
- 1三天学会阿里分布式事务框架Seata-nacos注册中心和配置中心支持_seata nacos
- 2c++ 遗传算法学习笔记_c++ 手撕遗传算法
- 3网络规划与设计————期末复习
- 4安装ROS_ros安装下载
- 5国密算法SM2,SM3,SM4之间的区别及应用_国密sm4
- 6数据分析利器:XGBoost算法最佳解析_决策树预测 xgboost预测
- 7EnsNet: Ensconce Text in the Wild 论文笔记
- 8【AI安全之对抗样本】深度学习基础知识(一)_一维对抗样本
- 9Redis 整合中 Redisson 的使用_redisson连接redis集群
- 10Floyd算法&&Dijkstra算法_dijkstra和floyd算法
AI绘图实践-用人工智能生图助力618大促_迭代步数推荐
赞
踩
现在各种AI大模型大行其道,前有GhatGPT颠覆了我们对对话型AI的原有印象,后有Sora文生视频,让我们看到了利用AI进行创意创作的无限可能性。如今各大公司和团队都争相提出自己的大模型,各种网页端和软件应用也极大地降低了我们使用AI作为生产力的门槛。
我这次就为大家带来使用AI进行绘图的入门实践,为大促文章配图,绘制大促广告宣传海报,提升促销图的画质和精度,探索一下从这方面助力大促的新思路。
平台
现在的AI绘图主要用到的模型是SD(Stable Diffusion),它是一种稳定扩散模型,用于生成高质量的图像。这种模型是在传统的扩散模型DDPMs(Denoising Diffusion Probabilistic models)的基础上发展出来的。
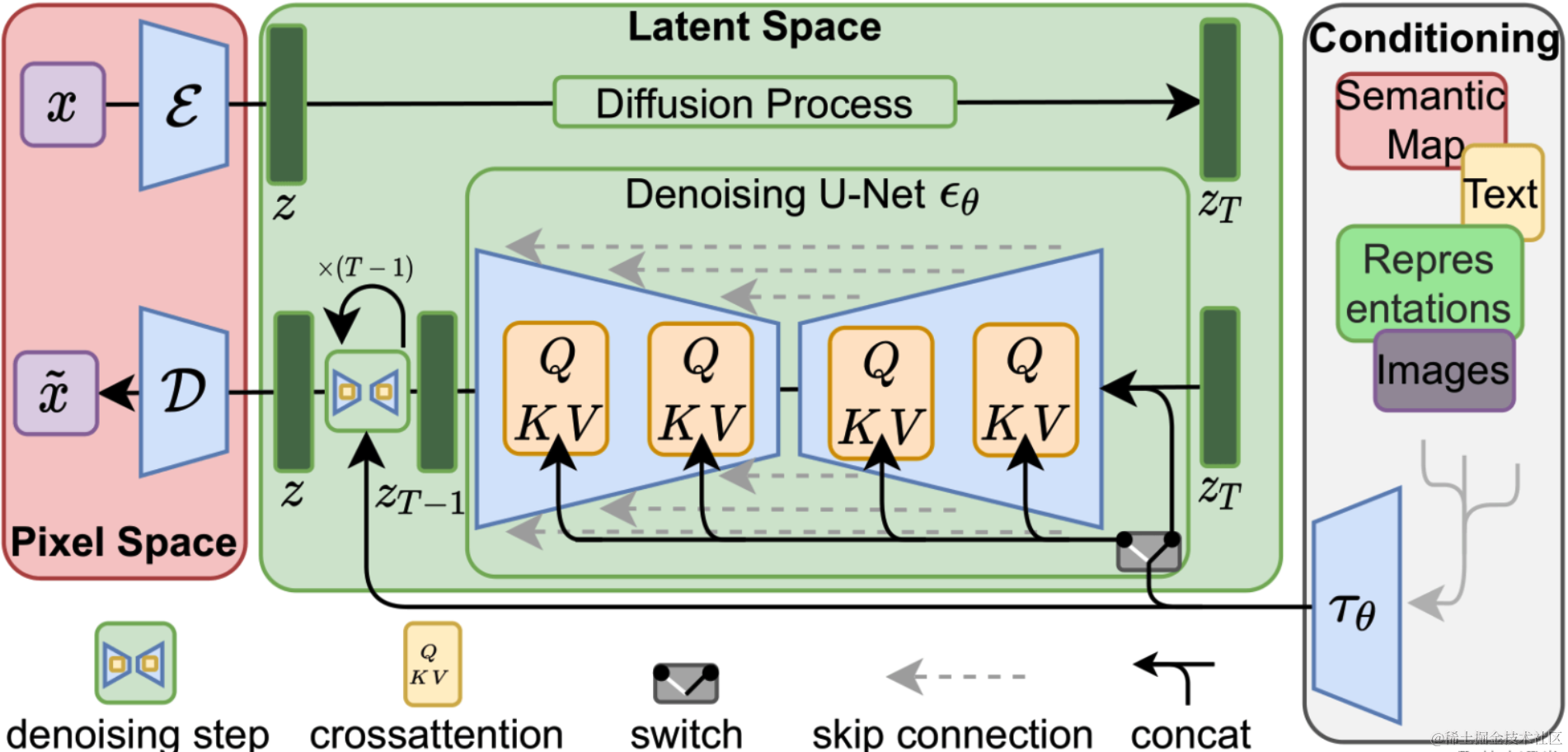
