
- 1Zotero的基本使用及插件、联动_zotero插件linter
- 2Git安装及环境配置_git安装成功后 环境配置
- 3LVDS、LVPECL、CML、miniLVDS、RSDS_minilvds和lvds信号的区别
- 4人工智能中的数学计算和数学思想_ai计算数学
- 5Spring Boot 笔记_spring boot admin注册进来的地址
- 6如何进行高效的数据清洗?_数据清洗方案
- 7VSCode神器 //GitHub Copilot代码自动补全工具//_vscode自动写代码工具
- 8一遍看懂Android.9图制作详解_android .9图片制作
- 9Gerrit 使用_gerrit配置
- 10EchoMimicV2,Audio Driven加速模型,推理速度大幅提升_echomimic 推理报错
深入大模型量化技术,大模型端侧落地已Ready?_端侧大模型
赞
踩

揭秘未来:大模型量化技术如何革新移动AI应用
©作者|饮水机
来源|神州问学
前言
最近,苹果发布了OpenELM系列模型,参数规模分别为270M、450M、1.1B和3B。与此同时,微软也推出了Phi-3系列模型,其中mini版本的参数规模为3.8B。这两款模型都专注于端侧,特别是移动设备的应用场景。这些场景往往计算资源和成本受限,却需要低延迟高质量的离线推理。尽管苹果和微软等企业不断地尽力提升小型模型的表现,受限于参数规模,这些模型只适用于极为简单的任务,而在体验过如GPT-4等大模型的强大后,许多用户希望能在便捷的移动设备上也可使用大模型的能力。为了实现这一目标,许多技术正在被研发和改进,其中极为重要的一项就是量化技术。
量化目的
量化的主要动机是使大型语言模型能够在不同的平台上高效部署,同时降低成本和内存需求。通过减少模型的大小和计算复杂性,量化使大模型能在资源有限的设备上运行,加快推理速度,提高能效,并降低操作成本。此外,量化增强了模型的可扩展性和灵活性,使其能够适应从高性能服务器到低功耗设备的各种硬件环境。
量化作用
实践中量化可以显著减小模型大小、加快计算速度并降低能耗,特别适用于资源有限的环境。然而,量化可能导致模型表现下降,从而生成质量不佳的文本。量化虽然使得在更广泛的硬件上部署复杂的语言模型成为可能,但需要使用者在性能和效率之间做出权衡。另外,在计算资源受限时,通过量化可以牺牲精度而实现对更高参数规模模型的支持,为使用者增加了一种选择。
量化原理
大模型的量化是指用更少的信息表示数据,同时尽量不损失太多准确性的技术。通常的做法是将模型的一些参数(如权重)转换并存储为更少比特的数据类型。例如,将部分层输入由16位浮点数转为8位整数,转换后的数字将会只需要一半的存储空间,同时因为精度降低,计算被简化,推理速度也会加快。计算方式如下图,其中X_i8代表转换后的8位整数,X_f16代表转换前的16位浮点数,max代表层输入矩阵中的最大绝对值,而包围等式右边的大括号代表取最接近的整数。
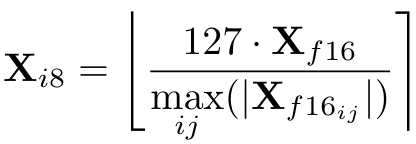
常见的一种量化策略是逐层量化。假使W代表模型中一层的权重,X代表该层的输入。量化的目标就是计算出最小平方错误的量化后的权重,如下式:
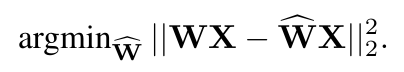
量化分类
主流的量化技术有两个方向,分别为QAT (Quantization Aware Training)和PTQ (Post-Training Quantization)。
QAT
