
- 1初学FPGA(assign存疑篇)_fpga assign
- 2人工智能法律审查系统:如何提高法律法规的准确性
- 3在docker上部署postgresSQL主从_postgresql docker
- 4山东大学软件学院项目实训-创新实训-山大软院网络攻防靶场实验平台(十二)-任意文件上传漏洞(2)_spring boot 文件上传漏洞
- 5文本摘要与抽取:信息的精简与提取
- 6Install or enable PHP‘s pcntl extension._install or enable php's pcntl extension
- 7反转单链表(递归,JAVA)_java递归反转单向链表
- 8uniapp 开发多端项目如何配置环境变量以及区分环境打包_uniapp 环境变量
- 9深度学习基础--DL原理研究2_深度学习 折纸
- 10利用区块链技术实现返利App的透明化追溯
人工智能10大算法-逻辑回归(logistics regression)_人工智能算法逻辑回归
赞
踩
逻辑回归是一个二分类问题
二分类问题
二分类问题是指预测的y值只有2个取值(0或1),二分类问题可以扩展到多分类问题.例如:我们要做一个垃圾邮件过滤系统, x i x^i xi是邮件的特征,预测的y值就是邮件的类别,是垃圾邮件还是正常邮件.对于类别我们通常称为正类(positive class)和负类(negative class),垃圾邮件的例子中,正类就是正常邮件,负类就是垃圾邮件
逻辑回归
Logistic函数
如果我们忽略二分类问题中y的取值是一个离散的取值(0或1),我们继续使用线性回归来预测y的取值.这样会导致y的取值并不为0或1.逻辑回归使用一个函数来归一化y值,使y的取值在(0,1)之间,这个函数称为Logistic函数(Logistic function),也称为Sigmoid函数,公式如下
g(z) =
1
1
+
e
−
z
\frac{1}{1 + ^{e^{-z}}}
1+e−z1
Logistic函数当z趋近于无穷大时,g(z)趋近于1;当z趋近于无穷小时,g(z)趋近于0
Logistic函数图如下:
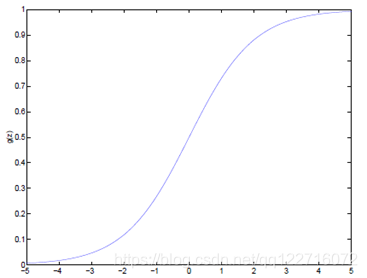
Logistic函数求导时有一个特征
g
/
g^/
g/(z) =
d
d
z
\frac{d}{dz}
dzd
1
1
+
e
−
z
\frac{1}{1+e^{-z}}
1+e−z1
=
1
(
1
+
e
−
z
)
2
\frac{1}{(1+e^{-z})^2}
(1+e−z)21(
e
−
z
e^{-z}
e−z)
=
1
1
+
e
−
z
\frac{1}{1+e^{-z}}
1+e−z1(1-
1
(
1
+
e
−
z
)
\frac{1}{(1+e^{-z})}
(1+e−z)1)
=g(z)*(1-g(z))
逻辑回归表达式
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)将最为假设函数来预测.g(z)可以将连续值映射到0和1之间.线性回归模型的表达式代入g(z),就得到逻辑回归的表达式:
h
θ
(
x
)
=
g
(
θ
T
x
)
=
1
1
+
e
−
θ
h_\theta(x) = g(\theta^Tx) = \frac{1}{1 + e^{-\theta}}
hθ(x)=g(θTx)=1+e−θ1
这里为什么用
h
θ
(
x
)
h_\theta(x)
hθ(x):hyperthesis:假设
令
x
0
=
1
x_0 = 1
x0=1,
θ
T
x
=
θ
0
+
∑
j
=
0
n
θ
j
x
j
\theta^Tx = \theta_0 + \sum_{j=0}^{n}\theta_jx_j
θTx=θ0+∑j=0nθjxj
逻辑回归的软分类
现在我们将y的取值
h
θ
(
x
)
h_\theta(x)
hθ(x)通过Logistic函数归一化到(0,1)间,y的取值特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P
(
y
=
1
∣
x
;
θ
)
=
h
θ
(
x
)
P(y=1|x;\theta) = h_\theta(x)
P(y=1∣x;θ)=hθ(x)
P
(
y
=
0
∣
x
;
θ
)
=
1
−
h
θ
(
x
)
P(y=0|x;\theta) = 1-h_\theta(x)
P(y=0∣x;θ)=1−hθ(x)
对上面的表达式合并:
P
(
y
∣
x
;
θ
)
=
(
h
θ
(
x
)
)
y
(
1
−
h
θ
(
x
)
)
1
−
y
P(y|x;\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y}
P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
解释:当y=0时,
P
(
y
∣
x
;
θ
)
=
1
−
h
θ
(
x
)
P(y|x;\theta)=1-h_\theta(x)
P(y∣x;θ)=1−hθ(x).当y=1时,
P
(
y
∣
x
;
θ
)
=
h
θ
(
x
)
P(y|x;\theta)=h_\theta(x)
P(y∣x;θ)=hθ(x)
梯度上升
得到逻辑回归的表达式,下一步和线性回归类似.构建似然函数,然后最大似然估计,最终推导出
θ
\theta
θ的迭代更新表达式,这个请参考文章《线性回归、梯度下降》,只不过这里用的不是梯度下降,而是梯度上升,因为这里是最大化似然函数不是最小化似然函数.
