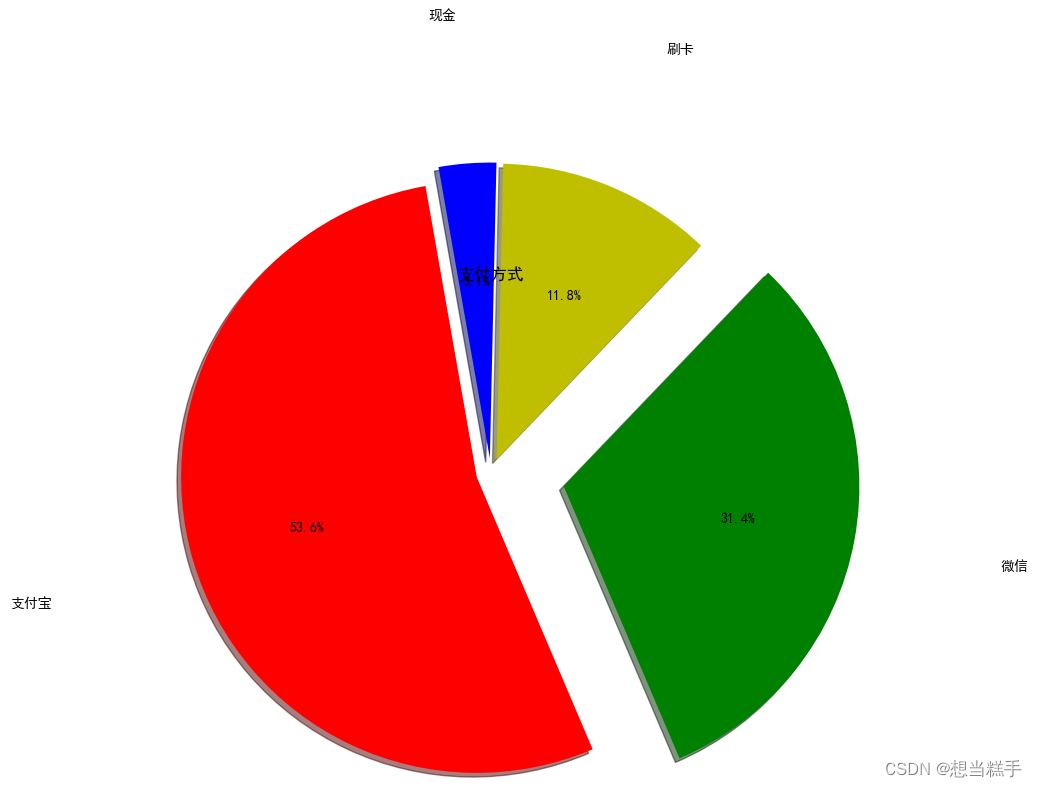
较全的自定义内容:
pie()函数参数的详细解释:
- x: 饼图每一块的比例数据。如果sum(x)大于1,比例会被归一化处理。
- labels: 饼图每一块外侧显示的说明文字列表,与x中的数据一一对应。
- explode: 控制饼图每一块离开中心的距离,可以是单个数值或者序列。如果设置为(0.1,),则第一块饼图会稍微突出显示。
- startangle: 起始绘制角度。默认情况下,饼图是从x轴正方向开始逆时针绘制。如果设置为90,则从y轴正方向开始绘制。
- shadow: 是否在饼图下方绘制阴影。默认值为False,即不绘制阴影。
- labeldistance: 标签标记的绘制位置,相对于饼图半径的比例。默认值为1.1,如果小于1,则标签会绘制在饼图内侧。
- autopct: 控制饼图内百分比的显示格式。可以使用格式化字符串或者格式化函数,例如'%1.1f%%'表示显示一位小数的百分比,不加空格。
- pctdistance: 类似于labeldistance,指定autopct的位置距离,默认值为0.6。
- radius: 控制饼图的半径大小,默认值为1。
- counterclock: 指定指针方向。布尔值,默认为True,即逆时针绘制。设置为False则改为顺时针绘制。
- wedgeprops: 用于自定义饼图扇形的属性,如线宽、颜色等。参数字典传递给wedge对象。
- textprops: 设置标签(labels)和比例文字的格式。传递给text对象的字典参数。
- center: 浮点类型的列表,指定饼图中心的位置,默认为(0, 0)。
- frame: 是否绘制带有网格线的轴框架。布尔类型,默认为False。
- rotatelabels: 是否旋转每个标签到指定的角度。布尔类型,默认为False。
这些参数提供了丰富的定制选项,使得用户可以根据需要创建具有特定外观和行为的饼图。通过调整这些参数,您可以创建更具吸引力和信息性的饼图,以直观地展示数据的比例关系。
- # 支付方式的标签和使用次数
- labels = ['支付宝', '微信', '刷卡', '现金']
- sizes = [20543, 12042, 4520, 1200]
-
- # 定义每个扇区的分离程度,这里将第一个扇区(支付宝)分离出来
- explode = (0.1, 0.5, 0.1, 0.1)
-
- # 自定义颜色列表
- colors = ['r', 'g', 'y', 'b'] # 分别对应红色、绿色、黄色、蓝色
-
- # 绘制饼图,包含自定义效果
- plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True, startangle=100, colors=colors, labeldistance=1.5, radius=2.0)
-
- # 设置图表标题
- plt.title("支付方式")
-
- # 显示图表
- plt.show()
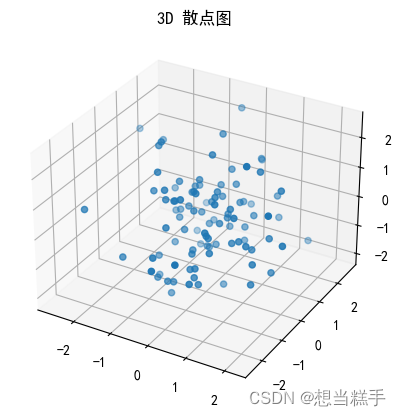