经过多个版本的迭代和改进,这类模型已经能很好的执行“文生图”、“图生图”、“后期处理”等AI功能,甚至可以在一定程度上代替PhotoShop等图像处理软件的工作。
现在许多开发者都发布了基于SD模型的改进型模型,基本上所有的网页端和软件也都是基于此模型搭建的,要使用它进行AI绘画,主要有三种方法:
1.自己搭建基于SD的webui,在gitHub上有项目的源代码: https://github.com/AUTOMATIC1111/stable-diffusion-webui 。这种方式的优点是自由度高,可以根据自己的需求进行客制化改造,更新也最及时,但是要自己进行环境搭建,对于一般用户来说学习门槛较高,国内使用的话需要魔法,同时经过我的体验稳定性不高,经常会失败。
2.使用网页端应用,这类网站是基于stable-diffusion-webui 搭建的第三方平台,由他们负责维护和更新,并提供稳定的连接,用户只需要选择需要的模型和参数,输入提示词,就可以在线生成图片。
国内有:
Liblib Ai: https://www.liblib.art/
MJ: https://mj.wxcbh.cn/home/?from=AI05&strategy=drawing5&bd_vid=17724435435623318479#/mj
都不需要魔法 。
国外的像:Playground AI: https://playground.com/ ,每天有免费的体验次数,速度和质量也不错。
这类网站一般都有自己的模型市场,以供创作者们上传和下载自定义的模型,并且分享自己的绘图作品以及相关生图的参数,非常方便。但是一般都会收费,都会收费,都会收费,重要的事情说三遍。
