
- 1sqlserver2012用ip远程连接设置_remote dac enable
- 2基于时空注意力机制的图卷积神经网络交通流预测(附数据集下载方式)
- 3(转)测试开发之路--聊聊自动化的打开方式
- 4鸿蒙(API 12 Beta2版)【使用命令行CMake构建NDK工程】
- 5人工智能深度学习框架,AI深度学习使用iTOP-3399开发板_对于初学人工智能专业的学生,有什么合适的开发板吗
- 6有关嵌入式、单片机、51单片机、STM32、的一些概念详解_嵌入式单片机
- 7Hadoop+hive+flask+echarts大数据可视化项目之flask结合echarts前后端结合显示hive分析结果_hadoop+hive+spark+通过系统进行结果可视化展现.
- 8作为一名35岁的测试人,拿我的经历给焦虑的朋友们一点借鉴。_35岁测试
- 9记录一个husky和commitlint的报错以及使用方式_安装husky报错
- 10Java并发:阻塞队列_controller 如何使用java队列?
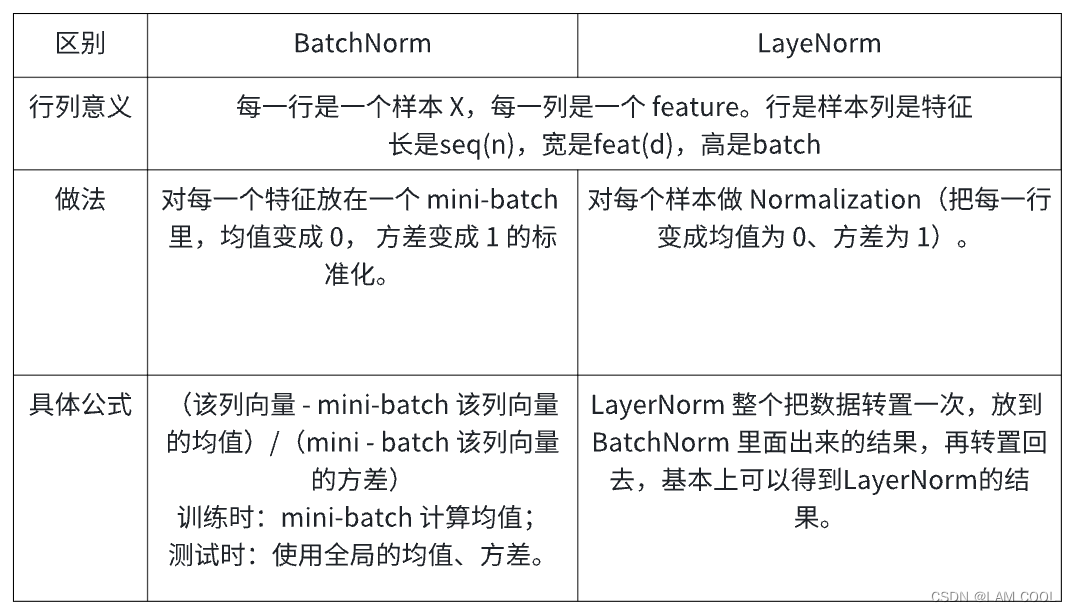
【深度学习入门】深度学习基础_深度学习基础模型
赞
踩
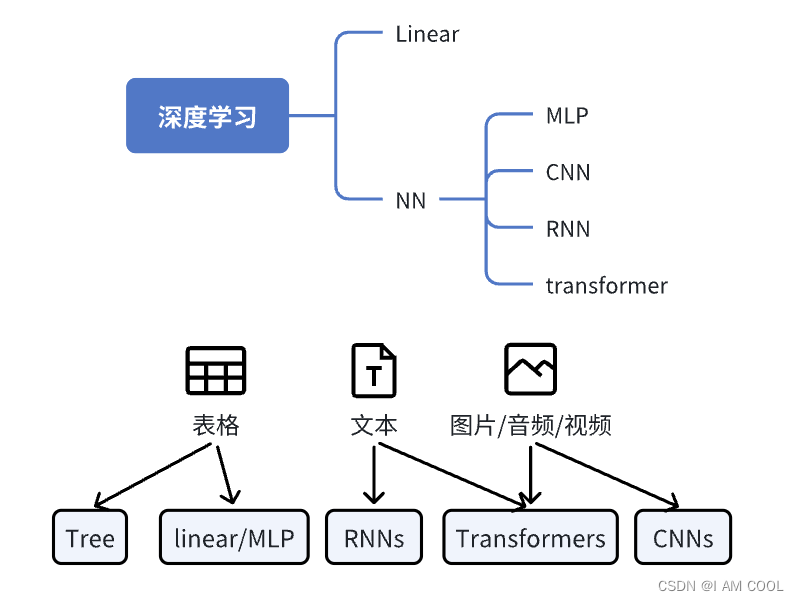
深度学习的基础模型包括:Linear、MLP、CNN、RNN、Transformer。其他的GRU、LSTM、BERT和GPT都是这些基础模型的变体和组合。这些模型实际上都是为了挖掘数据的特征,不同数据的表达都有相较而言适合的模型来解决(如图中的表格、文本和音频对应的模型)。本篇笔记将对这五个基础模型进行概览。(摘录于李沐老师的b站视频课程)
一、Linear Methods 线性模型
线性回归是机器学习最基础的模型,也是所有深度学习模型的基础。
1. 定义
给定 n 维输入
x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
\mathbf{x}=[x_1,x_2,...,x_n]^T
x=[x1,x2,...,xn]T
线性模型有一个 n 维权重和一个标量偏差:
w
=
[
w
1
,
w
2
,
.
.
.
,
w
n
]
T
,
b
\mathbf{w}=[w_1,w_2,...,w_n]^T,b