QAT是一种在模型训练期间使用的技术。该技术通过在训练过程中引入量化效应,缩小了使用高精度浮点数训练与部署时降低精度之间的差距。通过在前向传播和反向传播过程中引入量化和去量化模块,量化造成的损失会被计入训练的损失函数中,从而使得模型能学习到更高质量的量化参数以缓解最终的精度下降。然而,QAT 显著增加了训练的复杂性。在训练中引入额外操作和调整损失函数需要精细的执行和调整。模型需改动以精确模拟量化效应,包括添加量化感知层和确保与所选模型量化方案的兼容。这种增加的复杂度可能导致训练过程中的计算更加密集,导致需要更多时间和计算资源。此外,为了减轻精度损失而进行的验证和微调进一步增加了训练流程的复杂性。
PTQ
PTQ是在模型初始训练后使用的技术。与QAT不同,PTQ在训练过程中不考虑模型量化的影响,而是专注于压缩预训练模型以便在资源受限的设备上部署。一般来说,由于不需要对模型训练进行任何调整,与QAT相比,PTQ要更加简单。然而,PTQ 也会导致模型精度的损失,因为浮点当中包含的语义在量化后有可能会丢失。因此,要在模型大小缩减和保持精度之间达到合适的平衡仍然需要仔细的校准和评估,尤其是模型被应用在对准确性有高要求的场景时。
量化技术
由于QAT的成本往往较高,PTQ通常更受欢迎。下文列举并介绍了一些PTQ技术。
GPTQ
GPTQ的名字结合了GPT(Generative Pre-trained Transformers)和PTQ。GPTQ是在OBQ的基础上改进而来的一种量化技术。OBQ以贪心顺序量化权重,即总是选择当前引起最小额外量化误差的单个权重。W(权重矩阵)的每一行都会独立进行计算。但是GPTQ的作者认为,在一行中以任何固定的顺序进行量化都能实现不错的效果,所以GPTQ为W的每一行都使用同样的顺序进行量化,在保证效果的同时计算量被减少几个数量级,提高了量化效率。不过当用于非常大的模型时,却可能面临两个问题。第一个问题是单纯实现上述算法并不能很好地利用现代地GPU,所以作者调整了算法,通过把计算进行分块而改善了这个问题。第二个问题是现有规模的模型进行上述量化时,数值的不准确性可能会导致计算中需要的一个黑塞矩阵变为不定,从而造成权重量化的方向出错。这个问题被作者通过在黑塞矩阵中加入一个常数,以及用数值稳定的方法提前计算一些所需的矩阵行而解决。下面是GPTQ的算法:

GPTQ能够将一些大型开源模型精确地压缩到3位和4位,带来了显著的可用性改进和端到端加速的同时只造成了较低的准确性损失。不过,GPTQ的研究专注于在生成任务上,并没有考虑激活的量化。
论文地址:
https://arxiv.org/pdf/2210.17323
AWQ
AWQ(Activation-Aware Weight Quantization)是一种考虑激活的量化方法。AWQ的作者认为有些权重比其他权重更为重要,所以不应该被量化或。一种常见的判断权重重要性的根据是它们的大小或者L2范数。但是AWQ的作者认为,通过激活(activation)的大小来判断相应权重的重要性更为有效。作者发现把权重放大再进行量化损失的计算可以提高量化的效果,所以他们通过如下方式找到一个最佳的放大系数。
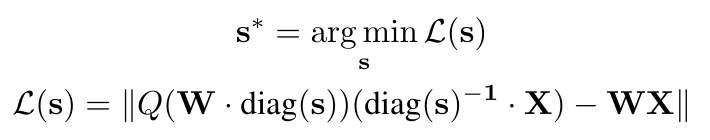
等式中s是放大系数,Q是量化函数(把FP16转为INT3),W是FP16的权重矩阵,X是来自一个校准数据集的输入。因为Q不可导而致使最佳的放大系数难以被找到,所以作者定义了以下的搜索空间,其中s_X是平均的激活大小。
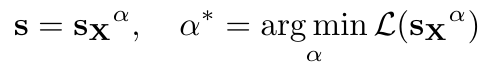
AWQ的困惑度表现:
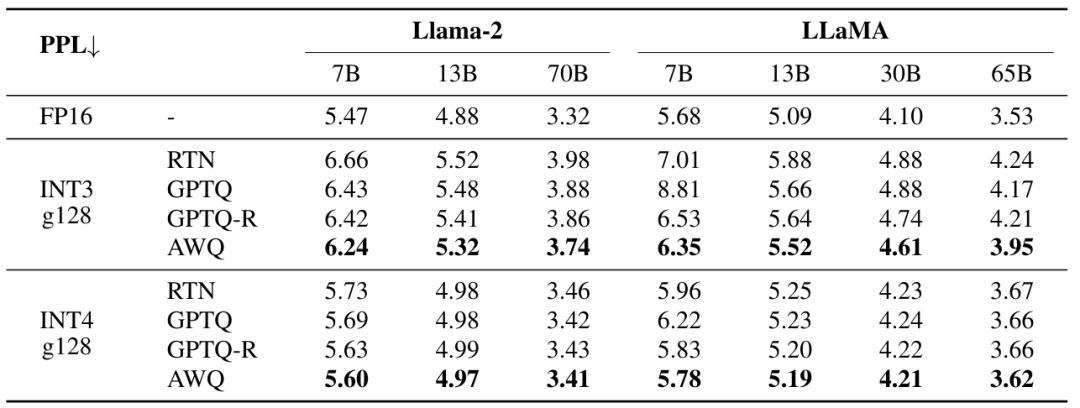
