
- 12024年Java最新Java算法基础 - 单链表详解(文末有配套视频)(2),2024Java面试题知识点总结_链表 java
- 2Git 安全警告修复手册:解决 `fatal- detected dubious ownership in repository at ` 问题 ️_fatal: detected dubious ownership in repository at
- 3常用机器学习算法训练预测模型的常规流程
- 4计算机必背单词——术语和缩写
- 5美团校招机试 - 小美的MT(20240309-T3)
- 6Github 上最大的开源算法库,还能学机器学习_在github中怎么搜算法题
- 7FastAPI vs Flask: 选择最适合您的 Python Web 框架_fastapi和flask
- 8mysql的information_schema浅析
- 9vue权限管理解决方案
- 10【Struts2漏洞】Struts2全版本漏洞检测工具 v19.23 官方版_struts2漏洞利用工具
yolov8环境配置可能遇到的问题_页面文件太小,无法完成操作 yolov8
赞
踩
YOLOv8环境配置中可能出现的问题
环境配置基于:【yolov8】从0开始搭建部署YOLOv8,环境安装+推理+自定义数据集搭建与训练,一小时掌握_哔哩哔哩_bilibili
CUDA版本我是延续YOLOv5的11.1大家可以自行选择(最好提前看下pytorch支持的版本,可以减少不必要的麻烦)
有了前面yolov5的环境配置作为铺垫,对于yolov8环境配置还是比较轻松的~
下面来说下我的配置流程:(我选择的CUDA版本为11.1.1)
1.CUDA下载(参考yolov5环境配置可能遇到的问题-CSDN博客)
2.Anconda(参考yolov5环境配置可能遇到的问题-CSDN博客)
3.pytorch环境创建(这个有点点不一样)
(我创建了一个新的环境yolov8,环境 python版本为3.8!!!我用3.7发生模块错误,所有模块重新下载)
conda create -n yolov8 python=3.8创建好后:
conda activate yolov8进入环境,然后看下一步:
进入pytorch官网(PyTorch)
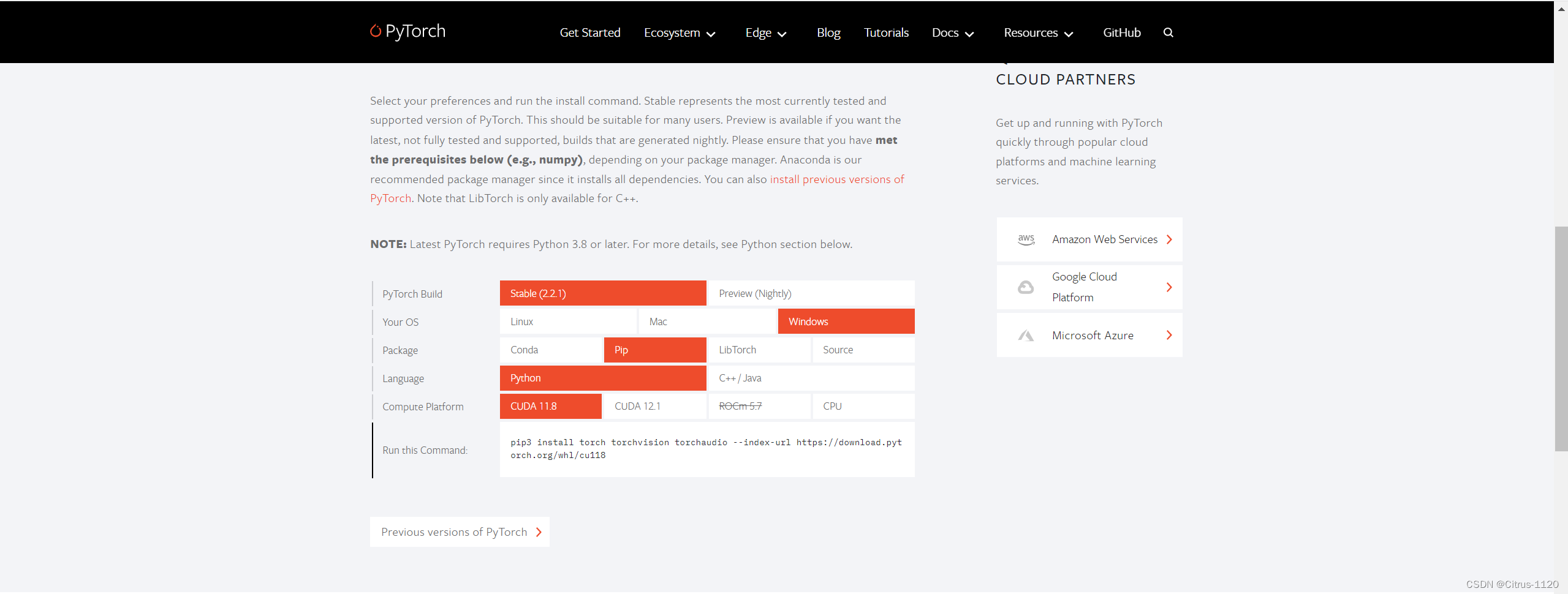
官网那里默认的版本都别选,因为会版本对应不上