w=[w1,w2,...,wn]T,b
输出是n维输入的加权和外加偏差:
y
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
+
b
=
⟨
w
,
x
⟩
+
b
y=w_1 x_1+w_2 x_2+...+w_n x_n + b = \langle \mathbf{w},\mathbf{x} \rangle +b
y=w1x1+w2x2+...+wnxn+b=⟨w,x⟩+b
2. 训练
- 训练数据(样本):
X = [ x 1 , x 2 , . . . , x n ] T , y = [ y 1 , y 2 , . . . , y n ] T \mathbf{X}=[\mathbf{x_1},\mathbf{x_2},...,\mathbf{x_n}]^T, \mathbf{y}=[y_1,y_2,...,y_n]^T X=[x1,x2,...,xn]T,y=[y1,y2,...,yn]T - 训练目标(参数):
w = [ w 1 , w 2 , . . . , w n ] T , b \mathbf{w}=[w_1,w_2,...,w_n]^T ,b w=[w1,w2,...,wn]T,b - 训练损失(平方损失):
ℓ ( X , y , w , b ) = 1 2 n ∑ i = 1 n ( y i − ⟨ x i , w ⟩ − b ) 2 = 1 2 n ∥ y − X w − b ∥ 2 \ell(\mathbf{X},\mathbf{y},\mathbf{w},b)=\frac1{2n}\sum_{i=1}^n\left(y_i-\langle \mathbf{x}_i,\mathbf{w}\rangle -b\right)^2=\frac1{2n}\left\|\mathbf{y}-\mathbf{X}\mathbf{w}-b\right\|^2 ℓ(X,y,w,b)=2n1i=1∑n(yi−⟨xi,w⟩−b)2=2n1∥y−Xw−b∥2 - 最小化损失来学习参数,线性回归有显式解:
w ∗ , b ∗ = arg min w , b ℓ ( X , y , w , b ) \mathbf{w}^*,\mathbf{b}^*=\arg\min_{\mathbf{w},b}\ell(\mathbf{X},\mathbf{y},\mathbf{w},b) w∗,b∗=argw,bminℓ(X,y,w,b)
