
- 1flink sql groupBy 使用注意_flink sql group by
- 2llama-index调用qwen大模型实现RAG_llamaindex qwen
- 3自制一个桌面宠物小狗(STM32hal库+ADC+IIC+DMA+PWM输出波)_stm32桌面小宠物
- 4[学习笔记] python深度学习---第七章 深度学习最佳实践_深度学习 不同的输入分别学习再组合
- 5医院预约挂号管理系统SSM+jsp
- 6MySQL 设置用户权限步骤_mysql权限设置
- 7从零开始构建基于ChatGPT的嵌入式(Embedding)本地医疗客服问答机器人模型(看完就会,看到最后有惊喜)
- 8数据库---索引和事务
- 9RabbitMQ笔记二_rabbitmq clientid
- 10weblogic 10.3.6.0 版本升级3L3H补丁_weblogic遇到无法识别的补丁
ARL灯塔魔改,自动化资产搜集+漏扫+推送+1W加指纹
赞
踩
0x01 前言
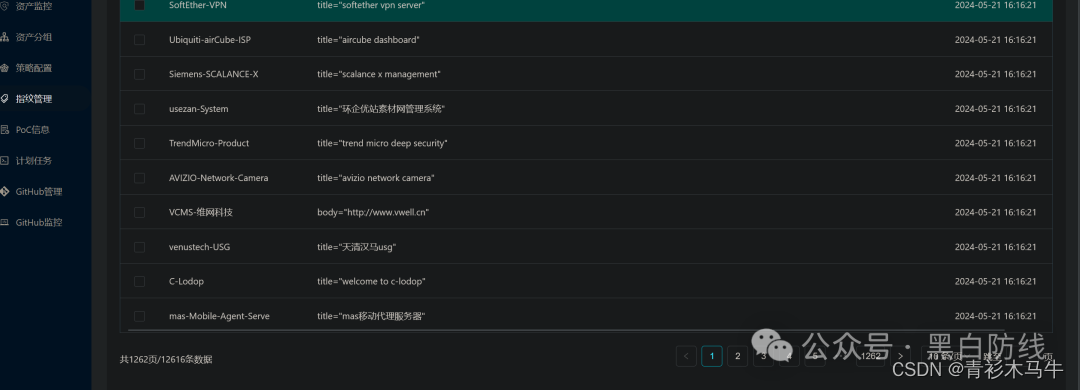
灯塔删库了,没有灯塔我该怎么活,在搭建这一套自动化资产搜集+漏扫体系之前,我一般是使用网络搜索引擎(fofa、zoomeye、hunter等)和C段ip进行资产搜集,然后批量指纹扫描工具(Ehole、Glass等)进行指纹识别,使用xray、nuclei进行批量漏扫。按照之前使用的打点流程存在缺陷,总觉得不太好用,打算强化一下灯塔
0x02 准备工作
一台或两台linux服务器:
一台:
配置:64位+2核4G+带宽100Mbps
两台:
服务器A:64位+2核4G (灯塔最低配置要求)
服务器B:100Mbps
ps:我这里使用的两台vps,一台国内阿里云搭建灯塔系统,一台国外vps作为漏扫服务器,两台
vps使用的操作系统均为centos
灯塔ARL【资产收集】:https://github.com/TophantTechnology/ARL
httpx 【存活检测】:https://github.com/projectdiscovery/httpx
anew【过滤重复】:https://github.com/tomnomnom/anew
nuclei【漏洞扫描】:https://github.com/projectdiscovery/nuclei
python3.10【推送钉钉】:推荐使用3.7,这里3.10太高了导致openssl需要安装最新版,涉及重新
编译openssl、python3,比较麻烦。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
0x03 工具安装配置
3.1 灯塔ARL
3.1.1 安装docker环境
安装一些依赖
sudo yum install -y yum-utils device-mapper-persistent-data lvm2 wget
下载repo文件