AWQ是一种简单而有效的量化方法。它只需要一个相对较小的校准集却不会过度拟合,而且完全不依赖回归或反向传播,同时保留了LLM在各种领域和模态中的通用能力。AWQ适用于经过指令调优的语言模型和多模态模型。AWQ的作者还开发了TinyChat框架,便于在端侧使用经过AWQ量化的模型推理。
论文地址:
https://arxiv.org/pdf/2306.00978
LLM.int8()
方法是把最大绝对值向量量化和混合精度分解结合起来的量化技术。LLM.int8()的作者认为在非常大LLM.int8()的模型中,当每个张量只对应一个比例常数(scaling constant)时,单个异常值就可导致整个张量被影响,而多个张量中存在异常值就会导致量化后的模型表现降低。为了增加比例常数的数量,LLM.int8()为隐藏态矩阵(hidden state)和权重矩阵的每一行都赋予一个单独的比例常数,此时矩阵相乘的公式如下:
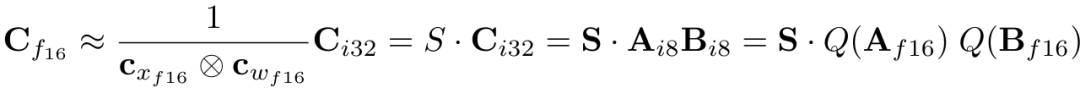
然而,在十亿级别参数的模型上,这种方法不能有效缓解异常值的影响,因为异常值总是在一些大的列中。于是LLM.int8()的作者发现,对一些异常值所在的列不进行量化(即保持原精度)可以很好地减轻模型表现损失。结合这种混合精度的方法,矩阵相乘的公式如下,其中O是含有超过一个阈值的异常值的列的集合。
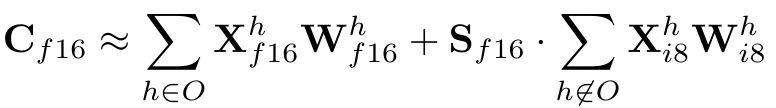
LLM. int8()的困惑度表现:
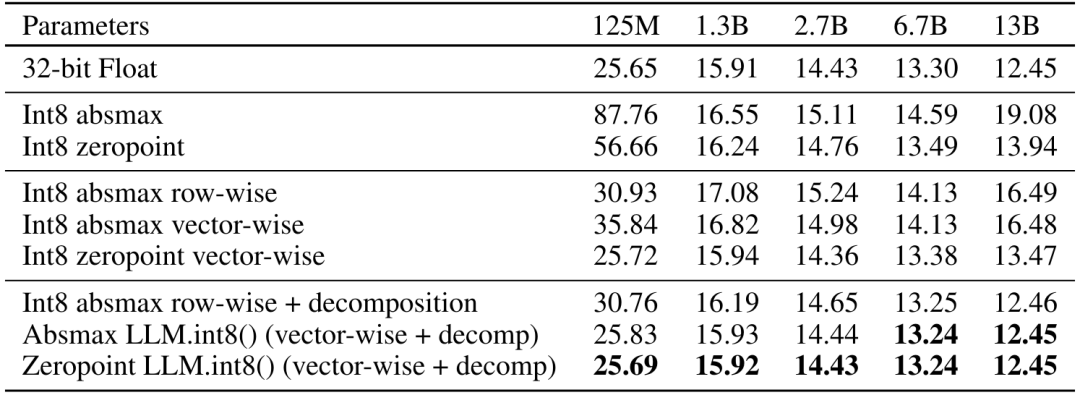
LLM.int8()在十亿规模参数的模型上表现极佳,但也存在一些限制。它的分析仅针对Int8数据类型,而没有研究其他如8位浮点(FP8)数据类型。虽然LLM.int8()最大将175B模型量化为Int8而没有性能下降,但更大规模的模型中额外的属性也许会影响这种量化方法的效果。LLM.int8()也没有对注意力函数使用Int8乘法,但是这可能是一个进一步提升量化效果的方向。最后,LLM.int8()专注于推理,但没有研究训练或微调。
论文地址:
https://arxiv.org/pdf/2208.07339
SmoothQuant
SmoothQuant是一种平衡量化激活和量化权重的技术。SmoothQuant的研究基于以下几个发现。激活比权重更难量化,异常值使量化激活十分困难,异常值存在于固定的通道中。SmoothQuant的作者认为每通道的激活量化比较理想,但限于
GEMM(General Matrix Multiplication)内核的计算方式而不能有效利用硬件。所以,SmoothQuant的作者引入了一个除数s来“平滑”输入的激活,同时为了保证线性层的结果不变,权重要乘以同样的数,等式如下:
![]()
通常s可被选为权重矩阵的最大绝对值,但这样量化的”困难“就全部施加在了权重上,而作者认为这样会导致较大的模型表现损失。于是作者添加了一个超参数α,用以把一部分量化的困难转移向激活,等式如下:
![]()
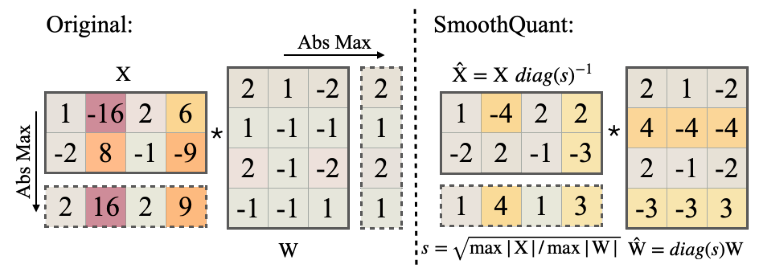
作者发现对于OPT和BLOOM模型,α=0.5是十分平衡的选择。上面的等式确保相应的通道里激活和权重有近似的最大值,从而平分了量化的困难。以下是一个SmoothQuant的原理图:
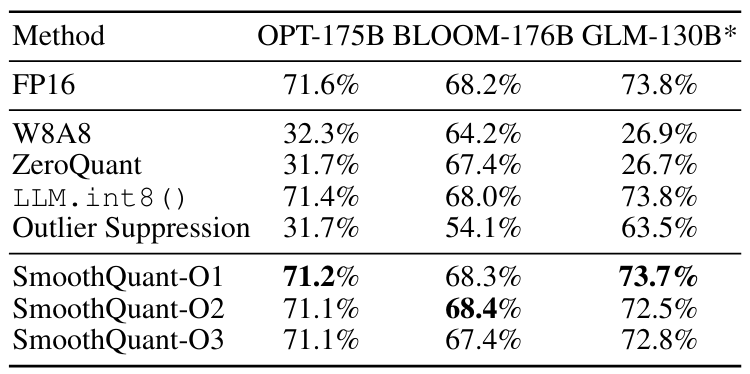
SmoothQuant的准确度(accuracy)表现:
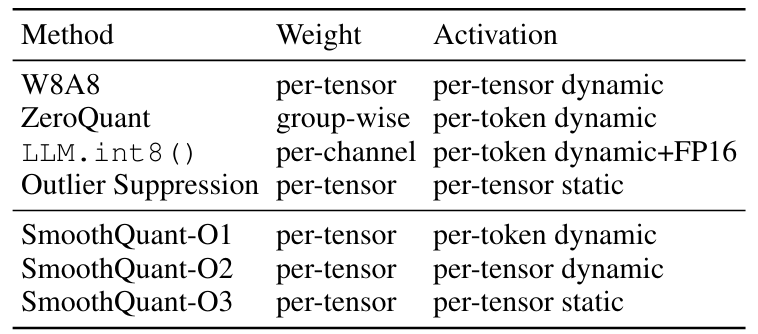
其中O1-O3代表着3种不同的效率实现,见下图:
SmoothQuant是一种精确高效的后训练量化方法,能够为高达530B参数的大型语言模型实现无损的8位权重和激活量化。SmoothQuant支持大语言模型中所有的GEMM的权重和激活量化,与混合精度激活量化基线相比,显著减少了推理延迟和内存使用。SmoothQuant现已被整合到PyTorch和FasterTransformer中,可实现高达1.56倍的推理加速,并将内存占用减半。
论文地址:
https://arxiv.org/pdf/2211.10438
GGUF
GGUF(GPT-Generated Unified Format)是一种用于存储用GGML(GPT-Generated Model Language)和基于GGML的执行器进行推理的模型的文件格式。GGUF是一种二进制格式,旨在快速加载和保存模型,并且容易阅读。传统上,先使用PyTorch或其他框架开发模型,然后再转换为GGUF以使用GGML。GGUF是GGML、GGMF和GGJT的后续文件格式,它被设计成包含加载模型所需的所有信息来消除任何潜在的歧义。GGUF还是可扩展的,因此可以在不破坏兼容性的情况下向模型添加新信息。以下是GGUF的结构图:

作为一种文件格式,GGUF支持存储量化后的模型。在开源社区常常看到一些量化后的模型名称带有字母数字下划线组合的后缀,其实它们就代表着模型的量化类型。以下是GGUF支持的量化类型及其描述。



GGUF代表了对GGML的升级,提供了更大的灵活性、可扩展性和兼容性。它旨在简化用户体验,并支持比llama.cpp更广泛的模型范围。然而,将已有模型转换为GGUF格式可能花费大量时间,而且开发者可能需要进行额外工作来适配GGUF格式。
项目地址:
https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
量化框架
Hugging Face的Transformers库是一个知名的模型训练推理框架,它可以和一些其他库一同使用来量化模型。Transformers支持的库包括Quanto,AQLM,AutoGPTQ,AutoAWQ,Optimum等,涵盖了不同的量化方式。如果现有的库不能满足需求,Transformers的HfQuantizer类还支持用户自定义量化方法。以下是一个使用AutoGPTQ库进行GPTQ量化的简单代码示例。
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
# 指定模型名称或本地路径并加载分词器model_id = "facebook/opt-125m"tokenizer = AutoTokenizer.from_pretrained(model_id)
# 创建一个GPTQ配置类实体gptq_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
# 量化并加载模型quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
# 保存模型和分词器quantized_model.save_pretrained("opt-125m-gptq")tokenizer.save_pretrained("opt-125m-gptq")
# 加载已保存的模型model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")量化效果
以下是来自LLM blog的量化效果对比,其中EXL2后缀代表着ExLlamaV2库使用的EXL2格式,其量化方法为GPTQ。

数据地址:
https://oobabooga.github.io/blog/posts/gptq-awq-exl2-llamacpp/
结语
