
- 1基于Java+SpringBoot+Vue前后端分离婚纱影楼管理系统设计和实现_springboot vue婚纱影楼系统
- 2保姆级教程-如何使用LLAMA2 大模型_如何调用 llama 的 api
- 3Jenkins忘记密码解决方案_jenkins忘记用户名和密码
- 4《Python编程:从入门到实践》第12章:武装飞船_python入门到实践中的 ship.bmg
- 52023美赛E题_2023美赛e题 背景 光污染是用来描述任何过度或不良的使用人工光。一些我们称之为
- 6MYSQL 8 UNDO 表空间 你了解多少
- 7vs code解决无法识别已安装python库的问题(Mac版)
- 8初始MyBatis,w字带你解MyBatis
- 9video 标签设置样式_video标签样式
- 10如何在论文中画出漂亮的插图?
Linux:监控CPU、磁盘、内存、I/O资源命令(mpstat、vmstat、pidstat、iostat)_cpu内存实时信息显示 pstate util ipc 命令是什么
赞
踩
目录
6.iostat -d -x -k 查看设备使用率(%util)、响应时间(await)
一、Linux资源监控命令汇总
内存:top、free、vmstat、mpstat、iostat、sar、pmpa
I/O:vmstat、mpstat、iostat、、sar
CPU:top、vmstat、mpstat、iostat、sar
今天就对一些常用的命令来详细说明一下
二、uptime
uptime [选项]
-p:有好输出系统已运行时间
-h:显示帮助信息
-s:--since已格式yyyy-mm-dd HHSS format输出系统时间
-V:显示系统版本
三、mpstat
mpstat命令主要用于多CPU环境下,它能显示各个CPU状态。这些信息存放在/proc/stat文件中。
3.1、应用场景:
分析多CPU的平均负载高的原因
计算机密集导致平均负载高
IO导致平均负载高
等待CPU调度导致平均负载高
mpstat经常配合pidstat等其他命令一起分析系统性能瓶颈
3.2、命令语法和参数详解
mpstat [选线] [参数] [i nternal] [count]
-P:指定要监控哪个CPU,范围是[0~n-1],ALL表示监控所有CPU
internal:相邻两次采样的间隔时间
count:采样次数
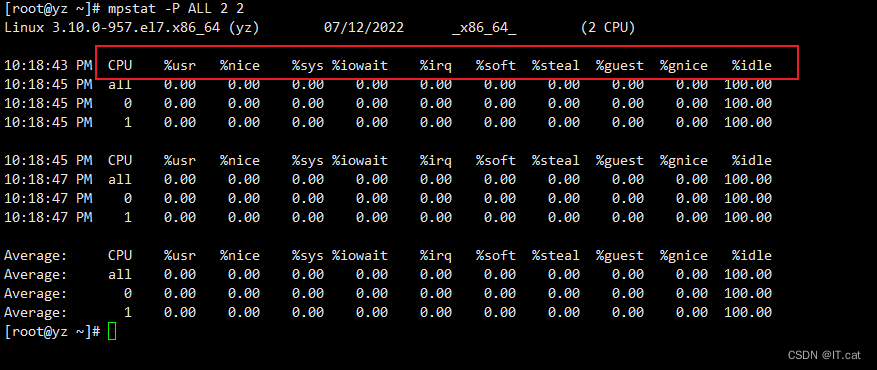
| %user | 表示用户所使用CPU的百分比 |
| %nice | 表示使用nice命令对进程进行降级时CPU的百分比 |
| %sys | 表示内核进程使用的CPU百分比 |
| %iowait | 表示等待进行I/O所使用的CPU时间百分比 |
| %irq | 表示用于处理系统中断的CPU百分比 |
| %soft | 表示用于软件中断的CPU百分比 |
| %steal | 虚拟机强制CPU等待的时间百分比 |
| %guest | 虚拟机占用CPU时间的百分比 |
| %idle | CPU的空闲时间的百分比 |
备注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
mpstat主要用在当系统变慢,如ssh过去输入命令特别卡,平均负载增大时,我们想判断到底是CPU的使用率增大了,还是IO压力增大的情况。
四、vmstat
vmstat可用给定时间间隔的服务器的状态值包括CPU的使用率,内存使用,虚拟内存交换情况,IO读写情况。可用查看整机的各个参数使用情况。
vmstat [选项] [刷新延时 刷新次数]