wget -O /etc/yum.repos.d/docker-ce.repo
https://download.docker.com/linux/centos/docker-ce.repo
把软件仓库地址替换为 TUNA:
sudo sed -i 's+download.docker.com+mirrors.tuna.tsinghua.edu.cn/docker-ce+'
/etc/yum.repos.d/docker-ce.repo
安装
sudo yum makecache fast
sudo yum install docker-ce
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.1.2 docker compose 安装
先安装pip,python3进行安装
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.py
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple docker-compose
- 1
- 2
- 3
- 4
- 5
3.1.3 ARL灯塔安装
这里我使用的是基于斗象灯塔ARL修改后的版本。相比原版,增加了OneForAll、中央数据库,修改了altDns
项目地址:https://github.com/ki9mu/ARL-plus-docker
ps:2.8.0版本以后无oneforall,所以用的2.7
使用wegt,或者本地下载上传到服务器后进行解压,下面是2.7的压缩包地址
https://github.com/ki9mu/ARL-plus-docker/archive/refs/tags/v2.7.1.zip
unzip 解压
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这是解压后的样子,自带一个docker-compose.yml文件
接下来很重要
docker volume create arl_db
docker-compose up -d
- 1
- 2
查看运行状况,如下图所示说明运行正常

3.1.4 登录并修改密码
url:http://127.0.0.1:5003
登录凭证:admin/arlpass
- 1
- 2
- 3
3.1.5 多用户登录
由于灯塔本身没有设计用户管理的功能,而且是单点登录,如果有多用户登录需求的需要到数据库中添加用户
# 可以使用下面的命令添加多个平行用户, 使用 admin1/admin123 可登录
docker exec -ti arl_mongodb mongo -u admin -p admin
use arl
db.user.insert({ username: 'admin1', password: hex_md5('arlsalt!@#'+'admin123')
})
- 1
- 2
- 3
- 4
- 5