十七、3D图
- # 生成100个介于-1到1之间的随机数,代表三维空间中的x, y, z坐标
- x = np.random.normal(0, 1, 100)
- y = np.random.normal(0, 1, 100)
- z = np.random.normal(0, 1, 100)
-
- # 创建一个新的figure画布
- fig = plt.figure()
-
- # 添加一个3D坐标轴
- # fig.add_subplot函数用于向一个figure对象添加一个新的子图(subplot)
- # 111是子图位置
- ax = fig.add_subplot(111, projection='3d')
- # 注意这里应该是fig.add_subplot而不是Axes3D
-
- # 绘制3D散点图
- ax.scatter(x, y, z)
-
- # 设置图表标题
- ax.set_title("3D 散点图")
-
- # 显示图形
- plt.show()
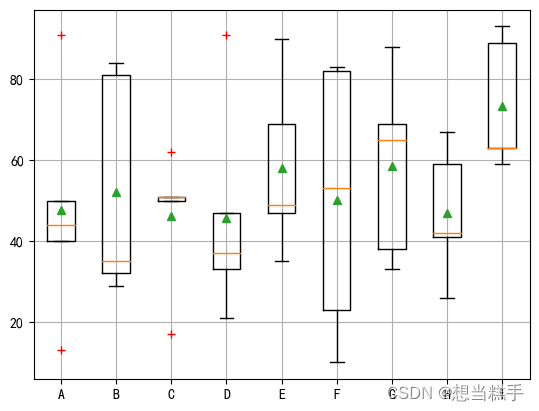
十八、箱线图 使用boxplot()
- # 随机生成5行9列在[10, 100]之间的整数数据
- x = np.random.randint(10, 100, size=(5, 9))
-
- # 打印数据
- print(x)
-
- # 显示网格
- plt.grid(True)
-
- # 绘制箱线图,
- # labels参数提供了每个箱线图的标签,
- # sym参数表示在箱线图上绘制红色加号标记,
- # showmeans=True表示显示每组数据的平均值
-
- # 每个列一个箱体 需要是数值列的列
- plt.boxplot(x, labels=list("ABCDEFGHI"), sym='r+', showmeans=True)
-
- # 显示图片
- plt.show()
- [[91 29 17 21 47 82 69 67 93]
- [44 32 51 33 49 83 33 26 63]
- [40 84 50 37 69 23 65 41 59]
- [13 81 51 47 35 53 38 59 89]
- [50 35 62 91 90 10 88 42 63]]
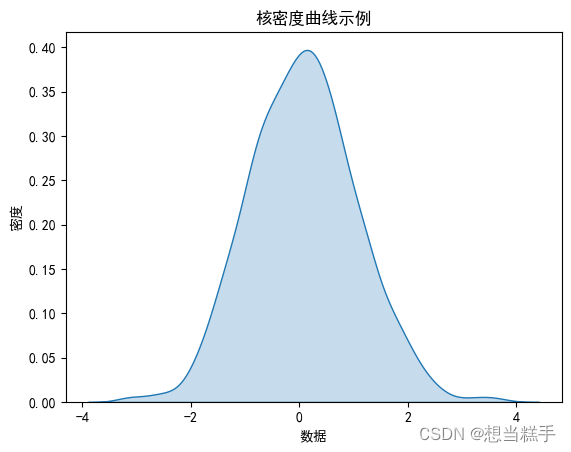
十九、核密度曲线
核密度曲线(Kernel Density Estimation, KDE)是一种用于估计概率密度函数的非参数方法。它可以平滑地展示数据的分布情况,而不需要假设数据遵循特定的分布。核密度曲线在数据可视化中非常有用,因为它能够提供比直方图更平滑、更连续的分布图像。
sns.kdeplot(data)
sns.displot(data)
- import numpy as np
- import matplotlib.pyplot as plt
- import seaborn as sns
-
- # 生成一组正态分布的随机样本数据
