
- 1国外计算机科学的 lab,真滴牛逼!_计算机lab是什么意思
- 2用Python求数学题中阴影部分面积_python编写程序,求出图5_编写程序求出阴影面积
- 3JavaWeb期末大作业——图书管理系统
- 4Unity 点乘(Dot)、叉乘(Cross)判断移动方向、朝向等向量问题_unity3d c# 2个向量方向
- 5alibaba实习生代码大赛_阿里巴巴实习生代码赛
- 6今天来聊一聊GPU在人工智能应用上的优势_计算机基础 ai人工智能 gpu 知乎
- 7通信原理课设(gec6818) 001:环境配置+文件操作_gec6818能否支持c++
- 8Spring cloud入门-OAuth 2.0(四)授权之基于JWT完成单点登录_oauth2.0 jwt单点登录
- 9Nginx 配置特定IP访问_nginx只允许指定ip访问
- 10Python+Django毕业设计校园易购二手交易平台(程序+LW+部署)_用python写一个交易平台
python大作业有哪些题目,python程序设计大作业
赞
踩
本篇文章给大家谈谈python大作业设计一个纸牌类游戏,以及python大作业有哪些题目,希望对各位有所帮助,不要忘了收藏本站喔。

期末大作业要求如下↓

参考教程:https://www.cnblogs.com/gezhuangzhuang/p/10596545.html
目标检测最新进展总结与展望 - 知乎
实验环境及工具:Python 3.7+Tensorflow 1.14(cpu版)+keras 2.31+Pycharm+精灵标注助手软件;
实验原理
目标检测:目标检测即找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,同时确定物体的类别和位置。
传统目标检测的方法一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然 后对这些区域提取特征,最后使用训练的分类器进行分类学python编程的书。
深度学习目标检测算法有两类:(1)One-Stage目标检测算法,这类检测算法不需要Region Proposal阶段,可以通过一个Stage直接产生物体的类别概率和位置坐标值,比较典型的算法有YOLO、SSD和CornerNet;(2)Two-Stage目标检测算法,这类检测算法将检测问题划分为两个阶段,第一个阶段首先产生候选区域(Region Proposals),包含目标大概的位置信息,然后第二个阶段对候选区域进行分类和位置精修,这类算法的典型代表有R-CNN,Fast R-CNN,Faster R-CNN等。
这里使用的是One-Stage中的YOLO v3算法。
YOLO系列算法:如下图所示,其中左图取自YOLOv1[8],右图取自YOLOv2[9],需要说明的是YOLOv1相比于YOLOv2在坐标回归的时候没有anchor的概念。YOLO系列算法在构建回归目标时一个主要的区别就是如果将图像划分成SxS的格子,每个格子只负责目标中心点落入该格子的物体的检测;如果没有任何目标的中心点落入该格子,则为负样本。
每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。
Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
confidence反映当前bounding box是否包含物体以及物体位置的准确性,计算方式如下:
confidence = P(object)* IOU, 其中,若bounding box包含物体,则P(object) = 1;否则P(object) = 0. IOU(intersection over union)为预测bounding
box与物体真实区域的交集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
YOLO使用均方和误差作为loss函数来优化模型参数,即网络输出的SS(B5 + C)维向量与真实图像的对应SS*(B*5 + C)维向量的均方和误差。
实验过程
- 数据集标注:选取旺仔单人照、浪味仙单人照和旺仔浪味仙双人照共100张,用精灵标注软件标注,导出
pascal-voc格式的xml文件。

- 下载所需的文件
下载YOLO v3:https://github.com/qqwweee/keras-yolo3
下载YOLO v3权重文件:https://pjreddie.com/media/files/yolov3.weightsyolov3.weight放入keras-yolo3-master内; - 数据准备及放置
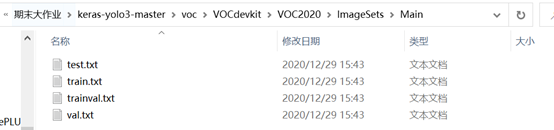
在keras-yolo3-master下新建一个voc文件夹,文件夹结构如图所示
将图片原文件放入JPEGImages中,在rename.py文件中输入代码对图片进行重命名。这里将图片用三位数字表示。

用标注软件标注后,将标注好的xml文件放在Annotations目录下。

在createText.py输入代码运行生成四个txt文件。

总共100张图片,其中训练集40张,测试集20张;(改变 val_split之后训练值测试集数量会发生变化)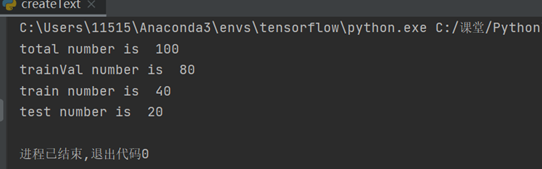
- 修改配置文件
将keras-yolo3-master下的voc_annotation.py复制到voc下;
并对voc_annotation.py进行修改。


