
- 1Django 入门教程_django入门教程
- 2Kettle的安装及简单使用
- 3linux(ubuntu20.04)+PicGo(gui版)+github+typora搭建笔记
- 4卷积神经网络(CNN)网络结构及模型原理介绍_卷积神经网络结构
- 5常用网络结构:深度残差理解Resnet_resnet综述
- 6uniapp转小程序,小程序转uniapp方法_uniapp如何转成原生小程序
- 7coma运行代码遇到的问题_no module named 'psbody
- 8Linux命令经典面试题:统计文件中出现次数最多的前10个单词_怎么统计指定条件出现次数最多的词
- 9好发现个开源又完全免费的大屏设计器_开源大屏组件
- 10小程序内嵌uniapp页面跳转回小程序指定页面方式
【万字图解】超级详细Transformer、self-attention教程、encoder、decoder、训练、推理、embedding_transformer embedding encoder
赞
踩
目录
序言
1. 整体模型架构
1.1. 论文原始图编辑
1.2. 精简图
2. transformer输入
2.1. 词embedding
2.2. 位置embedding
3. Encoder
3.1. 输入
3.2. Multi-Head Attention
3.3. add&norm
3.4. Feed Forward
3.5. 多层编码器堆栈
5. Decoder
5.1. 训练
5.1.1. 训练方法
5.1.2. 输入
5.1.3. Maskd Multi-HeadAttention
5.1.4. cross attention(注意这里不是Masked Multi-head-attention)
5.1.5. 输出
5.2. 推理
5.2.1. 推理过程示意图
5.2.2. 对比encoder和decoder的输入方式
5.2.3. 图解:训练与推理输入不同却等价原因
5.2.3.1. 分析encoder输入
5.2.3.2. 分析teacher forcing的推理输入
5.2.4. 推理模式变种
5.2.4.1. 输出序列长度不和输入等长
5.2.4.2. transformer做回归任务
5.2.5. cross attention
6. 心得
6.1. 全连接网络与矩阵之间的关系
6.2. 问题记录:
6.3. tips
6.4. 思考
6.4.1. 一个值得注意的地方
序言
其实在观看本博客前建议先看一下李宏毅老师的视频作为本博客的铺垫,看完后可以来阅读此博客,你将会对transformer有更加深刻,深入的认识,本博客会贯穿一个例子通过图解的方式更直观地展现transformer的一些较为抽象的地方。尤其是decoder部分,我相信你一定非常苦恼网上decoder部分的教程如此之少还懵懵懂懂,通过本博客你可以详细了解它。
李宏毅老师的视频
Transformer终于有拿得出手得教程了! 台大李宏毅自注意力机制和Transformer详解!通俗易懂,草履虫都学的会!_哔哩哔哩_bilibili
一些比较好的学习博客
层层剖析,让你彻底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的机制和原理_masked attention-CSDN博客
pytorch中transformer模型的使用(非原理)
1. 整体模型架构
1.1. 论文原始图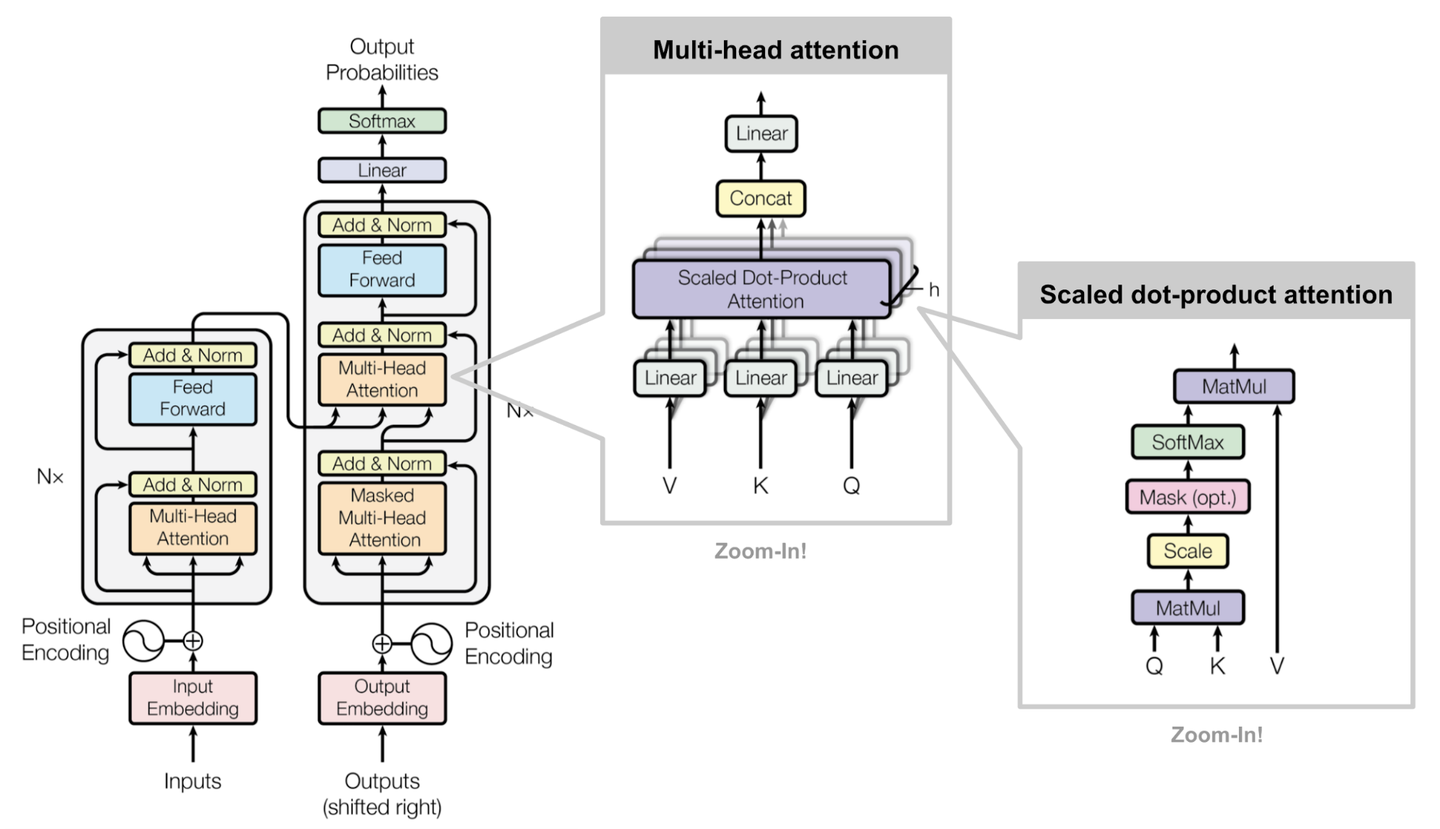
这是Attention Is All You Need论文原始图像,先放在这里,方便查看,后面将详细展开模型中的模块
1.2. 精简图