X ← [ X , 1 ] w ← [ w b ] ℓ ( X , y , w ) = 1 2 n ∥ y − X w ∥ 2 ∂ ∂ w ℓ ( X , y , w ) = 1 n ( y − X w ) T X \mathbf{X}\leftarrow[\mathbf{X},\mathbf{1}]\quad \mathbf{w}\leftarrow\\ \ell(\mathbf{X},\mathbf{y},\mathbf{w})=\frac{1}{2n} \left\| \mathbf{y}-\mathbf{X}\mathbf{w} \right\|^{2} \frac{\partial}{\partial\mathbf{w}}\ell(\mathbf{X},\mathbf{y},\mathbf{w})=\frac{1}{n}\left(\mathbf{y}-\mathbf{X}\mathbf{w}\right)^{T}\mathbf{X} X←[X,1]w←[wb]ℓ(X,y,w)=2n1∥y−Xw∥2∂w∂ℓ(X,y,w)=n1(y−Xw)TX[wb]
∂ ∂ w ℓ ( X , y , w ) = 0 ⇔ 1 n ( y − X w ) T X = 0 ⇔ w ∗ = ( X T X ) − 1 X y∂w∂ℓ(X,y,w)=0⇔n1(y−Xw)TX=0⇔w∗=(XTX)−1Xy∂∂wℓ(X,y,w)=0⇔1n(y−Xw)TX=0⇔w∗=(XTX)−1Xy
3. 模型
线性模型可以看作是单层神经网络。
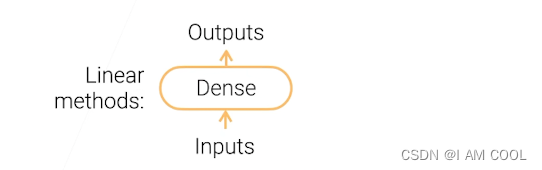
Dense:全连接层(Fully Connected Layer, FC)。全连接层指深度学习中常用的一种神经网络层,也称为连接层或感知机层。
二、MLP多层感知机
1. Linear ➡️ MLP(Multi-Layer Perceptron)的过程
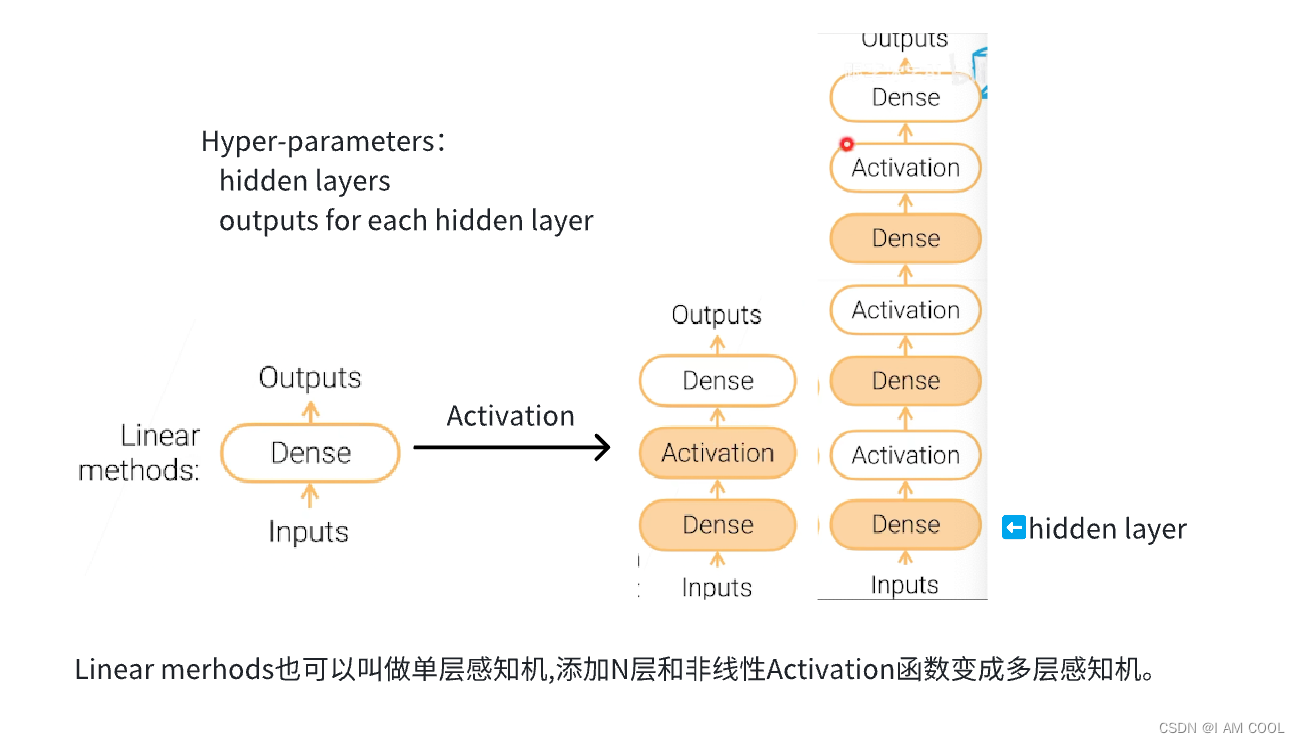
2. 各层解释
- 激活函数(Activation)
是一个按元素的非线性函数,两个常用激活函数:
s i g m o d ( x ) = 1 1 + e − x sigmod(x)=\cfrac{1}{1+e^{-x}} sigmod(x)=1+e−x1