我的选择是点击:左下角Previous version of PyTorch(选择更多版本)
然后因为我的是11.1.1的所以,我选择
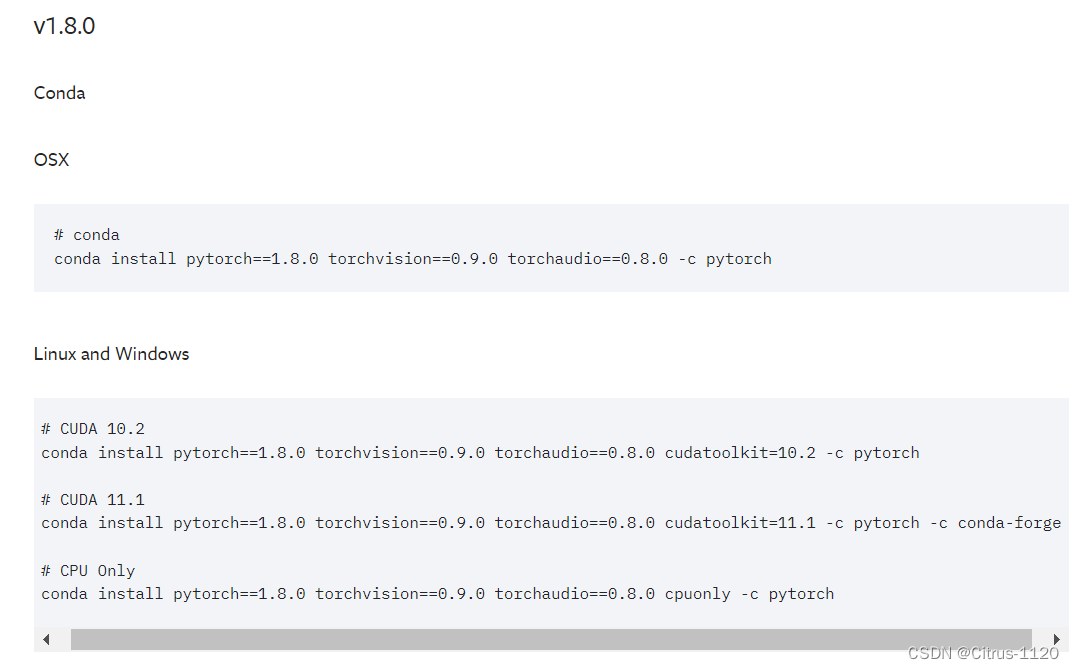
对应的是CUDA 11.1的,注意是v1.8.0 前面的对应的不是11.1.1可能是11.1.0
(下一步重要跟着我来,不然速度很慢)
从上图我们可以得到安装代码如下:
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge但是,根据文章(yolov5环境配置可能遇到的问题-CSDN博客)反映,如果直接输入安装代码会非常慢,一直卡在Solving environment,通过查CSDN,我找到了比较快的方法:pytorch下载太慢的解决办法-CSDN博客
该方案就是将官网的下载路径,改到清华镜像源的路径,先用activate激活自己之前创建的环境后,在命令行输入以下代码:
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
-
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
-
- conda config --set show_channel_urls yes
-
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
这时候我们输入安装代码,会发现出现错误:

可能是在镜像里找不到这个版本的cudatoolkit 11.1
我的思路如下:
先安装cudatoolkit=11.1再执行安装指令(单独分开来,这样到时候他会检测到你已经安装了cudatoolkit 11.1 后就会跳过寻找这个包了)不知道佬们有没有别的方法
conda install cudatoolkit=11.1 -c nvidia/label/cuda-11.1.1 -c conda-forge安装完后再执行:(不需要填写 -c pytorch -c conda-forge就不会一直卡在Solving environment)
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1然后等待安装...... 20-30分钟吧
4. pycharm安装
到这里最难的环境基本配置好了!
