
- 1机器学习与深度学习:区别与联系(含工作站硬件推荐)_7个pcie插槽 机箱 双路gpu
- 2部署DiffSynth-Studio实现视频风格转换
- 3Leetcode题库(数据库合集)_ 难度:困难_leetcode题库数据集
- 4milvus实战 | docker部署单机版_milvus docker
- 5Graph Embedding_有向图 节点相似度计算
- 6最新最全大数据毕业设计选题推荐_数据科学与大数据毕业论文选题方向
- 7Flutter 应用内调试工具(字节&贝壳)
- 8ctfshow元旦水友赛 easy_web_ctfshow 以假换真
- 9SublimeText3配置UnityShader编辑环境_unity shader 格式化
- 10实现页面分页
m数据结构 day18 查找(一)无序表查找(线性查找),有序表查找(二分查找,插值查找, 斐波那契查找)_无序顺序表的查找
赞
踩
查找,也叫做 搜索,是一个非常常用,操作极为频繁的操作。
比如当我们写完一篇博客,载有这篇博客的网页就会被上传到CSDN网站的主机上,然后各大搜索引擎公司,比如Google,百度等,就会抓取到这个新网页(爬虫),并把它存入他们公司自己的网页数据库,然后搜索引擎公司会对这个网页进行分析,比如全文检索提取有效信息并存入索引数据库,提取网页链接存入链接数据库。并且这些搜索引擎公司还会定期再去CSDN网站看看我的这个网页的地址是否变化,对它的链接数据库做定期的维护。

当你输入关键词,点击搜索之后,搜索引擎的查找算法就会带着你的关键词奔向索引数据库,检索到所有包含关键词的网页,并按照这些网页的浏览次数和关联性按照一定算法对网页们进行排序,然后按照排序后的格式呈现在网页上。
概念
-
关键字:key, 是数据元素中某个数据项的值,又称为键值。用于标识一个数据元素或者一个记录的某个字段(标识一个记录的某个字段的关键字也叫做关键码)。
-
主关键字:primary key, 可以唯一地标识一个记录的关键字。所以不同记录的主关键字不同。
-
主关键码:主关键字所在的数据项(字段)。
-
次关键字:secondary key,可以识别多个数据元素或记录的关键字。即不能唯一标识一条记录的关键字呗。
-
次关键码:次关键字对应的数据项。

-
查找表: search table, 所有被查的数据所在的集合。由同一类数据元素或数据记录构成的集合。
查找表按照操作方式可以分为两大类:静态查找表,动态查找表。
- 静态查找表:static search table,只做查找操作的查找表。比如:查询某各数据元素是否在查找表中;检索某个数据元素及其属性。
- 动态查找表: dynamic search table,即不只做查找,查找的目的不只是为了查找,比如添加和删除,你要首先查找一下添加项或者删除项是否在查找表中,如果不在则可以添加,不能删除。
- 查找:searching,根据给定值,在查找表中确定一个关键字等于给定值的数据元素或记录。
- 查找结构:为了提高查找的效率,专门为查找操作设计的数据结构,是面向查找操作的数据结构。本来,查找面向的数据结构是集合,即所有被查找的数据相互之间没有关系,只是同在一个集合里,但是为了提高查找的效率,所以要为数据元素之间加点关系,比如动态查找表可以把数据元素们存储为集合以外的数据结构中,比如存在二叉查找树中,这样能够提高查找和添加删除的效率。
静态查找表还是要使用线性表结构来存储数据,因为这样可以用顺序查找算法;如果对静态查找表的主关键字排序,则可以用二分查找。
动态查找表一般用二叉查找树存储,还可以用散列表结构。
无序表查找
根据查找表中的数据记录之间的关系是否有特定顺序,查找可分为无序表查找和有序表查找。
无序表查找,即查找表的数据记录们没有任何次序,只是同处一个集合的关系。
线性查找(顺序查找):最基本的查找技术, O ( n ) O(n) O(n),适合用于小型数据

代码
这里是以数组存储结构和int类型关键字来示例的,实际应用中,数据还可以用栈,队列,链表等线性表数据结构存储。关键字也可以改变。
代码很简单,就是从头开始找
int Sequential_search(int *a, int n, int key)
{
int i;
for (i=0;i<n;++i)
if (a[i]==key)
return i;
return -1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
时间复杂度分析:
- 最好情况:第一个就找到了,O(1)
- 最坏情况:最后一个才找到,则需要比较n次;或者最后一次都没找到,则需要n+1次比较。O(n)
- 平均情况:由于关键字在任何一个位置找到的概率是一样的,所以平均查找次数是(n+1)/2,所以最后的时间复杂度还是O(n)
代码层面的优化(值得学习发扬):使用哨兵以减少不必要的比对, O ( n ) O(n) O(n)