在model_data下新建txt文件wangwang_classes.txt,一行一个类别。这里一定不能用中文,否则跑起来就会报字符集的错。

修改yolov3.cfg文件
ctrl+F 搜索yolo,搜索结果大概有三处。每一处都改三个地方。filter :3*(5+len(classes)),此处我的classes有两个所以是21classes:len(classes) 我的类别是2random:原来是1,显存小改为0
要改三处。
输入python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5生成h5文件
修改train.py代码。除了下面框中的还需要改一下epochs,否则要跑很长时间。

在终端中输入python train.py运行
5. train.py代码介绍
获得anchor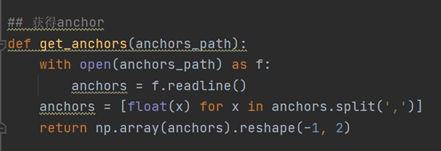
获取分类:
建立模型:
建立迭代器:
训练模型:
主函数:
6. 修改参数
- YOLO – 原始 优化器为
adam,epochs为20: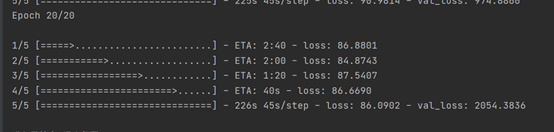
- YOLO - 修改优化器为
sgd:
效果并不好,在第一个epochs就变成nan了。
- YOLO – 修改优化器为
adadelta: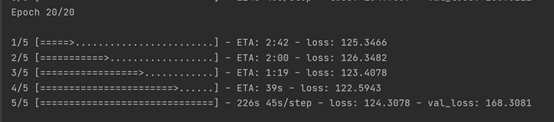
- 增加
epochs到30: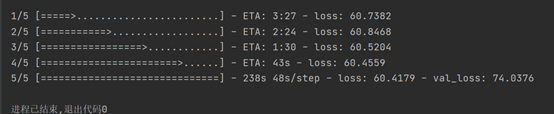
- 改变
val_spilt=0.4: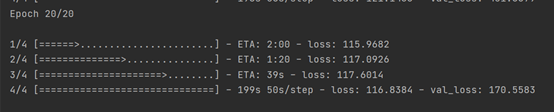
- 改变
val_spilt=0.2: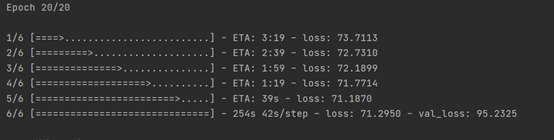
跑完一次后要去model_data/logs下改h5的名字,否则会覆盖。也在文件名中加入运行完成的时间进行区分。
- 图片识别测试
修改yolo.py文件: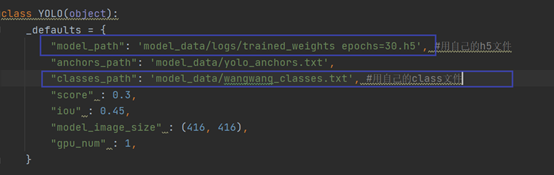
在终端输入python yolo_video.py –image,然后输入需要测试的地址,然而我的效果都好差啊,不放图了。
实验心得
整个过程挺烦心的。刚开始去github上找教程,然而教程都太高级了也不适用,后来去找博客,s同学给我推荐了一篇博客,这篇博客用的是tensorflow 1.x的cpu版本,而我安装的是2.3的gpu版本,所以跑不起来,第一次尝试在pycharm里更改Tensorflow的版本,但是因为连接的外网,半年过去都下不出来。只能去清华镜像里找Tensorflow的版本,所以用的Tensorflow 1.15的版本,keras同步下载的2.3.1版本(然而2.3.1在训练的时候会报错所以又降到了2.1.5)。第一次标注只有旺仔的照片,觉得有点少就又添上了浪味仙的照片,到了一百张。但是在写wangwang_classes.txt发现标注的时候旺仔和浪味仙写的全都是中文,果然报错了。侥幸地想把pycharm的全局字符编码改成GBK,然而并没有用。只能一百张从头开始把标注改成拼音,本人现在已经很精通ctrl+s和右方向键的组合了。导出的时候也遇到了问题,刚开始我导出的用的xml格式,然后报错说xml文件里没有different标签,百思不得其解,后来去问了s同学才想起来应该用pascal-voc的格式,最后就是跑代码特别费时这件事。


