
- 1基于SpringBoot+Vue的在线公务员考试练习系统_公考在线题库网站 csdn
- 2解决gif图在小程序的webview长按转发不是动图的问题(安卓手机)_微信小程序中web-view的图片长按分享
- 3前端怎么实现聊天输入框?怎么实现类似b站评论的输入并发送自定义表情包?输入回显、发送时表情包转义为[emoji]字符串、页面展示回显_vue自定义表情如何显示到输入框
- 4探索Web3D世界:Three.js城市模型项目详解
- 5海量数据面试题----分而治之/hash映射 + hash统计 + 堆/快速/归并排序_hash分冶 统计词频 局部排序
- 6快速构建本地RAG聊天机器人:使用LangFlow和Ollama实现无代码开发_ragflow ollama
- 7【翻译】GPT-3架构,简述于“餐巾纸”上_gpt3 前馈网络 隐藏层维度
- 8【数据结构】C语言实现单链表万字详解(附完整运行代码)_c语言可运行代码
- 9通用大模型VS垂直大模型,两者的详细分析对比_通用大模型和垂直大模型
- 10数据结构——二叉树的非递归遍历_二叉树遍历的非递归实现
【知识图谱】医疗知识图谱可视化及问答系统设计与实现(2024年最全教程)_医疗系统 知识图谱
赞
踩
【知识图谱】医疗知识图谱可视化及问答系统设计与实现
一、项目概述
知识图谱是将知识连接起来形成的一个网络。由节点和边组成,节点是实体,边是两个实体的关系,节点和边都可以有属性。知识图谱除了可以查询实体的属性外,还可以很方便的从一个实体通过遍历关系的方式找到相关的实体及属性信息。
基于知识图谱+flask的KBQA医疗问答系统基于医疗方面知识的问答,通过搭建一个医疗领域知识图谱,并以该知识图谱完成自动问答与分析服务。 基于知识图谱+flask的KBQA医疗问答系统以neo4j作为存储,本系统知识图谱建模使用的最大向前匹配是一种贪心算法,从句首开始匹配,每次选择最长的词语。由于只需一次遍历,因此在速度上相对较快。 算法相对简单,容易实现和理解,不需要复杂的数据结构。 对于中文文本中大部分是左向的情况,最大向前匹配通常能够较好地切分。