| 字段 | 含义 |
| procs | 进程信息字段 r(运行队列):等待运行的进程数,数量越大,系统越繁忙 b(进程阻塞):不可被唤醒的进程数量,数量越大系统越繁忙 |
| memory | 内存信息字段 (单位未KB) swap:虚拟内存的使用情况,大于0说明你物理内存不足了 free:空闲的物理内存容量 buff:缓冲的内存容量 cache:缓存的内存容量 |
| swap | 交换分区信息字段(单位为KB) si:从磁盘中交换到内存中数据的数量 so:从内存中交换到磁盘中数据的数量 这两个数越大,表明需要经常在磁盘和内存之间进行交换,系统性能越差 |
| io | 磁盘读/写信息字段 bi:从块设备中读入的数据的总量,单位为块 bo:写入块设备的数据的总量,单位为块 这两个值越大,表示系统的I/O越繁忙 |
| system | 系统信息字段 in:每秒被中断的进程次数 cs:每秒进行的时间切换次数 这两个值越大,代表系统与接口设备的通信越繁忙 |
| CPU | CPU信息字段 us:非内核进程消耗CPU运算时间的百分比 sy:内核进程消耗CPU运算时间额百分比 id:空闲CPU的百分比 wa:等待I/O所消耗的CPU百分比 st:被虚拟机盗用的CPU资源 |
五、pidstat
pidstat可用于监控全部或指定进程的CPU、内存、IO等系统资源的占用情况
与vmstat可用查询的资源相似,但是相对对于某一个进程进行监控的话,vmstat多少有点吃力,但是pidstat可用很轻松的完成,所以可用根据使用场景,来使用资源监控工具
pidstat [选项] [时间间隔 刷新次数] #如果没有刷新次数就会按时间间隔一直刷新
-u:默认参数,显示各个进程的使用统计
-r:显示各个进程的内存使用情况
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下切换
-t:显示选择任务的线程的统计信息的额外信息
-T{TASK | CHILD | ALL}:TASK表示独立的task(进程任务),CHILD关键字表示报告进程下所有线程统计信息,ALL表示报告独立的task和task下面的所有进程(注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。
-I:在SMP环境,表示任务的CPU使用率/内核数量
5.1、查看所有进程的cpu使用情况
pidstat 或 pidstat -u 或pidstat -p ALL 是一样的

| PID | 进程ID |
| %usr | 进程在用户空间占用CPU的百分比 |
| %system | 进程在内核空间占用CPU的百分比 |
| %guest | 进程在虚拟机占用的CPU的百分比 |
| %CPU | 进程占用的CPU的百分比 |
| CPU | 处理进程的CPU编号 |
| Command | 进程对应的命令 |
5.2、内存使用情况
pidstat -r

| PID | 进程ID |
| minflt / s | 每秒次缺页错误次数(minor page faults),当虚拟内存地址映射为物理内存地址时,相应的page数据已经加载到page cache,只需要将该page与进程虚拟地址空间进行映射即可 |
| majflt / s | 每秒主缺页错误次数(major page faults),当虚拟内存映射为物理内存地址时,相应的page数据还在磁盘上,此时则会触发一次major fault, |
| VSZ | 虚拟内存大小,虚拟机内存的使用KB |
| RSS | 常驻内存大小,非交换区里内存使用KB |
| Command | 当前进程对应的命令 |
5.3、显示进程I/O使用情况
pidstat -d
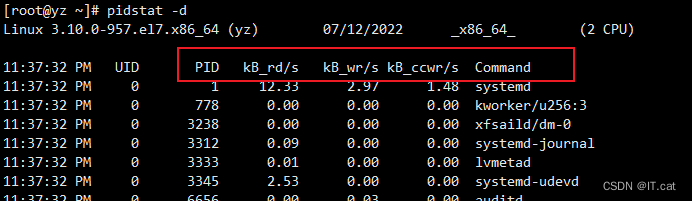
| PID | 进程ID |
| kB_rd / s | 每秒从磁盘读取的字节数(kb) |
| KB_wr / s | 每秒写入磁盘的字节数(kb) |
| KB_ccwr / s | 任务取消的写入磁盘的字节数(kb),当任务截断脏PageCache |
| iodelay | IO延迟,该延迟包含了等待同步块IO完成和swap块IO完成所花费的延迟 |
| Command | 当前进程对应的命令 |
5.4、显示进程上下文切换情况
- 简单说:进程上下文切换,是指从一个进程切换到另一个进程运行。
pidstat -w
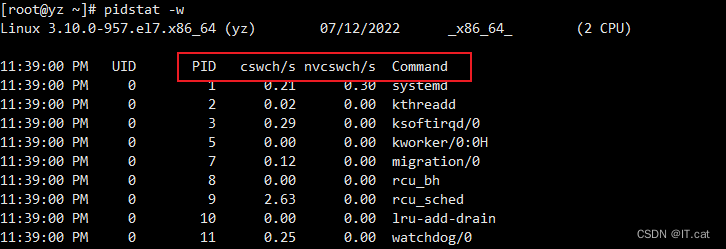
| PID | 进程ID |
| cswch / s | 每秒主动切换次数 |
| nvcswch / s | 每秒被动切换次数 |
| Command | 当前进程对应的命令 |
主动切换:当前进程无法获取所需资源导致的上下文切换。当IO、内存等系统资源不足时就会发生
被动切换:当进程由于CPU时间分片已到等原因,被系统强制调度所发生的上下文切换。当有大佬进程争抢CPU资源时,就容易发生被动切换
六、iostat
iostat主要用于监控系统设备的IO负载情况,根据这个可用看出当前系统的写入和读取量,CPU负载和磁盘负载
iostat [选项] [时间间隔 次数 ]
-c:显示CPU使用情况
-d:显示磁盘使用情况
-N:显示磁盘阵列信息
-n:显示NFS使用情况
-k:以KB为单位显示
-m:以M为单位显示
-t:报告每秒向终端读取和写入的字符数和CPU的信息
-V:显示版本信息
-x:显示详细信息
-p:[磁盘]显示磁盘和分区的情况
6.1、显示所有设备负载情况
iostat