pycharm部分:
5. 安装依赖:
在yolov8环境终端输入指令(第一个好像安装不了,不过没关系)
- pip install -e ultralytics
- pip install ultralytics
- pip install yolo
6.训练:
训练部分也容易出现很多问题,出现的问题我都堆在下面了,先说下我的流程:
首先我们需要自定义数据集。自定义数据集跟yolov5有挺大区别,代码也不一样。我也是看了很多csdn的资料,最终通过尝试,以下的方法比较好用:
YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等_yolov8训练自己的数据集-CSDN博客
下面我说下我对上面文章的理解
1.打标签:
跟yolov5打标签一样,使用labelimg进行标注(存放格式有讲究,请看下面)
2.文件说明
但是文件格式有所不同。根据上面文章可知yolov8有四个文件:Annotations, images, ImageSets, labels
打标签的时候:
Open Dir是图片路径是images
Change Save Dir是保存路径也就是Annotations
然后需要在ImageSets里面创建四个txt文件(test.txt train.txt trainval.txt val.txt)用来集中保存yolo文件
labels文件放的是全部txt文件(后面运行代码会生成txt文件)
3.按比例划分数据集
因为训练集train 验证集val 测试集test比例不同所以需要划分下数据集
按照文章调好自己的路径就好了,建议是绝对路径
4.将xml文件转换成YOLO系列标准读取的txt文件
填好自己的分类
classes = ['xxx']
5.修改数据加载配置文件
进入data/文件夹,新建xxx.yaml,内容如下,注意txt需要使用绝对路径
我的叫做bomb.yaml
6.模型训练
这一步有点问题
我一开始输入的是yolo task=detect mode=train model=yolov8s.pt data==D:\yolov8\data\bomb.yaml epochs=100 imgsz=640 resume=True workers=2
会出现各种报错。经过排查,应该是model=yolov8s.pt这里出现问题了。我看b站视频上说的是用yolov8n.yaml(在目前版本找不到这个文件,好像是换了个名字)
我是找到了D:\yolov8\ultralytics-main\ultralytics\cfg\models\v8\yolov8.yaml
把他复制去了我的data文件夹下面。
但是我输入yolo task=detect mode=train model=D:\yolov8\data\yolov8.yaml data=D:\yolov8\data\bomb.yaml epochs=250 imgsz=640 workers=2 会出现以下报错:
![]()
可能是没有给他一个大小文件(像下图这种格式)
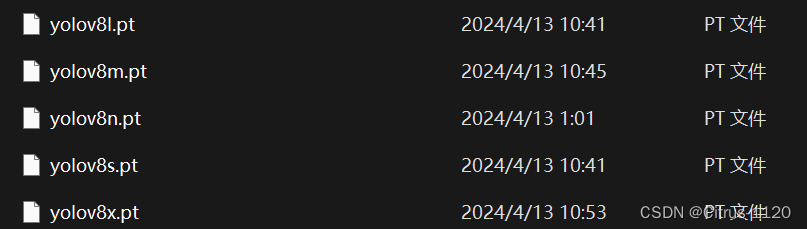
所以,我把yolov8.yaml的名字改成yolov8n.yaml后运行代码
yolo task=detect mode=train model=D:\yolov8\data\yolov8n.yaml data=D:\yolov8\data\bomb.yaml epochs=350 imgsz=640 resume=True workers=2
成功开始训练......

7.推理问题
代码部分:
1.推理设置:
经过探索,我发现,如果想要修改参数值,只不需要找到相应文件的。而是通过代码进行设置。
具体方法如下:(以视频为例)
- import cv2
- from ultralytics import YOLO
-
- # 模型加载权重
- model = YOLO(r'D:\yolov8\runs\detect\train\weights\best.pt')
- # 视频路径
- cap = cv2.VideoCapture(0)
- # 对视频中检测到目标画框标出来
- while cap.isOpened():
- # Read a frame from the video
- success, frame = cap.read()
-
- if success:
- # Run YOLOv8 inference on the frame
- results = model(frame,conf=0.7)
-
- # Visualize the results on the frame
- annotated_frame = results[0].plot()
-
- # Display the annotated frame
- cv2.imshow("YOLOv8 Inference", annotated_frame)
-
- # Break the loop if 'q' is pressed
- if cv2.waitKey(1) & 0xFF == ord("q"):
- break
- else:
- # Break the loop if the end of the video is reached
- break
-
- # Release the video capture object and close the display window
- cap.release()
- cv2.destroyAllWindows()

只需要在捕获的图像帧中,在mode(frame,conf=?,show=?)设置即可。就跟终端的推理代码一样。(yolo task=detect mode=predict model=D:\yolov8\runs\detect\train\weights\best.pt source=0 device=0 show=True)
2.自己发现的问题
我一开始推理的时候非常卡,我以为是电脑是不行,通过查询,我得知是因为我调用函数的问题。
我一开始的代码是:
- while cap.isOpened():
- success, frame = cap.read() # 读取摄像头的一帧图像
- results = model(frame)
- if success:
- model.predict(source=frame, show=True) # 对当前帧进行目标检测并显示结果
- # 通过按下 'q' 键退出循环
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
啊错错错!这样卡死了!