R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x,0) ReLU(x)=max(x,0) - 全连接层(Dense)
n是输入特征的长度,m是输出向量的长度:
y = W x + b ∈ R m . W ∈ R m ∗ n , b ∈ R m , x ∈ R n y=Wx+b\in{R^m}. W\in{R^{m*n},b\in{R^m}},x\in{R^n} y=Wx+b∈Rm.W∈Rm∗n,b∈Rm,x∈Rn- 线性回归(Linear regression):Dense layer输出1个结果(m = 1)
- softmax 回归:Dense layer输出 m 个结果
- 超参数(Hyper-parameters)
- 隐藏层数 num_hiddens
- 每一层输出结果的大小 num_outputs
三、卷积神经网络
1. CNN(Convolution Neural Networks)
模型结构如下图所示:
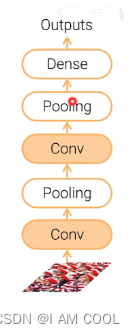
- 本地性:
卷积核(kernel):k*k窗口,每个输出只用这一个窗口,输出之间参数共享
卷积层(weight layer) - 汇聚/池化层(Pooling):
输入移一个像素,输出就变一个像素。求卷积结果的最大或平均值。
2. ResNet(Residual Net) 关于残差连接
(1)背景:CNN虽好,可以加很多层
(2)问题:随着网络越来越深,仅仅堆叠在一起就行了吗?
- 问题1: 网络层数增加,梯度会爆炸或者消失。使梯度收敛的方法:
- 初始化时,权重不大不小
- 在中间加入BN(batch normalization),校验每个层之间的输出和梯度的均值和方差,避免有些层特别大/小。
- 问题2: 网络层数增加,训练/测试精度会变差。
- 并不是由过拟合导致
- 新加的层不应该影响精度
- 理论上应该是在做identify mapping:前20层权重一样,后14层是identify mapping(类似于把权重变成n分之一,输入输出一一对应)
- 实际却做不到
(3)解决方法:要学习的是
H
(
x
)
H(x)
H(x),原始层学的是
x
x
x,新添层学习的是
F
(
x
)
=
h
(
x