- data = np.random.normal(loc=0, scale=1, size=1000)
-
- # 创建一个新的图形
- plt.figure()
-
- # 使用seaborn的kdeplot函数绘制核密度曲线
- sns.kdeplot(data, shade=True)
-
- # 添加标题和轴标签
- plt.title('核密度曲线示例')
- plt.xlabel('数据')
- plt.ylabel('密度')
-
- # 显示图形
- plt.show()
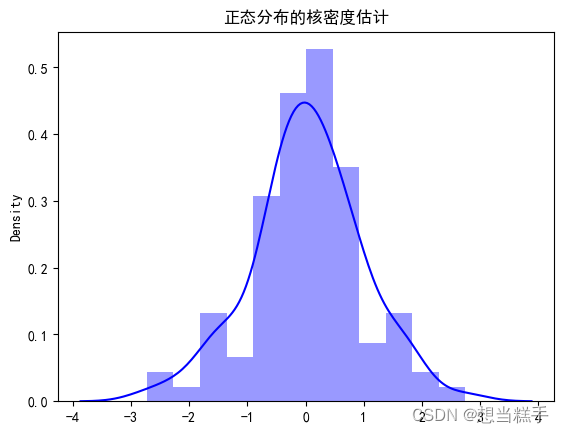
- import seaborn as sns
- import matplotlib.pyplot as plt
-
- # 生成一组正态分布的随机样本数据
- data = np.random.normal(loc=0, scale=1, size=100)
-
- # 绘制数据的分布情况
- sns.distplot(data, kde=True, color='blue')
-
- # 添加标题
- plt.title('正态分布的核密度估计')
-
- # 显示图形
- plt.show()
-
- # 以下是sns.distplot函数的一些关键参数:
-
- # data:要绘制的数据,可以是单个数据数组或多个数据数组的列表。
-
- # bins:直方图的条形数目。默认情况下,seaborn会尝试自动选择一个合适的bins数目。
-
- # kde:一个布尔值,用于控制是否在直方图上绘制核密度曲线。默认值为True。
-
- # rug:一个布尔值,用于控制是否在x轴上显示数据点的“rug”,即在直方图的每个条形下方标记实际的数据点。默认值为False。
-
- # fit:一个函数或函数的字符串名称,用于指定用于计算核密度估计的核函数。常用的核函数包括gaussian、tophat、epanechnikov等。
-
- # color:用于指定直方图和核密度曲线的颜色。
-
- # shade:一个布尔值,用于控制核密度曲线是否应该填充阴影。默认值为True。
-
- # hist:一个布尔值,用于控制是否显示直方图。当kde=True时,此参数通常被忽略。
-
- # norm_hist:一个布尔值,用于控制直方图是否应该被归一化为密度估计。当True时,直方图的高度表示概率密度而不是频率。默认值为False。
-
- # ax:一个matplotlib.axes.Axes对象,用于在指定的轴上绘制图形。
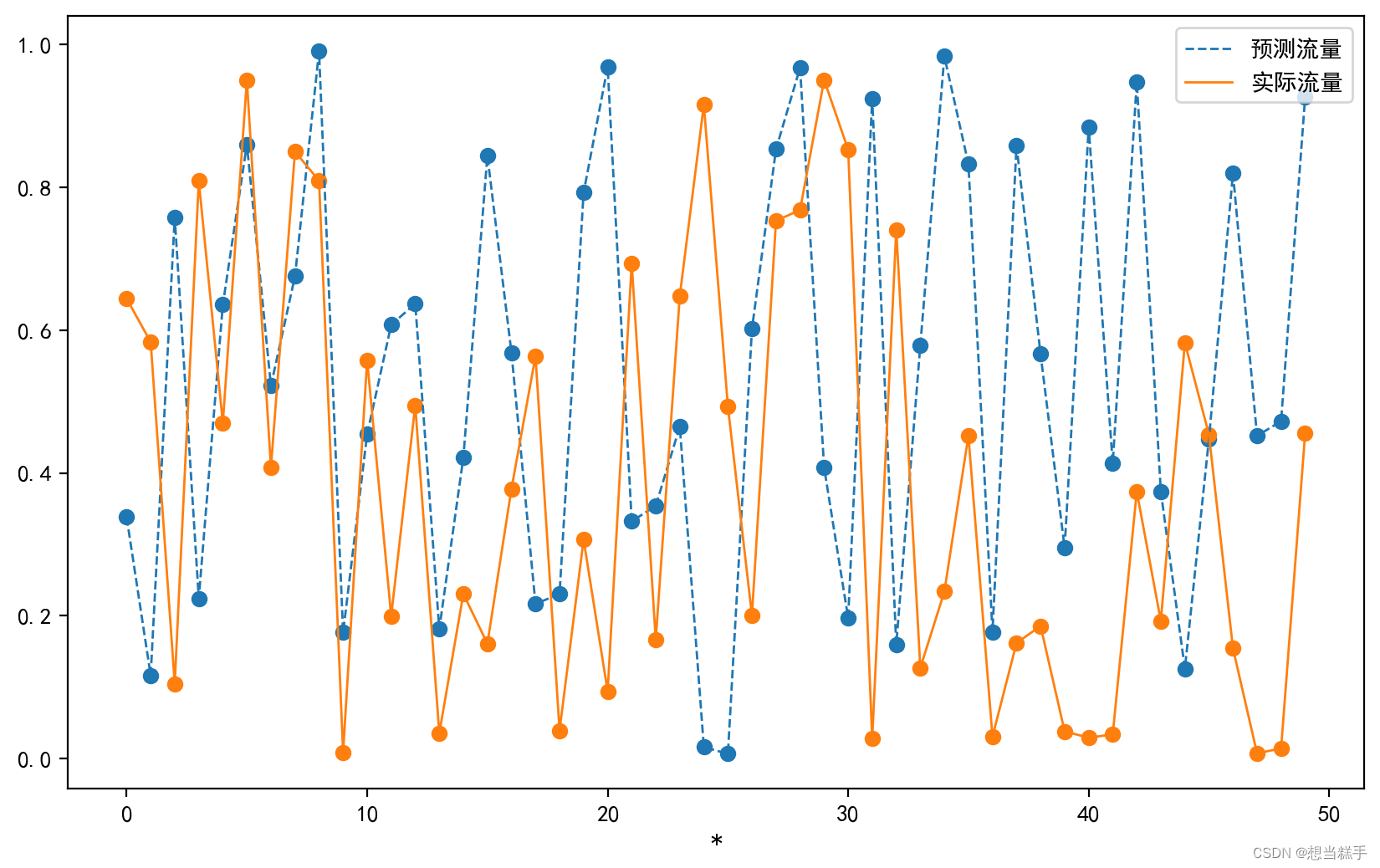
二十、保存高清图片
- 默认情况下matplotlib画的图dpi=80,不是非常清晰,难以满足论文出版要求。通过plt.figure()设置图片大小和分辨率;dataframe的plt方法没有dpi属性,只能使用默认值dpi=80;
- 使用plt.savefig保存图片。
- 如果保存的图片是空的,一般是因为前面有plt.show()
即创建画布的时候设置一次dpi,保存图片是设置一次dpi