似然函数表达式:
L
(
θ
)
=
p
(
y
⃗
∣
X
;
θ
)
L(_\theta)=p(\vec{y}|X;\theta)
L(θ)=p(y
∣X;θ)
=
∏
i
=
1
m
p
(
y
(
i
)
∣
x
i
;
θ
)
\prod_{i=1}^{m}p(y^{(i)}|x^{i};\theta)
∏i=1mp(y(i)∣xi;θ)
=
∏
i
=
1
m
(
h
θ
(
x
i
)
)
y
(
i
)
(
1
−
h
θ
(
x
i
)
)
1
−
y
i
\prod_{i=1}^{m}(h_\theta(x^{i}))^{y^{(i)}}(1-h_\theta(x^{i}))^{1-y^{i}}
∏i=1m(hθ(xi))y(i)(1−hθ(xi))1−yi
对似然函数取
log
\log
log:即逻辑回归的损失函数
Ψ
(
θ
)
=
log
L
(
θ
)
\Psi(\theta)=\log{L(\theta)}
Ψ(θ)=logL(θ)
=
∑
i
=
1
m
y
(
i
)
log
h
(
x
(
i
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
(
x
(
i
)
)
)
\sum_{i=1}^{m}y^{(i)}\log{h(x^{(i)})+(1-y^{(i)})\log{(1-h(x^{(i)})}})
∑i=1my(i)logh(x(i))+(1−y(i))log(1−h(x(i)))
转换后的似然函数对
θ
\theta
θ求偏导,
α
α
θ
j
Ψ
(
θ
)
\frac{\alpha}{\alpha\theta_j}\Psi(\theta)
αθjαΨ(θ)
=
(
y
1
g
(
θ
T
x
)
−
(
1
−
y
)
1
1
−
g
(
θ
T
x
)
)
α
α
θ
j
g
(
θ
T
x
)
(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)})\frac{\alpha}{\alpha\theta_j}g(\theta^Tx)
(yg(θTx)1−(1−y)1−g(θTx)1)αθjαg(θTx)
=
(
y
1
g
(
θ
T
x
)
−
(
1
−
y
)
1
1
−
g
(
θ
T
x
)
)
g
(
θ
T
x
)
(
1
−
g
(
θ
T
x
)
α
α
θ
j
)
θ
T
x
(y\frac{1}{g(\theta^Tx)}-(1-y)\frac{1}{1-g(\theta^Tx)})g(\theta^Tx)(1-g(\theta^Tx)\frac{\alpha}{\alpha\theta_j})\theta^Tx
(yg(θTx)1−(1−y)1−g(θTx)1)g(θTx)(1−g(θTx)αθjα)θTx
=
(
y
(
1
−
g
(
θ
T
x
)
)
−
(
1
−
y
)
g
(
θ
T
x
)
)
x
j
(y(1-g(\theta^Tx))-(1-y)g(\theta^Tx))x_j
(y(1−g(θTx))−(1−y)g(θTx))xj
=
(
y
−
h
θ
(
x
)
)
x
j
(y-h_\theta(x))x_j
(y−hθ(x))xj
这个求导过程第一步是对
θ
\theta
θ偏导的转化,一句偏导公式:
y
=
ln
x
y=\ln{x}
y=lnx;
y
/
=
1
x
y^/=\frac{1}{x}
y/=x1
- 第二步是根据个g(z)求导的特性: g / ( z ) = g ( z ) ( 1 − g ( z ) ) g^/(z)=g(z)(1-g(z)) g/(z)=g(z)(1−g(z))
- 第三步就是普通的变换
这样我们就得到了梯度上升每次迭代的更新时间,那么 θ \theta θ的迭代表达式为:
θ j : = θ j + α ( y ( i ) − h θ ( x ( i ) ) ) x j ( i ) \theta_j:=\theta_j+\alpha(y{(i)}-h_\theta(x^{(i)}))x_j^{(i)} θj:=θj+α(y(i)−hθ(x(i)))xj(i)
这个表达式域LMS算法的表达式相比,看上去完全相同,但是梯度上升与LMS是两个不同的算法,因为 h θ ( x i ) h_\theta(x^i) hθ(xi)表示的是关于 θ T x \theta^Tx θTx的一个非线性函数.两个不同的算法,同一个表达式表达,这并不仅仅是巧合,两者存在深层次的联系.这个问题,我们将在广义线性模型GLM中解答