)
−
x
F(x)=h(x)-x
F(x)=h(x)−x,最后shortcut connection:
F
(
x
)
+
x
F(x)+x
F(x)+x
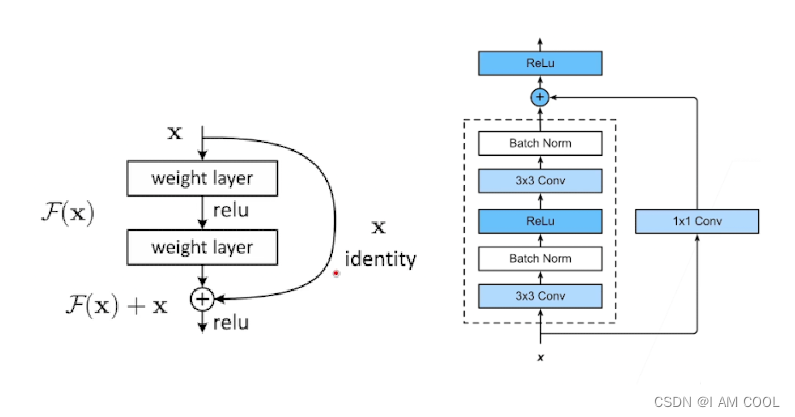
好处:不需要学习额外参数 不会增加模型复杂度 网络跟以前一样 没有任何变化
四、RNN循环神经网络
1. Dense layer ➡️ RNN(Recurrent networks)
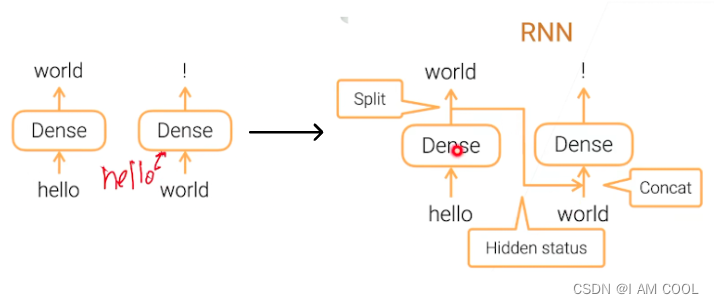
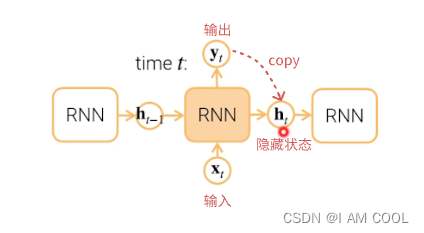
2. RNN基本结构
3. RNN变形
-
带有门的RNN(Gated RNN):更好的控制信息流 e.g. LSTM、GRU
- 忘记 x t x_t xt
- 忘记 h t − 1 h_{t-1} ht−1
-
双向RNN和深度RNN
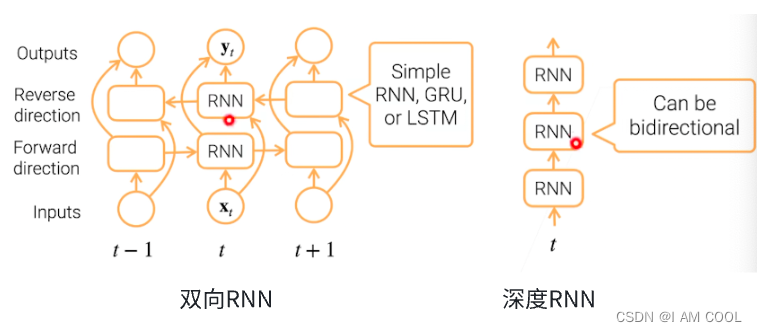
五、Transformer
1. self-attention (Attention is all you need精读)
(1)背景介绍
主流序列转录模型(sequence transduction models):seq2seq,依赖于循环RNN或者卷积神经网络CNN,框架是 encode-decode+Attetion。
- Transformer贡献
简单、摒弃RNN或CNN架构、仅通过Attention机制、训练的比其他架构快、效果好。 - RNN的问题
串行:RNN必须保证前一个词已经编码完成,计算性能差
遗忘:计算信息一步一步传递,早期信息到后面可能被丢掉
(2)模型架构
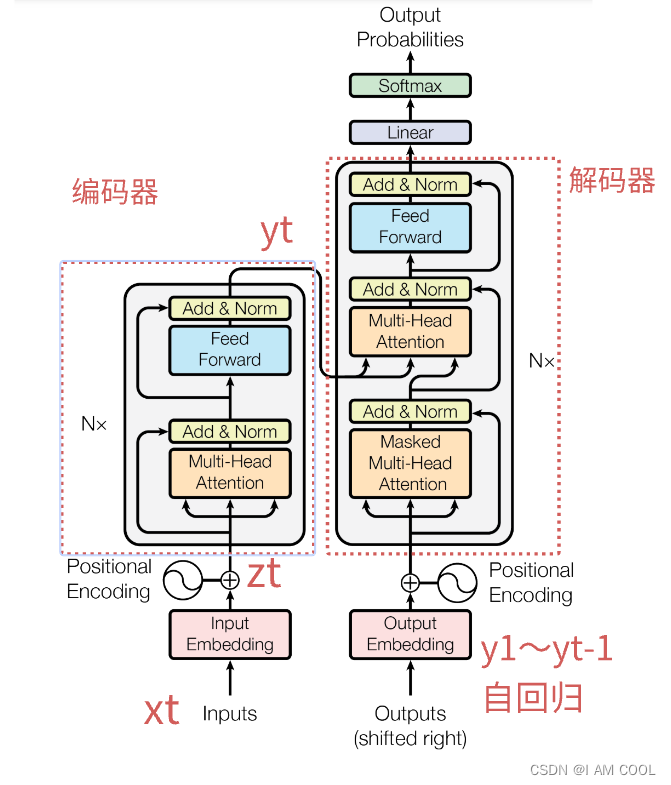
-
输入输出
- Inputs:中文句子Inputs经过一个Embedding层表示成一个向量,得到的向量值和 Positional Encoding相加。
- Outputs:decoder在做预测的时候是没有输入的。Shifted right 指的是 decoder 在之前时刻的一些输出,作为此时的输入。一个一个往右移。
- Positional encoding
- Why? Attention 不会有时序信息。顺序会变,但是值不会变,有问题!