- import numpy as np
- import matplotlib.pyplot as plt
-
- # 生成50个从0到49的整数序列
- x = np.arange(50)
-
- # 生成50个[0, 1)区间内的随机数,代表预测流量
- pre_flow = np.random.rand(50)
-
- # 生成50个[0, 1)区间内的随机数,代表实际流量
- real_flow = np.random.rand(50)
-
- # 创建一个新的图形,设置图形大小和分辨率
- plt.figure(figsize=(10, 6), dpi=200)
-
- # 设置y轴标签,这里为空字符串表示不显示标签
- plt.ylabel("", fontsize=10)
-
- # 设置x轴标签,这里使用星号"*"表示
- plt.xlabel("*", fontsize=10)
-
- # 绘制预测流量的散点图
- plt.scatter(x, pre_flow)
-
- # 绘制实际流量的散点图
- plt.scatter(x, real_flow)
-
- # 绘制预测流量的折线图,使用虚线样式
- plt.plot(x, pre_flow, linewidth=1, linestyle='--', label='预测流量')
-
- # 绘制实际流量的折线图,使用实线样式
- plt.plot(x, real_flow, linewidth=1, label='实际流量')
-
- # 添加图例,位置在右上角
- plt.legend(loc='upper right')
-
- # 保存图形到文件,设置分辨率和格式
- plt.savefig('图9-4.png', dpi=200, format='png')
-
- # 显示图形
- plt.show()
二十一、总结
使用Python进行绘图的基本思路和步骤可以分为以下几个阶段:
- 环境准备:确保已经安装了绘图库,如matplotlib。
- 数据准备:收集、清洗并准备要展示的数据。
- 绘制图形:选择合适的图形类型,并使用绘图库提供的函数创建图形。
- 定制图形:调整图形的样式、颜色、标签等,使图形更加直观和美观。
- 添加注释:在图形上添加文本、标签或其他注释,以便更好地解释数据。
- 保存或显示图形:将图形保存到文件,或直接在屏幕上显示。
大家可以亲自实践,试试能不能通过这个思路独自画出相同的图像;下一篇内容会更新关于我的课程实验内容,会是以往内容的综合应用。
二十二、扩展
1.enumerate()
- # # 遍历每个柱子,添加数值标签
- # for index, value in enumerate(sales):
- # plt.text(value, index, f'{value:.0f}', va='center', ha='right')
enumerate 是 Python 中的一个内置函数,它用于将一个可迭代的数据对象(如列表、元组、字符串等)组合为一个索引序列,同时列出数据和数据下标,通常用在 for 循环中。