与最大向前匹配相反,最大向后匹配从句尾开始匹配,每次选择最长的词语。适用于大部分右向的中文文本。双向最大匹配结合了最大向前匹配和最大向后匹配的优势,从两个方向分别匹配,然后选择分词数量较少的一种结果。这种方法综合考虑了左向和右向的特点,提高了切分的准确性,以关键词执行cypher查询,并返回相应结果查询语句作为问答。后面我又设计了一个简单的基于 Flask 的聊天机器人应用,利用nlp自然语言处理,通过医疗AI助手根据用户的问题返回结果,用户输入和系统返回的输出结果都会一起自动存储到sql数据库。
在多模式匹配方面, Aho-Corasick算法专门用于在一个文本中同时搜索多个模式(关键词)。相比于暴力搜索算法,Aho-Corasick算法的时间复杂度较低,在本知识图谱建模问答系统中,性能更为显著。在线性时间复杂度方面,进行预处理的阶段,Aho-Corasick算法构建了一个确定性有限自动机(DFA),使得在搜索阶段的时间复杂度为O(n),其中n是待搜索文本的长度。这种线性时间复杂度使得算法在本应用中非常高效。在灵活性方面, Aho-Corasick算法在构建有限自动机的过程中,可以方便地添加、删除模式串,而不需要重新构建整个数据结构,提高了算法的灵活性和可维护性。
二、本系统的基本流程
- 配置好所需要的环境(jdk,neo4j,pycharm,python等)
- 爬取所需要的医学数据,获取所需基本的医疗数据。
- 对医疗数据进行数据清洗处理。
- 基于贪心算法进行分词策略。
- 关系抽取定义与实体识别。
- 知识图谱建模。
- 基于 Aho-Corasick算法进行多模式匹配。
- 设计一个基于 Flask 的聊天机器人AI助手。
- 设计用户输入和系统输出记录数据自动存储到sql数据库。
三、本系统的环境适配
Neo4j版本:Neo4j Desktop1.5.6;
Pycharm版本:2021;
JDK版本:jdk-17.0.7_windows-x64_bin;
MongoDB版本:MongoDB-windows-x86_64-5.0.14;
Flask版本:3.0.0
四、本系统所需要软件的安装和使用