- 6
3.1.6 修改配置文件
config-docker.yaml中的61行,取消域名限制

添加指纹
https://github.com/loecho-sec/ARL-Finger-ADD
- 1
- 2
3.2 anew
anew没有发布编译好的二进制文件,需要下载源码下来自行编译,这里我windows已经安装了go语言环境,在windows环境下编译生成linux二进制文件命令如下:
# 需要在命令行界面,powershell无法配置go环境变量
SET CGO_ENABLED=0
SET GOARCH=amd64
SET GOOS=linux
go build main.go
- 1
- 2
- 3
- 4
- 5
- 6
anew主要将输出与旧文件进行比较,只会输出新添加的内容,并且将新添加的内容加到旧文件。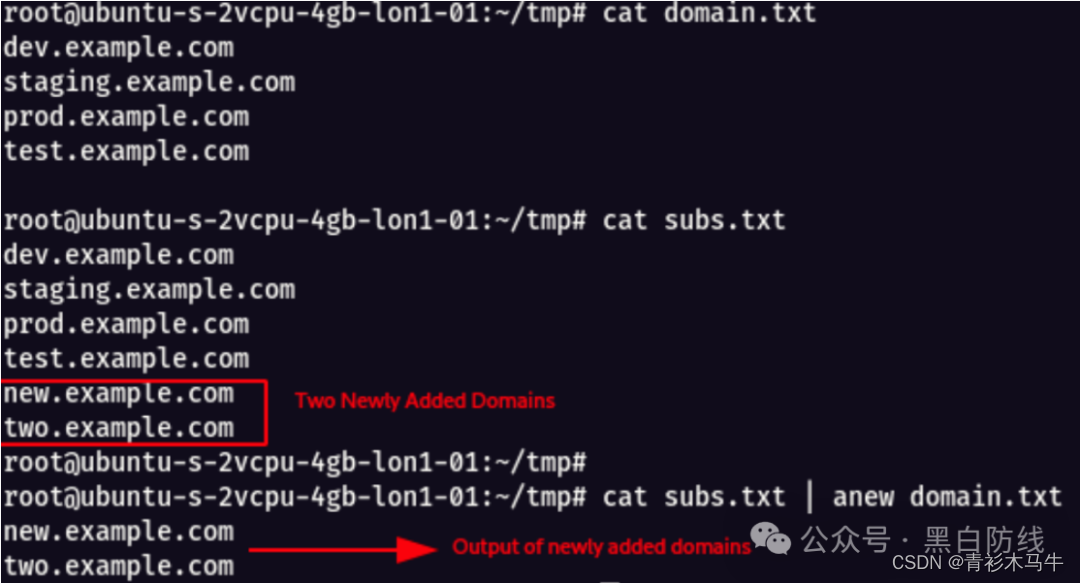 将anew上传服务器之后,赋予权限和配置软连接
将anew上传服务器之后,赋予权限和配置软连接
chmod 777 anew
ln -s /root/tools/anew/anew /usr/bin/anew
- 1
- 2
- 3
配置完之后可以直接使用命令行使用

3.3 httpx
httpx可以用于探测站点是否存活,灯塔收集的站点可能存在各种返回状态码,httpx这里就能够再筛查一次,将httpx上传服务器之后,赋予权限和配置软连接
chmod 777 httpx
ln -s /root/tools/httpx_1.2.0_linux_amd64/httpx /usr/bin/httpx
- 1
- 2
- 3
配置完之后可以直接使用命令行使用
3.4 nuclei
3.4.1 nuclei介绍
Nuclei 基于模板跨目标发送请求,扫描速度快且准确度高,可一键更新模板库,模板库来源于nuclei社区,活跃度还是比较高的,因此模板更新速度也比较客观。需要使用go语言编译搭建
3.4.2 nuclei安装
git clone https://github.com/projectdiscovery/nuclei.git
cd nuclei/v2/cmd/nuclei
go build
mv nuclei /usr/local/bin/
nuclei -version
- 1
- 2
- 3
- 4
- 5
- 6
安装完之后可以直接使用命令行运行nuclei
3.5 灯塔资产获取
3.5.1灯塔api配置
灯塔提供了api接口文档,地址:https://ip:5003/api/doc
要使用api接口爬取数据,首先要配置一个apikey
进入arl目录
vim config-docker.yaml
- 1

api-key可以自己设定
API_KEY:"ff44256c-xxxx-xxxx-xxxx-xxxxxxxxxxx"
- 1
- 2
设置好之后重启下灯塔
docker-compose restart
- 1
