
- 1字节跳动被爆猛料:海外审核部门一锅端,转岗“难于上青天”
- 2Linux MMC子系统 - 5.eMMC 5.1工作模式-引导模式_mmc的数据传输模式
- 3python2.7 print的用法,Python中print函数报错
- 4苹果电脑可以玩魔兽世界吗 魔兽世界有mac版本么 macbook 可以玩魔兽世界吗_mac玩魔兽世界
- 5进入AI领域做产品 —— 我的自学之路(CV-人脸识别)_人脸识别需要多少个像素点
- 6文本数据预处理_文本数据的预处理
- 7基于信号到达角度(AOA)的无线传感器网络定位——最大似然估计_最大似然估计到达角
- 8【网络协议】精讲DHCP协议!图解超赞超详细!!!_dhcp格式详解
- 9SAP PP学习笔记31 - 计划运行的步骤2 - Scheduling(日程计算),BOM Explosion(BOM展开)
- 10达梦 8 函数 —— 从常用函数到分析函数_达梦数据库常用函数
聚类算法之DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
赞
踩
注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
DBSCAN是在1990年代后期推出的一种聚类方法,它迅速成为基于密度的聚类技术中最受欢迎和广泛使用的算法之一。与传统的聚类方法如K-means不同,DBSCAN的主要优势在于其能够识别出任意形状的聚类,并有效地处理噪声。在机器学习和数据分析领域,该算法常被用于其高鲁棒性和对形状的不受限制的处理能力。
1. 算法解读:
DBSCAN是一种基于密度的聚类方法,其基本思想是:在一个特定的半径内有足够多的点,则这些点构成一个“密集”区域。根据这一思想,DBSCAN将数据点分类为核心点、边界点和噪声点。这些基本概念的解释如下:
核心点:在其半径ε内,存在超过 MinPts 数量的其他点,那么这个点被称为核心点。这意味着核心点周围有足够多的邻居,构成了一个“密集”区域。
边界点:在其半径ε内有少于MinPts数量的邻居点,但是它离某个核心点足够近,可以被归入某个聚类。
噪声点:既不是核心点,也不是边界点被认为是噪声点,它们不属于任何聚类。
MinPts:MinPts是一个用户定义的参数,表示一个点的邻域中最小的数据点数量,用于判断该点是否为核心点。如果一个点的半径ε内的邻居点数量不少于MinPts,那么这个点被认为是核心点,反之则不是。
DBSCAN首先任意选择一个点,并检查其邻居点的数量。如果该点是一个核心点,一个新的聚类将开始。否则,该点被标记为噪声。然后,DBSCAN会继续探索这个核心点的邻居,并将它们添加到同一个聚类中。这个过程递归地继续,直到聚类完成。
2. 步骤和细节:
1.初始化:
将所有数据点标记为未处理。
2.选择一个随机点:
随机选择一个未被标记处理的点。
3.寻找近邻:
计算该点在半径 ε 内的所有邻居点。
这些邻居点是基于用户定义的距离度量(例如欧几里得距离)和半径 ε 确定的。
4.检查核心点与创建聚类:
如果该点的邻居数量不少于 MinPts,那么该点被标记为核心点。
为该核心点创建一个新的聚类,并将其和它的邻居点加入这个聚类。
如果该点的邻居数量少于 MinPts,那么先暂时将其标记为噪声点。
5.扩展聚类:
对于新聚类中的每一个核心点,查找其在半径 ε 内的所有邻居。
对于每个邻居点,如果它是未处理的,将其标记为已处理,并加入当前聚类。如果这个邻居点有不少于 MinPts 的邻居,那么它也是一个核心点,需要继续查找其邻居。
重复上述过程,直到当前聚类中所有核心点的邻居都被考虑过。
6.重复:
返回到步骤2,选择下一个未处理的点。
重复步骤3-5,直到所有的点都已被处理。
7.最终结果:
所有没有被归入任何聚类的噪声点,保持为噪声点。
输出所有找到的聚类。
3. 举例:
想象一下,你在一个大型公园里,有很多人在聚会。我们想要找出哪些人是一起聚会的,哪些人是孤独的,不属于任何聚会。
初始化:开始时,我们看到的每个人都是单独的,没有归入任何聚会。