(一)neo4j桌面版安装与配置
neo4j桌面版安装与配置教程
链接:https://zskp1012.blog.csdn.net/article/details/136736760
(二)安装MongoDB数据库:
参照MongoDB数据库安装教程:
安装教程链接: https://zskp1012.blog.csdn.net/article/details/138333533
五、项目结构整体目录
医疗知识图谱可视化及问答系统
- data\本项目的数据
- medical.json \本项目的数据,通过build_medicalgraph.py导neo4j
- dict
- check.txt \诊断检查项目实体库
- deny.txt \否定词词库
- department.txt \医学科目实体库
- disease.txt \疾病实体库
- drug.txt \药品实体库
- food.txt \食物实体库
- producer.txt \在售药品库
- symptom.txt \疾病症状实体库
- prepare_data \爬虫及数据处理
- build_data.py \数据库操作脚本
- data_spider.py \网络资讯采集脚本
- max_cut.py \基于词典的最大向前/向后脚本
- static \静态资源文件
- templates\问答系统前端UI页面
- answer_search.py \基于问题答复脚本
- app.py \医学AI助手问答系统机器人脚本
- question_classifier.py \问句类型分类脚本
- build_medicalgraph.py \构建医学图谱脚本
- question_parser.py \基于问句解析脚本
这里脚本首先从需要运行的app.py文件开始分析。该脚本构造了一个问答类ChatBotGraph,定义了QuestionClassifier类型的成员变量classifier、QuestionPase类型的成员变量parser和AnswerSearcher类型的成员变量searcher。