在实际应用中,量化技术可能面临多个挑战。首先,量化过程可能导致精度损失,尤其是在使用较低位数的量化(如8位)时,这可能会影响模型的性能和准确性。其次,不同的模型可能对量化敏感,可能需要特定的优化措施来保持性能。另外,一些硬件平台可能不支持某些类型的量化,这可能会限制在这些平台上的应用范围。此外,量化可能会增加训练和微调的复杂性,可能需要额外的计算资源和工程投入。
针对这些挑战,存在一些潜在的解决策略。改进量化算法以减少精度损失。开发自适应的量化方法以动态调整量化策略。加强硬件支持以适配量化模型。结合其他技术如知识蒸馏和模型剪枝来提高量化后模型的性能和准确性。推动标准化工作以促进更多的量化工具和框架出现,帮助开发者更好地应用和优化量化技术。
量化技术的关键点包括模型规模、计算效率、硬件利用等方面。随着模型规模的增加,需求更多的计算资源以及更高效的算法支持,同时也需关注模型的可解释性和透明性,以及其在不同领域的应用能力。量化技术未来的发展趋势可能涉及开发更高效的计算技术、多模态信息融合技术、隐私保护技术以及更可持续的训练和部署方法,以推动大语言模型在各个领域的应用和发展。
引用
A detailed comparison between GPTQ, AWQ, EXL2, q4_k_m, q4_k_s, and load_in_4bit: Perplexity, VRAM, speed, model size, and loading time. A detailed comparison between GPTQ, AWQ, EXL2, q4_K_M, q4_K_S, and load_in_4bit: perplexity, VRAM, speed, model size, and loading time. - LLM blog. (n.d.). https://oobabooga.github.io/blog/posts/gptq-awq-exl2-llamacpp/
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh: “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers”, 2022; arXiv:2210.17323.
Ggerganov. (n.d.). GGML/Docs/gguf.md at master · GGERGANOV/GGML. GitHub. https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han: “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”, 2022; arXiv:2211.10438.
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han: “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration”, 2023; arXiv:2306.00978.
Quantization. (n.d.). https://huggingface.co/docs/transformers/en/quantization
Tim Dettmers, Mike Lewis, Younes Belkada, Luke Zettlemoyer: “LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale”, 2022; arXiv:2208.07339.