这是上面详细图的一个展开图,把Nx部分展开了,并且我们可以看到左边Nx每个部分都叫一个encoder,同理右边叫Decoder,我们整篇文章将会围绕着一个翻译“我有一只猫”作为例子展开所有细节(这里的tokens中的<begin><end>都是很有讲究的哦,注意看清楚)
2. transformer输入
2.1. 词embedding
注意:建议先别看这部分内容,我们只要知道我们输入的数据转换成了一个输入矩阵就可以了,等将整个流程理解了再来看是如何转换的即可。
【python函数】torch.nn.Embedding函数用法图解-CSDN博客
我们在翻译输入时都需要将我们的输入文字转换成一个词嵌入矩阵,上面这个博客讲的已经非常清楚了,我再来概括一下。
说白了就是创建了一个矩阵存储了所有文本的内容,比如一篇文章100个词汇,那么可以创建一个(100,8)的矩阵存储他们,每一行表示一个词汇,并且每个词汇在第几行都是确认的,当我们想要拿出我这个词的时候利用一个(1,100)的one-hot矩阵(这个矩阵数值为1的位置正好对应embedding矩阵中这个词对应的位置)与这个embedding矩阵叉乘就拿出了这个词的词嵌入表示。
2.2. 位置embedding
位置嵌入部分理解起来会比词嵌入部分困难一点。下面有几个博客写的不错,我们可以看一下。
如何优雅地编码文本中的位置信息?三种positional encoding方法简述
Transformer学习笔记一:Positional Encoding(位置编码)
首先我们要知道positional encoding和input embedding其实是两个矩阵相加的关系,所以我们通过positioanl embedding也会得到一个和词嵌入input embedding一样大小的矩阵。
相信在上面的文章中我们都看到了很多不一样的位置表示方式,及其优劣,其中很重要的两个点就是绝对位置表示和相对位置表示,因为当我们输入一段文字的时候我们需要这个词汇在整句话或者整篇文章中的绝对位置,还有某个词汇和其他的相对位置
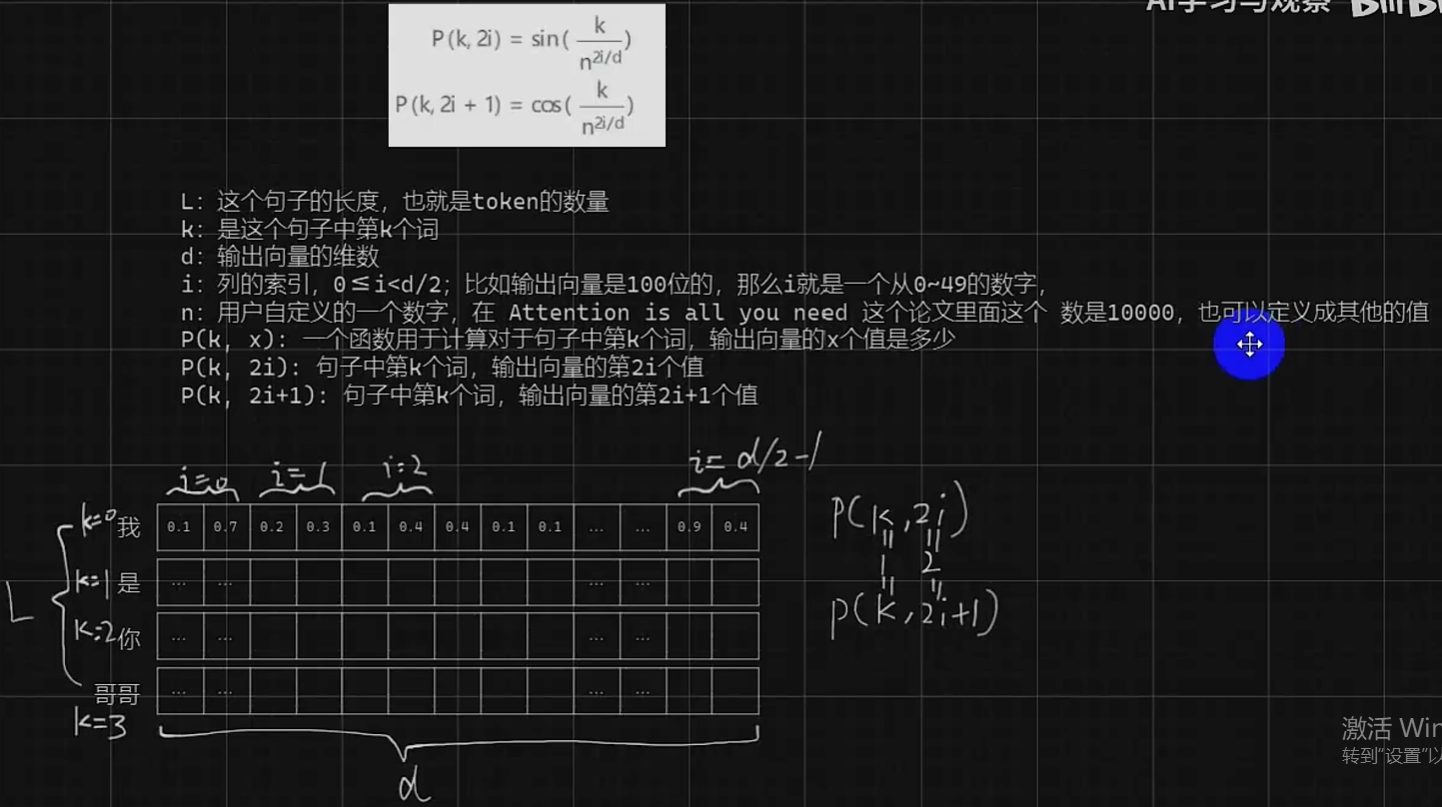
我们最先想到的就是用0,1,2,3去直接定义他们的位置关系,问题就是,我们训练时候最多用到了99,我们现在输入一个长度是133的文本进来,这个数字神经网络以前是没见过的,那就容易出问题,用[0,1]之间的数分配每个词汇会让每一次训练、推理文本间隔都不一致。
这个时候我们可以采用多个维度同时表示,怎么操作呢,举个例子,我们想告诉神经网络我这个token绝对位置,我们又希望输入的数据一只都在一定的范围内,因为你要是输入一个100000,神经网络之前没见过,泛化能力就不强,通过引入sin函数让输出结果限制在0-1之间,然后i就相当于一个旋钮,最终虽然每一列得到了都是0-1之间的小数,但是含义可能都是不相同的,i=1那一列距离单位可能是0.001,i=4那一列可能就是1000,这样这些数据经过一个全连接相乘再相加后便得到了它对应的绝对位置。这是只有sin函数的情况下,selef-attention的作者为了引入相对位置加入了cos列,怎么做呢?