这是一个很细微的代码层面的优化,真的很细微,很适合用在日常工作中的一线代码调优中。
上面的代码用for循环,每一次都要判断i是否还小于n,在n很大的时候,这个判断也会耗费很多时间。所以,优化的思路就是省略这个判断,每次不要再把i和n作比较。怎么做呢?通过加入一个哨兵。直接看代码:
int Sequential_Search2(int * a, int n, int key)
{
int i;
a[0] = key;//a[0]是哨兵,不用于存储数据,这是和上面代码的一大区别
i = n;//倒着查找
while (a[i]!=key)
--i;
return i;//返回0则说明查找失败
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
或
int Sequential_Search2(int * a, int n, int key)
{
int i;
a[n] = key;//a[0]是哨兵,不用于存储数据,这是和上面代码的一大区别
i = 0;//顺着查找
while (a[i]!=key)
++i;
return i;//返回n则说明查找失败
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这样一改,就只需要比对数据元素和关键字了,不需要比较循环变量i和n的大小。对于很大的n,还是一笔可观的优化的。这种优化细节一定要学着点。
虽然时间复杂度还是 O ( n ) O(n) O(n),但是一定要明白, O ( n ) O(n) O(n)和 O ( n ) O(n) O(n)之间绝对也是有区别的,虽然咱们用大O表示法省略了系数和低次项,但是如果真是相同复杂度的两个算法来比较的话,还是要看看那些被省略的项的。比如,成绩不用分数公布,而是公布为优秀,良好,及格,不及格等,那99和91都是优秀,有区别吗?有。优秀和优秀之间也不全是一样的。一个道理。
优缺点
- 优点:简单,不需要对静态查找表的记录进行排序等操作
- 确定:n很大时,查找效率很低,所以不适用于大型数据集,只适用于小数据。
其实,每一条数据被查找的概率是不一样的,就像之前学习霍夫曼编码,每一个字符在文本信息中的出现概率是不一样的,所以可以给大概率出现的字符更短的编码,而给小概率出现的字符较长的编码,这样可以使得平均码长更短,进而压缩数据。仅仅是考虑到了字符的出现概率,就做出了如此巨大的优化,现在也是一样,我们应该考虑到一个客观事实,那就是查找表中的多条数据,并不是以均等的概率被用户搜索查找的,一定是某些数据记录被频繁查找,而另一些则不怎么被人问津。
基于这种概率特性带来的启示,我们应该把经常被查找到的数据记录放在查找表的前面,而不经常被查找的记录放在后面,这样就可以大幅提高效率。这就是下面要说的有序表查找。
有序表查找
无序查找一定是差于有序查找的。不然图书馆为啥要给所有书编号呢?图书馆又不傻。
对线性表先做个排序,然后在查找,效率会高很多。
二分查找, O ( log n ) O(\log n) O(logn),前提:顺序存储有序查找表
binary search,也叫折半查找
前提:线性表中的记录必须是关键字有序(一般从小到大的顺序)的,且线性表必须采用顺序存储,即不能用链式存储。
换句话说,二分查找必须用数组存储一个有序查找表,而不可以用单链表。
思想:取有序表的中间记录作为比较对象,如果给定值等于中间记录的关键字,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续使用二分查找进行查找;若给定值大于中间记录的关键字,则在中间记录的右半区查找。重复这个过程,直到查找成功或者查找失败为止。
每次都找中间,记住找中间就对了。
代码
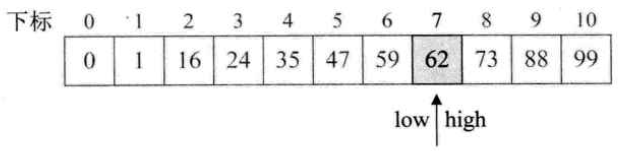
举个例子,从一个有11个元素的int数组中找是否有数字62,注意,数组a是排序过的哦,这是二分查找的前提,关键字必须有序,这里关键字就是数据本身
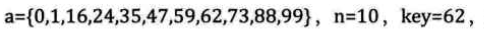
int Binary_Search(int *a, int n, int key) { int low, mid, high; low = 1;//注意不是0哦! high = n; while (low<=high) { mid = (low + high) / 2;//整数除法 if (key < a[mid]) high = mid-1; else if (key > a[mid]) low = mid+1; else return mid;//查找成功 } return -1;//查找失败 }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 过程:
注意low并不是指向0!!!