在处理时序数据的时候,一句话里面的词完全打乱,那么语义肯定会发生变化,但是 attention 不会处理这个情况。 --> 加入时序信息 - How:RNN 把上一时刻的输出 作为下一个时刻的输入,来传递时序信息。Attention 在输入里面加入时序信息 --> positional encoding
- Why? Attention 不会有时序信息。顺序会变,但是值不会变,有问题!
-
编码器-解码器和解码器中的自回归(encode-decode + auto-regressive in decode )
- encoder:将 x 1 , x 2 , . . . , x n x_1, x_2, ... , x_n x1,x2,...,xn(原始输入) 映射成 $ z_1, z_2, …, z_n$(机器学习理解的向量)
- decoder:拿到 encoder 的输出,生成一个长为 m 的序列 y 1 , y 2 , . . . , y m y_1, y_2, ... , y_m y1,y2,...,ym
- 编码器和解码器区别:
- encoder 一次性很可能看全整个句子。
i.e., 翻译看到整句英语:Hello World - decoder 的输出词是一个一个生成的,过去时刻的输出会作为你当前时刻的输入,自回归 auto-regressive。给定 z 向量 ( $ z_1, z_2, …, z_n$) 生成
y
1
y_1
y1,在得到
y
1
y_1
y1 之后可以生成
y
2
y_2
y2。在生成
y
t
y_t
yt的时候,要把之前的
y
1
,
.
.
.
,
y
t
−
1
y_1,...,y_{t-1}
y1,...,yt−1都拿到。在翻译的时候,一个词一个词往外蹦。
i.e., 中英互译:Hello World 你好世界
- encoder 一次性很可能看全整个句子。
-
堆叠的block(stacked self-attention and point-wise、fully-connected layers)
- 堆叠:Nx,N个 block 叠在一起。N = 6
- block:
- Multi-Head attention
- Add & Norm: 残差连接 + LayerNorm
- Feed Forward: 前馈神经网络 MLP
(3)编码器-解码器详细解读
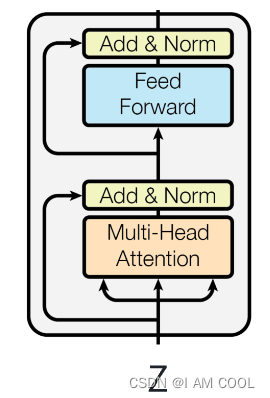
- 编码器结构
- 每个 layer 有 2 个 sub-layers。
第一个 sub-layer 是 multi-head self-attention,第二个 sub-layer 是 position-wise fully connected feed-forward network, 简称 MLP。 - 每个 sub-layer 的输出做残差连接和LayerNorm
- 每个 layer 有 2 个 sub-layers。
- 编码器公式:LayerNorm( x + Sublayer(x) )
- Sublayer(x) 指 self-attention 或者 MLP
- residual connections 需要输入输出维度一致,不一致需要做投影。简单起见,固定每一层的输出维度 d m o d e l d_{model} dmodel = 512
- N:多少层block堆叠
- 和 CNN、MLP 不一样。MLP 空间维度往下减;CNN 空间维度往下减,channel 维度往上拉。