3.PC端软件,这类软件一般也是基于SD模型进行封装,可以下载模型,设置参数并在本地生成图片,使用体验类似于PS等图片处理软件,但是由于整个生成过程在本地执行,比较依赖于本机算力,电脑性能不好的话生成会很慢,但是好处就是自定义程度相对较高,而且一般免费。
生图软件
我这次主要介绍软件的途径,使用的软件就是这款Draw Things,Mac端App Store免费下载,不需要魔法

他的界面是这样的:
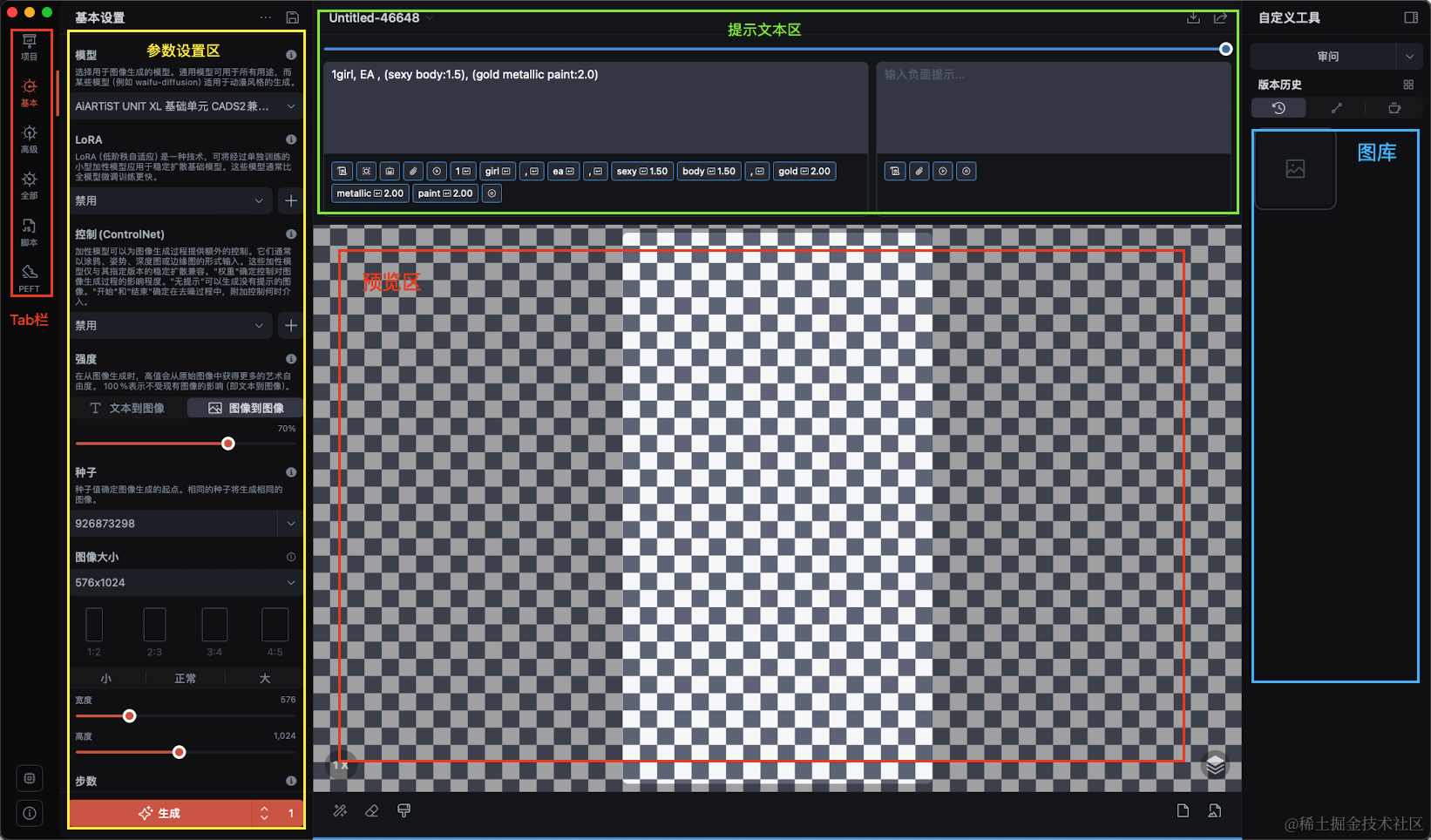
参数设置区用于选择模型,采集器,步数和随机种子等参数,首次生成图片首先选择“文本到图像”模式。在这里我大致介绍一下涉及到的名词:
模型
模型是AI绘画的基础,一般的模型都是基于SD改进的,SD模型也有V1.0、V1.5、V2.0、V2.1等不同的迭代版本,不同的模型可以生成不同风格的图片,可以根据自己的需要进行选择,模型可以在DrawThings里进行下载和选择,当然也可以在Liblib Ai等网站上下载然后导入。
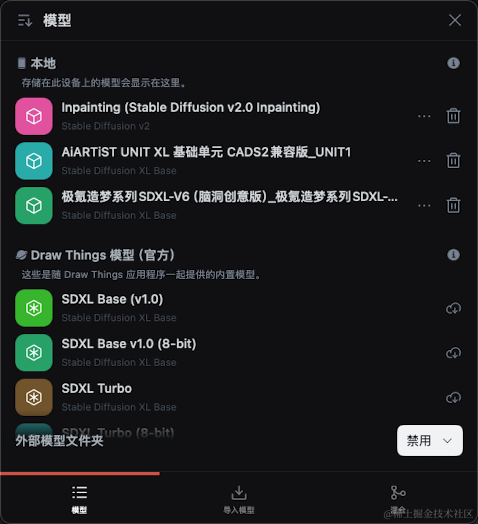
模型分为几个主要的种类:
chekpoint(检查点)
它是完整模型的常见格式,模型体积较大,一般真人版的单个模型的大小在7GB左右,动漫版的在2-5个G之间。决定了图片的整体风格。chekpoint的后缀名是safetensors
有写实,科幻,漫画,广告等等风格
Lora
是一种体积较小的绘画模型,是对大模型的微调。可以添加Lora为图片创造更丰富的表现形式。与每次作画只能选择一个大模型不同,lora模型可以在已选择大模型的基础上添加一个甚至多个。一般体积在几十到几百兆左右。