当你在 for 循环中使用 enumerate 函数时,它会返回一个枚举对象,这个对象生成包含每个迭代元素的索引和值的元组。这使得你可以同时获得元素及其在原始序列中的位置(索引),而不需要手动管理或计算索引。
- # 示例列表
- sales = [100, 200, 300, 400, 500]
-
- # 使用 enumerate 遍历列表
- for index, value in enumerate(sales):
- print(f'Index: {index}, Value: {value}')
- 输出结果将会是:
-
- Index: 0, Value: 100
- Index: 1, Value: 200
- Index: 2, Value: 300
- Index: 3, Value: 400
- Index: 4, Value: 500
- # 使用 enumerate 从 1 开始计数
- for index, value in enumerate(sales, start=1):
- print(f'Index: {index}, Value: {value}')
- 这将会输出:
-
- Index: 1, Value: 100
- Index: 2, Value: 200
- Index: 3, Value: 300
- Index: 4, Value: 400
- Index: 5, Value: 500
- # 示例列表
- sales = [100, 200, 300, 400, 500]
-
- # 使用 enumerate 和 reversed 进行反向遍历
- for index, value in enumerate(reversed(sales)):
- print(f'Index: {len(sales) - index - 1}, Value: {value}')
- 输出结果将会是:
-
- Index: 4, Value: 500
- Index: 3, Value: 400
- Index: 2, Value: 300
- Index: 1, Value: 200
- Index: 0, Value: 100
2.f'{value:.0f}'格式化
在 Python 中,f'{value:.0f}' 是一个格式化字符串(也称为 f-string),它是 Python 3.6 及以上版本中引入的一种新的字符串格式化机制。这种格式化字符串允许你在字符串中直接嵌入表达式,并且可以对这些表达式进行格式化。
在这个特定的例子中,f'{value:.0f}' 表示:
f:前缀f表示这是一个格式化字符串(f-string)。{value}:花括号{}内的value表示一个变量占位符,它将被替换为变量value的值。::冒号:后面的部分是格式化选项。.0f:这是格式化选项,.0表示保留 0 位小数,即不显示任何小数位,f表示浮点数(float)类型。
- value = 123.456
- formatted_value = f'{value:.0f}'
- print(formatted_value) # 输出:123