如果不想多浪费第一个空间,想从0开始,则代码为:
//二分查找 int Binary_Search(int *a, int n, int s) { int low=0, mid, high=n-1; while (low<high) { mid = (low+high)/2 + 1;//改变在这里,很简单很好理解 if (s == a[mid]) return mid; else if (s > a[mid]) low = mid + 1; else if (s < a[mid]) high = mid - 1; } if (low==high && a[low]==s) return low; return -1;//没找到 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
注意我还把return放到前面了,这样就不用多执行无效判断啦
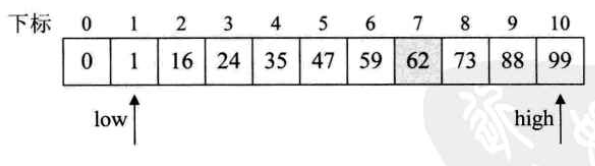
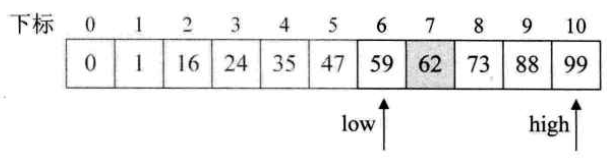
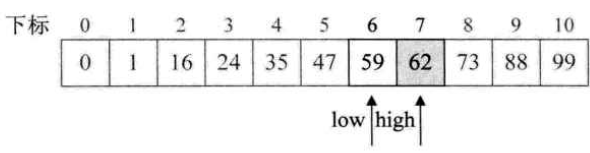
- 时间复杂度分析:
二分查找每一次判断都把整个数组一分为二,且一次直接排除一半的范围,直观思考就比线性查找那老老实实的操作要快。下面仔细分析一下:
把二分查找的过程画成一颗二叉树:
首先找到中间记录,即第6个数字,47,于是47把静态有序查找表数组分成了两棵子树;
由于目标记录62更大,所以瞬间排除47左边的五个元素。右半区的五个数的中间记录是73,所以进入左半区····可以看到,第四次比较后查找成功。

认真思考一下你会发现,其实这里需要的查找次数就是这棵二叉树的深度,这里这棵二叉树是一棵完全二叉树,有n个结点的完全二叉树的深度是多少呢?这是之前学完全二叉树时候学到的性质,答案是
⌊
log
2
n
⌋
+
1
\lfloor \log_2 n \rfloor+1
⌊log2n⌋+1。所以这次的查找次数是
⌊
log
2
n
⌋
+
1
\lfloor \log_2 n \rfloor+1
⌊log2n⌋+1。
但是,二分查找得到的二叉树可不一定就是完全二叉树,但是二分查找得到的二叉树的深度一定是小于等于完全二叉树的是深度的,所以二叉树中查找次数一定是小于等于 ⌊ log 2 n ⌋ + 1 \lfloor \log_2 n \rfloor+1 ⌊log2n⌋+1。
所以二分查找的时间复杂度是 O ( log n ) O(\log n) O(logn),这比线性查找好多了。
看看下图你就明白 O ( n ) O(n) O(n)和 O ( log n ) O(\log n) O(logn)的区别有多大了,n越大,两者的差异越大。所以二分查找比现行查找快很多,只是需要保证查找表是有序的。

优缺点
- 优点:相较于线性查找要快很多。对于静态查找表来说简直是完美,只要对静态查找表排序1次,后面的查找都很快。
- 缺点:对于需要频繁插入和删除的数据集,即动态查找表,维护数据集的有序,需要带来不少工作量,所以并不适合使用二分查找。
插值查找: O ( log n ) O(\log n) O(logn),顺着二分查找的思路进一步优化,思路很贴近生活
interpolation search
插值查找的思路是很贴近于生活的。小时候经常需要查字典,查字典多了的人肯定不会还老老实实用拼音或者部首一步一步规规矩矩地查,而是拿起字典就直接翻,如果查“安”字,我们就翻很靠前的位置;如果查“山”,则往后很多;查“张”则更加靠后。这里面涉及到字符的比较。英文字典也一样,查apple肯定在前面翻,查zoo就在后面翻。这其实就是插值查找算法利用的思路和原理。从这个原理和例子就可以看到,插值查找算法适用于大的关键字分布均匀的查找表,细节见后文。