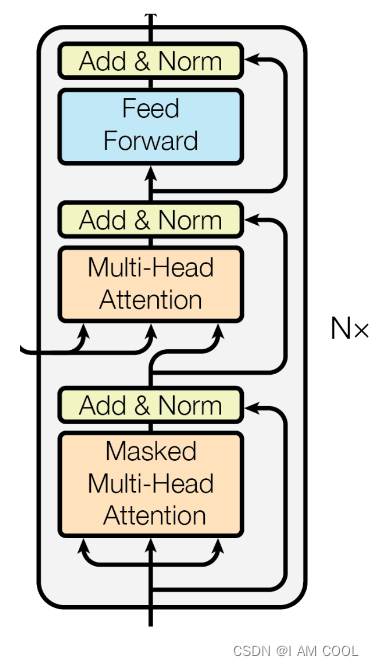
- 解码器结构
- 每个 layer 有 3 个 sub-layers。
第一个 sub-layer 是 multi-head self-attention,第二个 sub-layer 是 position-wise fully connected feed-forward network 简称 MLP,第三个 sub-layer 是 Masked multi-head self-attention 带掩码的注意力机制,保证 t 时刻看不到t时刻以后的数据。 - 每个 sub-layer 的输出做残差连接和LayerNorm
- 每个 layer 有 3 个 sub-layers。
(4)注意力机制详细解读
-
通用注意力函数
将query和key-value对映射成一个输出的函数。一个query的output是与它相似的value的加权和
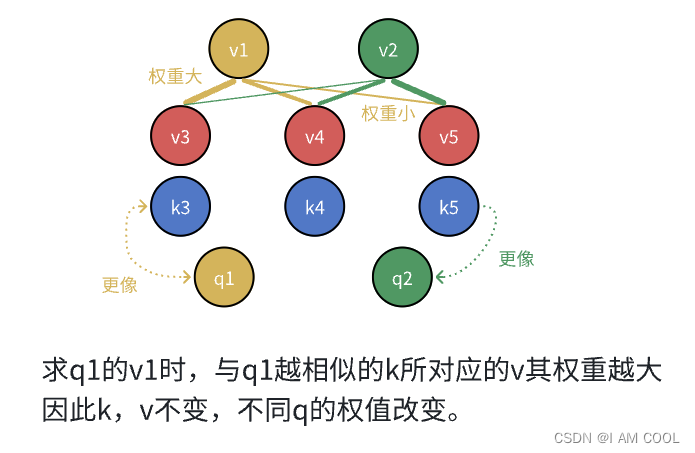
- 权重:对应每一个value的权重,是value对应的key和查询的query的相似度。
- 相似度:compatibility function算得,不同的相似函数导致不同的注意力机制
-
2 种常见的注意力机制:
- 加性的注意力机制(它可以处理 query 和 key 不等长的情况)
- 点积 dot-product 的注意力机制 (本文采用 Scaled Dot-Product Attention )
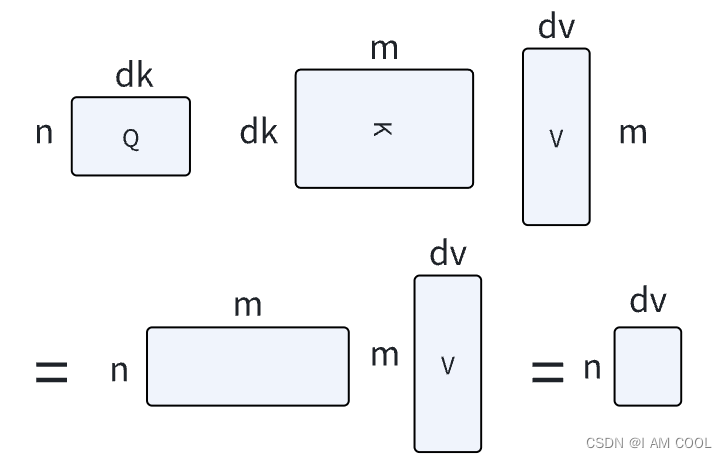
选用 dot-product 原因:两种注意力机制其实都差不多, 点乘实现简单、高效,两次矩阵乘法计算。 点积注意力函数的公式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\cfrac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
其中:
queries 和 keys 等长为 d k d_k dk,values长为 d v d_v dv,把 n 个 query 写成 matrix Q;把 m 个 key 写成 matrix K,对Q、K进行内积,每行算出来的是每一对query和key的相似度。 d k d_k dk比较大时,导致softmax出来的值偏向0或者1,梯度小,因此对 d k d_k dk 取根号 \sqrt{} ,再用softmax得到权重。
-
带掩码的注意力机制
权重 k k k会全算出来,怎么办?把 k t k_t kt后面的值换成非常大的负数(mask掉),进入到softmax会变成0。这时只能看到 0 − ( t − 1 ) 0 - (t-1) 0−(t−1)时刻的 q q q 和 k k k。

-
多头注意力机制
与其做一个单个的注意力函数,不如说把整个 query、key、value 整个投影 project 到 1个低维,投影 h 次。 然后再做 h 次的注意力函数,把每一个函数的输出拼接在一起,然后 again projected,会得到最终的输出。 -
TR如何使用注意力机制:使用上述的 3 种不一样的注意力层
- encoder 的自注意力层
假设句子长度是 n,encoder 的输入是一个 n 个长为 d 的向量。
encoder 的注意力层,有三个输入,它分别表示的是key、value 和 query。