question_classifier.py脚本构造了一个问题分类的类QuestionClassifier,定义了特征词路径、特征词、领域actree、词典、问句疑问词等成员变量。
question_parser.py问句分类后需要对问句进行解析。该脚本创建一个QuestionPaser类,该类包含三个成员函数。
answer_search.py问句解析之后需要对解析后的结果进行查询。该脚本创建了一个AnswerSearcher类。与build_medicalgraph.py类似,该类定义了Graph类的成员变量g和返回答案列举的最大个数num_list。该类的成员函数有两个,一个查询主函数一个回复模块。
问答系统框架的构建是通过chatbot_graph.py、answer_search.py、question_classifier.py、question_parser.py等脚本实现。
六、系统实现具体步骤
(一)数据的抓取与存储
数据的抓取与存储参考教程
链接:https://zskp1012.blog.csdn.net/article/details/138333468
(二)基于neo4j构建医疗领域知识图谱
基于neo4j构建医疗领域知识图谱参考教程
链接:https://zskp1012.blog.csdn.net/article/details/138348897
(三)问答系统实现
(1)支持的问答类型
本项目问答对话系统的分析思路,整体上接近一个基于规则的对话系统,首先我们需要对用户输入进行分类,其实就是分析用户输入涉及到的实体及问题类型,也就是Neo4j中的node、property、relationship,然后我们利用分析出的信息,转化成Neo4j的查询语句,最后再把查询的结果返回给用户,就完成了一次问答。
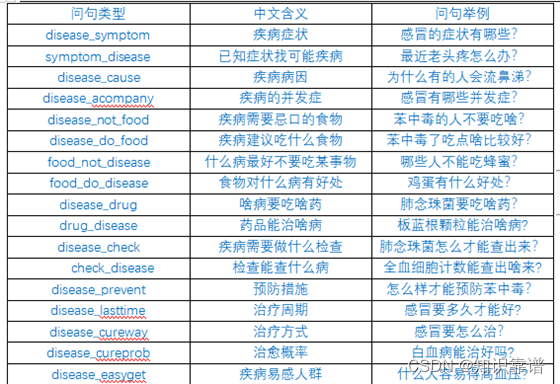
本项目问答系统支持的问答类型:
问答系统整体上涉及到三个模块,问题的分类、问题的解析以及回答的搜索。前文已经进行过解读。
(2)Aho-Corasick算法
这里需要使用Python的Ahocorasick库进行模式匹配,因此记录该库所使用的到的Aho-Corasick算法(AC算法)