回顾一下已经学过的查找算法:
顺序查找要么从头元素开始找,要么从尾元素开始找;
而二分查找另辟蹊径,每次都从排序后的中间元素入手;
插值查找仔细深思,决定比二分查找更进一步,也先把查找表排好序,但是每次迭代都在现用查找表的不同位置查找,而不是每次都和中间元素比大小。具体细节用语言描述的话,就像上面查字典的例子一样。直观上思考确实是有利于提高查找效率的,那么我们怎么把查找时候的具体位置用数学精确描述呢?
这就要用到插值公式。
插值公式
k e y − a [ l o w ] a [ h i g h ] − a [ l o w ] \frac{key-a[low]}{a[high]-a[low]} a[high]−a[low]key−a[low]
它是关键字到最低下标的距离 和 最高下标到最低下标的距离的比值。它的物理意义很简单:关键字大概在查找表中什么位置,大概在哪一段。
但是这个插值公式本身就决定了,插值算法适用于那些关键字分布均匀连续,一个一个规规矩矩往后排,没有大的断层现象的查找表,而且查找表的长度并不影响查找效率,查找表越长反而越能体现效率的优势。
从二分查找推出插值公式
插值查找算法受了一点二分查找的启发。
二分查找中,中间元素的位置的计算公式是
m
i
d
=
l
o
w
+
h
i
g
h
2
mid=\frac{low+high}{2}
mid=2low+high,变换一下就是
m
i
d
=
l
o
w
+
1
2
(
h
i
g
h
−
l
o
w
)
mid=low+\frac12(high-low)
mid=low+21(high−low),即中间元素的位置等于 最低下标 加上 最高下标和最低下标的差的一半。
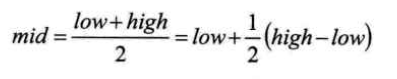
我们要改的就是这个 1 2 \frac12 21。
把这个
1
2
\frac12
21改为上述插值公式,则中间位置mid的计算公式变为:
m
i
d
=
l
o
w
+
k
e
y
−
a
[
l
o
w
]
a
[
h
i
g
h
]
−
a
[
l
o
w
]
(
h
i
g
h
−
l
o
w
)
mid = low + \frac{key-a[low]}{a[high]-a[low]}(high-low)
mid=low+a[high]−a[low]key−a[low](high−low)
算出来如果不是整数则截断式取整。
用一个例子来感受优化效果
假设查找表是一个int数组
a
[
11
]
=
{
0
,
1
,
16
,
24
,
35
,
47
,
59
,
62
,
73
,
88
,
99
}
a[11]=\left\{0,1,16,24,35,47,59,62,73,88,99\right\}
a[11]={0,1,16,24,35,47,59,62,73,88,99}
起始状态:
low=1(注意low并不是指向0!!!),high=10
假设要找的数字是62,在这里数值本身就是关键字,所以key=62
- 如果用二分查找,则第一次,
1
+
10
2
=
5.5
\frac{1+10}{2}=5.5
21+10=5.5,截断取整为5,mid=5,找到47,low变为6;
第二次, 6 + 10 2 = 8 \frac{6+10}{2}=8 26+10=8,找到73,high变为7;
第三次, 6 + 7 2 = 6.5 \frac{6+7}{2}=6.5 26+7=6.5,找到59,59小于62,所以low变为7,
第四次, 7 + 7 2 = 7 \frac{7+7}{2}=7 27+7=7,找到62
总共找了4次。
- 如果用插值查找呢?