Lora的后缀名也是safetensors,所以在安装的时候要注意,Lora要在规定的地方导入:

Hypernetwork(超网络)
类似 LoRA ,但模型效果不如 LoRA,不能单独使用,需要搭配大模型使用
采样器
采样器也会在一定程度上影响图画风格,不同于模型,它一般是基于算法。选择对的采样器对于生成图片的质量至关重要,下面介绍一些主流的采样器类型:
DDIM和PLMS是早期SD专为扩散模型而设计的采样器。DPM和DPM++系列是专为扩散模型而设计的新型采样器。DPM++是DPM的改进版。
Euler a 比较适用于图标设计、二次元图像、小型场景等简单的图像数据生成场景。
DPM和DPM++系列非常适用于三维景象和复杂场景的描绘,例如写实人像。
Karras系列是专为扩散模型而设计的改进版采样器,有效提升了图片质量。
Euler a,DPM2 a, DPM++2S a和DPM++2S a Karras适合给图片增加创造性,随着迭代步数的提升,图片也会随之变化。不同的采样方法可能对不同的模型产生不同的影响,会影响生成图片的艺术风格,建议结合模型和迭代步数多做尝试。
步数
生图时,去噪重复的步数被称为采样迭代步数。
测试新的模型或Prompts效果时,迭代步数推荐使用10~15,可以快速获得结果,方便进行调整。当迭代步数太低时,生成的图像几乎无法呈现内容。20 ~ 30之间的迭代步数通常会有不错的效果。40步以上的迭代步数会需要更长的生图时间,但收益可能有限,除非在绘制动物毛发或皮肤纹理等。
过低或过高的初始分辨率都可能会让SD生图时无法正常发挥,建议参考基础模型的分辨率,配置合适的初始宽高
随机种子
随机种子会影响生图时的初始噪声图像。
