
热门标签
热门文章
- 1【HarmonyOS 4.0 应用开发实战】ArkTS 快速入门
- 2java swing 开发手册_解读阿里巴巴 Java 开发手册背后的思考
- 315种数据分析方法和模型,赶紧收藏!_数据分析模型
- 4程序员带你解析Web是什么
- 5windows server 2016的安装及基础操作_server2016安装完以后变成dos版
- 6使用镜像源下载Hugging Face模型_hugging face 国内镜像
- 7近50年数据库技术发展史_叙述数据库技术50年发展取得的主要成就
- 8nginx 有哪些功能_nginx有什么功能
- 9麒麟系统防火墙配置方法_银河麒麟操作系统最佳安全配置
- 10三次样条插值(Cubic Spline Interpolation)及代码实现(C语言)
当前位置: article > 正文
pytorch --反向传播和优化器
作者:小丑西瓜9 | 2024-02-27 07:04:44
赞
踩
pytorch --反向传播和优化器
1. 反向传播
计算当前张量的梯度
Tensor.backward(gradient=None, retain_graph=None, create_graph=False, inputs=None)
- 1
计算当前张量相对于图中叶子节点的梯度。
使用反向传播,每个节点的梯度,根据梯度进行参数优化,最后使得损失最小化
代码:
import torch import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10('data',train=False,transform=torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset,batch_size=1) class Tudui(nn.Module): def __init__(self): super().__init__() # 另一种写法 self.model1 = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(2), nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(2), nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(in_features=1024, out_features=64), nn.Linear(in_features=64, out_features=10) ) def forward(self,x): # sequential方式 x = self.model1(x) return x loss = nn.CrossEntropyLoss() tudui = Tudui() for data in dataloader: imgs,target = data outputs= tudui(imgs) result_loss = loss(outputs,target) result_loss.backward() # 梯度 print(result_loss)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
2.优化器 (以随机梯度下降算法为例)
将上一步的梯度清零
params ,lr(学习率)
随机梯度下降SGD
torch.optim.SGD(params,
lr=,
momentum=0, dampening=0, weight_decay=0, nesterov=False, *, maximize=False, foreach=None, differentiable=False)
代码:
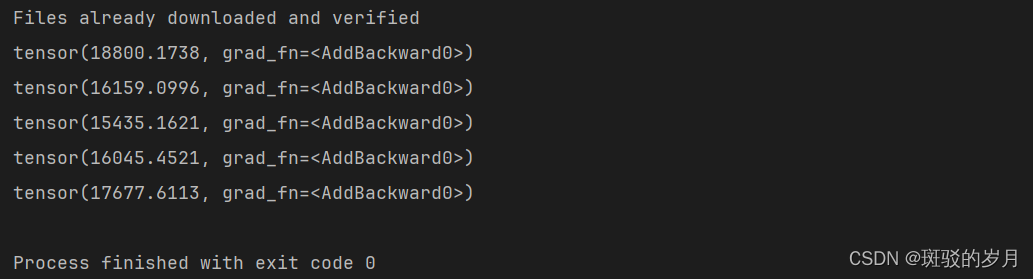
import torch import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10('data',train=False,transform=torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset,batch_size=1) class Tudui(nn.Module): def __init__(self): super().__init__() # 另一种写法 self.model1 = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(2), nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(2), nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(in_features=1024, out_features=64), nn.Linear(in_features=64, out_features=10) ) def forward(self,x): # sequential方式 x = self.model1(x) return x loss = nn.CrossEntropyLoss() tudui = Tudui() optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # params,lr for epoch in range(5):# 在整个数据集上训练5次 running_loss = 0 #对数据进行一轮学习 for data in dataloader: imgs,target = data outputs= tudui(imgs) result_loss = loss(outputs,target) optim.zero_grad() # 将上一步的梯度清零 result_loss.backward() # 梯度 optim.step() # 根据梯度修改参数 # print(result_loss) running_loss = running_loss + result_loss print(running_loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
输出
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/150933
推荐阅读
相关标签