第一次, k e y − a [ l o w ] a [ h i g h ] − a [ l o w ] = 62 − 0 99 − 0 = 0.626262 ⋅ ⋅ ⋅ \frac{key-a[low]}{a[high]-a[low]}=\frac{62-0}{99-0}=0.626262··· a[high]−a[low]key−a[low]=99−062−0=0.626262⋅⋅⋅, m i d = 1 + 0.626262 ∗ ( 10 − 1 ) = 6.636363 ⋅ ⋅ ⋅ mid=1+0.626262*(10-1)=6.636363··· mid=1+0.626262∗(10−1)=6.636363⋅⋅⋅,mid截断为6,找到59,59小于62,所以low=7
第二次, k e y − a [ l o w ] a [ h i g h ] − a [ l o w ] = 62 − 62 99 − 62 = 0 \frac{key-a[low]}{a[high]-a[low]}=\frac{62-62}{99-62}=0 a[high]−a[low]key−a[low]=99−6262−62=0, m i d = 7 + 0 ∗ ( 10 − 1 ) = 7 mid=7+0*(10-1)=7 mid=7+0∗(10−1)=7,找到62
总共只花了2次。
当然,并不是什么情况下,插值查找都能比二分查找的查找次数少,必须是查找表的关键字们适合用这个插值公式来计算他们的大体位置才行。
代码
由于只是把二分查找的 1 2 \frac12 21改了,所以代码也只是改mid公式那一行:
int Interpolation_Search(int *a, int n, int key) { int low, mid, high; low = 1;//注意不是0哦! high = n; while (low<=high) { mid = low + (high - low) * (key - a[low])/ (a[high] - a[low]);//整数除法 if (key < a[mid]) high = mid-1; else if (key > a[mid]) low = mid+1; else return mid;//查找成功 } return -1;//查找失败 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
优缺点(适用场景):插值公式计算出来的概率是否符合数据在查找表中的位置次序
没人十全十美,也没有算法在什么问题上都是香饽饽。
这里说插值算法的优缺点,不如说是在说他的适用场景。
一个查找表是否适合用插值查找算法的判定依据是:插值公式计算出来的概率是否符合数据在查找表中的位置次序。
- 适用于:表长较大,关键字分布比较均匀的查找表。
- 不适用于:反之。比如 { 0 , 1 , 2 , 2000 , 2001 , ⋯ , 999998 , 999999 } \left\{0,1,2,2000,2001,\cdots,999998,999999\right\} {0,1,2,2000,2001,⋯,999998,999999},这个查找表就不适合插值查找法。
斐波那契查找:利用黄金分割原理,只用加减运算, O ( log n ) O(\log n) O(logn)
Fibonacci search
先说斐波那契数列,斐波那契数列的定义是:从第三项开始,每一项都等于前两项之和。
F
(
n
)
=
F
(
n
−
1
)
+
F
(
n
−
2
)
F(n)= F(n-1)+F(n-2)
F(n)=F(n−1)+F(n−2)
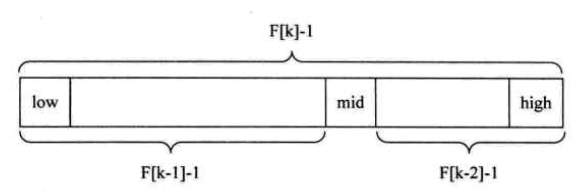
而斐波那契查找就是基于这个公式得到的思路,它利用黄金分割原理,把扩展后的查找表(长度为
F
[
k
]
−
1
F[k]-1
F[k]−1)分为左侧长半区和右侧短半区,左侧长度是
F
[