当Seed=-1时,表示每次出图都会随机一个种子,使得每次生成的图都会不同。其他创作者上传图片的时候,一般会附带此图片对应的随机种子,可以参考它来生成类似的图片。点击可以生成一个随机的种子,长按则可以输入特定的随机种子。
提示词
提示词是生成图片时关键中的关键,它直接决定了图片内容,画面风格,场景,表情动作等一些列内容,在生成图片时,选择合适的提示词至关重要。

提示词分为“正向提示词”和“反向提示词”,“正向提示词”代表你想要在图片中呈现的内容,反之“反向提示词”则是不想要在图片里具备的要素。
比如,我想要画一张“618西瓜大促”相关的宣传图,我就可以这样描述:
“许多人在湖里流动的水边吃西瓜,高质量的微型摄影”,翻译成英文:“Many people eat watermelons by the flowing water in the lake, with high-quality miniature photography”
将这段文字输入DrawThings的文本框,它会自动把整句话拆分成一个个提示词。
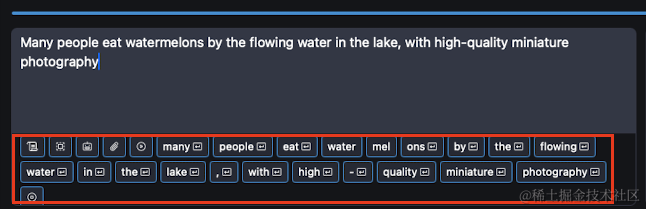
当然,我们也可以直接填入想要绘制的提示词:
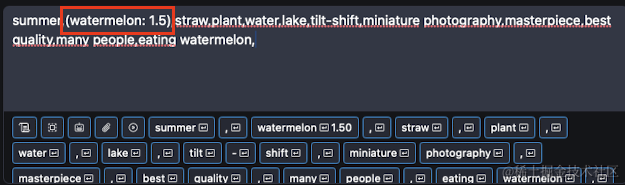
如上图所示,如果我们想着重强调某一个提示词,让AI绘制的时候更偏重一这一特征,就可以用括号把它包起来,然后在后面注明权重,这里我就把西瓜(watermelon)加重到了1.5权重,以便更加突出这一点。
“反向提示词”一般有:低质量,不适合上班时间浏览(NSFW),描绘人物的时候,糟糕的眼睛,多余的手指,扭曲,变形等等

其他