选择一个人:我们随机走到一个人旁边,观察他周围是否有其他人。
寻找近邻:我们查看这个人周围一定距离(例如3米)内是否有其他人。这个距离就像是DBSCAN中的半径ε。
检查核心点与创建聚会:
如果这个人周围有不少于MinPts(例如3个)的人,我们就认为他们是在一起聚会的,这个人就像是核心点。我们将这个人和他周围的人标记为一个聚会组。如果周围人数少于3个,我们先暂时认为这个人是孤独的,不属于任何聚会。
扩展聚会:
接下来,我们继续观察刚刚找到的聚会组中的每个人,查看他们周围是否还有其他人。如果有,我们就将这些人也归入这个聚会组,如果其中有人周围也有3个及以上的人,我们还需要继续观察他们周围的人。这个过程一直持续,直到我们找不到更多属于这个聚会组的人。
换句话说,对于这些人的每一个邻居,无论其周围是否有3个以上的人,都会被加入到聚会组中。但是,如果某个邻居B的周围确实有3个以上的人,我们就需要继续观察B的邻居,看是否有更多的人可以加入到聚会组中,因为B作为一个“聚会的中心”有可能将更多的人聚集在一起。
重复:
我们再随机找一个还没有归入任何聚会组的人,重复上述过程。
这样不断重复,直到公园里的每个人都被我们观察过。
最终结果:
最后,我们就能找出公园里所有的聚会组,以及那些孤独的人。
这个类比中,人就像是数据点,聚会组就像是聚类,孤独的人就像是噪声点。希望这个生活中的例子能帮助你更直观地理解DBSCAN的工作原理。
代码实现
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.cluster import DBSCAN
- from sklearn.datasets import make_blobs
-
- # 设置随机种子以保证结果的可重复性
- np.random.seed(0)
-
- # 创建三个聚会组的数据点
- cluster_1 = np.random.normal(loc=5, scale=1, size=(15, 2)) # 聚会组1
- cluster_2 = np.random.normal(loc=15, scale=1, size=(15, 2)) # 聚会组2
- cluster_3 = np.random.normal(loc=25, scale=1, size=(15, 2)) # 聚会组3
-
- # 创建一些孤立的点
- noise = np.array([[2, 3], [3, 18], [17, 4], [22, 15]])
-
- # 将所有点合并成一个数据集
- data = np.vstack([cluster_1, cluster_2, cluster_3, noise])
-
- # 可视化原始数据点
- plt.scatter(data[:, 0], data[:, 1], c='black', label='People')
- plt.xlabel('X Coordinate')
- plt.ylabel('Y Coordinate')
- plt.title('People in the Park')
- plt.legend()
- plt.show()
-
- # 设置DBSCAN算法的参数
- epsilon = 3 # 半径ε
- min_samples = 3 # MinPts
-
- # 应用DBSCAN算法
- dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
- dbscan.fit(data)
-
- # 获取聚类结果
- labels = dbscan.labels_
-
- # 可视化聚类结果
- plt.scatter(data[labels == -1][:, 0], data[labels == -1][:, 1], c='black', label='Noise')
- for i in range(max(labels) + 1):