我们可以看到偶数列都是使用sin来表示的,奇数列一定有有一个对应的cos,当我们得到Q矩阵和K矩阵后会进行Q*K转置(如果不知道QKV矩阵建议先往下看完self-attention)在进行叉乘的时候会让对应的sin和sin相乘,对应的cos和对应的cos相乘,比如说Q矩阵中代表“我”的那一行和K矩阵中代表“是”那一列相乘的时候其实会得到对应的sin*sin+cos*cos,然后我们又知道cos(a+b) = cos(a)*cos(b) - sin(a)*sin(b),这就会得到一个“我”和“是”相关位置信息的cos值,代表了“我”和“是”之间的相对位置关系。这里建议在下面self-attention详解图像中带入sin和cos去发现这些不同词汇之间的sin和cos是如何结合相乘的。
题外话:
为什么词嵌入信息和位置信息加在一起而不是其他方式?比如矩阵拼接?我举个例子,我给你一个图片让你猜这是哪两种动物,一个图片里包含了两张图片左右拼接,分别是猫和狗,一张图片是像素混合叠加在了一起,隐隐约约看到一个猫和一个狗,我们说猫和狗确实更难区分了,但是信息确实是还在的。
3. Encoder
3.1. 输入
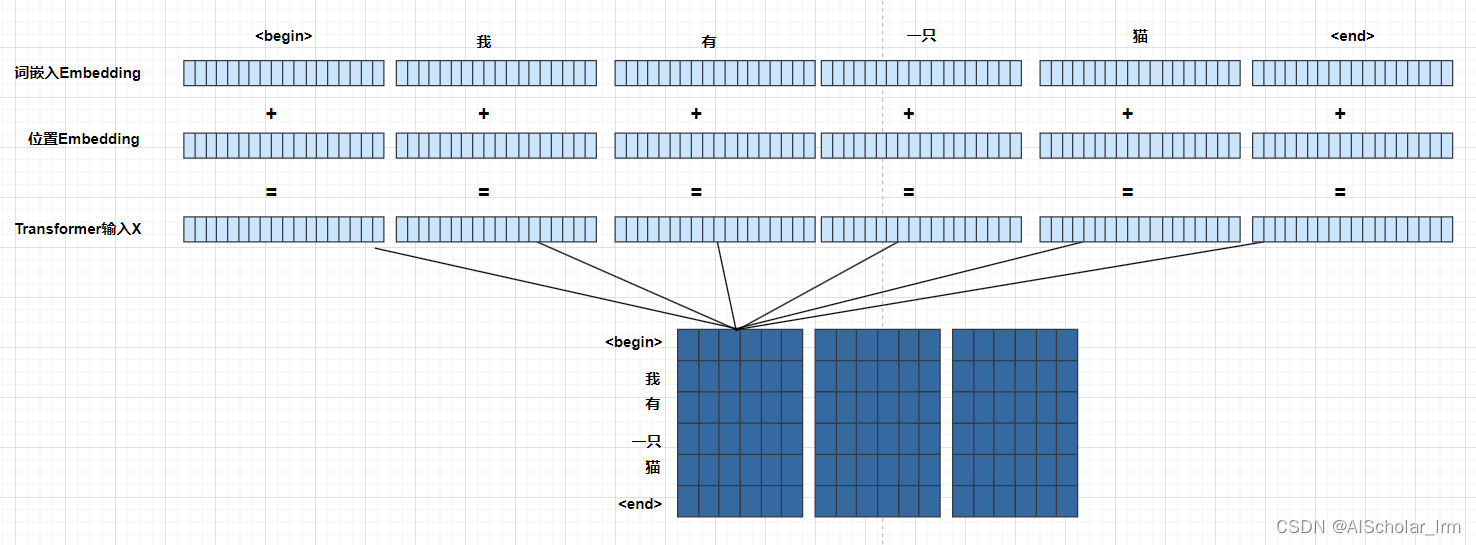
我们处理好了词嵌入和位置嵌入后就得到了输入到encoder中的输入矩阵X了,输入X由词Embedding和位置Embedding相加而成