进入api接口文档,在如下位置输入设置的api-key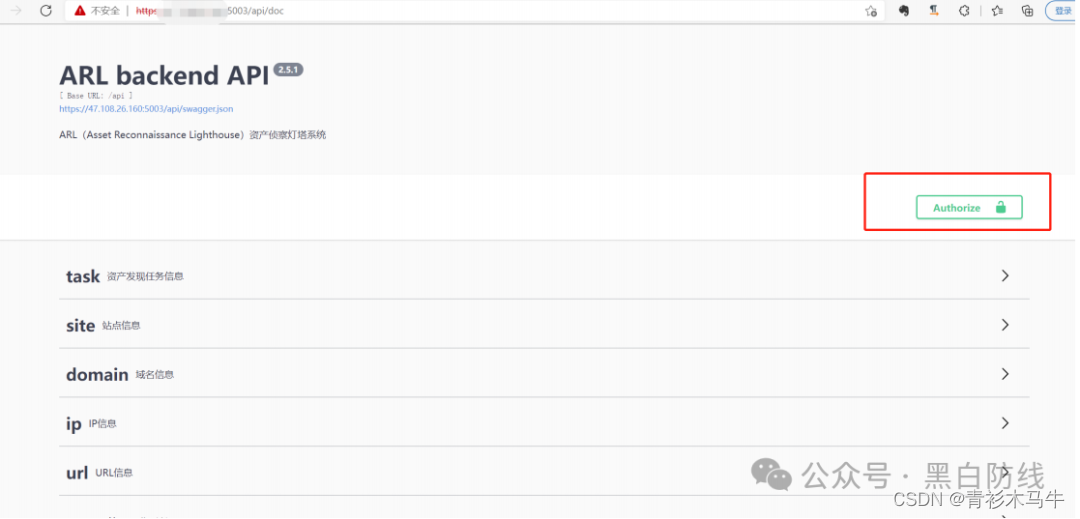
设置好之后可以现在网页端的接口文档进行调试使用,检查是否生效,能否正常获取数据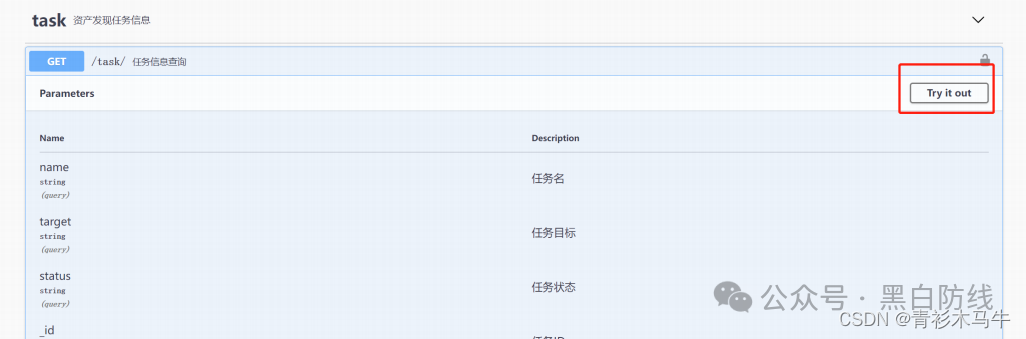
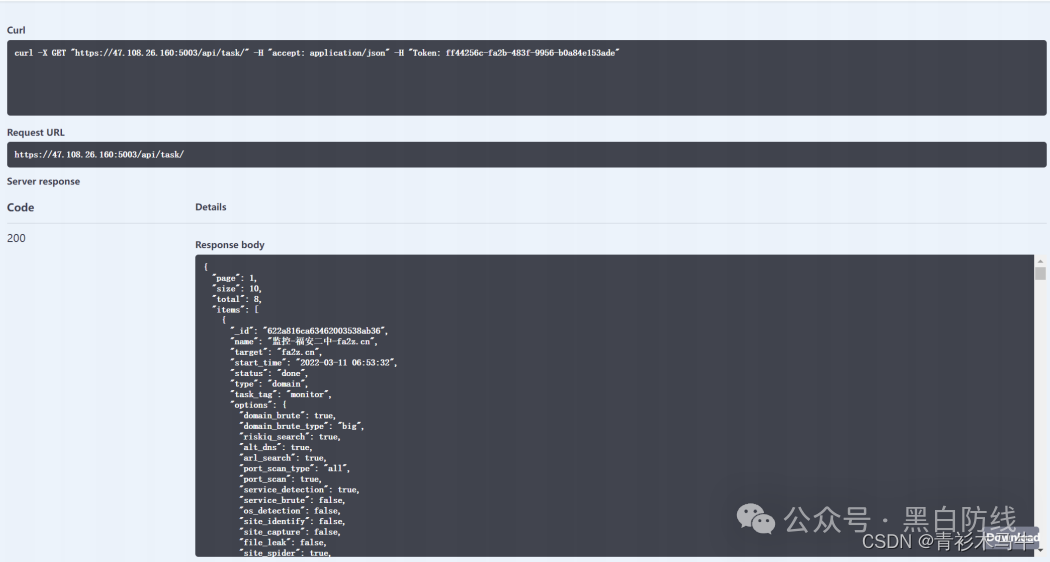
以上调试无异常之后,开始构造数据包,灯塔的认证是在头部加入Token字段即可
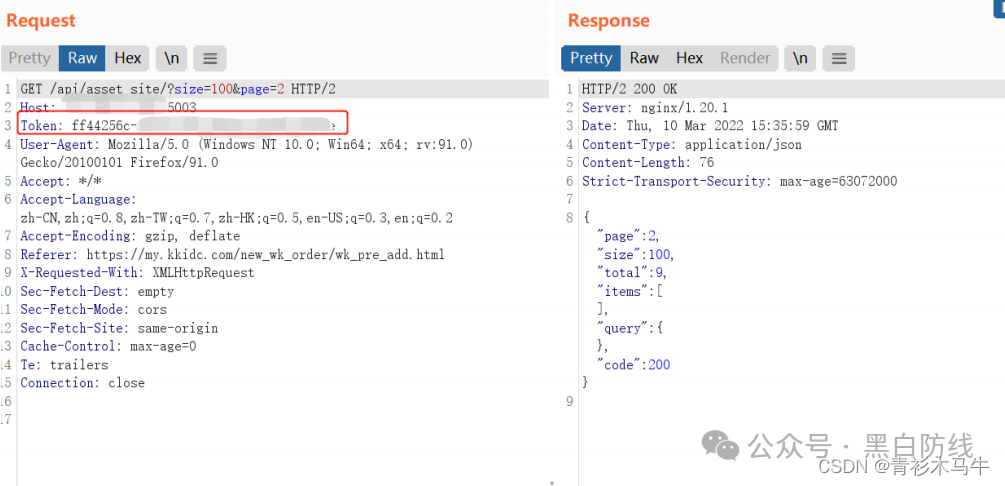
3.5.2 编写脚本
import optparse import requests apikey = "ff44256c-xxxx-xxxx-xxxx-xxxxxxxxxxxx" requests.packages.urllib3.disable_warnings() def print_hi(name): # Use a breakpoint in the code line below to debug your script. print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint. def task(scope_id): headers = { 'accept': 'application/json', 'Token': apikey } ceshi = requests.get("https://ip:5003/api/asset_site/? size=100&scope_id="+scope_id, headers=headers, verify=False) json1 = ceshi.json() number = json1['total'] pages = number//100 pages += 1 for page in range(1,pages+1): data = requests.get("https://ip:5003/api/asset_site/? page="+str(page)+"&size=100&scope_id="+scope_id, headers=headers, verify=False) json_data = data.json() items = json_data['items'] for item in items: print("%s" %(item['site'])) # Press the green button in the gutter to run the script. if __name__ == '__main__': parser = optparse.OptionParser('python3 arlGetAassert.py -s scope_id -o result.txt\n' 'Example: python3 arlGetAassert.py -s 6229835c322616001dd91fe4\n') parser.add_option('-s', dest='scope_id', default='6229835c322616001dd91fe4', type='string', help='scope_id 资产范围ID') (options, args) = parser.parse_args() task(options.scope_id)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
代码很简单,大概解释一下流程,这里调用api通过scope_id参数(资产组id)去筛出想要获取的资产组的站点信息,先获取总数,在爬取每一页的数据。资产组id就是下面这个字符串,每次新建一个资产组,就会分配一个资产组id: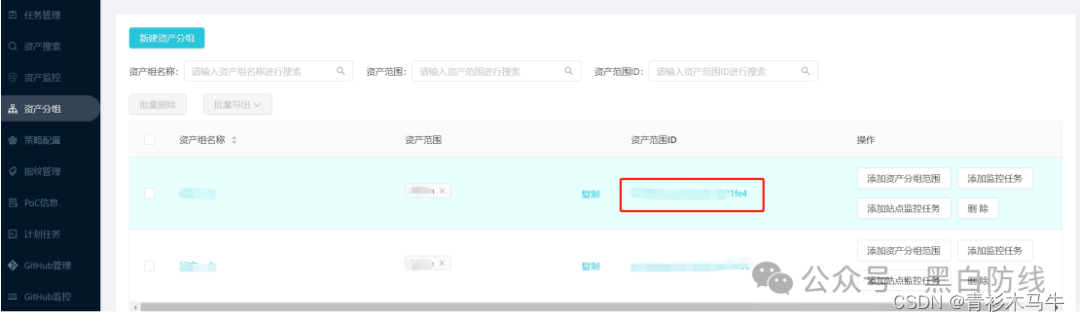
这里运行看下结果

可以看到,顺利获取到数据
3.6 配置钉钉机器人
3.6.1 推送灯塔资产
先在群里新建一个机器人
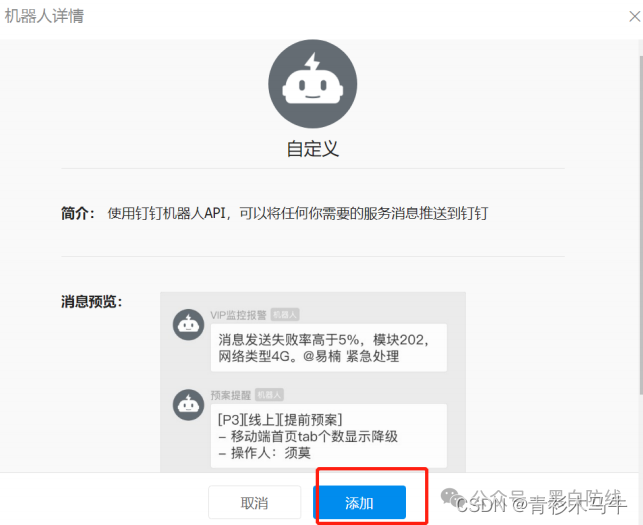
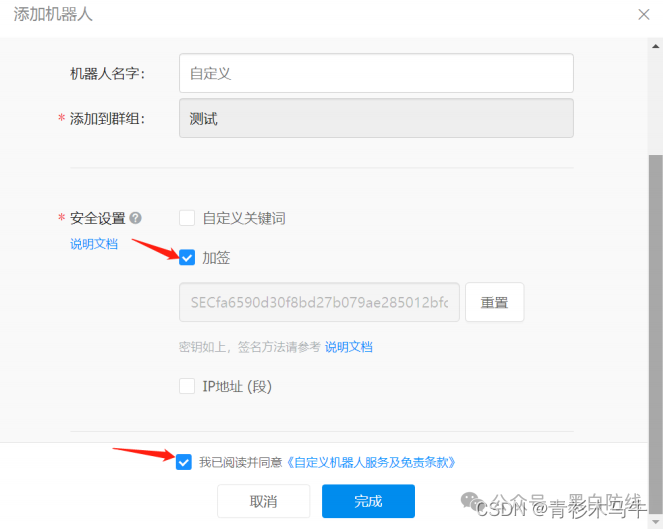
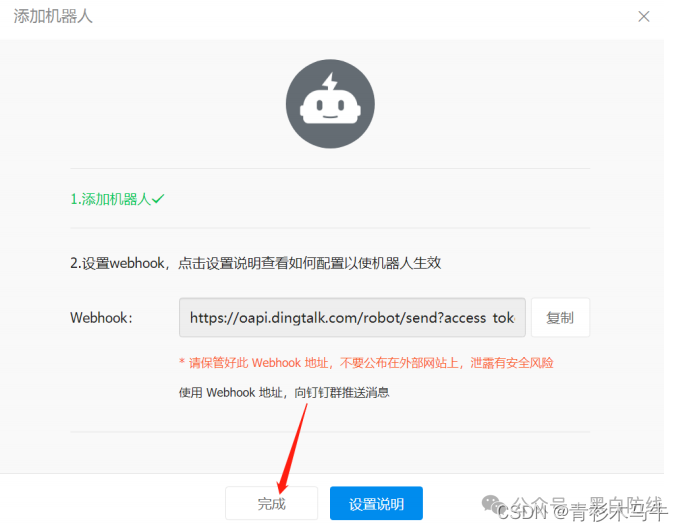
将webhook的access_token保存留用
进入灯塔配置文件
vim config-docker.yaml
- 1

SECRET对应着钉钉机器人的签名密钥
ACCESS_TOKEN对应着钉钉机器人webhook的access_token
配置完之后重启灯塔,测试配置是否成功
docker-compose exec worker bash
python3.6 -m test.test_utils_push
- 1
- 2
成功的话钉钉会收到消息推送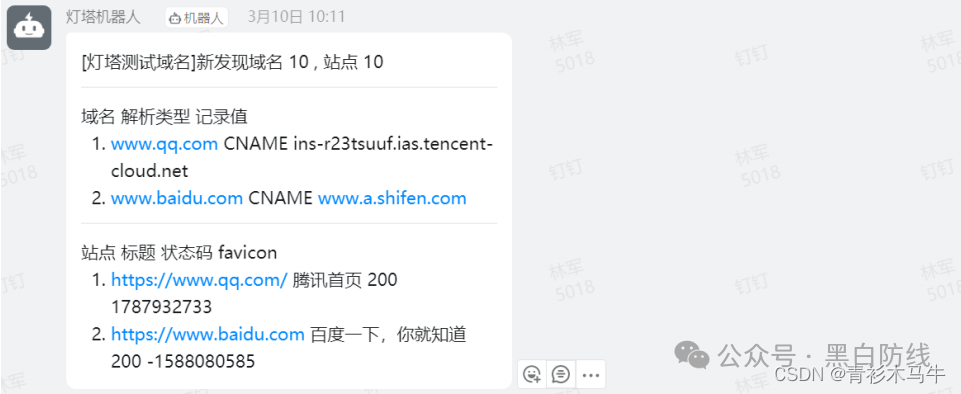
3.6.2 推送nuclei漏扫数据
钉钉机器人要求一定要进行安全设置。
安全设置目前有三种方式
方式一,自定义关键词
最多可以设置10个关键词,消息中至少包含其中1个关键词才可以发送成功。
例如:添加了一个自定义关键词:监控报警
在你写的代码中,让这个机器人所发送的消息必须包含“监控报警”这个词,才能发送成功。否则会出现keyword not in content。错误。
方式二,加签
第一步,把timestamp+“\n”+密钥当做签名字符串,使用HmacSHA256算法计算签名,然后进行Base64 encode,最后再把签名参数再进行urlEncode,得到最终的签名(需要使用UTF-8字符集)。
参数 说明
timestamp 当前时间戳,单位是毫秒,与请求调用时间误差不能超过1小时
secret 密钥,机器人安全设置页面,加签一栏下面显示的SEC开头的字符串
- 1
- 2
- 3
- 4
签名计算代码示例