还有一些其他的参数,比如图片分辨率和比例,文本指导强度(越高越忠实呈现文本内容),以及一次生成的图片数量等等
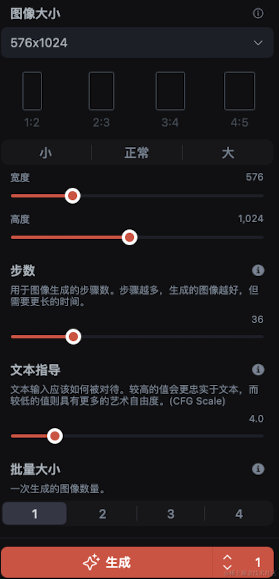
设置好一切,就可以开始生成图片了,可以多尝试几张,从中挑选最合适的进行二次处理。
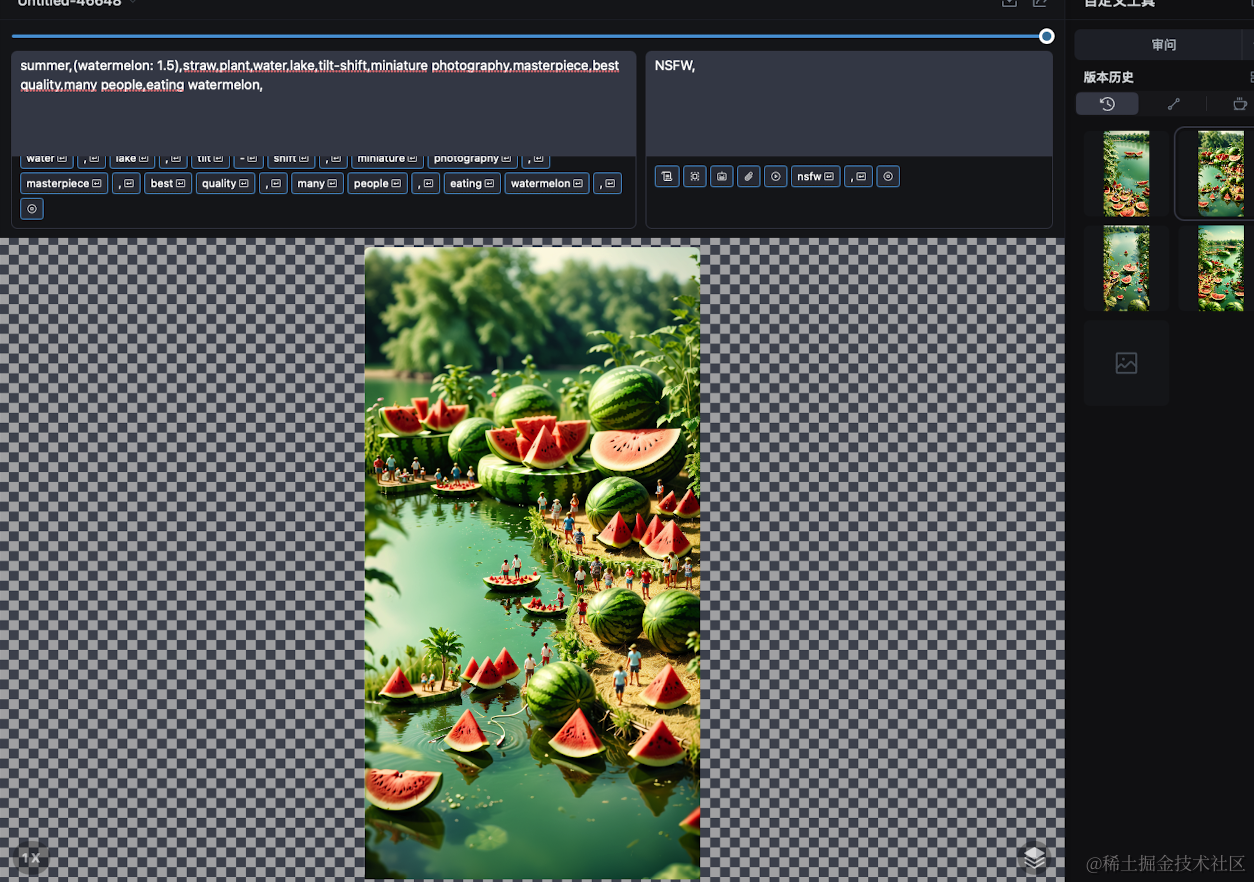
二次处理
如果对生成的图片有些细节不满意,可以利用“图像到图像”模式,然后选择强度。高分辨率修复的重绘强度为0时不会改变原图,30% 以下会基于原图稍微修正,超过 70% 会对原图做出较大改变,1 会得到一个完全不同的图像。
二次处理主要包括以下几个目的:
重绘图像元素
如果对图像中某部分的元素不满意,可以用“橡皮擦”擦除该部分,然后重新生成,让模型自动将擦数的部分重绘,甚至可以消除某部分图像元素,实测效果甚至好于PS。

扩图
对于一张图片,如果想要扩展边界部分,让模型绘制出额外的内容,可以首先重新设置图片的宽高。我这里原是图片是1088*2048,想要扩展左侧湖里的景象,就可以先将图片宽度增加到1536,然后移动图片到右侧贴紧图层边缘。然后最关键的一步,用“橡皮擦”工具,沿着想要扩展的那一边,细细的擦一道,这么做的目的是告诉模型,从这一部分开始重绘,风格要按照擦除的这部分来进行,然后重新生成图片。

提升画质
最开始生成图片时,为了提高速度和效率,可以适当降低分辨率,的到合适的图片以后,可以重设分辨率和清晰度,重绘图片,达到提升画质的目的。当然,对于已经已经画好的第三方图片,也可以加载进来进行处理。
好了,本篇利用AI绘图进行实践的文章就介绍到这里,希望能够帮助到大家。在以后大促文章配图,和大促海报绘制方面为大家提供便利,助力618大促再创新高!