词嵌入和位置嵌入的列我设计了18列,最后得到的输入矩阵X是(6,18)的矩阵,我把他们切开了,其实他们是在一起的,我这里是给大家强调一下,我们在多头自注意力的时候在这里就开始了,假设我们有三个头,那么就切成三份,就像下面这样竖着切,每一份矩阵进入不同的头计算(当你们遇到了这个报错:嵌入维度必须能被MultiheadAttention中的头数整除 的时候你就回来感谢我了,原因就在这里)
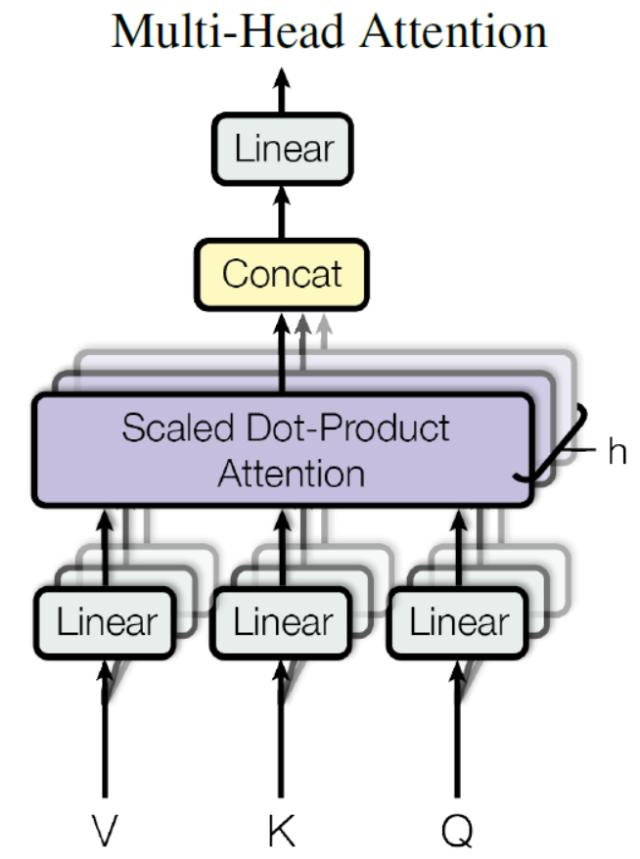
3.2. Multi-Head Attention
关于Attention的超详细讲解_attention详解-CSDN博客
Self-Attention机制的计算详解_自注意力机制计算-CSDN博客
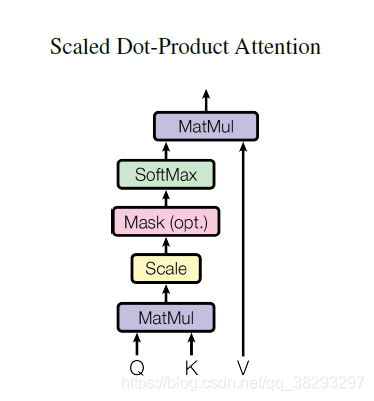
自注意力机制公式:
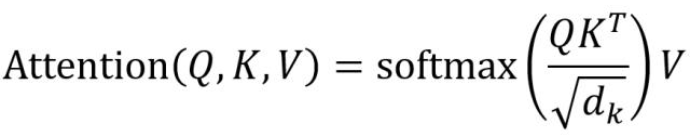
Scaled dot-product attention是self-attention的一种具体实现方式
每个self-attention是并行计算的
但是整个multi-attention是串行计算的
下面假设有三个head
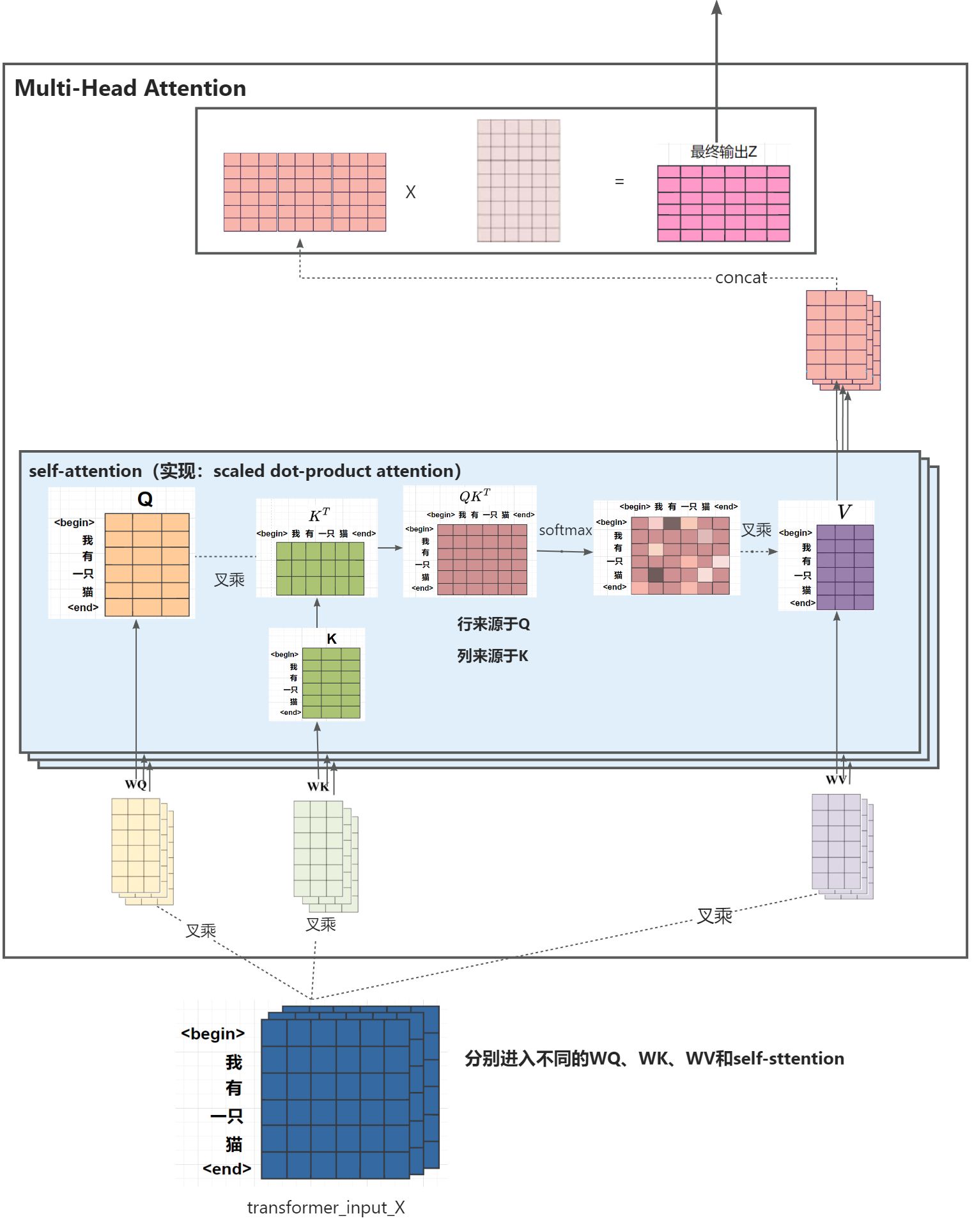
3.3. add&norm
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:
Layer Norm( X + MultiHeadAttention(X) )
Add:
指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:

Norm:
指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。

3.4. Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。

X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
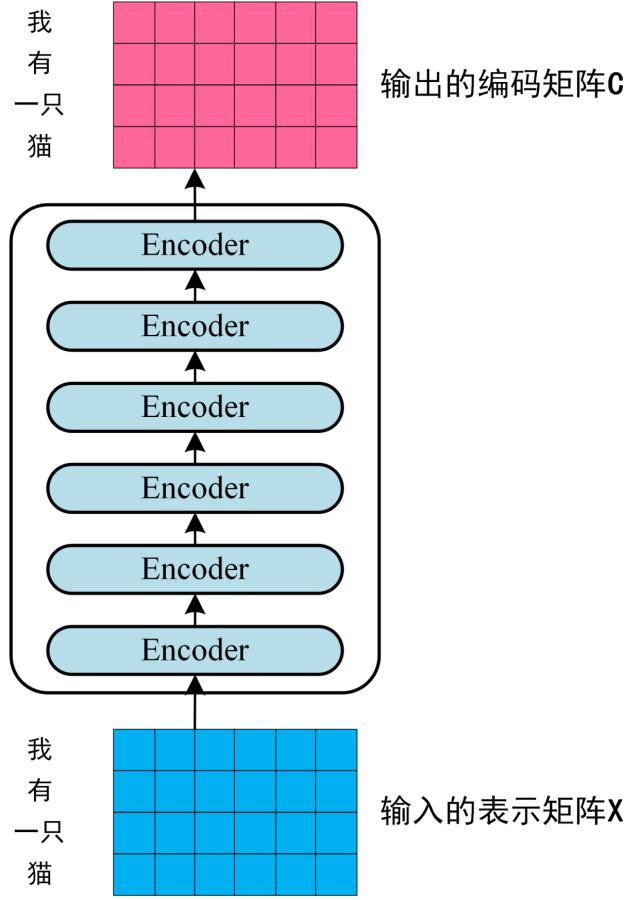
3.5. 多层编码器堆栈
对应原论文图中的Nx,就是六个相同的Encoder组合而成
5. Decoder
5.1. 训练
5.1.1. 训练方法
训练时向解码器输入整个目标序列的方法被称为 Teacher Forcing。
训练时,我们本可以使用与推理时相同的方法。即在一个时间步运行 Transformer,从输出序列中取出最后一个词,将其附加到解码器的输入中,并将其送入解码器进行下一次迭代。最后,当预测到句末标记时,Loss 函数将比较生成的输出序列和目标序列,以训练网络。
但这种训练机制不仅会导致训练时间更长,而且还会增加模型训练难度:若模型预测的第一个词错误,则会根据第一个错误的预测词来预测第二个词,以此类推。
相反,通过向解码器提供目标序列,实际上是给了一个提示。即使第一个词预测错误,在下一时间步,它也可以用正确的第一个词来预测第二个词,避免了错误的持续累加。
此外,这种机制保证了 Transformer 在训练阶段并行地输出所有的词,而不需要循环,这大大加快了训练速度。
5.1.2. 输入
输入处理和encoder一样,词embedding和位置embedding
5.1.3. Maskd Multi-HeadAttention

公式对比两个attention:
Multi-HeadAttention:
Maskd Multi-HeadAttention:
所以decoder的mask multi-attention层只是对进行了一个mask操作
mask操作方式如下:

我们输出下一个序列数据的时候不希望机器看到答案
我们希望机器应该这样输入输出:
输入:<begin> 0 0 0 0 输出:I
输入:<begin> I 0 0 0 输出:have
输入:<begin> I have 0 0 输出:a
输入:<begin> I have a 0 输出:cat
输入:<begin> I have a cat 输出:<end>
所以需要对每一行从预测数据开始后面所有的数据进行遮盖
得到 Mask之后在 Mask
上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。计算
后所得到的矩阵含义理解:

嵌入维度必须能被MultiheadAttention中的头数整除:
原始数据经过embedding后会得到一个序列:seq_len x emb_dim (假设,20 x 8),并且您希望使用num_heads=2,则该序列将沿着emb_dim维度拆分。因此,您将获得两个20 x 4序列。你希望每个头部都有相同的形状,如果emb_dim不能被num_heads整除,这是行不通的。以序列20 x 9为例,再以num_heads=2为例。然后你会得到不同维度的20 x 4和20 x 5。

5.1.4. cross attention(注意这里不是Masked Multi-head-attention)