一根线过来,它复制成了三下:同样一个东西,既 key 也作为 value 也作为 query,所以叫做自注意力机制。key、value 和 query 其实就是一个东西,就是自己本身。 - decoder 的 masked multi-head attention
在解码器的时候,后面的东西要设置成0 - decoder 的 multi-head attention
不再是 self-attention。key - value 来自 encoder 的输出。 query 是来自 decoder 里 masked multi-head attention 的输出。
- encoder 的自注意力层
(5)前馈神经网络 Position-wise Feed-Forward Networks (MLP)
- Feed-Forward Networks :作用在最后一个维度的 MLP ,point-wise:输入的序列有很多词,每个词是一个点,是一个position,同一个MLP对每一个词作用一次。
- 公式
两个线性层加一个ReLU激活层: F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_1+b_1)W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
其中:
每一个query对应的输出长度为512。 x x x是512的向量; W 1 W_1 W1把维度扩大四倍即2048;最后有一个残差连接,需要投影回去,用 W 2 W_2 W2投影回去。 - 本质
单隐层MLP,中间隐藏层把输入扩大四倍,最后输出变成输入的大小。
2. cross-attention
(1)定义
交叉注意力(Cross-Attention)则是在两个不同序列上计算注意力,用于处理两个序列之间的语义关系。例如,在翻译任务中,需要将源语言句子和目标语言句子进行对齐,就需要使用交叉注意力来计算两个句子之间的注意力权重。
(2)公式
交叉注意力机制是一种特殊形式的多头注意力,它将输入张量拆分成两个部分:
X
1
,
X
2
X_1,X_2
X1,X2,一个部分作为 query 集合,另一个部分作为 key 集合。交叉注意力计算为:
C
r
o
s
s
A
t
t
e
n
t
i
o
n
(
X
1
,
X
2
)
=
S
o
f
t
m
a
x
(
Q
K
T
d
2
)
V
CrossAttention(X_1,X_2) = Softmax(\cfrac{QK^T}{\sqrt{d_2}})V
CrossAttention(X1,X2)=Softmax(d2
QKT)V
公式解释:
Q
=
X
1
W
Q
,
K
=
V
=
X
2
W
K
Q = X_1W^Q, K = V =X_2W^K
Q=X1WQ,K=V=X2WK 其中
X
1
∈
R
n
∗
d
1
,
W
Q
∈
R
d
1
∗
d
k
X_1\in{R^{n*d_1}},W^Q\in{R^{d_1*d_k}}
X1∈Rn∗d1,WQ∈Rd1∗dk
X
2
∈
R
n
∗
d
2
,
W
K
∈
R
d
2
∗
d
k
X_2\in{R^{n*d_2}},W^K\in{R^{d_2*d_k}}
X2∈Rn∗d2,WK∈Rd2∗dk
d
k
d_k
dk是 key / query 集合的维度。输出是一个大小为
n
∗
d
2
n*d_2
n∗d2的张量,对于每个行向量都给出了它对于所有行向量的注意力权重。