Aho-Corasick算法是多模式匹配中的经典算法,目前在实际应用中较多。Aho-Corasick算法对应的数据结构是Aho-Corasick自动机,简称AC自动机Automaton。该算法能够识别出一个给定的语句中包含了哪些词典库中特定的词语,具有很有的模式匹配作用。
算法主要分为以下三个部分:
- 构造Goto表:成功转移到另一个状态
- 构造Failture指针:如果某状态发生匹配失败,需要跳转到一个特定的节点
- 匹配:匹配成功某一字符串
我们构建一个基于Aho-Corasick算法的trie树,用于加速过滤敏感词汇或关键词。
'''构造actree,加速过滤'''
def build_actree(self, wordlist):
actree = ahocorasick.Automaton() # 初始化trie树,ahocorasick 库 ac自动化 自动过滤违禁数据
for index, word in enumerate(wordlist):
actree.add_word(word, (index, word)) # 向trie树中添加单词
actree.make_automaton() # 将trie树转化为Aho-Corasick自动机
return actree
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用Aho-Corasick自动机的目的是在输入文本中高效地检测和过滤多个关键词。这种数据结构的优势在于,它能够同时匹配多个关键词而无需多次扫描输入文本,因此在过滤大量文本时性能较高。
- ahocorasick.Automaton(): 初始化一个Aho-Corasick自动机,使用了ahocorasick库。Aho-Corasick算法是一种多模式匹配算法,用于在输入文本中同时查找多个关键词。
- for index, word in enumerate(wordlist):: 对给定的关键词列表进行遍历。enumerate函数用于同时获取关键词在列表中的索引和关键词本身。