- plt.scatter(data[labels == i][:, 0], data[labels == i][:, 1], label=f'Cluster {i + 1}')
- plt.xlabel('X Coordinate')
- plt.ylabel('Y Coordinate')
- plt.title('DBSCAN Clustering')
- plt.legend()
- plt.show()
-
- # 返回聚类标签
- labels

代码结果:
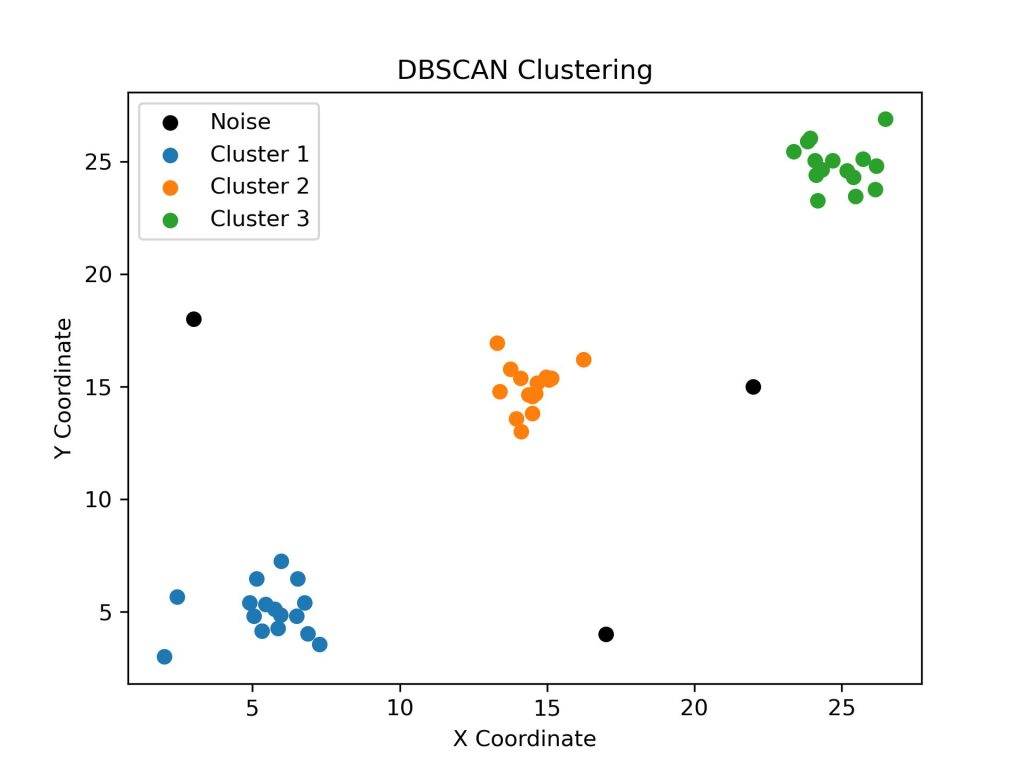
在这个模拟实例中,我们生成了三个聚会组(Cluster 1, Cluster 2, Cluster 3)以及一些孤立的点(标记为Noise)。你可以在第一张图中看到这些原始的“人群”分布,其中每个点代表一个人。
接着,我们使用DBSCAN算法进行聚类。设置的参数为:半径 ε=3,MinPts(最小邻居点数)为 3。通过这个设置,算法成功地将三个聚会组识别了出来,并将孤立的点标记为了噪声,你可以在第二张图中看到聚类的结果。
最后,聚类标签labels数组中的每个元素代表相应点的聚类标识。标签为 -1 的点表示噪声点,其他正数标签表示点所属的聚类编号。
这个模拟实例展示了DBSCAN如何在有噪声的情况下,成功地识别出不同的聚类。希望这有助于你更直观地理解DBSCAN算法的运作方式。
4. 算法评价:
优点:
形状灵活:能够发现任意形状的聚类,不仅仅是球形。
动态聚类数:不需要预先指定聚类的数量。
噪声处理:可以区分出噪声点和边界点。
缺点:
参数敏感:ε和MinPts的选择会直接影响聚类的结果。
密度不均:当聚类具有显著不同的密度时,可能难以得到好的结果。
DBSCAN是一个强大的聚类方法,特别是当数据集中的聚类形状是不规则的或者当数据中存在大量噪声时。它的优点在于能够自动确定聚类的数量并有效地隔离噪声。然而,选择正确的参数(如ε和MinPts)是非常关键的,因为这会直接影响到聚类的质量。在现实世界中,DBSCAN被广泛应用于各种领域,如天文学、生物学、地理信息系统和计算机视觉。
5. 算法的变体:
HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)是一种基于层次的、用于识别具有噪声的空间聚类的算法,它是DBSCAN算法的扩展。该算法由R. J. G. B. Campello, D. Moulavi, 和J. Sander在2013年提出,目的是解决DBSCAN在处理不同密度聚类时的一些局限性。
基本原理为:HDBSCAN与DBSCAN共享相同的核心概念,即通过密度来定义聚类。然而,HDBSCAN通过构建层次结构,实现了对数据集中不同密度区域的聚类,使其更加灵活和稳健。
具体来说,HDBSCAN首先计算数据点之间的成对距离,然后基于这些距离构建一个最小生成树(Minimum Spanning Tree, MST)。 算法在最小生成树的基础上进行层次聚类,形成一个扩展的聚类树。在这个树中,叶节点代表原始数据点,而内部节点代表不同层次的聚类。最后,HDBSCAN通过一种基于稳定性的方法剪枝聚类树,以识别最终的聚类。这一步骤使得HDBSCAN能够识别并忽略噪声点,同时确定不同密度的聚类。
优点:
不同密度聚类:HDBSCAN能够自适应地识别不同密度的聚类,这是其相对于DBSCAN的显著优势。
无需预设聚类数量:与DBSCAN一样,HDBSCAN不需要用户预先设定聚类的数量。
灵活性:由于其层次性质,HDBSCAN可以适应各种形状和规模的聚类。
引用:
Campello, R. J. G. B., Moulavi, D., & Sander, J. (2013). Density-Based Clustering Based on Hierarchical Density Estimates. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 160-172). Springer, Berlin, Heidelberg.