在cross attention(交叉注意力)中同样输入QKV但是QKV的来源却不一样,K、V来自于encoder的输出,Q来自于Masked Multi-Head Attention的输出
这样做的好处是在 Decoder 的时候,每一个单词都可以利用到 Encoder 所有单词的信息
5.1.5. 输出
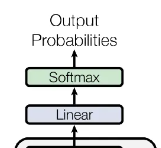
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下:

Decoder Softmax 之前的 Z
Softmax 根据输出矩阵的每一行预测下一个单词:

Decoder Softmax 预测
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。
5.2. 推理
5.2.1. 推理过程示意图

推理部分与训练部分的最大的区别在于,推理部分的输出必须是按顺序进行的
举个例子:encoder输入我有一只猫,这个时候decoder按顺序输入如下
输入:<begin> 模型输出:I
输入:<begin> I 模型输出:have
输入:<begin> I have 模型输出:a
输入:<begin> I have a 模型输出:cat
输入:<begin> I have a cat 模型输出:<end>
5.2.2. 对比encoder和decoder的输入方式
在Transformer模型中,encoder和decoder的输入并不完全相同。
- Encoder的输入是原始输入序列,例如在机器翻译任务中,这将是源语言的句子。
- Decoder的输入则稍有不同。在训练阶段,它的输入是目标序列,但是这个序列通常会向右移动一位(或者说在序列前面加上一个特殊的开始符号,如"<begin>“),这样做的目的是让模型在预测下一个词的时候能够看到之前的所有词。这种技术被称为"teacher forcing”。
在Transformer模型中,训练和推理时的输入方式略有不同。
- 训练时:在训练时,Decoder的输入是实际的目标序列,即"<begin> i love you <end>"。在每个时间步,Decoder都会接收到前一个时间步的输出作为输入。所以在这个例子中,Decoder的输入序列是这样的:
-
- 输入: <begin>, 输出:i
- 输入: <begin> i, 输出:love
- 输入: <begin> i love, 输出:you
- 输入: <begin> i love you, 输出:<end>
- 推理时:在推理时,我们不能直接使用目标序列作为输入,因为我们不知道目标序列。相反,我们会逐步生成序列。在每个时间步,Decoder会生成一个单词,并将其作为下一个时间步的输入。推理过程中的输入包括:
-
- 初始输入: <begin>
- 下一个输入: i
- 下一个输入: love
- 下一个输入: you
- 下一个输入: <end>
5.2.3. 图解:训练与推理输入不同却等价原因
其实我们自己观察encoder与decoder会疑惑一个问题,那就是训练时与与推理时的输入好似是不同的。
如果没注意到这个问题,那我举个例子说明什么是看似是不一样的:
5.2.3.1. 分析encoder输入
假设词嵌入后输入到一个头中的数据如下

然后进行Mask,再乘上V得到Z矩阵。
需要提示的一个点是Mask QKT矩阵的每一行的数据与Z的每一行数据是对应的,也就是说决定Z的某一行的输出是由Mask QKT的对应的行决定的,不会受到其他行的影响(矩阵叉乘的计算方法的缘故)
看下面的图,假设我们单独抽出第一、二行输入,我们看到其实在第二个token之后的数据神经网络并没有看到计算结果是(1,3)实际上真正参与计算的数据是没有被黑色部分遮挡的矩阵也就是其实这个矩阵计算可以看成是(1,2)*(2,3)=(1,3)!请记住这一结论
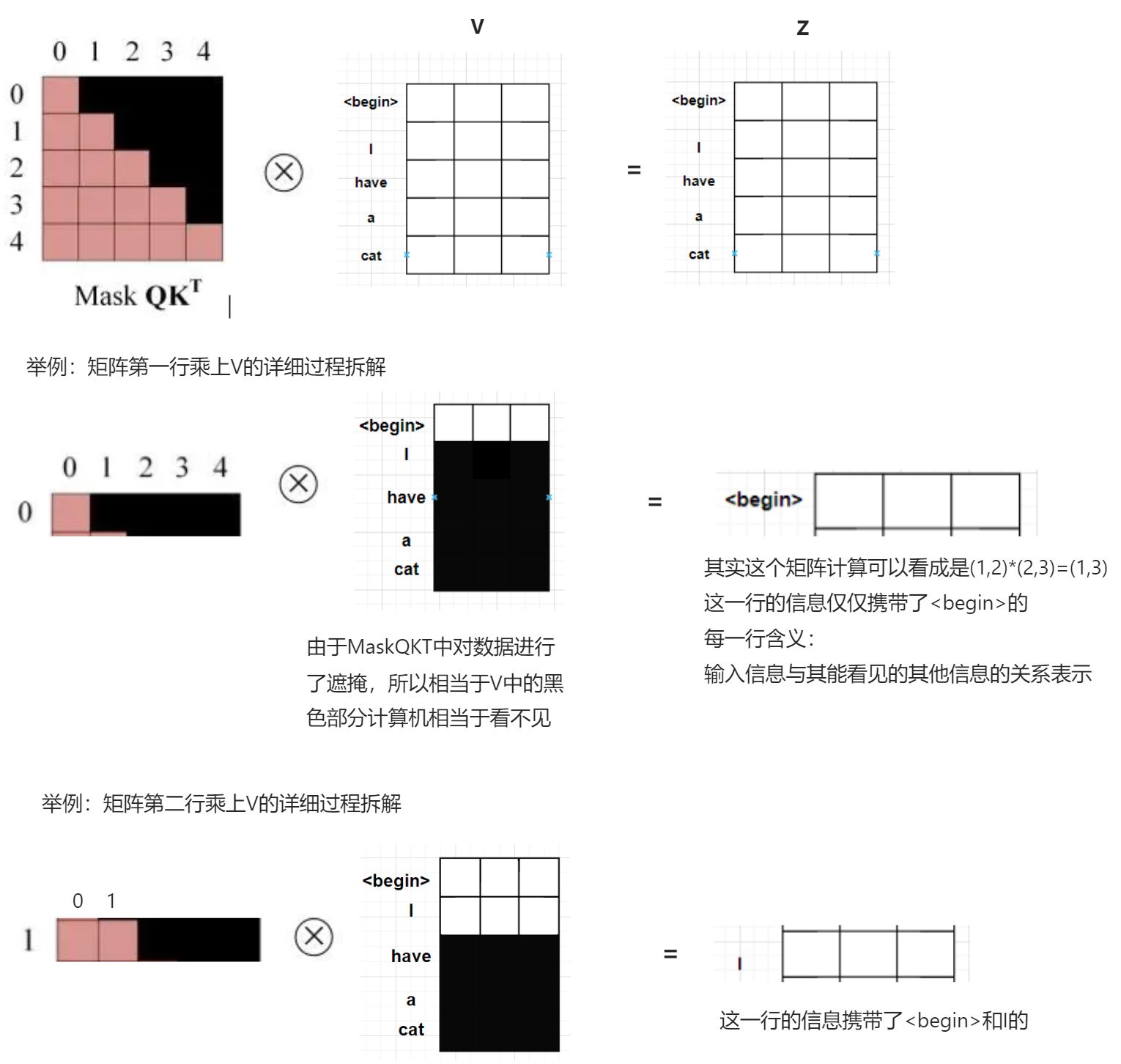
我们来真正看下Z矩阵每一行所携带的信息,第一行<begin>只携带了自身信息,第二行I携带了自身外还有<begin>信息,也就是说在自身信息前面的信息都携带了。后面不管是Z拼接也好,又乘上了一个线性层也好,对应的行都只携带了相同意义的信息,也就是说每一行的计算其实都是独立的。其实一行就是一次独立的训练!记住这一点
5.2.3.2. 分析teacher forcing的推理输入
我们正式开始推理部分:
假设我们输入<begin>
然后经过embedding后进入其中一个头的数据如下:

得到的Mask QKT矩阵与V矩阵如下:
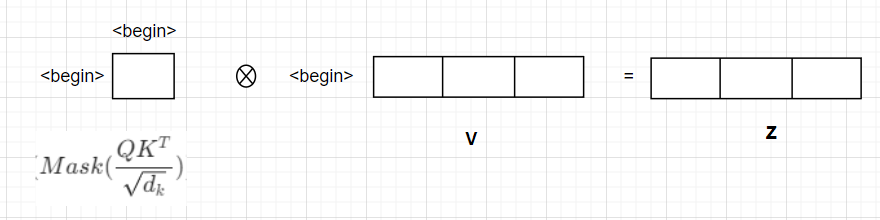
通过推理得到"I"

我们可以对比看到,因为我们进行了遮挡,所以其实训练与推理时的计算时是一样的,区别只是训练时计算结果多加了多少个0,所以对和推理的结果完全等价。
并且我们也很直观的看到了一个问题,就是我们重复计算了第一行输入

总结:
我们完全可以说其实训练时向decoder中输入数据和推理时向decoder输入数据是完全一样的,训练时用遮掩的方式等价模拟了推理时输入不同长度的数据。
5.2.4. 推理模式变种
5.2.4.1. 输出序列长度不和输入等长
我们在做seq2seq的时候其实输出的seq完全可以和输入不一样长,如果我们是做翻译,一般来说我们的输出雀食会和输入文本差不多长,但是啊,transformer的teacher forcing是很灵活的,比如说我们现在做一个文章的主题分析或者总结概括。那么输出文本一定比输入文本小的多。
如果我们仅仅只是输出一个数据那么我们就发现decoder出现的意义就失去了,我们可以这样想,我们每次作答时仔细分析我们回答(对比自注意力),没回答一个词思考一下下一个词怎么回答,同时分析原文(encoder的输入)最后做出下一个回答,那么decoder的目的其实就是做出下一个输出时,仔细分析自己已经说过的话,并且带着输出位置关系信息,这是他的真实目的,如果我们是输出一个输出值的话,decoder就失去了其意义,如果仅仅只是输出一个值,decoder便是多此一举。