后面经过排查,确认了是因为通过函数model.predict(source=frame, show=True)显示图片结果很慢!
后面改了一种显示方法:
- while cap.isOpened():
- success, frame = cap.read() # 读取摄像头的一帧图像
- results = model(frame)
- annotated_frame = results[0].plot()
- if success:
- cv2.imshow("YOLOv8 Inference", annotated_frame)
- # 通过按下 'q' 键退出循环
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
啊对对对,通过cv.imshow来显示,速度快多了。
8.问题合集
1 import importlib.metadata ModuleNotFoundError: No module named 'importlib.metadata'
额,好好好,原来你也安装了3.8以下版本。。
没办法,重新安装环境吧......下次改成python=3.8就好
删除环境:conda remove -n 环境名字 --all
2 “ImportError: DLL load failed while importing _imaging: 找不到指定的模块”的错误
[完美解决]出现“ImportError: DLL load failed while importing _imaging: 找不到指定的模块”的错误-CSDN博客
3 Usage: yolo [OPTIONS] COMMAND [ARGS]...
Try 'yolo -h' for help.
Error: No such command 'task=detect'.
解决办法:
YOLOv8推理使用(指令讲解+报错解决方法)_yolov8 pt推理代码-CSDN博客
4.ConnectionError: Download failure for https://github.com/ultralytics/assets/releases/download/v8.1.0/yolov8n.pt. Retry limit reached.
这个是说连不上github,搞个加速器就好了。
5. raise RuntimeError(emojis(f"Dataset '{clean_url(self.args.data)}' error ❌ {e}")) from e e
RuntimeError: Dataset '
听不懂思密达,估计是网络不太好。我是再输入同样的指令,等他训练
下面一堆问题我把它归结为设备性能问题:
6.raise RuntimeError( DataLoader worker (pid(s) {}) exited unexpectedly .format(pids_str)) from e RuntimeError: DataLoader worker (pid(s) 23984, 15984) exited unexpectedly
这个问题解决后我就可以开始训练了...(性能问题优先考虑我这个方法,下面的问题我都没找到好的解决办法,只有解决这个问题,我的程序才开始训练)
一开始我在终端输入的是:yolo task=detect mode=train model=yolov8s.pt data={dataset.location}/data.yaml epochs=100 imgsz=640 resume=True
然后就会出现各种报错,通过查找资料,我发现是因为在yolov8中,默认workers=8好像,这样的话,对电脑要求特别高。通过修改代码:
yolo task=detect mode=train model=yolov8s.pt data={dataset.location}/data.yaml epochs=100 imgsz=640 resume=True workers=2
我就可以开始训练了......
7.for i, (f, n, m, args) in enumerate(d[backbone] + d[head]): # from, number, module, args KeyError: backbone
这个我不太懂,当时我再运行一遍就出现了别的问题
8.RuntimeError: cuda runtime error (2) : out of memory at ..\aten\src\THC\THCCachingHostAllocator.cpp:278
网上说显卡内存不足,在任务管理器关闭程序
9.OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading
10.RuntimeError: CUDA out of memory. Tried to allocate 76.00 MiB (GPU 0; 8.00 GiB total capacity; 112.42 MiB already allocated; 5.61 GiB free; 130.00 MiB reserved in total by PyTorch)
同8.一样显存爆炸,我也是通过修改workers=2解决的。
磁盘分配虚拟内存问题,设置完应该要重启电脑。
11.WARNING ⚠️ no labels found in detect set, can not compute metrics without labels
检查数据集,可能是名字没有按照规定来填写,或者转换xml转换成txt中间出现错误
如果都没有问题,看看是不是因为你cd .../进去了一个路径然后在终端执行的命令。这样的话它找不到根目录里面的图片。退出pycharm再重进
12.TensorFlow installation not found - running with reduced feature set.
没安装TensorFlow
13.No dashboards are active for the current data set.
这个你得进入你的训练路径,例如:cd D:\yolov8\runs\detect\train
然后再输入 tensorboard --logdir="D:\yolov8\runs\detect\train"
14.WARNING ⚠️ data\images\90fdf0069a4b337d9181dd2b1a2b0de.jpg: corrupt JPEG restored and saved
应该跟11类似,数据集的问题。检查一下路径,名字,还有文件里面的内容
15.ValueError: not enough values to unpack (expected 3, got 0)
很大可能是你cd D:\yolov8\runs\detect\train进去了一个文件,里面执行训练代码,导致他找不到这个文件以外的东西。退出pycharm重新进去执行训练代码即可。
遇到的问题大概就这么多,还有问题的话可以再评论区问,我找到解决方法就会更新下文章。