cpu值
| %user | 表示用户所使用CPU的百分比 |
| %nice | 表示使用nice命令对进程进行降级时CPU的百分比 |
| %system | 表示内核进程使用的CPU百分比 |
| %iowait | 表示等待进行I/O所使用的CPU时间百分比 |
| %steal | 虚拟机强制CPU等待的时间百分比 |
| %idle | CPU的空闲时间的百分比 |
io值
| device | 磁盘名称 |
| tps | 每秒钟发送到I/O请求数 |
| Blk_read / s | 每秒读取的块数 |
| Blk_wrtn / s | 每秒写入的块数 |
| Blk_read | 读入块的总数 |
| Blk_wrtn | 写入块的总数 |
6.2、以M为的单位显示所有信息
iostat -m
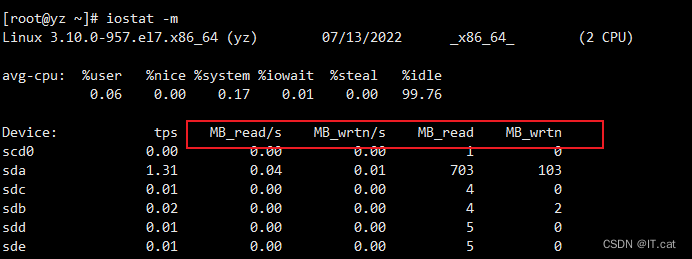
6.3、显示指定硬盘信息
iostat -d sda

6.4、报告每秒向终端读取和写入的字节数
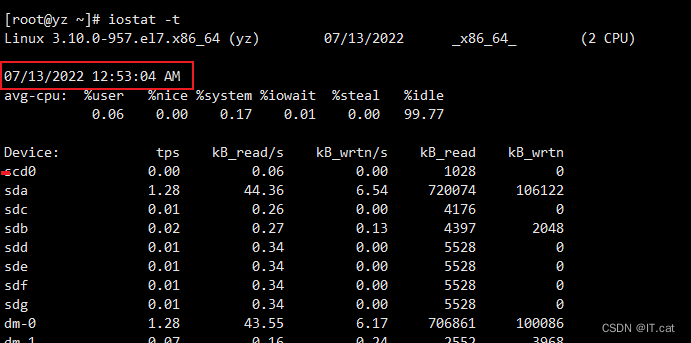
6.5、查看TPS和吞吐量信息
iostat -d -k
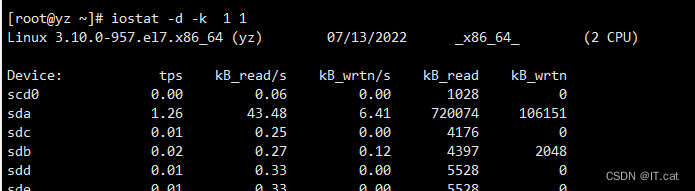
6.iostat -d -x -k 查看设备使用率(%util)、响应时间(await)

- tps:每秒钟发送到的I/O请求数。
- Blk_read/s:每秒读取的block数。
- Blk_wrtn/s:每秒写入的block数。
- Blk_read:读入的block总数。
- Blk_wrtn:写入的block总数。
- rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
- wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
- r/s: 每秒完成的读 I/O 设备次数。即 rio/s
- w/s: 每秒完成的写 I/O 设备次数。即 wio/s
- rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
- wkB/s: 每秒写K字节数。是 wsect/s 的一半。
- avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
- avgqu-sz: 平均I/O队列长度。
- rsec/s: 每秒读扇区数。即 rsect/s
- wsec/s: 每秒写扇区数。即 wsect/s
- r_await:每个读操作平均所需的时间
- 不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间。
- w_await:每个写操作平均所需的时间
- 不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间。
- await: 平均每次设备I/O操作的等待时间 (毫秒)。
- svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
- %util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比

注意点:
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
如果avgqu-sz比较大,也表示有当量io在等待。
总结
以上命令都有查看cpu、磁盘、内盘、io等资源,但是具体还是得根据实际需求来使用,以上列出的是较常使用的。