k
−
1
]
−
1
F[k-1]-1
F[k−1]−1,右侧长度是
F
[
k
−
2
]
−
1
F[k-2]-1
F[k−2]−1所以左侧一定比右侧长,但是左右侧的长度的比值并不是固定值1.618(所以我觉得应该和黄金分割原理没关系):
F
[
k
−
1
]
−
1
F
[
k
−
2
]
−
1
\frac{F[k-1]-1}{F[k-2]-1}
F[k−2]−1F[k−1]−1
看个更长的(来自维基百科)

代码
int FibonacciSearch(int *a, int n, int key)//a指向的数组是长度为n的查找表 { int low, high, mid; low = 1; high = n-1; //找到n在斐波那契数列中的位置k int k = 0; while (n > F[k]-1) ++k; //补齐数组长度,最大值补全 int i; for (i=n;i<F[k]-1;++i) a[i] = a[n]; //核心代码 while (low<=high) { mid = low + F[k-1]-1; if (key < a[mid])//在左侧长半区 { high = mid - 1; --k;//k=k-1 } else if (key > a[mid])//在右侧短半区 { low = mid + 1; --k;//k=k-2 --k; } else { if (mid <= n) return mid; else return n;//在补全位置找到的,所以就是第n个元素 } } return 0;//没找到,查找失败 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
举个例子,数组是
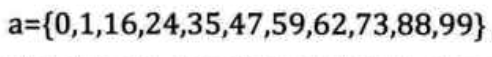
查找59,初始状态是low=1,high=10
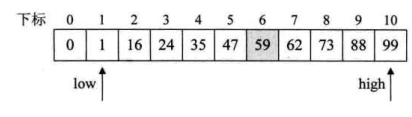
- 首先,数组长度为11,k = 7, 所以把数组长度补充为13,a[11]=a[12]=a[10]=99
- 开始查找。第一次查找,mid=1+F[6]-1=8, key=59<a[mid]=73,所以high=mid-1=7,落在左侧,k=k-1=6;排除了右侧下标8-12的5个位置
- 第二次查找,mid=1+F[5]-1=5,a[mid]<key,所以落在右侧,low=mid+1=6,k=k-2=4;排除了左侧的下标0-5的6个位置
- 第三次查找,mid= 6+F[3]-1=7, a[mid]>key,落在左侧,high=mid-1=6,k=k-1=3,排除了位置7,只剩下位置6了
- 第四次查找,mid=6+F[2]-1=6,a[mid]=key,结束;位置6刚好就是要找的关键字,于是查找成功,但这一步也是有可能把位置6排除掉从而得到查找失败的结果的。
和折半查找的对比
- 平均起来,性能优于折半查找
从上面的例子可以看到,斐波那契查找的好处是,一次性可能排除掉多于一半的位置(当然也可能排除少于一半),而二分查找固定每次查找只可以排除一半位置。所以平均起来,优于二分查找
如下图,每一次查找后,确定的新范围要么有F[k-1]-1个元素(则排除了F[k-2]个元素),要么有F[k-2]-1个元素(则排除了F[k-1]个元素)。
- 斐波那契查找法在key等于a[1]时是这种算法的最坏情况,这时候就比二分查找查了。因为算法将一直排除右侧短区,而始终在左侧长区中查找,一直到找到最左边。
对三种有序表的总结:本质差别是分隔点的选择不同
所以不能简单说孰好孰坏,要根据自己数据的特点进行选择。
其他差别:
- 二分查找使用加法和除法;插值查找使用四则运算,加减乘除都用;斐波那契查找只使用了加减法运算。这点细微差别,对于海量数据的查找,就很重要了。
- 斐波那契查找的坏处是:需要依赖斐波那契数列的数值来加长数组
相同点
- 都是通过区间分割,不断把查找区间缩小