#python 2.7 import time import hmac import hashlib import base64 import urllib timestamp = long(round(time.time() * 1000)) secret = 'this is secret' secret_enc = bytes(secret).encode('utf-8') string_to_sign = '{}\n{}'.format(timestamp, secret) string_to_sign_enc = bytes(string_to_sign).encode('utf-8') hmac_code = hmac.new(secret_enc, string_to_sign_enc, digestmod=hashlib.sha256).digest() sign = urllib.quote_plus(base64.b64encode(hmac_code)) print(timestamp) print(sign)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
第二步,把 timestamp和第一步得到的签名值拼接到URL中。
https://oapi.dingtalk.com/robot/send?access_token=XXXXXX×tamp=XXX&sign=XXX
- 1
- 2
方式三,IP地址(段)
设定后,只有来自IP地址范围内的请求才会被正常处理。支持两种设置方式:IP、IP段,暂不支持IPv6地址白名单,格式如下
安全设置的上述三种方式,需要至少设置其中一种校验不通过的消息将会发送失败,错误如下
// 消息内容中不包含任何关键词 { "errcode":310000, "errmsg":"keywords not in content" } // timestamp 无效 { "errcode":310000, "errmsg":"invalid timestamp" } // 签名不匹配 { "errcode":310000, "errmsg":"sign not match" } // IP地址不在白名单 { "errcode":310000, "errmsg":"ip X.X.X.X not in whitelist" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
编写脚本
import requests import json import sys def ding_push_message(msg): # 构建请求头部 header = { "Content-Type": "application/json", "Charset": "UTF-8" } # 构建请求数据 message = { "msgtype": "text", "text": { "content": msg }, # 设置@所有人 "at": { "isAtAll": True } } # 对请求的数据进行json封装 message_json = json.dumps(message) # 发送请求 info = requests.post(url=web_url, data=message_json, headers=header) # 打印返回的结果 print(info.text) if __name__ == "__main__": # 请求的URL,WebHook地址 web_url = "https://oapi.dingtalk.com/robot/send?access_token=xxx" # 构建请求数据 file = sys.argv[1] keyword = sys.argv[2] with open(file) as f: data = f.read() if data == '': data = '未发现新漏洞' ding_push_message("[漏洞监控-"+keyword+"]\n"+str(data))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
这里可以输入任意message进行测试检查能否正常推送
可以看到正常推送了
0x04 自动化命令
部署完以上所有工具后,即可使用命令进行无止尽的自动探测,在linux下输入如下指令:
while true; do python3 arlGetAassert.py -s 6229835c322616001dd91fe4 | anew
urls.txt | httpx | nuclei -es info -o result.txt ;python3 dingding.py result.txt
; sleep 3600; done
- 1
- 2
- 3
- 4
流程大概如下:
先用脚本获取灯塔数据进行资产收集,并通过anew来过滤历史域名,把监测到的新资产送给httpx存活检测,httpx把存活的资产送给nuclei进行漏洞扫描,-es info的意思是排除扫描info级别的漏洞。扫描结束后,会使用python脚本把漏洞结果发送到我们钉钉推送,这样一个循环就结束了,并等待3600秒,也就是1小时。
0x05 结语
这套体系刚搭建完,目前体验还是不错的,但仍然有提升优化的空间,可以在灯塔api开发的基础上多写几个脚本用于搜索资产、增加资产等,我这里部署完灯塔之后明显能感觉到web端访问响应速度体验并不是很好,使用api进行操作能够提高速度。
然后的话就是灯塔收集资产是需要提供根域名的,这里并没有集成搜集根域名的方式,可以在后续进行优化提升,除此之外,灯塔收集的资产有限,还可以结合其他资产收集工具进行资产收集,同时也可以集成指纹识别的工具并进行钉钉推送,提高渗透效率。
最后,篇幅较为冗长,感谢能够看到这里,整体涉及的所有步骤都写了,如果觉得有所收获的话,麻烦点个关注支持下啦。