5.2.4.2. transformer做回归任务
在回归任务重我们只需要使用encoder模块就可以了,在一般情况下,Transformer 架构中的编码器(Encoder)部分比较常用,尤其是在处理序列数据时。这是因为编码器能够很好地捕捉输入序列中的关键信息,并将其编码为一个上下文感知的表示,适用于许多任务,如机器翻译、文本生成、语义理解等。
在某些情况下,我们也会使用 Transformer 的解码器(Decoder)部分。例如,在机器翻译任务中,我们可以使用编码器来将源语言句子编码为一个表示,然后使用解码器来将这个表示解码为目标语言句子。解码器在生成序列数据方面非常有用,但并非所有任务都需要它。
另外,有时候也会将 Transformer 的编码器和解码器结合起来,构建一个端到端的序列到序列模型,例如用于聊天机器人或摘要生成等任务。这种情况下,我们同时使用编码器和解码器来处理输入和输出序列。
5.2.5. cross attention
假设我们有以下输入序列和目标序列:
- 输入序列 src = [0, 4, 3, 4, 6, 8, 9, 9, 8, 1, 2, 2],长度为12
- 目标序列 tgt = [0],长度为1
首先,我们对输入序列和目标序列进行embedding,并扩展维度以适应注意力机制的计算:
- src_emb = torch.LongTensor([[0, 4, 3, 4, 6, 8, 9, 9, 8, 1, 2, 2]]),维度为(1, 12)
- tgt_emb = torch.LongTensor([[0]]),维度为(1, 1)
然后,我们将这些embedding传递给Transformer模型的Decoder部分。在Decoder中,我们需要在每个时间步生成一个输出,直到生成特殊的结束标记<end>或达到最大输出长度。
对于每个时间步t:
- 使用tgt_emb作为Q,src_emb作为K和V,计算注意力分数:
-
- Q = tgt_emb * Wq,维度为(1, 1, 4)
- K = src_emb * Wk,维度为(1, 12, 4)
- V = src_emb * Wv,维度为(1, 12, 4)
- Attention_scores = softmax(Q * K.transpose(1, 2) / sqrt(4)),维度为(1, 1, 12)
- 使用注意力分数和V计算加权和,作为当前时间步的输出:
-
- Attention_output = Attention_scores * V,维度为(1, 1, 4)
- Output_t = Attention_output.sum(dim=2),维度为(1, 1)
- 将Output_t传递给线性层和softmax层,得到当前时间步的预测结果和下一个时间步的输入:
-
- Next_input = Output_t.argmax(dim=-1),维度为(1,)
- 如果Next_input是<end>或达到最大输出长度,则停止生成输出;否则,将Next_input作为下一个时间步的输入继续生成输出。
6. 心得
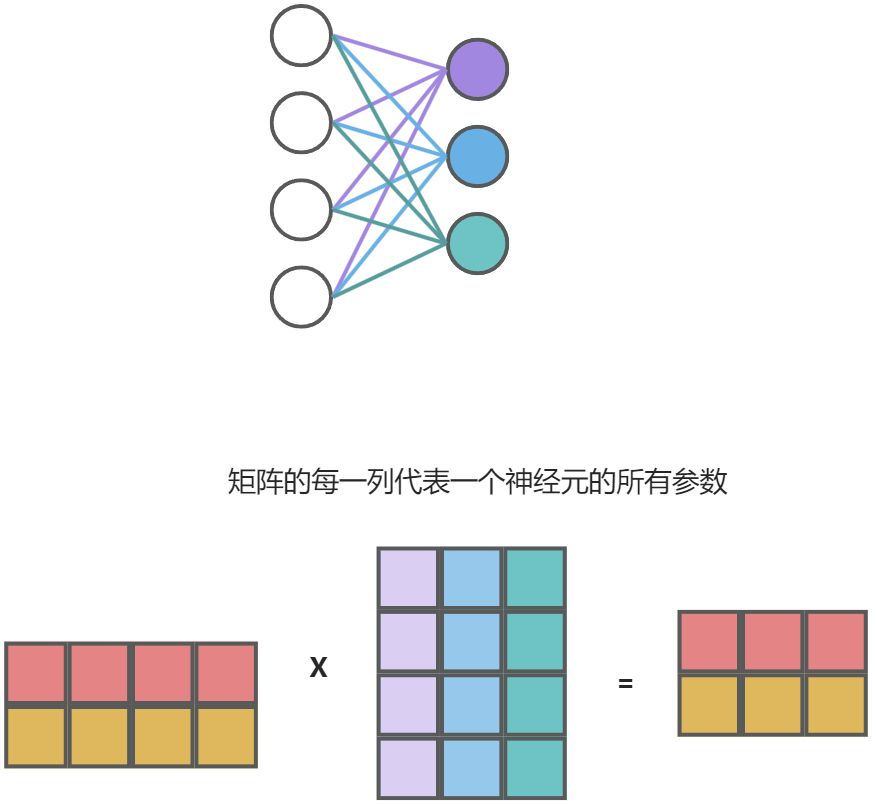
6.1. 全连接网络与矩阵之间的关系
输入数据的每一行数据进入神经网络都是相互独立的
举例子:一个batch数据,输入本需要(1,4)个数据,但是我一个batch数据同时输入输入了(2,4)个数据,相当于分别输入了两个(1,4)
6.2. 问题记录:
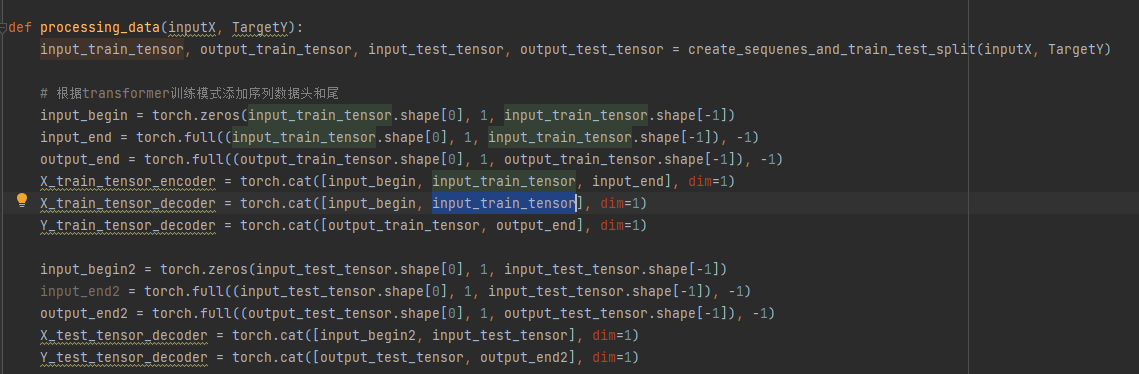
transformer的encoder输入是原始数据,decoder应该是目标数据!训练的时候带着mask遮蔽一下,在推理的时候第一次输入<begin>第二次输入decoder输出的最后一个数据。
上面是正确的,但是自己写的代码里却把输入encoder的数据加了个<begin>又输入到了decoder中!
说这个的原因是,我一开始学transformer的时候没注意这个问题,希望提醒下大家
6.3. tips
除了最基本的神经网络参数外,
- Transformer模型的反向传播会更新权重矩阵WQ、WK、WV
- Decoder中的KV来自encoder,Q来自decoder
6.4. 思考
6.4.1. 一个值得注意的地方
词嵌入embedding处理一个token数据(还没进行positional embedding)得到的(1,?)表示矩阵是不变且确定的
举个例子
我们输入123456经过词嵌入embedding(没进行位置嵌入)后得到A(6,128)矩阵,如果输入234561得到的矩阵B(6,128),那么A矩阵的第一行数据与B矩阵的第六行数据完全相等。
那么我们如果重新设计词嵌入,或者改变embedding,需要考虑论文原应用中的这个细节