- actree.add_word(word, (index, word)): 向Aho-Corasick自动机中添加关键词。这里的关键词是来自于wordlist列表,(index, word)是一个元组,包含关键词在列表中的索引和关键词本身。Aho-Corasick算法将这些关键词构建成一个trie树。
- actree.make_automaton(): 将trie树转化为Aho-Corasick自动机。这一步是Aho-Corasick算法的关键,它会为每个节点添加失败转移(failure transition)和输出(output)信息,使得在匹配过程中能够快速定位到匹配的关键词。
- return actree: 返回构建好的Aho-Corasick自动机。
(3)实现方法与步骤
问答框架包含问句分类、问句解析、查询结果三个步骤,具体一步步分析。
首先是问句分类,是通过question_classifier.py脚本实现的。
再通过question_parser.py脚本进行问句分类后对问句进行解析。
然后通过answer_search.py脚本对解析后的结果进行查询
最后通过chatbot_graph.py脚本进行问答实测。
七、项目启动
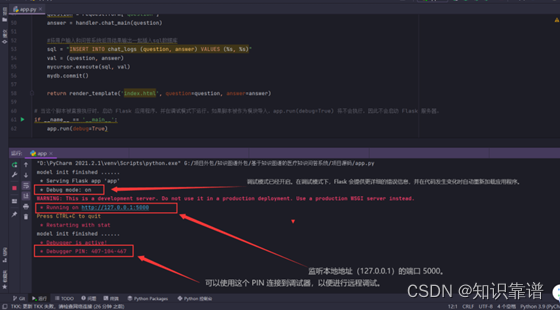
(一)系统运行
直接运行app脚本文件,启动flask。本地地址 http://127.0.0.1:5000/ 5000端口
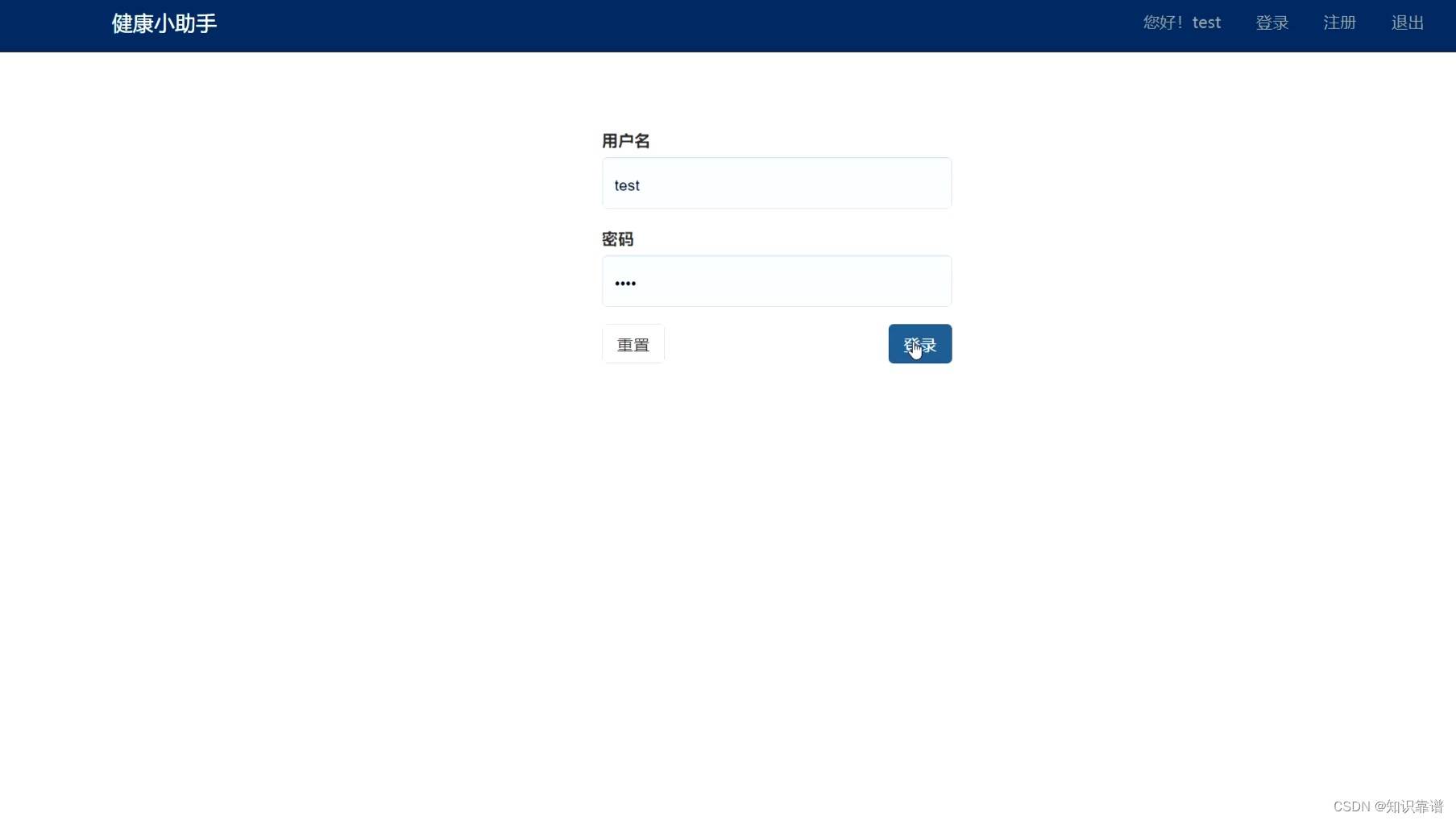
(二)系统登录
登录页面如下图所示,可自行进行用户注册。
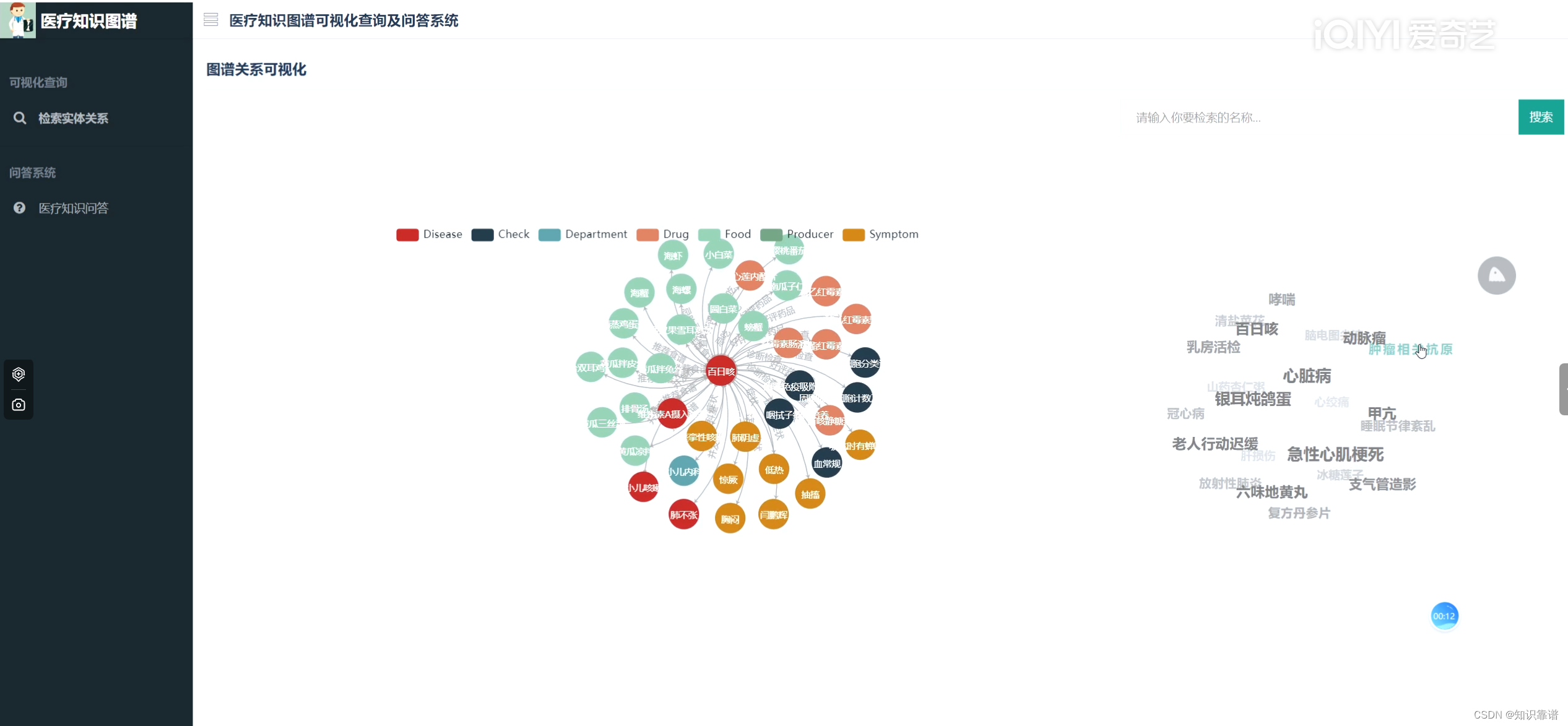
(三)可视化查询功能
可视化查询功能如下图所示。按照类型进行实体和关系的可视化。
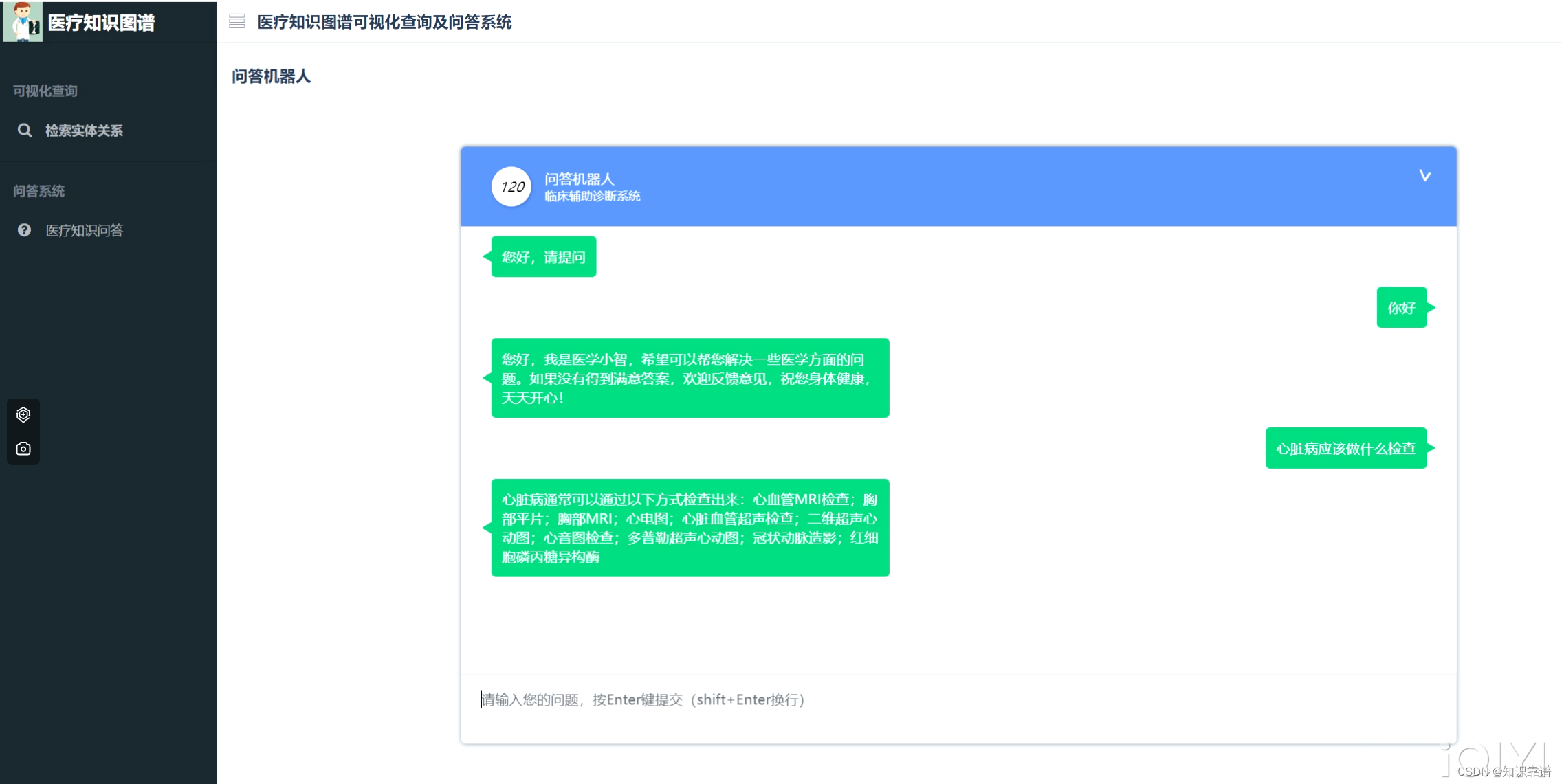
(四)医疗问答功能
医疗问答功能如下图所示。按照问答机器人的形式进行对话式问答。
以上就是对于本系统的介绍,不足之处敬请批评指正。
(如遇问题或合作咨询欢迎联系Wechat:zskp1012)

